
20145215《信息安全系统设计基础》期中总结
20145215《信息安全系统设计基础》期中总结
知识点总结
常用的Linux命令
- Linux中命令格式为:
command [options] [arguments] []表示是可选的,即组成结构为:命令 [选项] [参数]
man命令
man命令是Linux下的帮助指令,通过man指令可以查看Linux中的指令帮助、配置文件帮助和编程帮助等信息。- 常用选项:
-a:在所有的man帮助手册中搜索-k:根据关键字搜索联机帮助,是一种模糊搜索-f:关键字精确搜索,等价于whatis指令,显示给定关键字的简短描述信息-P:指定内容时使用分页程序-M:指定man手册搜索的路径
- 参数:
数字:指定从哪本man手册中搜索帮助关键字:指定要搜索帮助的关键字
man -k:常用来搜索,结合管道使用。例句如下:man -k k1 | grep k2 | grep 2
cheat命令
- 在linux上,
man命令几乎是万能的,但它却不是最高效的。由于它给出的帮助信息很长,在短时间内不好理解,所以在这种情况下,用cheat命令更方便,cheat命令简单来说,就是告诉你一个命令如何使用。它没有提供其他额外多余的信息,只通过使用实例告诉你一个命令如何使用。
grep命令
grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。- 命令格式:
grep [options] - [options]主要参数:
-c:只输出匹配行的计数-I:不区分大小写(只适用于单字符)-h:查询多文件时不显示文件名-l:查询多文件时只输出包含匹配字符的文件名-n:显示匹配行及行号-s:不显示不存在或无匹配文本的错误信息-v:显示不包含匹配文本的所有行
- 如果想查找某个宏,我们已知宏保存在include文件夹中,所以可以使用下列语句:
grep -nr XXX /usr/include(XXX为所要找的宏)
find命令
find命令用来在指定目录下查找文件。任何位于参数之前的字符串都将被视为欲查找的目录名。如果使用该命令时,不设置任何参数,则find命令将在当前目录下查找子目录与文件。并且将查找到的子目录和文件全部进行显示。- 命令格式:
find pathname -options [-print -exec -ok ...] - 参数:
pathname:find命令所查找的目录路径。例如用.来表示当前目录,用/来表示系统根目录print:find命令将匹配的文件输出到标准输出exec:find命令对匹配的文件执行该参数所给出的shell命令,相应命令的形式为'command' { } ;,注意{ }和\;之间的空格ok:和-exec的作用相同,只不过以一种更为安全的模式来执行该参数所给出的shell命令,在执行每一个命令之前,都会给出提示,让用户来确定是否执行
- 常用选项:
-name:按照文件名查找文件-perm:按照文件权限来查找文件mtime -n +n:按照文件的更改时间来查找文件, - n表示文件更改时间距现在n天以内,+ n表示文件更改时间距现在n天以前-newer file1 ! file2:查找更改时间比文件file1新但比文件file2旧的文件-type:查找某一类型的文件,诸如:b - 块设备文件,d - 目录,c - 字符设备文件,p - 管道文件,l - 符号链接文件,f - 普通文件-size n:[c] 查找文件长度为n块的文件,带有c时表示文件长度以字节计-depth:在查找文件时,首先查找当前目录中的文件,然后再在其子目录中查找
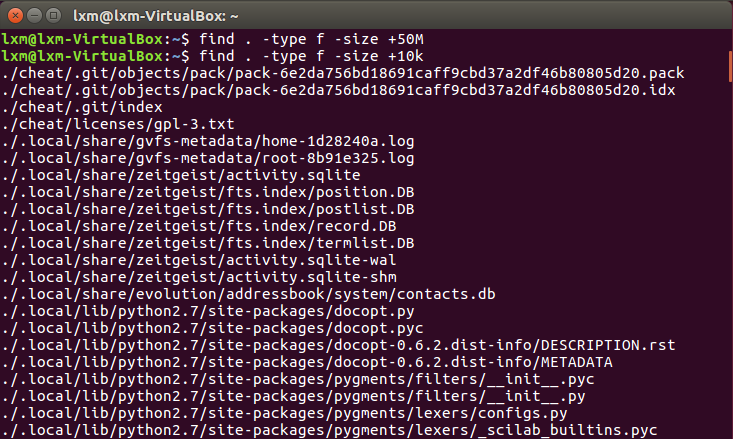
- 举例:查找当前目录下大小大于50M的文件,查找大小大于10K的文件
locate命令
