
Python并发编程-Redis
一、Redis 简介
Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。
Remote Dictionary Server(Redis)是一个基于 key-value 键值对的持久化数据库存储系统。redis 和 Memcached 缓存服务很像,但它支持存储的 value 类型相对更多,包括 string (字符串)、list (链表)、set (集合)、zset (sorted set --有序集合)和 hash(哈希类型)。这些数据类型都支持 push/pop、add/remove 及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis 支持各种不同方式的排序。与 memcached 一样,为了保证效率,数据都是缓存在内存中。区别的是 redis 会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了 master-slave (主从)同步。
redis 的出现,再一定程度上弥补了 Memcached 这类 key-value 内存换乘服务的不足,在部分场合可以对关系数据库起到很好的补充作用。redis 提供了 Python,Ruby,Erlang,PHP 客户端,使用方便。
官方文档:http://www.redis.io/documentation
二、Redis 与其他 key - value 缓存产品有以下三个特点:
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
三、Redis 优势
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
四、Redis与其他key-value存储有什么不同?
-
Redis有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进化路径。Redis的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象。
-
Redis运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,因为数据量不能大于硬件内存。在内存数据库方面的另一个优点是,相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样Redis可以做很多内部复杂性很强的事情。同时,在磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问。
一、Redis安装和基本使用
1、Ubuntu安装Redis
# Ubuntu 安装 redis $ sudo apt-get install redis-server # 启动服务端 $ sudo service redis-server {start|stop|restart|force-reload|status} # 启动服务端 $ sudo redis-cli
2、Centos6.x安装Redis
源码安装的方式
wget http://download.redis.io/releases/redis-3.0.6.tar.gz tar xzf redis-3.0.6.tar.gz cd redis-3.0.6 make
#启动Redis服务端
[root@redis src]#cd /server/scripts/redis-3.0.6/src #启动redis-server服务端 [root@redis src]# ./redis-server 13545:C 06 Feb 10:39:52.856 # Warning: no config file specified, using the default config. In order to specify a config file use ./redis-server /path/to/redis.conf 13545:M 06 Feb 10:39:52.858 * Increased maximum number of open files to 10032 (it was originally set to 1024). _._ _.-``__ ''-._ _.-`` `. `_. ''-._ Redis 3.0.6 (00000000/0) 64 bit .-`` .-```. ```\/ _.,_ ''-._ ( ' , .-` | `, ) Running in standalone mode |`-._`-...-` __...-.``-._|'` _.-'| Port: 6379 | `-._ `._ / _.-' | PID: 13545 `-._ `-._ `-./ _.-' _.-' |`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | http://redis.io `-._ `-._`-.__.-'_.-' _.-' |`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | `-._ `-._`-.__.-'_.-' _.-' `-._ `-.__.-' _.-' `-._ _.-' `-.__.-' 13545:M 06 Feb 10:39:52.862 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128. 13545:M 06 Feb 10:39:52.862 # Server started, Redis version 3.0.6 13545:M 06 Feb 10:39:52.863 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect. 13545:M 06 Feb 10:39:52.863 # WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled. 13545:M 06 Feb 10:39:52.863 * The server is now ready to accept connections on port 6379
#查看redis端口
