


1 数据库基础
一、数据库与数据库管理系统
1.数据库(DB):存放数据的仓库,从广义来说,数据不仅包括数字,还包括了文本、图像、音频、视频。
2.数据库管理系统
数据库管理系统(DBMS)是管理数据库的系统,它按一定的数据模型组织数据。DBMS应提供如下功能:
●数据定义功能可定义数据库中的数据对象。
●数据操纵功能可对数据库表进行基本操作,如插入、删除、修改、查询。
●数据的完整性检查功能保证用户输入的数据满足相应的约束条件。
●数据库的安全保护功能保证只有赋予权限的用户才能访问数据库中的数据。
●数据库的并发控制功能使多个应用程序可在同一时刻并发地访问数据库的数据。
●数据库的故障恢复功能使数据库运行出现故障时进行数据库恢复,以保证数据库可靠运行。
●在网络环境下访问数据库的功能。
●方便、有效地存取数据库信息的接口和工具。编程人员通过程序开发工具与数据库的接口编写数据库应用程序。
数据库管理员(DBA,DataBase Adminitrator)通过提供的工具对数据库进行管理。
二、关系型数据库管理系统
数据、数据库、数据库管理系统与操作数据库的应用程序,加上支撑它们的硬件平台、软件平台及与数据库有关的人员,构成了一个完整的数据库系统。图描述了数据库系统的构成。

学生表
|
学 号 |
姓 名 |
性别 |
出生时间 |
专 业 |
总学分 |
备 注 |
|
081101 |
王林 |
男 |
1990-2-10 |
计算机 |
50 |
|
|
081102 |
程明 |
男 |
1991-2-1 |
计算机 |
50 |
|
|
081103 |
王燕 |
女 |
1989-10-6 |
计算机 |
50 |
|
|
081104 |
韦严平 |
男 |
1990-8-26 |
计算机 |
50 |
|
|
081106 |
李方方 |
男 |
1990-11-20 |
计算机 |
50 |
|
|
081107 |
李明 |
男 |
1990-5-1 |
计算机 |
54 |
提前修完《数据结构》,并获学分 |
|
081108 |
林一帆 |
男 |
1989-8-5 |
计算机 |
52 |
已提前修完一门课 |
|
081109 |
张强民 |
男 |
1989-8-11 |
计算机 |
50 |
|
|
081110 |
张蔚 |
女 |
1991-7-22 |
计算机 |
50 |
三好学生 |
|
081111 |
赵琳 |
女 |
1990-3-18 |
计算机 |
50 |
|
|
081113 |
严红 |
女 |
1989-8-11 |
计算机 |
48 |
有一门课不及格,待补考 |
|
081201 |
王敏 |
男 |
1989-6-10 |
通信工程 |
42 |
|
|
081202 |
王林 |
男 |
1989-1-29 |
通信工程 |
40 |
有一门课不及格,待补考 |
|
081203 |
王玉民 |
男 |
1990-3-26 |
通信工程 |
42 |
|
|
081204 |
马琳琳 |
女 |
1989-2-10 |
通信工程 |
42 |
|
|
081206 |
李计 |
男 |
1989-9-20 |
通信工程 |
42 |
|
|
081210 |
李红庆 |
男 |
1989-5-1 |
通信工程 |
44 |
已提前修完一门课,并获学分 |
|
081216 |
孙祥欣 |
男 |
1989-3-19 |
通信工程 |
42 |
|
|
081218 |
孙研 |
男 |
1990-10-9 |
通信工程 |
42 |
|
|
081220 |
吴薇华 |
女 |
1990-3-18 |
通信工程 |
42 |
|
|
081221 |
刘燕敏 |
女 |
1989-11-12 |
通信工程 |
42 |
|
|
081241 |
罗林琳 |
女 |
1990-1-30 |
通信工程 |
50 |
转专业学习 |
课程表
|
课 程 号 |
课 程 名 |
开 课 学 期 |
学 时 |
学 分 |
|
101 |
计算机基础 |
1 |
80 |
5 |
|
102 |
程序设计与语言 |
2 |
68 |
4 |
|
206 |
离散数学 |
4 |
68 |
4 |
|
208 |
数据结构 |
5 |
68 |
4 |
|
210 |
计算机原理 |
5 |
85 |
5 |
|
209 |
操作系统 |
6 |
68 |
4 |
|
212 |
数据库原理 |
7 |
68 |
4 |
|
301 |
计算机网络 |
7 |
51 |
3 |
|
302 |
软件工程 |
7 |
51 |
3 |
成绩表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | 表7.3 成绩表学 号 课程号 成 绩 学 号 课程号 成 绩 学 号 课程号 成 绩081101 101 80 081107 101 78 081111 206 76081101 102 78 081107 102 80 081113 101 63081101 206 76 081107 206 68 081113 102 79081103 101 62 081108 101 85 081113 206 60081103 102 70 081108 102 64 081201 101 80081103 206 81 081108 206 87 081202 101 65081104 101 90 081109 101 66 081203 101 87081104 102 84 081109 102 83 081204 101 91081104 206 65 081109 206 70 081210 101 76081102 102 78 081110 101 95 081216 101 81081102 206 78 081110 102 90 081218 101 70081106 101 65 081110 206 89 081220 101 82081106 102 71 081111 101 91 081221 101 76081106 206 80 081111 102 70 081241 101 90 |
码:在关系表中,如果一个字段或几个字段组合的值可唯一标志其对应的记录,则字段或字段组合为码
“学生”表涉及的主要信息有:学号、姓名、性别、出生时间、专业、总学分、备注
“课程”表涉及的主要信息有:课程号、课程名、开课学期、学时和学分
“成绩”表涉及的主要信息有:学号、课程号和成绩
三、关系型数据库语言
2.MySQL数据库简介
一、MySQL数据库介绍
MySQL数据库的特点主要有以下几个方面:
●使用核心线程的完全多线程服务,这意味着可以采用多CPU体系结构。
●可运行在不同平台。
●使用C和C++语言编写,并使用多种编译器进行测试,保证了源代码的可移植性。
●支持AIX、FreeBSD、HP-UX、Linux、Mac OS、Novell Netware、OpenBSD、OS/2 Wrap、Solaris、Windows等多种操作系统。
●为多种编程语言提供了API。这些编程语言包括C、C++、Eiffel、Java、Perl、PHP、Python、Ruby和Tcl等。
●支持多线程,充分利用CPU资源。
●优化的SQL查询算法,可有效地提高查询速度。
●既能够作为一个单独的应用程序应用在客户端服务器网络环境中,也能够作为一个库嵌入其他的软件中。提供多语言支持,常见的编码如中文的GB2312、BIG5,
日文的Shift_JIS等,都可以用做数据表名和数据列名。
●提供TCP/IP、ODBC和JDBC等多种数据库连接途径。
●提供可用于管理、检查、优化数据库操作的管理工具。
●可以处理拥有上千万条记录的大型数据库。
二、MySQL服务器的安装与配置
可以从http://dev.mysql.com/downjloads/mysql/5.1thml免费下载
MySQL服务器的安装:
(1)下载Windows版的MySQL,双击下载文件进入安装向导。有3种安装方式可供选择:Typical(典型安装)、Complete(完全安装)和Custom(定制安装),如图7.2所示。
对于大多数用户,选择Typical就可以了。单击【Next】按钮进入下一步。

