
2018软工实践结对作业二
2018软工实践结对作业二
队友博客链接:http://www.cnblogs.com/luzeming/p/9769827.html
github地址:https://github.com/Travaill/pair-project/commits/master
具体分工
- 031602328卢泽明:python爬虫学习,负责对2018CVPR爬虫,得到results.txt,博客部分的书写。
- 031602325林燊:负责对WordCount的功能更新,如自定义输入输出文件,权重词频统计,词组统计等新功能
PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Development | 开发 | 420 | 600 |
| Planning | 计划 | 30 | 30 |
| Reporting | 报告 | 50 | 80 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 120 |
| · Code Review | · 代码复审 | 100 | 120 |
| · Coding | · 具体编码 | 100 | 120 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 60 | 240 |
| · Design Review | · 设计复审 | 30 | 120 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| · Test Repor | · 测试报告 | 30 | 60 |
| 合计 | 1660 |
解题思路描述与设计实现说明
-
爬虫使用
-
使用工具:自己手写python脚本
-
使用说明:cmd下键入python Crawer.py 即可,在编译目录下会生成results.txt
-
代码:
base_url = "http://openaccess.thecvf.com/CVPR2018.py" html = urlopen(base_url).read().decode('utf-8') soup = BeautifulSoup(html, features='lxml') paper_link = soup.find_all('a', {'href': re.compile('content_cvpr_2018/html/.*')}) #正则表达式查找所有论文网址 for link in paper_link: url = 'http://openaccess.thecvf.com/'+link['href'] urllist.append(url) #将所有论文链接存到一个list里面 for url in urllist: page = request.Request(url,headers=headers) page_info = request.urlopen(page).read().decode('utf-8') soup1 = BeautifulSoup(page_info, 'html.parser') #解析每个url的源码 papertitle = soup1.find('div', id='papertitle') abstract = soup1.find('div', id='abstract') titles = papertitle.string.strip() abstracts = abstract.string.strip()#将爬取到的文本进行找字符和除换行处理 dic2 = {titles:abstracts}#title和abstract分别存进字典 dic.update(dic2) with open('results.txt','a+',encoding='utf-8') as file: for k,v in dic.items(): file.write(str(num)+'\n'+'Title: '+k+'\n'+'Abstract: '+v+'\n'+'\n'+'\n') num += 1 #生成results.txt -
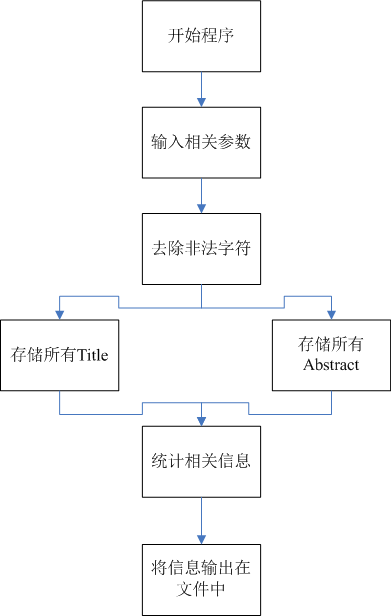
代码组织与内部实现设计
- 预处理模块:将一份txt文件里面的非法字符等全部转换为空格,并将Titile与Abstact分开
- 字符统计模块:统计文件中出现的字符
- 行数统计模块:统计文件中的行数综合
- 单词统计模块:统计文件中的单词出现次数并输出频率前十的单词,频率相同按照字典序输出
-
流程图
附加题
- 爬取作者,爬取论文pdf并下载到本地
- 实现思路
- 下载pdf
def main():
root_link = 'http://openaccess.thecvf.com/'
save_path = 'D:\pythonfile\pdf' # pdf save path
conference = 'CVPR' # conference name
year = 2018 # conference year
from_page(root_link=root_link, conference=conference, year=year, save_path=save_path)
def from_page(root_link, conference, year, save_path):
"""
Get all .pdf url from root_link
"""
url = root_link + conference + str(year) + '.py'
r = requests.get(url)
if r.status_code == 200:
soup = BeautifulSoup(r.text, "html5lib")
index = 1
# print("\n=============== {0:10} ===============\n".format('Start Downloading'))
for link in soup.find_all('a'):
new_link = link.get('href')
if new_link == None:
continue
if new_link.endswith('.pdf'):
new_link = root_link + new_link
download_file(new_link, save_path)
index += 1
print('Totally {} files have been downloaded.'.format(index))
else:
print("ERRORS occur !!!")
def download_file(download_url, save_path):
"""
Download pdf file from download_url
"""
try:
response = urllib.request.urlopen(download_url)
except urllib.request.HTTPError:
print("url is not exist")
else:
file_name = download_url.split('/')[-1]
save_name = os.path.join(save_path, file_name)
with open(save_name, 'wb') as file:
for data in response:
file.write(data)
file.close()
#print("Completed Dowloaded: {0:30}".format(file_name))
if __name__ == "__main__":
main()
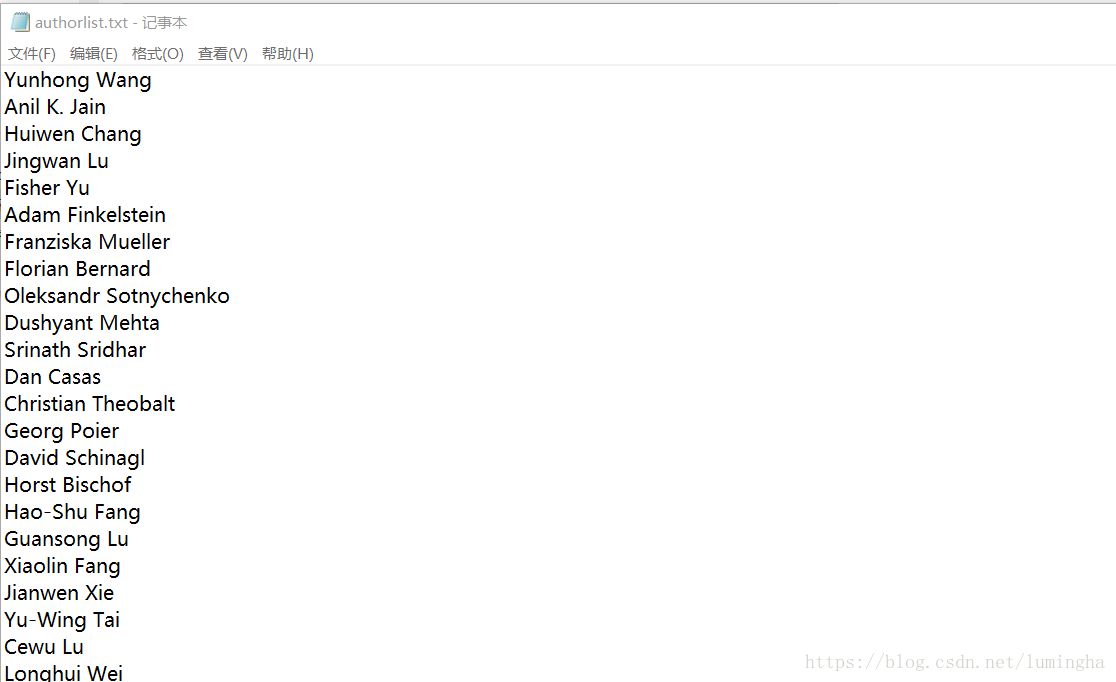
- 爬取作者
authors = soup1.find('i')
namelist = authors.string.strip().split(',')
for a in namelist:
authorlist.append(a)
with open('authorlist.txt','a+',encoding='utf-8') as file:
for a in authorlist:
file.write(a+'\n')
- 成果展示


