

python--文件读写--函数--(day3)
知识点一、文件读写内容
-
1、当文件当前没有写文件模式,默认为r,当文件以r的形式打开不存在的文件会报错
1 f = open('a.txt') 2 f = open('a.txt','r',encoding = 'utf-8')
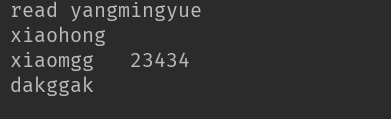
文件内容:
yangmingyue
xiaohong
xiaomgg 23434
dakggak
-
(1)read
1 f = open('a.txt','r',encoding = 'utf-8')#当前没有写文件模式,默认为r 2 print('read',f.read())#读出文件所有内容,文件内容为字符串
-
(2)readlines
1 f = open('a.txt','r',encoding = 'utf-8')#当前没有写文件模式,默认为r 2 print('readlines',f.readlines())#读出文件所有内容,把文件每一行内容放在list中

-
(3)readline
1 f = open('a.txt','r',encoding = 'utf-8')#当前没有写文件模式,默认为r 2 print('readline',f.readline())#一次只读一行

-
(4)文件指针:控制文件读到的位置
1 f = open('a.txt','r',encoding = 'utf-8')#当前没有写文件模式,默认为r 2 print('readlines',f.readlines())#读出文件所有内容,把文件每一行内容放在list中 3 print('readline',f.readline())#一次只读一行

1 f = open('a.txt','r',encoding = 'utf-8') 2 print('readlines',f.readlines()) 3 print('read',f.read())

1 f = open('a.txt','r',encoding = 'utf-8')#当前没有写文件模式,默认为r 2 print('readline',f.readline())#一次只读一行 3 print('readlines',f.readlines())#读出文件所有内容,把文件每一行内容放在list中

-
2、当文件以w的模式写入文件,能写不能读,写之前会清空文件(1)write 写入内容是字符串,就用write,
1 f = open('a.txt','w') 2 f.write('asdeeff\n')#只能写字符串 3 f.close()

-
(2)writelines 写入list时用
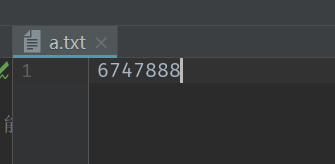
1 f = open('a.txt','w') 2 f.writelines('6747888')#可以写list,自动循环list每个元素,将元素都写入文件,也可以写入集合,只能能循环的数据类型都可以写 3 f.close()
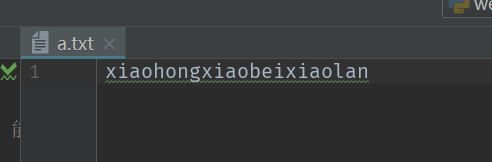
1 stus = ['xiaohong','xiaobei','xiaolan'] 2 f = open('a.txt','w') 3 f.writelines(stus)#可以写list,自动循环list每个元素,将元素都写入文件 4 f.close()
1 set = {'xiaohong','xiaohei','xuangg'} 2 f = open('a.txt','w') 3 f.writelines(set)#可以写list,自动循环list每个元素,将元素都写入文件 4 f.close()

-
3、当文件以a 的模式打开不存在的文件,会追加生成新的文件,不会报错
1 f = open('a.txt','a',encodinga = 'utf-8')
-
4、r+ 能读能写,打开不存在文件报错
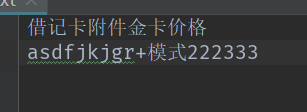
1 f = open('a.txt','r+',encoding = 'utf-8') 2 print(f.read()) 3 f.write('r+模式222333') 4 f.close()
1 f = open('a.txt','r+',encoding = 'utf-8') 2 #print(f.read()) 3 f.write('r+模式4444') 4 f.close()

注意:
读与不读会影响写的位置,因为文件指针导致的
-
5、w+ 能读能写,但是会清空之前的文件,
1 f = open('a.txt','w+',encoding = 'utf-8') 2 print(f.read()) 3 f.write('r+模式4444') 4 f.close()