(2)进入如图7.3所示的安装界面。在MySQL 5.1中,数据库主目录和文件目录是分开的。其中,“Destination Folder”为MySQL所在的主目录,
默认为C:\Program Files\MySQL\MySQL Server 5.1。
“Data Folder”为MySQL数据库文件和表文件所在的目录,默认为C:\Documents and Settings\All Users\Application Data\MySQL\MySQL Server 5.1\data,
其中Application Data是隐藏文件夹。确认后单击【Install】按钮开始安装。

(3)等待一段时间后安装完成,在弹出的窗口中单击【Next】按钮完成安装
MySQL服务器的配置:
(1)安装完毕后选择“Configure the MySQL server now”复选框,单击【Finish】按钮进入配置向导。
单击【Next】按钮进入选择配置类型对话框,配置类型有2种:Detailed Configuration(详细配置)和Standard Configuration(标准配置)。
标准配置选项适合想要快速启动MySQL而不必考虑服务器配置的新用户。详细配置选项适合想要更加细粒度控制服务器配置的高级用户。本书选择Detailed Configuration选项。
(2)单击【Next】按钮进行服务器类型选择,分为3种:Developer Machine(开发机器)、Server Machine(服务器)
和Dedicated MySQL Server Machine(专用MySQL服务器)。本书选择Developer Machine选项。
(3)单击【Next】按钮进入数据库使用情况对话框,有3个选项:
Multifunctional Database(多功能数据库)
Transactional Database Only(只是事务处理数据库)
Non-Transactional Database Only(只是非事务处理数据库)。其中多功能数据库对InnoDB和MyISAM表都适用,所以本书选择Multifunctional Database选项。
(4)单击【Next】按钮进入InnoDB表空间对话框,这里可以修改InnoDB表空间文件的位置,如图7.4所示。默认位置是MySQL服务器数据目录,这里不做修改。

5)进入并发连接选择对话框。
Decision Support (DSS)/OLAP(决策支持):如果服务器不需要大量的并行连接可以选择该选项;
Online Transaction Processing(OLTP,联机事务处理):如果服务器需要大量的并行连接则选择该选项;
Manual Setting(人工设置):选择该选项可以手动设置服务器并行连接的最大数目。本书选择Decision Support (DSS)/OLAP选项。
(6)进入联网选项对话框,如图7.5所示。默认情况是启用TCP/IP网络,默认端口为3306。这里不做修改。

(7) 进入字符集选择对话框,前面的选项一直是按默认设置进行的,这里要做一些修改。选中“Manual Selected Default Character Set/Collation”选项,
在“Character Set”选框中将latin1修改为gb2312,如图7.6所示。

(8)单击【Next】按钮进入服务选项对话框,服务名为MySQL,这里不做修改。
(9)单击【Next】按钮进入安全选项对话框,如图7.7所示,在密码输入框中输入root用户的密码,为了便于演示,此处密码设为“123456”。
在实际应用时密码不可过于简单。要想创建一个匿名用户账户,选中“Create An Anonymous Account”(创建匿名账户)选项旁边的框。由于安全原因,不建议选择该项

(10)设置完毕后,最后一步是提交配置,单击【Execute】按钮即可完成。
注意:对不同的操作系统和不同版本的MySQL,安装过程可能有所不同,这里只举MySQL 5.1的安装例子。
三、MYSQL的环境
1.mysql命令行客户端
MySQL安装和配置完后,打开“开始”→“程序”→“MySQL”→“MySQL Server 5.1”→“MySQL Command Line Client”菜单项,
进入MySQL客户端,在客户端输入密码,就以root用户身份登录到MySQL服务器,在窗口中出现如图7.8所示的命令行,在命令行中输入SQL语句就可以操作MySQL数据库。
以root用户身份登录可以对数据库进行所有的操作。

2.重新配置服务器
如果要对服务器重新配置,可以打开“开始”→“程序”→“MySQL”→“MySQL Server 5.1”→“MySQL Server Instance Configure Wizard”菜单项,
在出现的配置向导中重新配置服务器
3.选项文件
在C:\Program Files\MySQL\MySQL Server 5.1的MySQL主目录下有一个my.ini文件,这是MySQL的选项文件,
MySQL启动时会自动加载该文件中的一些选项。可以通过修改选项文件来修改MySQL的一些默认设置
4. 数据目录
MySQL有一个数据目录,用于存放数据库文件。在MySQL 5.1中,数据目录的默认路径为C:\Documents and Settings\All Users\Application Data
\MySQL\MySQL Server 5.1\data。在data目录中MySQL为每个数据库建立一个文件夹,所有的表文件存放在相应的数据库文件夹中。
3.MYSQL基础知识
一、mysql数据库对象
1.表
2.视图
视图是从一个或多个基本表中引出的表,数据库中只存放视图的定义,而不存放视图对应的数据,这些数据仍存放在导出视图的基本表中。
视图一经定义,就可以像基本表一样被查询、修改、删除和更新。
3.索引
它是对数据表中的一列或多列的数据进行排序的一种结构。
4.约束
约束机制保障了MySQL中数据的一致性与完整性,具有代表性的约束就是主键和外键
5.存储过程
存储过程是一组完成特定功能的SQL语句集合
6.触发器
触发器是一个被指定关联到一个表的数据库对象,触发器是不需要调用的,当对一个表的特别事件出现时,它会被激活。触发器的代码是由SQL语句组成的
7.存储函数
存储函数与存储过程类似,也是由SQL和过程式语句组成的代码片段,并且可以从应用程序和SQL中调用。但存储函数不能拥有输出参数,
因为存储函数本身就是输出参数。存储函数必须包含一条RETURN语句,从而返回一个结果
8.事件
事件与触发器类似,都是在某些事情发生时启动。不同的是触发器是在数据库上启动一条语句时被激活,而事件是在相应的时刻被激活。
二、MYSQL表结构
空值(NULL)通常表示未知、不可用或将在以后添加的数据。若某列允许为空值,则向表中输入记录值时可不为该列给出具体值。
而某列若不允许为空值,则在输入时必须给出具体值。
关键字。若表中记录的某一字段或字段组合能唯一标志记录,则称该字段或字段组合为候选关键字(Candidate key)。
若表中有多个候选关键字,则选定其中一个为主关键字(Primary key),也称为主键。
三、MYSQL数据类型

