


第三周学习总结
Vim的操作指令:
:tabe fn 在一个新的标签页中编辑文件fn
gt 切换到下一个标签页
gT 切换到上一个标签页
:tabr 切换到第一个标签页
:tabl 切换到最后一个标签页
:tabm [N] 把当前tab移动到第N个tab之后
对,正如你所想象的那样,跟eclipse, ue等的标签页是一个意思!
窗口命令
ctrl+w s 水平分割窗口
ctrl+w w 切换窗口
ctrl+w q 退出当前窗口(由于同时有多个文件,此命令不会影响其他窗口)
ctrl+w v 垂直分割窗口
其他
vim在保存之前不会对文件做实际的修改,只是加载到缓冲区中,对文件的编辑其实是对缓冲区的编辑,直到:w时才会存入物理文件。
:e file 把file加载到新的缓冲区中
:bn 跳转到下一个缓冲区
:bd 删除缓冲区(关闭文件)
:sp fn 分割窗口,并将fn加载到新的窗口中
退出编辑器
:w 将缓冲区写入文件,即保存修改
:wq 保存修改并退出
:x 保存修改并退出
:q 退出,如果对缓冲区进行过修改,则会提示
:q! 强制退出,放弃修改
查找替换
/pattern 向后搜索字符串pattern
?pattern 向前搜索字符串pattern
n 下一个匹配(如果是/搜索,则是向下的下一个,?搜索则是向上的下一个)
N 上一个匹配(同上)
:%s/old/new/g 搜索整个文件,将所有的old替换为new
:%s/old/new/gc 搜索整个文件,将所有的old替换为new,每次都要你确认是否替换
复制粘贴
dd 删除光标所在行
dw 删除一个字(word)
x 删除当前字符
X 删除前一个字符
D 删除到行末
yy 复制一行,此命令前可跟数字,标识复制多行,如6yy,表示从当前行开始复制6行
yw 复制一个字
y$ 复制到行末
p 粘贴粘贴板的内容到当前行的下面
P 粘贴粘贴板的内容到当前行的上面
]p 有缩进的粘贴,vim会自动调节代码的缩进
"a 将内容放入/存入a寄存器,可以支持多粘贴板
附:比如常用的一个寄存器就是系统寄存器,名称为+,所以从系统粘贴板粘贴到vim中的命令为"+p,注意此处的+不表示操作符,二十一个寄存器。
移动光标
在vim中移动光标跟其他的编辑器中有很大的区别,不过一旦学会了,就会飞速的在文本中移动了。
h,j,k,l 上,下,左,右
ctrl-f 上翻一页
ctrl-b 下翻一页
% 跳到与当前括号匹配的括号处,如当前在{,则跳转到与之匹配的}处
w 跳到下一个字首,按标点或单词分割
W 跳到下一个字首,长跳,如end-of-line被认为是一个字
e 跳到下一个字尾
E 跳到下一个字尾,长跳
b 跳到上一个字
B 跳到上一个字,长跳
0 跳至行首,不管有无缩进,就是跳到第0个字符
^ 跳至行首的第一个字符
$ 跳至行尾
gg 跳至文件的第一行
gd 跳至当前光标所在的变量的声明处
[N]G 跳到第N行,如0G,就等价于gg,100G就是第100行
fx 在当前行中找x字符,找到了就跳转至
; 重复上一个f命令,而不用重复的输入fx
tx 与fx类似,但是只是跳转到x的前一个字符处
Fx 跟fx的方向相反
),( 跳转到上/下一个语句
* 查找光标所在处的单词,向下查找
# 查找光标所在处的单词,向上查找
`. 跳转至上次编辑位置
在屏幕上移动
H 移动光标到当前屏幕上最上边的一行
M 移动光标到当前屏幕上中间的一行
L 移动光标到当前屏幕上最下边的一行
书签
ma 把当前位置存成标签a
`a 跳转到标签a处
编辑
r 替换一个字符
J 将下一行和当前行连接为一行
cc 删除当前行并进入编辑模式
cw 删除当前字,并进入编辑模式