1 f = open('a.txt','w+',encoding = 'utf-8') 2 f.write('r+模式4444') 3 print(f.read()) 4 f.close()
注意:写完之后读不到东西,想要想要读到内容,移动文件指针,f.seek(0)
-
6、a+ 能读能写不会清空之前的文件
1 f = open('a.txt','a+',encoding = 'utf-8') 2 print(f.read()) 3 f.write('r+模式4444') 4 f.close()d
注意:读不到东西,文件指针导致,想要读到内容,移动文件指针,f.seek(0)
1 f = open('a.txt','a+',encoding = 'utf-8') 2 f.seek(0) 3 print(f.read()) 4 f.write('r+模式4444') 5 f.close()

总结:

-
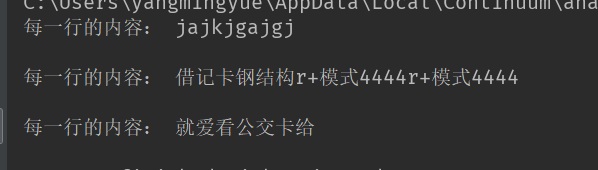
高效读文件:打开文件,直接循环文件对象
1 f = open('a.txt',encoding='utf-8') 2 3 for line in f: 4 print('每一行的内容:',line)
-
列子:
1 #1、监控服务器日志,找出每分钟访问超过100次的ip地址 2 #分析: 3 #1、当前时间去读上一分钟的数据,死循环 while True 实现,读取文件,获取到文件里面的所有ip地址 4 #2、把ip地址存起来,用字典存,key是ip地址,value是次数 5 #3、循环字典,判断value大于100的 6 7 import time 8 point = 0 9 while True: 10 ips = {} # 存放所有的ip地址以及它出现的次数 11 f = open('access.log')#默认r 的模式,读出所有的文件内容 12 f.seek(point)#文件指针到文件头 13 for line in f: 14 if line.strip():#判断不为空行的时候 15 ip = line.split()[0] 16 if ip not in ips: 17 ips[ip] = 1 18 else: 19 ips[ip] = ips[ip]+1 20 point = f.tell() #当前文件指针的位置 21 for ip in ips: 22 if ips.get(ip) >= 100: 23 print('超过100次的ip是:%s'%ip) 24 time.sleep(60)
知识点二、文件修改
-
#方式一:先读文件,替换,将替换的文件写入文件
1 f = open('a.txt','a+',encoding='utf=8') 2 result = f.read() 3 new_result = result.replace('abc','ABC') 4 f.seek(0) 5 f.truncate()#清空文件内容 6 f.write(new_result) 7 f.close()
-
#方式二:一次读一行,一行一行修改
1 #import os 2 # f1 = open('test.txt',encoding="utf-8") 3 # f2 = open('a2.txt','w',encoding='utf-8') 4 # for line in f1: 5 # new_line = line.replace('-','1') 6 # f2.write(new_line) 7 # f1.close() 8 # f2.close() 9 # os.remove('test.txt') 10 # os.rename('a2.txt','test.txt')
-
#方法三:使用with 不用自己关闭文件
1 import os 2 with open('a1.txt',encoding='utf-8') as f1,open('a2.txt','w',encoding='utf-8') as f2: 3 for line in f1: 4 new_line = line.replace('-', '1') 5 f2.write(new_line) 6 7 os.remove('a1.txt') 8 os.rename('a2.txt', 'a1.txt')
程序明明运行完,文件中没有内容,原因是不同的区域运行速度不一致,处理方式:
1 with open ('a.txt','w')as fw: 2 fw.write('123') 3 fw.flush()#处理文件运行后没有内容
知识点三、非空即真,非0即真,判断的时候使用给,简化代码
1 s = ''#字符串 2 l = []#数组 3 d = {}#字典 4 s1 = set()#集合 5 6 username = input('user').strip() 7 if username:#表示内容不为空 8 print('欢迎登录') 9 else: 10 print('输入内容不能为空') 11 12 if not username:#表示没有内容,内容为空
知识点四、json 文件
json串就是字符串
1 d = {"name":"abc"} 2 import json 3 import pprint 4 json_str = json.dumps(d) #就是把字典/list转成字符串(json) 5 pprint.pprint(json_str)

