
CLR 2.0 Memory Model
声明:
这篇文章关于内存模型的部分主要翻译自Understand the Impact of Low-Lock Techniques in Multithreaded Apps,此外增加了无锁编程(即Lock-Free)的内容,发布这篇文章的目的在于为以后描述.NET多线程并发/并行编程做底层基础。理解内存模型对于多线程编程有着莫大的益处,尤其是对于Lock-Freedom。
关于Lock-Free的优缺点,可以参考关于无锁编程。具体的解释可以参考《Java并发编程实践》,《Intel Threading Building Blocks. Outfitting C++ for Multi-core Processor Parallelism》,《Concurrent programming without locks》。
预备知识
任何支持多线程的系统都需要一个规范来描述多线程交互时如何精确的访问内存数据状态,我们称其为内存模型(Memory Model)。最简单的模型就是图1所展示的序列一致性内存模型(Sequential Consistency Memory Model)。在这个模型中,内存独立于任何使用它们的进程(线程)。内存通过内存控制器连接到每个线程,而内存控制器则会反馈每个线程的读写请求。来自单线程的读写请求会精确的按照线程的指定次序到达内存,然而它们也可能会和其他线程的读写请求按照一个未指定的方式交错进行。
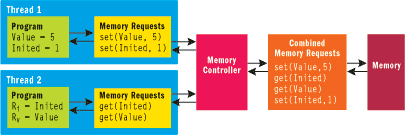
图1 Sequential Consistency Memory Model
在图1所示的例子中,Value变量需要初始化,而Inited标志则用来表明其是否已被初始化。Value和Inited首先都被设置为0。线程1首先初始化Value(Value被设置成5),然后设置Inited为1表明Value已被初始化了。线程2把这些值读进寄存器Rv和Ri。在一个依赖于顺序的(sequential)程序中,不可能会有当Ri为1(说明Value已被初始化了)时,Rv还是0(Value未初始化)的情况发生。这归因于Sequential Consistency Memory Model。图2中的表格枚举了序列一致性内存所允许的所有6种合法排列,从中我们可以看出Ri和Rv最终的值是什么。没有一种情况当Ri非零时,Rv为零。

图2 Possible Permutations of Memory Requests
如前面的例子所示,序列一致性是很容易想到的一种模型。依赖于顺序的程序的一些概念都可以在其上应用。坦白说,它也很自然的在单处理器机器上获得实现。大多数程序员都对这种内存模型相当熟悉。不幸的是,对于真正的多处理器机器,通过内存硬件来高效的实现这种模型,非常受限制。并且,没有商业多处理器机器符合这种模型。
典型的多处理器机器内存系统看起来很像图3。每一个处理器都有一个相关的非常快速的小型缓存来记忆最近访问的数据。除此之外,所有从处理器到内存的写操作都会有一个缓冲区,以便处理器可以在数据刷到以及缓存前可以继续下一个指令。我们可以在图3看到每个处理器至少会有一级或更多级的缓存。这些缓存每一级都会比前一级容量更大,但是速度更慢。最终数据会到达内存,这样数据就可以被其他处理器共享。这种架构会加速处理器,而且也意味着不再会有单一内存视图。现在一个处理器会在各级缓存针对特定内存位置存储一个值,同时其他处理器也缓存了相同内存位置的数据,但是这个数据可能是过期的老的数据。这就可能导致处理器的缓存内容不一致。

图3 Realistic Memory System
上述情况肯定不符合需要。如果我们拿它来用于线程间通信铁定引发问题。但是如果我们刷新每一个线程的缓存数据来作为通信机制的一部分,系统就会可靠了。这样的系统是高效的,因为保持缓存同步的开销只会在线程使用内存通信时才会产生,这只占所有内存访问的很小的一部分。
图3所示的就是真实的内存系统,它并不符合序列一致性内存模型。因此我们就要创建一种内存模型来解决这样的内存系统所带来的问题。我们要做的就是让处理器互相“看到”所有移动内存存取。

图4 Initial Memory State
举个例子,考虑下Inited-Value示例运行在如图4所示的多处理器机器上会发生什么。注意,这里的缓存是简化的。在这个版本的系统里,主内存内的两个变量初始值都是0。处理器1的缓存现在是空的,而处理器2则已经读取Value的值(Inited还没读)到了它的本地缓存。如果我们以前读取过程序的其他数据,而Value又紧挨着这个数据的话,就有可能发生上述情况。