c$ 擦除从当前位置至行末的内容,并进入编辑模式
s 删除当前字符并进入编辑模式
S 删除光标所在行并进入编辑模式
xp 交换当前字符和下一个字符
u 撤销
ctrl+r 重做
. 重复上一个编辑命令
~ 切换大小写,当前字符
g~iw 切换当前字的大小写
gUiw 将当前字变成大写
guiw 将当前字变成小写
>> 将当前行右移一个单位
<< 将当前行左移一个单位(一个tab符)
== 自动缩进当前行
插入模式
i 从当前光标处进入插入模式
I 进入插入模式,并置光标于行首
a 追加模式,置光标于当前光标之后
A 追加模式,置光标于行末
o 在当前行之下新加一行,并进入插入模式
O 在当前行之上新加一行,并进入插入模式
Esc 退出插入模式
可视模式
标记文本
v 进入可视模式,单字符模式
V 进入可视模式,行模式
ctrl+v 进入可视模式,列模式,类似于UE的列模式
o 跳转光标到选中块的另一个端点
U 将选中块中的内容转成大写
O 跳转光标到块的另一个端点
aw 选中一个字
ab 选中括号中的所有内容,包括括号本身
aB 选中{}括号中的所有内容
ib 选中括号中的内容,不含括号
iB 选中{}中的内容,不含{}
对标记进行动作
> 块右移
< 块左移
y 复制块
d 删除块
~ 切换块中内容的大小写






GCC的操作指令:
1 GCC 的意思也只是 GNU C Compiler 而已。经过了这么多年的发展,GCC 已经不仅仅能支持 C 语言;它现在还支持 Ada 语言、C++ 语言、Java 语言、Objective C 语言、Pascal 语言、COBOL语言,以及支持函数式编程和逻辑编程的 Mercury 语言,等等。而 GCC 也不再单只是 GNU C 语言编译器的意思了,而是变成了 GNU Compiler Collection 也即是 GNU 编译器家族的意思了。另一方面,说到 GCC 对于操作系统平台及硬件平台支持,概括起来就是一句话:无所不在。
2简单编译
示例程序如下:
//test.c
#include <stdio.h>
int main(void)
{
printf("Hello World!\n");
return 0;
}
这个程序,一步到位的编译指令是:
gcc test.c -o test
实质上,上述编译过程是分为四个阶段进行的,即预处理(也称预编译,Preprocessing)、编译(Compilation)、汇编 (Assembly)和连接(Linking)。
2.1预处理
可以输出test.i文件中存放着test.c经预处理之后的代码。打开test.i文件,看一看,就明白了。后面那条指令,是直接在命令行窗口中输出预处理后的代码.
gcc的-E选项,可以让编译器在预处理后停止,并输出预处理结果。在本例中,预处理结果就是将stdio.h 文件中的内容插入到test.c中了。
2.2编译为汇编代码(Compilation)
预处理之后,可直接对生成的test.i文件编译,生成汇编代码:
gcc的-S选项,表示在程序编译期间,在生成汇编代码后,停止,-o输出汇编代码文件。
2.3汇编(Assembly)
对于上一小节中生成的汇编代码文件test.s,gas汇编器负责将其编译为目标文件,如下:
2.4连接(Linking)
gcc连接器是gas提供的,负责将程序的目标文件与所需的所有附加的目标文件连接起来,最终生成可执行文件。附加的目标文件包括静态连接库和动态连接库。
对于上一小节中生成的test.o,将其与C标准输入输出库进行连接,最终生成程序test
在命令行窗口中,执行./test, 让它说HelloWorld吧!