精度:存储十进制数据的总位数
小数位数。指数值数据中小数点右边可以有的数字位数的最大值。例如,数值数据3560.697的精度是7,小数位数是3。
长度。指存储数据所使用的字节数。
1.整数型
BIGINT。大整数,数值范围为-263 (-9 223 372 036 854 775 808)~263-1(9 223 372 036 854 775 807),其精度为19,小数位数为0,长度为8字节。
INTEGER(简写为INT)。整数,数值范围为-231(-2 147 483 648)~231-1(2 147 483 647),其精度为10,小数位数为0,长度为4字节。
MEDIUMINT。中等长度整数,数值范围为-223(-8 388 608)~223-1(8 388 607),其精度为7,小数位数为0,长度为3字节。
SMALLINT。短整数,数值范围为-215(-32 768)~215-1(32 767),其精度为5,小数位数为0,长度为2字节。
TINYINT。微短整数,数值范围为-27(-128)~27-1(127),其精度为3,小数位数为0,长度为1字节。
2. 精确数值型
精确数值型由整数部分和小数部分构成,其所有的数字都是有效位,能够以完整的精度存储十进制数。
精确数值型包括decimal、numeric两类。从功能上说两者完全等价,两者的唯一区别在于decimal不能用于带有identity关键字的列。
声明精确数值型数据的格式是numeric | decimal(p[,s]),其中p为精度,s为小数位数,s的默认值为0。例如,指定某列为精确数值型,精度为6,小数位数为3,
即decimal(6,3),那么若向某记录的该列赋值56.342 689时,该列实际存储的是56.3 427。
3. 浮点型
这种类型不能提供精确表示数据的精度。使用这种类型来存储某些数值时,有可能会损失一些精度,
所以它可用于处理取值范围非常大且对精确度要求不是十分高的数值量,如一些统计量。
4. 位型
位字段类型,表示如下:
BIT[(M)]
其中,m表示位值的位数,范围为1~64。如果省略m,默认为1。
5. 字符型
字符型数据用于存储字符串,字符串中可包括字母、数字和其他特殊符号(如#、@、&等)。
在输入字符串时,需将串中的符号用单引号或双引号括起来,如'abc'、"Abc<Cde"。
MySQL字符型包括固定长度(char)和可变长度(varchar)字符数据类型。
6. 文本型
当需要存储大量的字符数据,如较长的备注、日志信息等,字符型数据的最长65 535个字符的限制可能使它们不能满足应用需求,此时可使用文本型数据。
文本型数据对应ASCII字符,其数据的存储长度为实际字符数个字节。
文本型数据可分为4种:TINYTEXT、TEXT、MEDIUMTEXT和LONGTEXT。
表列出了各种文本数据类型的最大字符数。