效果:把字典转成字符串,用pprint,效果更明显
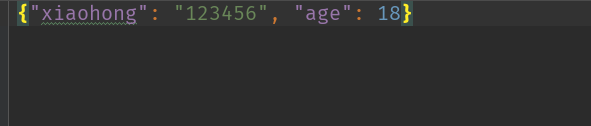
1 json_str2 = ' {"xiaohei":"123456","age":18} ' 2 dic = json.loads(json_str2) #把字符串(json)转成 字典 3 pprint.pprint(dic)

1 d = {"xiaohong":"123456","age":18} 2 with open('users.json','w',encoding='utf-8') as f: 3 json_d = json.dumps(d)#把字典转成字符串 4 f.write(json_d)
1 with open('users','r',encoding='utf-8') as f: 2 result = f.read() 3 a = json.loads(result)#把字符串转成字典 4 pprint.pprint(a)

1 d = { 2 "id": 314, 3 "name": "矿泉水", 4 "sex": "男", 5 "age": 18, 6 "addr": "北京市昌平区", 7 "grade": "摩羯座", 8 "phone": "18317155663", 9 "gold": 40 10 } 11 with open('user','w',encoding = 'utf-8') as f: 12 json_b = json.dumps(d,ensure_ascii=False,indent=4)#ensure_ascii=False读出中文,indent=4缩进格式化 13 f.write(json_b)
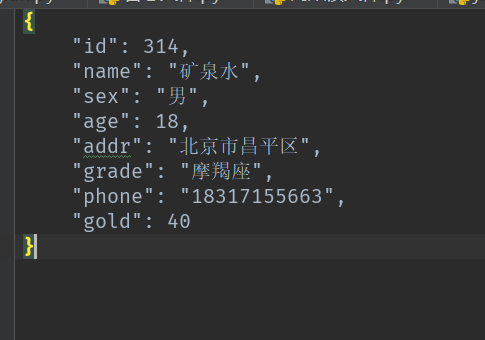
1 d = { 2 "id": 314, 3 "name": "矿泉水", 4 "sex": "男", 5 "age": 18, 6 "addr": "北京市昌平区", 7 "grade": "摩羯座", 8 "phone": "18317155663", 9 "gold": 40 10 } 11 with open('user.json','w',encoding = 'utf-8') as f:#打开json 文件后,写入格式有颜色区分 12 json_b = json.dumps(d,ensure_ascii=False,indent=4)#ensure_ascii=False读出中文,indent=4缩进格式化,4表示4个缩进 13 f.write(json_b)
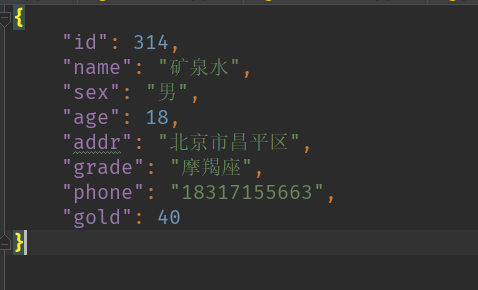
1 import json 2 import pprint 3 d = { 4 "id": 314, 5 "name": "矿泉水", 6 "sex": "男", 7 "age": 18, 8 "addr": "北京市昌平区", 9 "grade": "摩羯座", 10 "phone": "18317155663", 11 "gold": 40 12 } 13 f = open('users','w',encoding= 'utf-8') 14 json.dump(d,f,ensure_ascii=False,indent = 4)

1 f = open('users','r',encoding= 'utf-8') 2 dic = json.load(f) 3 print(dic)