locate命令其实是find -name的另一种写法,但是要比后者快得多,原因在于它不搜索具体目录,而是搜索一个数据库(/var/lib/locatedb),这个数据库中含有本地所有文件信息。Linux系统自动创建这个数据库,并且每天自动更新一次,所以使用locate命令查不到最新变动过的文件。为了避免这种情况,可以在使用locate之前,先使用updatedb命令,手动更新数据库。- 命令格式:
locate [选择参数] [样式] - 命令参数:
-e:将排除在寻找的范围之外-1:如果是1则启动安全模式,在安全模式下,使用者不会看到权限无法看到的档案。这会使速度减慢,因为locate必须至实际的档案系统中取得档案的权限资料-f:将特定的档案系统排除在外,例如我们没有到必要把proc档案系统中的档案放在资料库中-q:安静模式,不会显示任何错误讯息-n:至多显示 n个输出-r:使用正规运算式 做寻找的条件-o:指定资料库存的名称-d:指定资料库的路径-h:显示辅助讯息-V:显示程式的版本讯息
whereis命令
whereis命令是定位可执行文件、源代码文件、帮助文件在文件系统中的位置。这些文件的属性应属于原始代码,二进制文件,或是帮助文件。whereis程序还具有搜索源代码、指定备用搜索路径和搜索不寻常项的能力。whereis命令只能用于程序名的搜索,而且只搜索二进制文件(参数-b)、man说明文件(参数-m)和源代码文件(参数-s)。如果省略参数,则返回所有信息。- 命令格式:
whereis [-bmsu] [BMS 目录名 -f ] 文件名 - 主要参数:
-b:定位可执行文件-m:定位帮助文件-s:定位源代码文件-u:搜索默认路径下除可执行文件、源代码文件、帮助文件以外的其它文件-B:指定搜索可执行文件的路径-M:指定搜索帮助文件的路径-S:指定搜索源代码文件的路径
which命令
which指令会在PATH变量指定的路径中,搜索某个系统命令的位置,并且返回第一个搜索结果。which是根据使用者所配置的PATH变量内的目录去搜寻可运行档的,所以,不同的PATH配置内容所找到的命令是不一样的。- 命令格式:
which 可执行文件名称 - 命令参数:
-n:指定文件名长度,指定的长度必须大于或等于所有文件中最长的文件名-p:与-n参数相同,但此处的包括了文件的路径-w:指定输出时栏位的宽度-V:显示版本信息
find、locate、which、whereis的区别
- which (寻找执行档) :这个指令是根据PATH这个环境变量所规范的路径,去搜寻执行档的档名,所以,重点是找出执行档而已,which 后面接的是完整档名
- whereis (寻找特定档案):搜寻linux数据库档案中所记录的东西,和locate的主要区别在于后面的参数
- locate:搜寻linux数据库档案中所记录的东西,后面直接跟档案的部分名称就行
- find:直接搜索整个硬盘
sort命令
- 将文本文件内容加以排序。可针对文本文件的内容,以行为单位来排序。
- 参数:
- m:将几个排序好的文件进行合并。
- n:依照数值的大小排序
- Linux Bash中,ls . | sort 命令的功能是(显示当前目录内容并排序)
du命令
- 显示目录或文件的大小。du会显示指定的目录或文件所占用的磁盘空间。
- 参数:
- a:显示目录中个别文件的大小。
- b:显示目录或文件大小时,以byte为单位。
- c: 除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和
ls命令
- 显示指定工作目录下之内容(列出目前工作目录所含之档案及子目录)。
- 参数:
- a:显示所有档案及目录
- A:同 -a ,但不列出 "." (目前目录) 及 ".." (父目录)
- t:将档案依建立时间之先后次序列出
- 列出目前工作目录下所有档案及目录;目录于名称后加 "/", 可执行档于名称后加 "*" : ls -AF