7. BINARY和VARBINARY型
BINARY和VARBINARY类型数据类似于CHAR和VARCHAR,不同的是它们包含的是二进制字符串,而不是非二进制字符串。
也就是说,它们包含的是字节字符串,而不是字符字符串。这说明它们没有字符集,并且排序和比较基于列值字节的数值。
●BINARY [(N)]。固定长度的N字节二进制数据。N取值范围为1~255,默认为1。
BINARY(N)数据的存储长度为N+4字节。若输入的数据长度小于N,则不足部分用0填充;若输入的数据长度大于N,则多余部分被截断。
输入二进制值时,在数据前面要加上0x,可以用的数字符号为0~9、A~F(字母大小写均可)。例如,0xFF、0x12A0分别表示十六进制的FF和12A0。因为每字节的
数最大为FF,故在“0x”格式的数据每两位占1字节。
●VARBINARY[(N)]。N字节变长二进制数据。N取值范围为1~65535,默认为1。VARBINARY(N)数据的存储长度为实际输入数据长度+4字节。
8. BLOB类型
在数据库中,对于数码照片、视频和扫描的文档等的存储是必须的,MySQL可以通过BLOB数据类型来存储这些数据。
BLOB是一个二进制大对象,可以容纳可变数量的数据。有4种BLOB类型:TINYBLOB、BLOB、MEDIUMBLOB和LONGBLOB。
这4种BLOB数据类型的最大长度对应于4种TEXT数据类型:TINYTEXT、TEXT、MEDIUMTEXT和LONGTEXT。不同的是BLOB表示的是最大字节长度,
而TEXT表示的是最大字符长度
9.日期时间类型
DATE。date数据类型由年份、月份和日期组成,代表一个实际存在的日期。DATE的使用格式为字符形式'YYYY-MM-DD‘
TIME。TIME数据类型代表一天中的一个时间,由小时数、分钟数、秒数和微秒数组成。
格式为'HH:MM:SS.fraction',其中fraction为微秒部分,是一个6位的数字,可以省略。
TIME值必须是一个有意义的时间,例如'10:08:34'表示10点08分34秒,而'10:98:10'是不合法的,它将变成'00:00:00'。
DATETIME,TIMESTAMP。DATETIME和TIMESTAMP数据类型是日期和时间的组合,日期和时间之间用空格隔开,如'2008-10-20 10:53:20'。
YEAR。YEAR用来记录年份值。MySQL以YYYY格式检索和显示YEAR值,范围是1901~2155。
10.ENUM和SET类型
ENUM和SET是比较特殊的字符串数据列类型,它们的取值范围是一个预先定义好的列表。ENUM或SET数据列的取值只能从这个列表中进行选择。
ENUM和SET的主要区别是:ENUM只能取单值,它的数据列表是一个枚举集合。ENUM的合法取值列表最多允许有65535个成员。
例如,ENUM("N", "Y")表示该数据列的取值要么是“Y”,要么是“N”。SET可取多值。它的合法取值列表最多允许有64个成员。空字符串也是一个合法的SET值。
4.数据库和表的建立与管理
一、创建数据库
1.创建数据库
说明:“[ ]”中内容为可选项
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name
例如:CREATE DATABASE PXSCJ;
注意每条sql语句都以;结束。
2.删除数据库
DROP DATABASE [IF EXISTS] db_name
二、创建表
1.表结构设计
2.创建表
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
(
<列名1> <数据类型> [<列选项>],
<列名2> <数据类型> [<列选项>],
…
<表选项>
)
●TEMPORARY。该关键字表示用CREATE命令新建的表为临时表。不加该关键字创建的表通常称为持久表,在数据库中持久表一旦创建将一直存在,
多个用户或者多个应用程序可以同时使用持久表。有时需要临时存放数据,例如,临时存储复杂的SELECT语句的结果。
此后,可能要重复地使用这个结果,但这个结果又不需要永久保存。这时,可以使用临时表。用户可以像操作持久表一样操作临时表。
只不过临时表的生命周期较短,而且只能对创建它的用户可见,当断开与该数据库的连接时,MySQL会自动删除它们。
●列选项。列选项主要有以下几种:
NULL或NOT NULL:表示一列是否允许为空,NULL表示可以为空,NOT NULL表示不可以为空,如果不指定,则默认为NULL。
DEFAULT default_value:为列指定默认值,默认值default_value必须为一个常量。
AUTO_INCREMENT:设置自增属性,只有整型列才能设置此属性。当插入NULL值或0到一个AUTO_INCREMENT列中时,列被设置为value+1,
value是此前表中该列的最大值。AUTO_INCREMENT顺序从1开始。每个表只能有一个AUTO_INCREMENT列,并且它必须被索引。
UNIQUE KEY | PRIMARY KEY:UNIQUE KEY和PRIMARY KEY都表示字段中的值是唯一的。PRIMARY KEY表示设置为主键,一个表只能定义一个主键,
主键必须为NOT NULL。
COMMENT 'string':对于列的描述,string是描述的内容。
例7.2
使用命令行方式在PXSCJ数据库中创建学生管理系统中的三个表XSB、KCB和CJB。表的结构参照表7.6、表7.7和表7.8。
创建XSB表使用如下语句:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | USE PXSCJ;CREATE TABLE XSB(学号 CHAR(6) NOT NULL PRIMARY KEY,姓名 CHAR(8) NOT NULL,性别 TINYINT(1) NULL DEFAULT 1,出生时间DATE NULL,专业 CHAR(12) NULL,总学分 INT(4) NULL DEFAULT 0,备注 TEXT NULL); |
创建KCB表使用如下语句
1 2 3 4 5 6 7 8 9 10 | USE PXSCJ;CREATE TABLE KCB( 课程号 CHAR(3) NOT NULL PRIMARY KEY, 课程名 CHAR(16) NOT NULL, 开课学期 TINYINT(1) NULL DEFAULT 1, 学时 TINYINT(1) NULL, 学分 TINYINT(1) NOT NULL); 创建CJB表使用如下语句 |
1 2 3 4 5 6 7 8 | USE PXSCJ;CREATE TABLE CJB( 学号 CHAR(6) NOT NULL, 课程号 CHAR(3) NOT NULL, 成绩 INT(4) NULL, PRIMARY KEY(学号,课程号)); |
三、修改表
ALTER TABLE table_name
ADD <列名> <数据类型> <列选项> /*添加列*/
| ALTER <列名> {SET DEFAULT default_value | DROP DEFAULT} /*修改默认值*/
| CHANGE <旧列名> <新列名> <数据类型> <列选项> /*对列重命名*/
| MODIFY <列名> <数据类型> <列选项> /*修改列类型*/
| DROP <列名> /*删除列*/
| RENAME <新表名> /*重命名该表*/
| 其他
注意:
1 | 若表中该列所存数据的数据类型与将要修改的列的类型冲突,则发生错误。 |
1 | 例如,原来CHAR类型的列要修改成INT类型,而原来列值中有字符型数据“a”,则无法修改。 |
1 | 例7.3 假设已经在数据库PXSCJ中创建了表XSB,表中存在“姓名”列。在表XSB中增加“奖学金等级”列,并将表中的“姓名”列删除 |
1 2 3 4 | USE PXSCJALTER TABLE XSB ADD 奖学金等级 TINYINT NULL, DROP 姓名; |
四、删除表
1 | 删除一个表可以使用DROP TABLE语句。语法格式如下: |
Drop [TEMPORARY] TABLE [IF EXISTS] tbl_name [, tbl_name] ...
例如,删除XSB表可以使用如下语句
1 2 | USE PXSCJ;DROP TABLE XSB; |
1 | 5.表数据操作 |
一、插入表数据
INSERT语句的基本格式如下:
INSERT [INTO] tbl_name [(col_name,...)]
VALUES ({expr | DEFAULT},...),(...),...
●tbl_name。被操作的表名。
●col_name。需要插入数据的列名。如果要给全部列插入数据,列名可以省略。如果只给表的部分列插入数据,需要指定这些列。
对于没有指出的列,它们的值根据列默认值或有关属性来确定。
●VALUES子句。包含各列需要插入的数据清单,数据的顺序要与列的顺序相对应。
若tb1_name后不给出列名,则在VALUES子句中要给出每列的值,如果列值为空,则值必须置为NULL,否则会出错。VALUES子句中的值如下:
expr:可以是一个常量、变量或一个表达式,也可以是空值NULL,其值的数据类型要与列的数据类型一致。
例如,列的数据类型为INT,插入数据“aa”时就会出错。当数据为字符型时要用单引号括起。
DEFAULT:指定为该列的默认值。前提是该列之前已经指定了默认值。
如果列清单和VALUES清单都为空,则INSERT会创建一行,每列都设置成默认值。
【例7.4】 向PXSCJ数据库的表XSB(表中列包括学号、姓名、性别、出生时间、专业、总学分、备注)中插入如下的一行:
081101,王林,1,1990-02-10,计算机,50,NULL
使用下列语句:
1 2 3 | USE PXSCJINSERT INTO XSB VALUES('081101', '王林' , 1, '1990-02-10', '计算机', 50, NULL); |
注意:若原有行中存在PRIMARY KEY或UNIQUE KEY,而插入的数据行中含有与原有行中PRIMARY KEY或UNIQUE KEY相同的列值,则INSERT语句无法插入此行。
要插入这行数据需要使用REPLACE语句,REPLACE语句的用法和INSERT语句基本相同。
使用REPLACE语句可以在插入数据之前将与新记录冲突的旧记录删除,从而使新记录能够正常插入
1 |
【例7.6】 若例7.4中的数据行已经插入,其中学号为主键(PRIMARY KEY),现在想再插入如下一行数据:
081101,刘华,1,1991-03-08,通信工程,48,NULL
若使用INSERT语句,执行结果如下:
1 2 | REPLACE INT XSB VALUES('081101','刘华',1,'1991-03-08','通信工程',48,null); |
二、修改表数据
UPDATE tbl_name
SET col_name1=expr1 [, col_name2=expr2 ...]
[WHERE where_definition]
● SET子句。根据WHERE子句中指定的条件对符合条件的数据行进行修改。若语句中不设定WHERE子句,则更新所有行。
col_name1、col_name2为要修改列值的列名,expr1、expr2可以是常量、变量或表达式。可以同时修改所在数据行的多个列值,中间用逗号隔开。
●WHERE子句。通过设定条件确定要修改哪些行,where_definition用于指定条件。
【例7.7】 将PXSCJ数据库的XSB表(数据以表7.1中数据为准)中学号为081101的学生的备注值改为“三好生”
1 2 3 4 | USE PXSCJ;UPDATE XSB SET 备注= '三好生' WHERE 学号='081101'; |
【例7.8】 将XSB表中的所有学生的总学分增加10。
1 2 | UPDATE XSB SET 总学分 = 总学分+10; |
1 | 【例7.9】 将姓名为“罗林琳”的同学的专业改为“软件工程”,备注改为“提前修完学分”,学号改为“081261” |
1 2 3 4 5 | UPDATE XSB SET 专业 = '软件工程', 备注 = '提前修完学分', 学号 = '081261' WHERE 姓名 = '罗林琳'; |
三、删除表数据
删除表中数据一般使用DELETE语句,语法格式如下:
DELETE FROM tbl_name
[WHERE where_definition]
【例7.10】 假设数据库mydata中有一个表table1,table1中有如下数据:
姓名 年龄 职业
张三 42 教师
李四 28 工人
要删除张三的信息可使用如下语句:
1 2 3 | USE mydataDELETE FROM table1 WHERE 姓名='张三'; |
【例7.11】 将PXSCJ数据库的XSB表中总学分小于50的所有行删除,使用如下语句:
1 2 3 | USE PXSCJDELETE FROM XSB WHERE 总学分<50; |
使用TRUNCATE TABLE语句也可以删除表中数据,但是该语句将删除指定表中的所有数据,因此也称为清除表数据语句。
语法格式如下:
TRUNCATE TABLE table_name
6. 查询数据
SELECT语句可以从一个或多个表中选取特定的行和列,结果通常是生成一个临时表。在执行过程中系统根据用户的要求从数据库中选出匹配的行和列,
并将结果存放到临时的表中,SELECT语句的语法格式如下:
SELECT
[ALL | DISTINCT ]
select_expr, ...
[FROM table1 [ , table2] …] /*FROM子句*/
[WHERE where_definition] /*WHERE子句*/
[GROUP BY {col_name | expr | position} [ASC | DESC], ...] /*GROUP BY子句*/
[HAVING where_definition] /*HAVING子句*/
[ORDER BY {col_name | expr | position}[ASC | DESC] , ...] /*ORDER BY子句*/
[LIMIT {[offset,] row_count}] /*LIMIT子句*/
一、选择列
1. 选择指定的列
使用SELECT语句选择表中的某些列,各列名之间要以逗号分隔。
【例7.12】 查询PXSCJ数据库的XSB表中各个同学的姓名、专业和总学分
1 2 3 | USE PXSCJSELECT 姓名,专业,总学分 FROM XSB; |
2. 定义列别名
当希望查询结果中的某些列或所有列显示时且使用自己选择的列标题时,可以在列名之后使用AS子句来指定查询结果的列别名。语法格式为:
SELECT column_name [AS] column_alias
【例7.13】 查询XSB表中计算机系同学的学号、姓名和总学分,结果中各列的标题分别指定为number、name和mark。
1 2 3 4 5 | SELECT 学号 AS number, 姓名 AS name, 总学分 AS mark FROM XSB WHERE 专业= '计算机'; |
查询结果为:

二、选择查询对象
1.引用一个表
可以用两种方式引用一个表,第一种方式是使用USE语句让一个数据库成为当前数据库,在这种情况下,如果在FROM子句中指定表名,则该表应该属于当前数据库。
第二种方式是指定的时候在表名前带上表所属数据库的名字。例如,假设当前数据库是db1,现在要显示数据库db2里的表tb的内容,使用如下语句:
SELECT * FROM db2.tb;
2. 引用多个表
如果要在不同表中查询数据,则必须在FROM子句中指定多个表。指定多个表时要使用到连接。把不同表的数据组合到一个表中叫做表的连接。
例如,在PXSCJ数据库中需要查找选修了离散数学课程的学生的姓名和成绩,就需要将XSB、KCB和CJB三个表进行连接,才能查找到结果。
连接的方式有全连接和JOIN连接两种。
(1)全连接
连接的第一种方式是将各个表用逗号分隔,这样就指定了全连接。FROM子句产生的中间结果是一个新表,是每个表的每行都与其他表中的每行交叉产生的所有可能的
组合,列包含了所有表中出现的列,也就是笛卡儿积。这样连接表潜在地产生数量非常大的行,因为可能得到的行数为每个表中行数之积。在这样的情形下,通常要使
用WHERE子句设定条件来将结果集减小到易于管理的大小。
【例7.14】 查找PXSCJ数据库中所有学生选过的课程名和课程号,使用如下语句:
1 2 3 | SELECT DISTINCT KCB.课程名, CJB.课程号 FROM KCB, CJB WHERE KCB.课程号=CJB.课程号; |