[root@redis src]# ps -ef|grep redis root 13545 1105 0 10:40 pts/0 00:00:18 ./redis-server *:6379 root 29207 28828 0 13:56 pts/1 00:00:00 grep redis [root@redis src]# netstat -lntup|grep redis tcp 0 0 0.0.0.0:6379 0.0.0.0:* LISTEN 13545/./redis-serve tcp 0 0 :::6379 :::* LISTEN 13545/./redis-serve
#关闭Redis服务端
[root@redis src]# pkill redis-server
[root@redis src]# netstat -lntup|grep redis
#启动Redis客户端
#启动Redis客户端 [root@redis src]# redis-cli 127.0.0.1:6379> set foo bar OK 127.0.0.1:6379> get foo "bar" 127.0.0.1:6379> exit
#关闭客户端
#查看客户端端口 [root@redis src]# netstat -lntup|grep redis tcp 0 0 0.0.0.0:6379 0.0.0.0:* LISTEN 29236/./redis-serve tcp 0 0 :::6379 :::* LISTEN 29236/./redis-serve #关闭Redis客户端 [root@redis src]# redis-cli shutdown #查看端口 [root@redis src]# netstat -tunpl|grep 6379
#实现用脚本启动redis方法
#创建一个目录,用来存放启动所需要的配置文件 [root@redis ~]# mkdir -p /usr/redis #去安装目录下,拷贝四个配置文件 [root@redis ~]# cd /server/scripts/redis-3.0.6 [root@redis redis-3.0.6]# cp redis.conf /usr/redis/ [root@redis redis-3.0.6]# cd src [root@redis src]# cp redis-benchmark redis-cli redis-server /usr/redis/ #查看拷贝好的配置文件 [root@redis init.d]# cd /usr/redis/ [root@redis redis]# ll 总用量 15436 -rw-r--r-- 1 root root 18 2月 6 14:29 dump.rdb -rwxr-xr-x 1 root root 4587331 2月 6 14:26 redis-benchmark -rwxr-xr-x 1 root root 4696546 2月 6 14:26 redis-cli -rw-r--r-- 1 root root 41560 2月 6 14:28 redis.conf -rwxr-xr-x 1 root root 6469246 2月 6 14:26 redis-server
#修改Redis为后台启动
[root@redis redis]# vi redis.conf
daemonize yes #42行把no 改成yes 意思是:后台运行
提示:
默认的redis.conf文件参数是前台启动的,修改daemonize no为daemonize yes则为后台启动。
再写一个Redis启动脚本,放在/etc/rc.d/init.d/目录下
[root@redis redis]# cd /etc/rc.d/init.d/
[root@redis init.d]# vi redisd #!/bin/sh #chkconfig: 345 86 14 #description: Startup and shutdown script for Redis #author:nulige at 2017-2-6 PROGDIR=/usr/redis #安装路径 PROGNAME=redis-server DAEMON=$PROGDIR/$PROGNAME CONFIG=/usr/redis/redis.conf PIDFILE=/var/run/redis.pid DESC="redis daemon" SCRIPTNAME=/etc/rc.d/init.d/redisd start() { if test -x $DAEMON then echo -e "Starting $DESC: $PROGNAME" if $DAEMON $CONFIG then echo -e "OK" else echo -e "failed" fi else echo -e "Couldn't find Redis Server ($DAEMON)" fi } stop() { if test -e $PIDFILE then echo -e "Stopping $DESC: $PROGNAME" if kill `cat $PIDFILE` then echo -e "OK" else echo -e "failed" fi else echo -e "No Redis Server ($DAEMON) running" fi } restart() { echo -e "Restarting $DESC: $PROGNAME" stop start } list() { ps aux | grep $PROGNAME } case $1 in start) start ;; stop) stop ;; restart) restart ;; list) list ;; *) echo "Usage: $SCRIPTNAME {start|stop|restart|list}" >&2 exit 1 ;; esac exit 0
#给脚本添加可执行权限
[root@redis init.d]# chmod +x redisd
[root@redis init.d]# ll redisd
-rwxr-xr-x 1 root root 1488 2月 6 14:32 redisd
#添加开机自启动
[root@redis init.d]# chkconfig --add redisd
[root@redis init.d]# chkconfig --level 345 redisd on
#检查是否启动redisd服务
[root@redis init.d]# chkconfig --list redisd
redisd 0:关闭 1:关闭 2:关闭 3:启用 4:启用 5:启用 6:关闭
#查看启动参数