- Linux Bash中,把ls命令显示当前目录的结果存入ls.txt的命令输出重定向命令是(ls > ls.txt)
vi、 gcc、gdb、make的使用
Vim六种模式
1. **普通模式(Normal mode)**:在普通模式中,用的编辑器命令,比如移动光标,删除文本等等。这也是Vim启动后的默认模式。在普通模式中,进入插入模式比较普通的方式是按a(append/追加)键或者i(insert/插入)键。
2. **插入模式(Insert mode)**:在插入模式中,可以按ESC键回到普通模式。
3. 可视模式(Visual mode):命令多与字母v有关,移动命令会扩大高亮的文本区域。高亮区域可以是字符、行或者是一块文本。
4. 选择模式(Select mode):这个模式中,可以用鼠标或者光标键高亮选择文本,不过输入任何字符的话,Vim会用这个字符替换选择的高亮文本块,并且自动进入插入模式。
5. **命令行模式(Command line mode)**:在命令行模式中,执行命令(:键),搜索(/和?键)或者过滤命令(!键)。在命令执行之后,Vim返回到命令行模式之前的模式,通常是普通模式。
6. Ex模式(Ex mode):这和命令行模式比较相似,在使用:visual命令离开Ex模式前,可以一次执行多条命令。
Vim常用命令总结
-
插入:
i:在当前光标处进行编辑a:在光标后插入编辑
-
退出:
q!:强制退出,不保存:q:退出:wq!:强制保存并退出:wq:保存并退出:w <文件路径>:另存为
-
删除:
x:删除游标所在的字符dd:删除整行
-
行间跳转:
nG(n Shift+g):光标移动到第n行
-
复制与粘贴:
nyy:复制光标所在及其后的整行共n行p:代表粘贴至光标后
-
功能设定:
:set autoindent(ai):设置自动缩进:set cindent(cin):设置C语言风格缩进:set nu:以显示行号
GCC编译过程
- 预处理:gcc –E hello.c –o hello.i ;gcc –E调用cpp 产生预处理过的C原始程序
- 编译:gcc –S hello.i –o hello.s ;gcc –S调用ccl 产生汇编语言原始程序
- 汇编:gcc –c hello.s –o hello.o ;gcc -c 调用as 产生目标文件
链 接:gcc hello.o –o hello ;gcc -o 调用ld 产生可执行文件 - 运行: ./hello
静态库
- 静态库是一系列的目标文件(.o文件)的归档文件((lib+name).a文 件);链接阶段,选择静态库,后缀名为“.a”;选择动态库,后缀名为“.so”。
- 静态链接库的生成:
gcc -c 文件名.c ar rcsv libxxx.a xxx.o - 静态库的使用:
gcc -o 文件名 文件名.c -L. -lxxx//链接到静态库 - 注意:
-L:在库文件的搜索路径列表中添加dir目录-l:在头文件的搜索路径列表中添加dir目录
共享库
- 共享库的生成:
gcc -fPIC -c xxx.cgcc -shared -o libxxx.so xxx.o
- 共享库的使用:
gcc -o main main.c -L. -lxxx - 注册共享库的方法:将库文件直接复制到/lib或者/usr/lib目录下:
cp (lib+name).so /lib
GDB调试
-
进入gdb:
gcc -g xxx.c -o xxxgdb xxx
-
查看源码:
(gdb) l:进行行号提示(gdb) b n:在第n行设置断点(gdb) r:运行代码,运行至断点处(gdb) n:单步运行(gdb) c:使程序继续往下运行,直到再次遇到断点或程序结束(gdb) q:退出GDB(gdb) watch n:在"n"设置了观察点,观察变量的变化情况
-
四种断点:
- 函数断点:
b 函数名 条件表达式 - 行断点:
b 行数或函数名 条件表达式 - 条件断点:
b 行数或函数名 if表达式 - 临时断点:
tbreak 行数或函数名 条件表达式
- 函数断点:
makefile
- 功能:识别文件代码是否更新,减少编译工作量
- 格式为:
- 目标体:依赖文件
- [tab键]各目标体运行命令
- 目标体:由make创建,通常是目标文件或可执行文件
- 依赖文件:创建目标体所依赖的文件
- 运行命令:创建每个目标体时需要的运行命令,必须以tab键开头。
- 使用make的格式:make 目标体
收获
- 学习了Linux系统相关命令,学会了用命令行去对计算机进行操作,这一点对我来说意义是巨大的。在我看来,命令行其实是一门很深的学问,有句老话是这么说的,“图形用户界面让简单的任务容易执行,命令行界面则让艰难的任务可能执行。”另外使用命令行最大的一个好处就是:它是一个持久的技巧。不像很多其它几个月就发生变化的计算机技巧,命令行具有持久力,很可能今天学的内容10年之后仍然是相关的。或许使用命令行的过程中有些枯燥无味,但是学习它所花费的精力会是一段美好时光,因为它让Linux环境变得更加强大实用。
- 站在全局的角度,重新理解了计算机系统。这个学期深入理解计算机系统的学习更像是把之前两年所学的知识重新串联了一遍,重新复习了计算机导论、汇编、c语言的相关知识,在复习旧的知识同时,又掌握了许多新的知识和技巧,感觉自己对知识的理解有了更深的认识。
- 提高了自己主动去寻找答案的能力,在学习Linux命令的时候,娄老师就强调man、cheat、find......这一系列帮助文档、查找工具的重要性。就像百度一样,在Linux中,有问题就可以去找man,查找东西可以locate,某个命令的man看不懂还可以cheat,尽量通过自己的搜索一步步的解决问题,而不是不动脑子的照搬。主动去搜索自己想要解决的问题确实要比问别人要快的多,记得也更加深刻,最重要的是能极大的提高自己的自信!
不足
- 对于学习的很多内容没有复习,只是学一遍,印象并不深刻,可能放下书之后就忘了所学的内容,没有做到反复阅读教材,所以理解还只是很浅层,虽然很多有之前课程的基础,还不至于看不懂,但是至于更深入的部分,也不能熟练掌握。
- 有的时候内心还是有点浮躁,没有做到能真正静下心来学习,总是有些急于求成。当然,这其中很大一部分原因要归结于自己没有把时间分配好,学习的时间不够,就恨不得一口吃成个胖子,虽然后来在老师的提醒下发现了这个问题,自己也有所改善,但是还是有继续改进的空间,学习应该是一个循序渐进由浅入深的过程,千万不能囫囵吞枣!
课程建议和意见
- 目前教材里面还是有一部分内容比较难理解,可能自己有的时候能看懂,但是想要深入去理解还是有一定的难度。希望老师上课可以多讲一些这方面的内容,可以多鼓励大家去提出每章的重点和难点,等到上课的时候再集中讲解一下,我想这样大家可能学的也会更透彻一些。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 0/0 | 1/2 | 25/45 | 学习了几个Linux核心命令 |
| 第二周 | 55/55 | 2/4 | 27/72 | 学会了vim,gcc以及gdb的基本操作 |
| 第三周 | 148/203 | 1/5 | 23/95 | 对信息的表示和处理有更深入的理解 |
| 第五周 | 72/275 | 1/6 | 25/120 | 对汇编语言有了更深的理解 |
| 第六周 | 56/331 | 2/8 | 30/150 | 安装了Y86模拟器 |
| 第七周 | 61/392 | 1/9 | 22/172 | 理解了局部性原理和缓存思想在存储层次结构中的应用 |
| 第八周 | 0/392 | 1/10 | 20/192 | 复习前几章内容 |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架