(2)JOIN连接
连接的第二种方式是使用JOIN关键字的连接,JOIN连接主要分为三种:内连接、外连接和交叉连接。
1)内连接。
使用内连接时需要指定INNER JOIN关键字,并使用ON关键字指定连接条件。例如,要使用内连接实现例7.14的查询,可以使用以下语句:
1 2 3 | SELECT DISTINCT 课程名, CJB.课程号 FROM KCB INNER JOIN CJB ON (KCB.课程号=CJB.课程号); |
该语句根据ON关键字后面的连接条件,合并两个表,返回满足条件的行。
内连接是系统默认的,可以省略INNER关键字。使用内连接后,FROM子句中ON条件主要用来连接表,其他并不属于连接表的条件可以使用WHERE子句来指定。
2)外连接。
使用外连接需要指定OUTER JOIN关键字, 外连接包括:
●左外连接(LEFT OUTER JOIN):结果表中除了匹配行外,还包括左表有的但右表中不匹配的行,对于这样的行,从右表被选择的列设置为NULL。
●右外连接(RIGHT OUTER JOIN):结果表中除了匹配行外,还包括右表有的但左表中不匹配的行,对于这样的行,从左表被选择的列设置为NULL。
●自然连接(NATURAL JOIN):自然连接还有自然左外连接(NATURAL LEFT OUTER JOIN)和自然右外连接(NATURAL RIGHT OUTER JOIN)。
NATURAL JOIN的语义定义与使用了ON条件的INNER JOIN相同。
其中的OUTER关键字均可省略。
【例7.15】 查找所有学生情况及他们选修的课程号,如果学生未选修任何课,也要包括其情况。
1 2 3 | SELECT XSB.* , 课程号 FROM XSB LEFT OUTER JOIN CJB ON XSB.学号 = CJB.学号; |
1 |
3)交叉连接。
指定了CROSS JOIN关键字的连接是交叉连接。
不包含连接条件,交叉连接实际上是将两个表进行笛卡儿积运算,结果表是由第一个表的每行与第二个表的每行拼接后形成的表
,因此结果表的行数等于两个表行数之积。
在MySQL中,CROSS JOIN从语法上来说与INNER JOIN等同,两者可以互换。
三、指定查询条件
1. 比较运算
比较运算符用于比较两个表达式的值,MySQL支持的比较运算符有=(等于)、<(小于)、<=(小于等于)、>(大于)、>=(大于等于)、<=>
(相等或都等于空)、<>(不等于)、!=(不等于)。
比较运算的语法格式为:
expression { = | < | <= | > | >= | <=> | <> | != } expression
其中expression是除TEXT和BLOB外类型的表达式。
当两个表达式值均不为空值(NULL)时,除了“<=>”运算符,其他比较运算返回逻辑值TRUE(真)或FALSE(假)。
【例7.16】 查询XSB表中总学分大于50的同学的情况
1 2 3 | SELECT 姓名,学号,出生时间,总学分 FROM XSB WHERE 总学分>50; |

WHERE子句的查询条件还可以将多个判定运算的结果通过逻辑运算符(AND、OR和NOT)再组成更为复杂的查询条件。
NOT表示对判定的结果取反。AND用于组合两个条件,两个条件都为TRUE时值才为TRUE。OR也用于组合两个条件,两个条件有一个条件为TRUE时值就为TRUE。
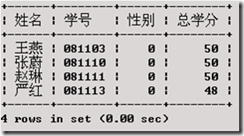
【例7.17】 查询XSB表中专业为计算机,性别为女(0)的同学的情况。
1 2 3 | SELECT 姓名,学号,性别,总学分 FROM XSB WHERE 专业='计算机' AND 性别=0; |
1 | <a href="http://images.cnblogs.com/cnblogs_com/lwcompany/201107/201107200949309610.png"><img style="background-image: none; padding-left: 0; padding-right: 0; display: inline; padding-top: 0; border: 0" title="比罗指定查询条件结果" border="0" alt="比罗指定查询条件结果" src="https://images.cnblogs.com/cnblogs_com/lwcompany/201107/201107200949326414.png" width="244" height="136"></a> |
2. 模式匹配
(1)LIKE运算符
LIKE运算符用于指出一个字符串是否与指定的字符串相匹配,其运算对象可以是char、varchar、text、datetime等类型的数据,返回逻辑值TRUE或FALSE。
使用LIKE进行模式匹配时,常使用特殊符号"_"和"%",即可进行模糊查询。“%”代表0个或多个字符。“_”代表单个字符。
【例7.18】 查询PXSCJ数据库XSB表中姓“王”的学生学号、姓名及性别。
1 2 3 | SELECT 学号,姓名,性别 FROM XSB WHERE 姓名 LIKE '王%'; |

(2)REGEXP运算符
REGEXP运算符用来执行更复杂的字符串比较运算。REGEXP是正则表达式(regular expression)的缩写。和LIKE运算符一样,REGEXP运算符有多种功能,
但它不是SQL标准的一部分,REGEXP运算符的同义词是RLIKE。语法格式如下:
match_expression [ NOT ][ REGEXP | RLIKE ] match_expression
LIKE运算符有两个符号具有特殊的含义:“_”和“%”。而REGEXP运算符则有更多的符号有特殊的含义,参见表

【例7.19】 查询姓李的学生学号、姓名和专业。
1 2 3 4 | SELECT 学号,姓名,专业 FROM XSB WHERE 姓名 REGEXP '^李';查询结果为: |

【例7.20】 查询学号里包含4、5、6的学生学号、姓名和专业。
1 2 3 | SELECT 学号,姓名,专业 FROM XSB WHERE 学号 REGEXP '[4,5,6]'; |
1 |

【例7.21】 查询学号以08开头、08结尾的学生学号、姓名和专业。
1 2 3 | SELECT 学号,姓名,专业 FROM XSB WHERE 学号 REGEXP '^08.*08$'; |