3多个程序文件的编译
通常整个程序是由多个源文件组成的,相应地也就形成了多个编译单元,使用GCC能够很好地管理这些编译单元。假设有一个由test1.c和 test2.c两个源文件组成的程序,为了对它们进行编译,并最终生成可执行程序test,可以使用下面这条命令:
如果同时处理的文件不止一个,GCC仍然会按照预处理、编译和链接的过程依次进行。如果深究起来,上面这条命令大致相当于依次执行如下三条命令:
4检错
-pedantic编译选项并不能保证被编译程序与ANSI/ISO C标准的完全兼容,它仅仅只能用来帮助Linux程序员离这个目标越来越近。或者换句话说,-pedantic选项能够帮助程序员发现一些不符合 ANSI/ISO C标准的代码,但不是全部,事实上只有ANSI/ISO C语言标准中要求进行编译器诊断的那些情况,才有可能被GCC发现并提出警告。
除了-pedantic之外,GCC还有一些其它编译选项也能够产生有用的警告信息。这些选项大多以-W开头,其中最有价值的当数-Wall了,使用它能够使GCC产生尽可能多的警告信息。
GCC给出的警告信息虽然从严格意义上说不能算作错误,但却很可能成为错误的栖身之所。一个优秀的Linux程序员应该尽量避免产生警告信息,使自己的代码始终保持标准、健壮的特性。所以将警告信息当成编码错误来对待,是一种值得赞扬的行为!所以,在编译程序时带上-Werror选项,那么GCC会在所有产生警告的地方停止编译,迫使程序员对自己的代码进行修改,如下:
5库文件连接
开发软件时,完全不使用第三方函数库的情况是比较少见的,通常来讲都需要借助许多函数库的支持才能够完成相应的功能。从程序员的角度看,函数库实际上就是一些头文件(.h)和库文件(so、或lib、dll)的集合。。虽然Linux下的大多数函数都默认将头文件放到/usr/include/目录下,而库文件则放到/usr/lib/目录下;Windows所使用的库文件主要放在Visual Stido的目录下的include和lib,以及系统文件夹下。但也有的时候,我们要用的库不再这些目录下,所以GCC在编译时必须用自己的办法来查找所需要的头文件和库文件。
例如我们的程序test.c是在linux上使用c连接mysql,这个时候我们需要去mysql官网下载MySQL Connectors的C库,下载下来解压之后,有一个include文件夹,里面包含mysql connectors的头文件,还有一个lib文件夹,里面包含二进制so文件libmysqlclient.so
其中inclulde文件夹的路径是/usr/dev/mysql/include,lib文件夹是/usr/dev/mysql/lib
5.1编译成可执行文件
首先我们要进行编译test.c为目标文件,这个时候需要执行
5.2链接
最后我们把所有目标文件链接成可执行文件:
Linux下的库文件分为两大类分别是动态链接库(通常以.so结尾)和静态链接库(通常以.a结尾),二者的区别仅在于程序执行时所需的代码是在运行时动态加载的,还是在编译时静态加载的。
5.3强制链接时使用静态链接库
默认情况下, GCC在链接时优先使用动态链接库,只有当动态链接库不存在时才考虑使用静态链接库,如果需要的话可以在编译时加上-static选项,强制使用静态链接库。