图5 Incoherent Caches
如果两个处理器均运行该程序的话,状态变化就如图5所示。不要考虑图5了,联系图4,现在我们把在主内存的数据Value设置成5,Inited则设置1。然而,由于缓存的原因,处理器2的内容不是我们所期望看到的。当处理器2读取Inited时,它没有在缓存中发现Inited的值,然后它看到其在主内存的值(Inited = 1)。当处理器2读取Value时,它在缓存中发现其值为过期的0。这其实是处理器2在早期读取的Value。这跟运行在序列一致性内存模型上的下列代码有着相同的行为:
CacheTemp = Inited
Rv = Value
Ri = CacheTemp
写操作跟读操作类似。
这种技术有三个优点。首先,它相对简单,不需要精确的详细描述硬件细节。其次,它可以让源代码回退到一个很简单易懂的风格。缓存读取可以比其真正需要时才读取更早的把值载入到一个临时变量。缓存写入则比写入最终位置要晚。最后,它可以应用于编译器优化中。
很明显,这种任意移动内存访问的能力会导致混乱。所以所有的实际内存模型有以下三个基本原则:
- 当线程隔离运行时,行为不会改变。它的意思是,指定线程到指定位置的读或写操作不会通过相同的线程到相同位置的写操作。
- 读操作在获得锁时,数据不能移动。
- 写操作在释放锁时,数据不能移动。
这就是锁协议实际的意义。这个协议确保了当持有相关锁时,所有的线程共享,读/写内存访问。
有了这三个原则就使得所有遵循锁协议的程序在任何内存模型都有相同的行为。这是一个极有价值的属性。没有这些关于编译器或内存系统能重新排序读写的必要思考,我们要写一个正确的并发程序将会非常困难。
遵循锁协议的程序不必思考这些。一旦你不想遵循锁协议,那么就必须详细说明和考虑硬件或编译器的读写变换。
较宽松的模型:ECMA
你现在已经明白序列一致性内存模型非常受限,因为它不允许任何交互的读写操作。在Section 12, Partition I of the .NET Framework ECMA standard描述了一个较宽松的模型。这个模型把内存访问操作划分成原始内存访问和那些特别标记为“volatile”的访问。Volatile内存访问不能创建,删除或移动。原始内存访问不止受限于三个基本原则,同时也要遵循以下两个原则:
- 在volatile读前,读操作和写操作都不能移动数据。
- 在volatile写后,读操作和写操作都不能移动数据。
这给了编译器和硬件相当的优化自由。它们只需要关心通过锁和Volatile访问的边界格式。对于没有使用锁或Volatile的程序片段,可以做任意的合法优化。这也意味着内存系统只需要在锁或Volatile访问时做相关的昂贵缓存失效,然后刷新即可。这个模型非常高效,但是需要程序在使用Low-Lock技术时,遵循锁协议或显式标记volatile。
健壮模型 1: x86 行为
不幸的是,正确遵循锁协议的程序还有更多例外。当设计基于x86架构的多处理器系统时,设计者需要一个内存模型来使得大多数程序可以正常工作,同时也允许硬件合理有效。规范需要单处理器写操作相对其他写操作保持有序,而读操作则不受限。
不幸的是,如果读操作不受限,写操作有序的保证等于什么也不做。因此,x86架构没有提供比ECMA模型更强的保证。
然而,我相信,x86实际实现的内存模型和文档上描述的有些微不同。因为在我的试验中正确预测行为这个模型从未失败,而且它跟公开已知的硬件如何工作完全一致,但是却不是官方规范。新的处理器可能会打破该规范。在这个模型中,除了三个基本内存模型规则,这些规则也起作用:
- A write can only move later in time.
- A write cannot move past another write from the same thread.
- A write cannot move past a read from the same thread to the same location.
- A read can only move by going later in time to stay after a write to keep from breaking rule 3 as that write moves later in time.
这个模型对于带有写缓冲队列和窥探读操作的系统很有效。写数据到内存时,不是立即写到内存,而是按序放入队列里。这些写操作或许会延迟,但是却保持了有序。高效率的读操作不会移动数据,除非允许窥探写操作队列。每一个读操作都会窥探写缓冲区来查看是否处理器最近写进了要读取的值,如果发现就会使用写缓冲区的值。因为逻辑上讲写缓冲区的写操作只在实体在刷到主内存时才会发生,高效率的读取操作也会延迟到那时才会获取其值。规则4特别允许了这种行为。
健壮模型 2: .NET Framework 2.0
尽管.NET Framework的ECMA模型规范并不是那么健壮,但是运行于x86机器上的.NET Framework 1.x运行时的实现模型却跟x86模型非常接近(源于JIT或JIT编译器优化)。在版本2.0时,这个模型在Intel IA-64处理器上却遇到了问题。那些依赖于x86实现的客户程序在类似IA-64平台上运行时会有问题。结果就导致了.NET Framework 2.0运行时内存模型,它的规则如下:
- All the rules that are contained in the ECMA model, in particular the three fundamental memory model rules as well as the ECMA rules for volatile.
- Reads and writes cannot be introduced.
- A read can only be removed if it is adjacent to another read to the same location from the same thread. A write can only be removed if it is adjacent to another write to the same location from the same thread. Rule 5 can be used to make reads or writes adjacent before applying this rule.
- Writes cannot move past other writes from the same thread.
- Reads can only move earlier in time, but never past a write to the same memory location from the same thread.
同x86模型一样的是写操作被严格限制了,不一样的则是读操作可以移动数据和可以被消除。因为重新在内存获取值和在low-lock代码内存中可以被改变,所以有了规则2.最后的规则似乎是多余的,但是如果允许通过写到相同位置就会改变要读取的值,这也就改变了序列行为。如果读取的值真正被使用了,这就会发生。这个规则更有技术性,而且它被特别添加进来是为了使得通用的延迟初始化模式在该模型中合法。
Lock-Free
对于编写lock-free代码来说,上面的描述并没有详细的涉及,下面我们来描述一下其规则:
- Data dependence among loads and stores is never violated.
- All stores have release semantics, i.e. no load or store may move after one.
- All volatile loads are acquire, i.e. no load or store may move before one.
- No loads and stores may ever cross a full-barrier (e.g. Thread.MemoryBarrier, lock acquire, Interlocked.Exchange, Interlocked.CompareExchange, etc.).
- Loads and stores to the heap may never be introduced.
- Loads and stores may only be deleted when coalescing adjacent loads and stores from/to the same location.
注意从定义来看,非易失性加载不需要请求拥有任何一种与其关联的内存屏障。所以加载可以被自由重新排序,写操作也可以在其后移动数据(由于规则2)。在这个模型里,如果你真的需要规则4所提供的完全内存屏障的话,就可以防止紧跟在易失性加载后重新排序。没有屏障,指令就会重新排序。