(3)范围比较
用于范围比较的关键字有两个:BETWEEN和IN。
当要查询的条件是某个值的范围时,可以使用BETWEEN关键字。BETWEEN关键字指出查询范围,格式为:
expression [ NOT ] BETWEEN expression1 AND expression2
使用IN关键字可以指定一个值表,值表中列出所有可能的值,当与值表中的任一个匹配时,即返回TRUE,否则返回FALSE。
expression IN ( expression [,…n])
【例7.22】 查询PXSCJ数据库XSB表中不在1989年出生的学生情况。
1 2 3 | SELECT * FROM XSB WHERE 出生时间 NOT BETWEEN '1989-1-1' and '1989-12-31'; |
【例7.23】 查询专业为“计算机”、“通信工程”或“无线电”的学生的情况。
1 2 3 | SELECT * FROM XSB WHERE 专业 IN ('计算机', '通信工程', '无线电'); |
1 | (4)空值比较 |
当需要判定一个表达式的值是否为空值时,使用IS NULL关键字,格式为:
expression IS [ NOT ] NULL
当不使用NOT时,若表达式expression的值为空值,返回TRUE,否则返回FALSE。当使用NOT时,结果刚好相反。
【例7.24】 查询总学分尚不确定的学生情况。
1 2 3 | SELECT * FROM XSB WHERE 总学分 IS NULL; |
(5)子查询
在查询条件中,可以使用另一个查询的结果作为条件的一部分,例如,判定列值是否与某个查询的结果集中的值相等,作为查询条件一部分的
查询称为子查询。SQL标准允许SELECT多层嵌套使用,以表示复杂的查询。子查询除了可以用在SELECT语句中,还可以用在INSERT、
UPDATE及DELETE语句中。子查询通常与IN、EXIST谓词及比较运算符结合使用。
(1)IN子查询
IN子查询用于进行一个给定值是否在子查询结果集中的判断,格式为:
expression [ NOT ] IN ( subquery )
其中subquery是子查询。当表达式expression与子查询subquery的结果表中的某个值相等时,IN谓词返回TRUE,否则返回FALSE;
若使用了NOT,则返回的值刚好相反。
【例7.25】 查找选修了课程号为206的课程的学生姓名、学号
1 2 3 4 5 6 7 | SELECT 姓名,学号 FROM XSB WHERE 学号 IN ( SELECT 学号 FROM CJB WHERE 课程号 = '206' ) ; |

(2)比较查询
这种子查询可以认为是IN子查询的扩展,它使表达式的值与子查询的结果进行比较运算,格式为:
expression { < | <= | = | > | >= | != | <> } { ALL | SOME | ANY } ( subquery )
其中expression为要进行比较的表达式,subquery是子查询。ALL、SOME和ANY说明对比较运算的限制。
ALL指定表达式要与子查询结果集中的每个值进行比较,当表达式与每个值都满足比较的关系时,才返回TRUE,否则返回FALSE。
SOME与ANY是同义词,表示表达式只要与子查询结果集中的某个值满足比较的关系时,就返回TRUE,否则返回FALSE。
【例7.26】 查找选修了离散数学的学生学号。
1 2 3 4 5 6 7 8 | SELECT 学号 FROM CJB WHERE 课程号 = ( SELECT 课程号 FROM KCB WHERE 课程名 ='离散数学' ); |

【例7.27】 查找XSB表中比所有计算机系的学生年龄都大的学生学号、姓名、专业、出生时间。
1 2 3 4 5 6 7 8 | SELECT 学号, 姓名, 专业, 出生时间 FROM XSB WHERE 出生时间 >ALL ( SELECT 出生时间 FROM XSB WHERE 专业='计算机' ); |
(3)exists 子查询
EXISTS谓词用于测试子查询的结果是否为空表,若子查询的结果集不为空,则EXISTS返回TRUE,否则返回FALSE。
EXISTS还可与NOT结合使用,即NOT EXISTS,其返回值与EXISTS刚好相反。格式为:
[ NOT ] EXISTS ( subquery )
【例7.28】 查找选修课程号为206的课程的学生姓名。
1 2 3 4 5 6 7 8 | SELECT 姓名 FROM XSB WHERE EXISTS ( SELECT * FROM CJB WHERE 学号 = XSB.学号 AND 课程号 = '206' ); |

MySQL有4种类型的子查询:
返回一个表的子查询是表子查询;
返回带有一个或多个值的一行的子查询是行子查询;
返回一行或多行,但每行上只有一个值的是列子查询;只返回一个值的是标量子查询。从定义上讲,
每个标量子查询都是一个列子查询和行子查询。上面介绍的子查询都属于列子查询。
另外,子查询还可以用在SELECT语句的其他子句中。
表子查询可以用在FROM子句中,但必须为子查询产生的中间表定义一个别名。
【例7.29】 从XSB表中查找总学分大于50的男同学的姓名和学号
1 2 3 4 5 6 7 | SELECT 姓名,学号,总学分 FROM ( SELECT 姓名,学号,性别,总学分 FROM XSB WHERE 总学分>50 ) AS STUDENT WHERE 性别=1; |
1 | <a href="http://images.cnblogs.com/cnblogs_com/lwcompany/201107/20110720095003603.png"><img style="background-image: none; padding-left: 0; padding-right: 0; display: inline; padding-top: 0; border: 0" title="子查询" border="0" alt="子查询" src="https://images.cnblogs.com/cnblogs_com/lwcompany/201107/201107200950045455.png" width="244" height="116"></a> |
1 |
SELECT关键字后面也可以定义子查询。
【例7.30】 从XSB表中查找所有女学生的姓名、学号和与081101号学生的年龄差距。
1 2 3 4 5 6 7 8 | SELECT 学号, 姓名, YEAR(出生时间)-YEAR ( ( SELECT 出生时间 FROM XSB WHERE 学号='081101' ) ) AS 年龄差距 FROM XSBWHERE 性别=0; |