在/usr/dev/mysql/lib目录下有链接时所需要的库文件libmysqlclient.so和libmysqlclient.a,为了让GCC在链接时只用到静态链接库,可以使用下面的命令:
静态库链接时搜索路径顺序:
1. ld会去找GCC命令中的参数-L
2. 再找gcc的环境变量LIBRARY_PATH
3. 再找内定目录 /lib /usr/lib /usr/local/lib 这是当初compile gcc时写在程序内的
动态链接时、执行时搜索路径顺序:
1. 编译目标代码时指定的动态库搜索路径
2. 环境变量LD_LIBRARY_PATH指定的动态库搜索路径
3. 配置文件/etc/ld.so.conf中指定的动态库搜索路径
4. 默认的动态库搜索路径/lib
5. 默认的动态库搜索路径/usr/lib
有关环境变量:
LIBRARY_PATH环境变量:指定程序静态链接库文件搜索路径
LD_LIBRARY_PATH环境变量:指定程序动态链接库文件搜索路径
GCC编译代码的过程如下:
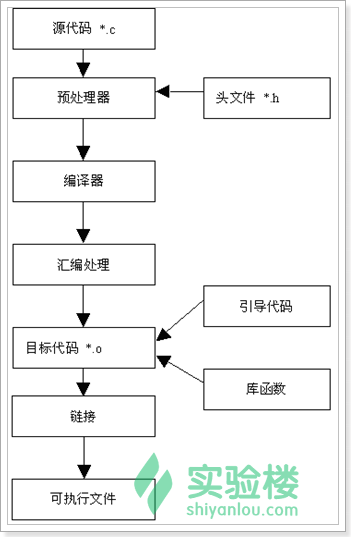
我们可以把编译过程分成四步,以编译hello.c生成可执行文件hello为例,如下图:
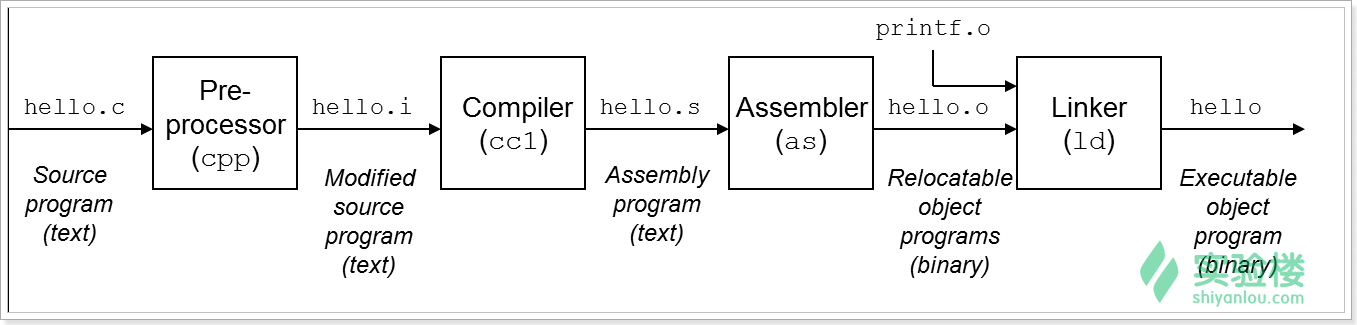
预处理:gcc –E hello.c –o hello.i;gcc –E调用cpp
编 译:gcc –S hello.i –o hello.s;gcc –S调用ccl
汇 编:gcc –c hello.s –o hello.o;gcc -c 调用as
链 接:gcc hello.o –o hello ;gcc -o 调用ld
注意使用GCC编译时要加“-g”参数
Gdb的操作指令:
编译时必须加上参数-g ,例:g++ -g temp.cpp -o temp.通过Gcc编译生成可执行文件才能用Gdb进行调试。
进入gdb界面:gdb temp. 提示符变成(gdb)
(1)查看文件
在Gdb中键入”l”(list)就可以查看所载入的文件
(2)设置断点
只需在”b”后加入对应的行号即可(这是最常用的方式,另外还有其他方式设置断点)。如下所示:
(gdb)b 6
代码运行到第五行之前暂停(并没有运行第五行)。
(3)查看断点情况
(Gdb) info b
(4)运行代码
Gdb默认从首行开始运行代码,可键入”r”(run)即可(若想从程序中指定行开始运行,可在r后面加上行号)。
(5)查看变量值
查看断点处的相关变量值。在Gdb中只需键入”p”+变量值即可,如下所示:
(Gdb) p n
Gdb在显示变量值时都会在对应值之前加上”$N”标记,它是当前变量值的引用标记,所以以后若想再次引用此变量就可以直接写作”$N”,而无需写冗长的变量名。
(6)单步运行
使用命令”n”(next)或”s”(step),它们之间的区别在于:若有函数调用的时候,”s”会进入该函数而”n”不会进入该函数。因此,”s”就类似于VC等工具中的”step in”,”n”类似与VC等工具中的”step over”。
(7)恢复程序运行
使用命令”c”(continue).