知识点五、函数
-
#函数就是把一段代码封装起来,函数的作用就是简化代码

-
#告诉文件名和内容
1 def write_file(file_name,content): 2 f = open(file_name,'w') 3 f.write(content) 4 f.close()
-
#函数里面定义的变量都是局部变量,只在函数里面可以用,出了函数就不能用了
1 def read_file(file_name): 2 with open(file_name,encoding='utf-8') as fr: 3 result = fr.read() 4 return result #函数返回值 5 6 content = read_file('users')#函数调用 7 # print(content)
#1、函数不写返回值的情况下返回的是空
#2、返回多个值的时候,返回的是什么
#函数里面遇到return函数立即结束运行
函数例子:
1 #判断是否是浮点数的函数方法 1.33,-4.5 正数负数都是浮点数 2 #1、必须只有一个小数点 3 #2、小数点的左边必须是整数,小数点的右边必须是正整数 4 def is_float1(s): 5 s = str(s) #.1 6 if s.count('.')==1:#小数点数量为1 7 left,right = s.split('.') #['-','1']左侧和右侧用小数点分割 8 if left.isdigit() and right.isdigit():#左右都是正整数 9 return True#表示正浮点数 10 elif left[0] == '-' and left[1:].isdigit() and right.isdigit():#左边的第一个元素是-,左边的第一个元素后和右边的元素都是正整数 11 return True#表示是负的浮点数 12 else: 13 return False#不是浮点数 14 else: 15 return False#不是浮点数 16 print(is_float1('-.1')) # 函数调用 17 print(is_float1('-1.1')) # 函数调用 18 print(is_float1('1.1')) # 函数调用 19 print(is_float1('s.1')) # 函数调用 20 print(is_float1('-s.1')) # 函数调用

简化后的代码
1 def is_float1(s): 2 s = str(s) #.1 3 if s.count('.')==1:#小数点数量为1 4 left,right = s.split('.') #['-','1']左侧和右侧用小数点分割 5 if left.isdigit() and right.isdigit():#左右都是正整数 6 return True#表示正浮点数 7 elif left[0] == '-' and left[1:].isdigit() and right.isdigit():#左边的第一个元素是-,左边的第一个元素后和右边的元素都是正整数 8 return True#表示是负的浮点数 9 10 return False#不是浮点数
简化的原因是只有不符合浮点数规则,都是返回False
print(is_float1(.1))会报错
1 def is_float1(s): 2 s = str(s) #.1 3 if s.count('.')==1: 4 left,right = s.split('.') #['-','1'] 5 if left.isdigit() and right.isdigit():#正小数 6 return True 7 elif left.startswith('-') and left.count('-')==1 and right.isdigit(): 8 #先判断负号开头,只有一个负号,小数点右边是整数 9 lleft = left.split('-')[1] #如果有负号的话,按照负号分隔,取负号后面的数字 10 if lleft.isdigit():# 11 return True 12 return False 13 print(is_float1(.1))
1 s='1.1' 2 def is_float(s): 3 s = str(s) 4 if s.count('.') == 1: # 判断小数点个数 5 left,right = s.split('.') # 按照小数点进行分割 6 if left.startswith('-') and left.count('-') == 1 and right.isdigit(): 7 lleft = left.split('-')[1] # 按照-分割,然后取负号后面的数字 8 if lleft.isdigit(): 9 return True 10 elif left.isdigit() and right.isdigit():# 判断是否为正小数 11 return True 12 return False 13 print(is_float(s))
1 def hhh(name): #默认值参数 2 print(name) 3 #默认值函数的参数不是必传的, 4 def op_file(file_name,content=None):#(必填参数,默认值参数) 5 if content: 6 f = open(file_name,'w',encoding='utf-8') 7 f.write(content) 8 else: 9 f = open(file_name,encoding='utf-8') 10 return f.read() 11 def abc(name,age,phone,addr,money):# 12 print(name) 13 print(age) 14 print(phone) 15 print(addr) 16 print(money) 17 abc('xiaohei',18,110,'beijing',9000)#按照位置顺序传 18 abc(age=18,addr='beijing',money=500,phone=111,name='111')#指定参数 19 abc('xiaobai',addr='123',phone=1111,money=11111,age=13)#顺序,指定参数 20 abc(age=13,'xiaohei')#指定参数,按照位置这种传参方式是不对滴
-
全局变量:公共的变量
1 file_name = 'users.json' #全局变量 2 def func(): 3 file_name = 'abc.json' 4 print(file_name) 5 func() 6 7 print(file_name)
修改全局变量的方法
1 file_name = 'users.json' #全局变量 2 def func(): 3 global file_name#声明修改的全局变量 4 file_name = 'abc.json' 5 print(file_name) 6 func() 7 print(file_name)

例子:
1 money = 500 2 def test(consume): 3 return money - consume 4 5 def test1(money): 6 return test(money) + money

-
#常量:不会变的变量,常用大写字母定义
1 PI = 3.14