四、数据分组
数据分组一般用GROUP BY子句完成
1.聚合函数

(1)COUNT函数
最经常使用的聚合函数是COUNT()函数,用于统计组中满足条件的行数或总行数,返回SELECT语句检索到的行中非NULL值的数目
,若找不到匹配的行,则返回0。
语法格式为:
COUNT ( { [ ALL | DISTINCT ] expression } | * )
ALL表示对所有值进行运算,DISTINCT表示除去重复值,默认为ALL。使用COUNT(*)时将返回检索行的总数目,不论其是否包含NULL值
【例7.31】求学生总人数
1 2 | SELECT COUNT(*) AS '学生总数' FROM XSB; |
【例7.32】统计总学分在50以上学生人数
1 2 3 | SELECT COUNT(总学分) AS '总学分50分以上的人数' FROM XSB WHERE 总学分>50; |

(2)MAX和MIN函数
MAX()和MIN()函数分别用于求表达式中所有值项的最大值与最小值,语法格式为:
MAX / MIN ( [ ALL | DISTINCT ] expression )
其中,expression是常量、列、函数或表达式。
【例7.33】 求选修课程号为101的课程的学生的最高分和最低分
1 2 3 | SELECT MAX(成绩), MIN(成绩) FROM CJB WHERE 课程号= '101'; |

(3)SUM函数和AVG函数
SUM()和AVG()函数分别用于求表达式中所有值项的总和与平均值,语法格式为:
SUM / AVG ( [ ALL | DISTINCT ] expression )
【例7.34】 求学号081101的学生所学课程的总成绩。
1 2 3 | SELECT SUM(成绩) AS '课程总成绩' FROM CJB WHERE 学号 = '081101'; |

【例7.35】 求课程号为101的课程的平均成绩
1 2 3 | SELECT AVG(成绩) AS '课程101平均成绩' FROM CJB WHERE 课程号 = '101'; |

2.GROUP BY子句
GROUP BY子句主要用于根据字段对行分组。例如,根据学生所学的专业对XSB表中的所有行分组,结果是每个专业的学生成为一组。
GROUP BY子句的语法格式如下:
GROUP BY {col_name | expr | position} [ASC | DESC], ...
【例7.36】 将PXSCJ数据库中各专业输出。
1 2 3 | SELECT 专业 FROM XSB GROUP BY 专业; |

【例7.37】 求PXSCJ数据库中各专业的学生数。
1 2 3 | SELECT 专业,COUNT(*) AS '学生数' FROM XSB GROUP BY 专业; |

3. HAVING子句
使用HAVING子句的目的与WHERE子句类似,不同的是WHERE子句用在FROM子句之后选择行,而HAVING子句用在GROUP BY子句后选择行。
例如,查找PXSCJ数据库中平均成绩在85分以上的学生,就是在CJB表上按学号分组后筛选出符合平均成绩大于等于85的学生。
【例7.38】 查找平均成绩在85分以上的学生的学号和平均成绩
1 2 3 4 | SELECT 学号, AVG(成绩) AS '平均成绩' FROM CJB GROUP BY 学号 HAVING AVG(成绩) >=85; |

五、排序
order by
六、限制返回行数
LIMIT子句是SELECT语句的最后一个子句,主要用于限制SELECT语句返回的行数。语法格式如下:
LIMIT {[offset,] row_count }
7.视图
1.视图的概念
视图一经定义,就可以像表一样被查询、修改、删除和更新。使用视图有下列优点:
●为用户集中数据,简化用户的数据查询和处理。有时用户所需要的数据分散在多个表中,定义视图可将它们集中在一起,从而方便用户的数据查询和处理。
●屏蔽数据库的复杂性。用户不必了解复杂的数据库中的表结构,并且数据库表的更改也不影响用户对数据库的使用。
●简化用户权限的管理。只需授予用户使用视图的权限,而不必指定用户只能使用表的特定列,增加了安全性。
●便于数据共享。各用户不必都定义和存储自己所需的数据,可共享数据库的数据,这样同样的数据只需存储一次。
可以重新组织数据以便输出到其他应用程序中
2.创建视图
CREATE VIEW view_name [(column_list)]
AS select_statement
●view_name。视图名。
●column_list。为视图的列定义明确的名称,可使用可选的column_list子句,列出由逗号隔开的列名。
column_list中的名称数目必须等于SELECT语句检索的列数。若使用与源表或视图中相同的列名时可以省略column_list。
●select_statement。用来创建视图的SELECT语句,可在SELECT语句中查询多个表或视图。
【例7.43】 创建PXSCJ数据库上的CS_KC视图,包括计算机专业各学生的学号、其选修的课程号及成绩。
1 2 3 4 5 6 | USE PXSCJCREATE VIEW CS_KC AS SELECT XSB.学号,课程号,成绩 FROM XSB, CJB WHERE XSB.学号 = CJB.学号 AND XSB.专业= '计算机'; |
【例7.44】 创建PXSCJ数据库上的计算机专业学生的平均成绩视图CS_KC_AVG,包括学号(在视图中列名为num)和平均成绩(在视图中列名为score_avg)。
1 2 3 4 5 | CREATE VIEW CS_KC_AVG(num, score_avg) AS SELECT 学号,AVG(成绩) FROM CS_KC GROUP BY 学号; |
3.查询视图
【例7.46】 查找平均成绩在80分以上的学生的学号和平均成绩。
本例首先创建学生平均成绩视图XS_KC_AVG,包括学号(在视图中列名为num)和平均成绩(在视图中列名为score_avg)。
创建学生平均成绩视图XS_KC_AVG:
1 2 3 4 5 | CREATE VIEW XS_KC_AVG ( num,score_avg ) AS SELECT 学号, AVG(成绩) FROM CJB GROUP BY 学号; |
1 2 3 4 | 再对XS_KC_AVG视图进行查询。SELECT * FROM XS_KC_AVG WHERE score_avg>=80; |
1 | <a href="http://images.cnblogs.com/cnblogs_com/lwcompany/201107/201107200950397297.png"><img style="background-image: none; padding-left: 0; padding-right: 0; display: inline; padding-top: 0; border: 0" title="view" border="0" alt="view" src="https://images.cnblogs.com/cnblogs_com/lwcompany/201107/201107200950417688.png" width="209" height="207"></a> |
4.删除视图
语法格式如下:
DROP VIEW [IF EXISTS] view_name [, view_name] ...
其中view_name是视图名,声明了IF EXISTS,若视图不存在的话,不会出现错误信息。使用DROP VIEW一次可删除多个视图。例如:
DROP VIEW CS_KC, XS_KC_AVG;
将删除视图CS_KC和XS_KC_AVG。


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