关键代码解释
1.通过比较argv接收到的字符串来实现判断参数的输入
for (int i = 0; i < argc; i++)
{
if (strcmp(argv[i],"-i")==0) //文件输入地址
{
strcpy_s(filename, argv[i+1]);
}
else if (strcmp(argv[i], "-o") == 0) // 文件输出地址
{
result.open(argv[i+1]);
}
else if(strcmp(argv[i], "-w") == 0) //是否采用不同权重计数
{
useweight = std::atoi(argv[i + 1]);
}
else if(strcmp(argv[i], "-n") == 0) //设定输出的单词数量
{
wordnum = std::atoi(argv[i + 1]);
}
}
2.通过判断每行的第一个单词来进行Title Abstact的分离
void GetTitleFile(string filename)
{
ifstream file(filename);
ofstream title;
ofstream abstract;
title.open("title.txt");
abstract.open("abstract.txt");
string str;
while (file) {
getline(file, str);//从文件中读取一行
if (str.substr(0, 5) == "title")
{
title << str.substr(7, str.length() - 6)<<endl;
}
else if(str.substr(0, 8) == "abstract")
{
abstract << str.substr(10, str.length() - 9) << endl;
}
}
}
性能改进与分析


贴出Github的代码签入记录
- 记录commit信息

遇到的代码模块异常或结对困难及解决方法
- 问题描述
- 爬虫爬到的字符前自带有一个换行符,这样写入文本就多了一个换行符
- 写入文本时,windows默认的是gbk,而python3中字符串默认是unicode,这样就会报错
Python 3 UnicodeEncodeError: 'gbk' codec can't encode
- 做过哪些尝试
- 问题一:我尝试过将字符串做处理如:titles.replace('\r\n'|'\n'|'\t',''),但是并没有用。
- 问题二:尝试过添加代码
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') #改变标准输出的默认编码
报错:
AttributeError: 'OutStream' object has no attribute 'buffer'
-
是否解决
已解决
- 问题一:对字符串去前缀空格或换行titles.strip()
- 问题二:打开文本以unicode打开即可,like this:
with open('results.txt','a+',encoding='utf-8') as file:
- 有何收获
多上网查资料,要善于自己找到解决方案
评价队友
-
值得学习的地方
完了,这是要让我夸人吗。我的队友林燊:不仅人长得帅气,还有一个帅气的名字,听这名字就是大佬,三火三木。学习、娱乐和工作能完美切割。代码能力很odk(毕竟西二大佬),不仅自身能力强,还虚心向别人请教问题,争取把事情做到最优。这点我很需要学习,因为我很大的缺点就是不太敢请教他人。
-
需要改进的地方
改进?有吗没有吧。赶紧装一个win10,不然很多vs2017功能都不能用了
学习进度
-
卢泽明
第N周 新增代码(行) 累计代码(行) 本周学习耗时(h) 累计学习耗时(h) 重要成长 2 400 400 15 15 单元测试,性能分析 3 0 400 12 27 Balsamiq Mockups 3的运用 4,5 200 600 20 47 python爬虫、正则表达式、html -
林燊
第N周 新增代码(行) 累计代码(行) 本周学习耗时(h) 累计学习耗时(h) 重要成长 2 400 400 15 15 单元测试,性能分析 3 0 400 10 25 md编译器和模型工具 4,5 350 750 25 50 对字符处理更加熟练,掌握文本输入输出

 浙公网安备 33010602011771号
浙公网安备 33010602011771号