在Gdb中,程序的运行状态有“运行”、“暂停”和“停止”三种,其中“暂停”状态为程序遇到了断点或观察点之类的,程序暂时停止运行,而此时函数的地址、函数参数、函数内的局部变量都会被压入“栈”(Stack)中。故在这种状态下可以查看函数的变量值等各种属性。但在函数处于“停止”状态之后,“栈”就会自动撤销,它也就无法查看各种信息了。
Gdb中的命令主要分为以下几类:工作环境相关命令、设置断点与恢复命令、源代码查看命令、查看运行数据相关命令及修改运行参数命令。以下就分别对这几类的命令进行讲解。
1.工作环境相关命令
set args运行时的参数 指定运行时参数,如:set args 2
show args 查看设置好的运行参数
path dir 设定程序的运行路径
show paths 查看程序的运行路径
set enVironment var [=value] 设置环境变量
show enVironment [var] 查看环境变量
cd dir 进入到dir目录,相当于shell中的cd命令
pwd 显示当前工作目录
shell command 运行shell的command命令
2.设置断点与恢复命令
info b 查看所设断点
break 行号或函数名 <条件表达式> 设置断点
tbreak 行号或函数名 <条件表达式> 设置临时断点,到达后被自动删除
delete [断点号] 删除指定断点,其断点号为”info b”中的第一栏。若缺省断点号则删除所有断点
disable [断点号]] 停止指定断点,使用”info b”仍能查看此断点。同delete一样,省断点号则停止所有断点
enable [断点号] 激活指定断点,即激活被disable停止的断点
condition [断点号] <条件表达式> 修改对应断点的条件
ignore [断点号]<num> 在程序执行中,忽略对应断点num次
step 单步恢复程序运行,且进入函数调用
next 单步恢复程序运行,但不进入函数调用
finish 运行程序,直到当前函数完成返回
c 继续执行函数,直到函数结束或遇到新的断点
由于设置断点在Gdb的调试中非常重要,所以在此再着重讲解一下Gdb中设置断点的方法。
Gdb中设置断点有多种方式:其一是按行设置断点,设置方法在3.5.1节已经指出,在此就不重复了。另外还可以设置函数断点和条件断点,在此结合上一小节的代码,具体介绍后两种设置断点的方法。
① 函数断点
(gdb) b 函数名
② 条件断点
格式为:b 行数或函数名 if 表达式
(gdb) b 8 if i==10
3.Gdb中源码查看相关命令
list <行号>|<函数名> 查看指定位置代码
file [文件名] 加载指定文件
forward-search 正则表达式 源代码前向搜索
reverse-search 正则表达式 源代码后向搜索
dir dir 停止路径名
show directories 显示定义了的源文件搜索路径
info line 显示加载到Gdb内存中的代码
4.Gdb中查看运行数据相关命令
指当程序处于“运行”或“暂停”状态时,可以查看的变量及表达式的信息
print 表达式|变量 查看程序运行时对应表达式和变量的值
x <n/f/u> 查看内存变量内容。其中n为整数表示显示内存的长度,f表示显示的格式,u表示从当前地址往后请求显示的字节数
display 表达式 设定在单步运行或其他情况中,自动显示的对应表达式的内容
5.Gdb中修改运行参数相关命令
Gdb还可以修改运行时的参数,并使该变量按照用户当前输入的值继续运行。它的设置方法为:在单步执行的过程中,键入命令“set 变量=设定值”。这样,在此之后,程序就会按照该设定的值运行了。下面,笔者结合上一节的代码将n的初始值设为4,其代码如下所示:
(Gdb) b 7
Breakpoint 5 at 0x804847a: file test.c, line 7.
(Gdb) r
Starting program: /home/yul/test
The sum of 1-m is 1275
Breakpoint 5, main () at test.c:7
7 for(i=1; i<=50; i++)
(Gdb) set n=4
(Gdb) c
Continuing.
The sum of 1-50 is 1279
Program exited with code 031.
可以看到,最后的运行结果确实比之前的值大了4。
Gdb的使用切记点:
· 在Gcc编译选项中一定要加入”-g”。
· 只有在代码处于“运行”或“暂停”状态时才能查看变量值。
· 设置断点后程序在指定行之前停止。