[root@redis init.d]# /etc/init.d/redisd
Usage: /etc/rc.d/init.d/redisd {start|stop|restart|list}
#启动redisd
[root@redis redis]# /etc/init.d/redisd start Starting redis daemon: redis-server OK #启动成功
二、Python操作Redis
sudo pip install redis or sudo easy_install redis or 源码安装 详见:https://github.com/WoLpH/redis-py
API使用
redis-py 的API的使用可以分类为:
- 连接方式
- 连接池
- 操作
- String 操作
- Hash 操作
- List 操作
- Set 操作
- Sort Set 操作
- 管道
- 发布订阅
1、操作模式
redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py。
#!/usr/bin/env python # -*- coding:utf-8 -*- import redis r = redis.Redis(host='10.211.55.4', port=6379) r.set('foo', 'Bar') print r.get('foo')
2、连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
#!/usr/bin/env python # -*- coding:utf-8 -*- import redis pool = redis.ConnectionPool(host='10.211.55.4', port=6379) r = redis.Redis(connection_pool=pool) r.set('foo', 'Bar') print r.get('foo')
3、操作
String操作,redis中的String在在内存中按照一个name对应一个value来存储。如图:
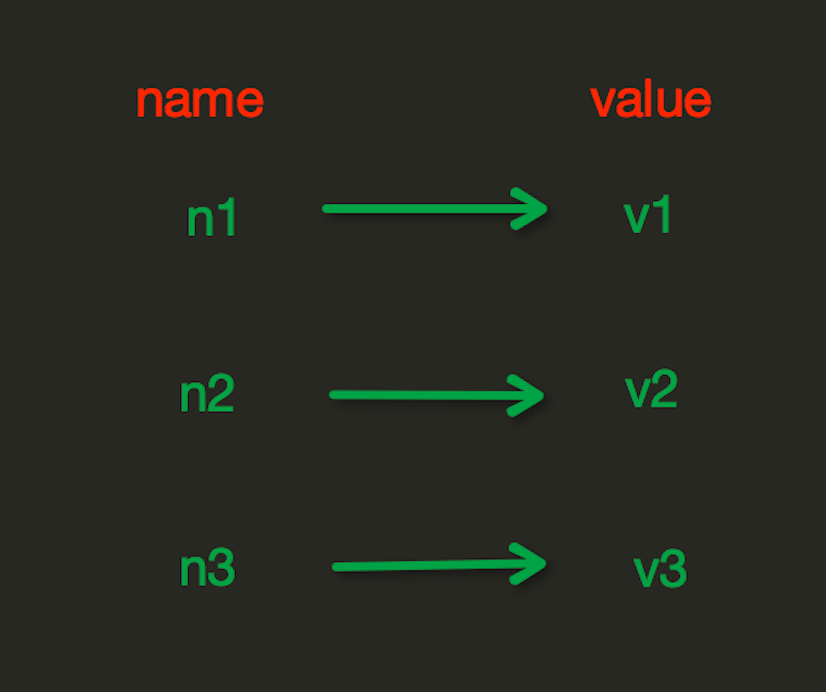
set(name, value, ex=None, px=None, nx=False, xx=False)
在Redis中设置值,默认,不存在则创建,存在则修改
参数:
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行
xx,如果设置为True,则只有name存在时,岗前set操作才执行
setnx(name, value)
设置值,只有name不存在时,执行设置操作(添加)
setex(name, value, time)
# 设置值
# 参数:
# time,过期时间(数字秒 或 timedelta对象)
psetex(name, time_ms, value)
# 设置值
# 参数:
# time_ms,过期时间(数字毫秒 或 timedelta对象)
mset(*args, **kwargs)
批量设置值
如:
mset(k1='v1', k2='v2')
或
mget({'k1': 'v1', 'k2': 'v2'})
get(name)
获取值
mget(keys, *args)
批量获取
如:
mget('ylr', 'wupeiqi')
或
r.mget(['ylr', 'wupeiqi'])
getset(name, value)
设置新值并获取原来的值
getrange(key, start, end)
# 获取子序列(根据字节获取,非字符)
# 参数:
# name,Redis 的 name
# start,起始位置(字节)
# end,结束位置(字节)
# 如: "武沛齐" ,0-3表示 "武"
setrange(name, offset, value)
# 修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加)
# 参数:
# offset,字符串的索引,字节(一个汉字三个字节)
# value,要设置的值
setbit(name, offset, value)
# 对name对应值的二进制表示的位进行操作
# 参数:
# name,redis的name
# offset,位的索引(将值变换成二进制后再进行索引)
# value,值只能是 1 或 0
# 注:如果在Redis中有一个对应: n1 = "foo",
那么字符串foo的二进制表示为:01100110 01101111 01101111
所以,如果执行 setbit('n1', 7, 1),则就会将第7位设置为1,
那么最终二进制则变成 01100111 01101111 01101111,即:"goo"
# 扩展,转换二进制表示:
# source = "武沛齐"
source = "foo"
for i in source:
num = ord(i)
print bin(num).replace('b','')
特别的,如果source是汉字 "武沛齐"怎么办?
答:对于utf-8,每一个汉字占 3 个字节,那么 "武沛齐" 则有 9个字节
对于汉字,for循环时候会按照 字节 迭代,那么在迭代时,将每一个字节转换 十进制数,然后再将十进制数转换成二进制
11100110 10101101 10100110 11100110 10110010 10011011 11101001 10111101 10010000
-------------------------- ----------------------------- -----------------------------
武 沛 齐
getbit(name, offset)
# 获取name对应的值的二进制表示中的某位的值 (0或1)
bitcount(key, start=None, end=None)
# 获取name对应的值的二进制表示中 1 的个数
# 参数:
# key,Redis的name
# start,位起始位置
# end,位结束位置
bitop(operation, dest, *keys)
# 获取多个值,并将值做位运算,将最后的结果保存至新的name对应的值
# 参数:
# operation,AND(并) 、 OR(或) 、 NOT(非) 、 XOR(异或)
# dest, 新的Redis的name
# *keys,要查找的Redis的name
# 如:
bitop("AND", 'new_name', 'n1', 'n2', 'n3')
# 获取Redis中n1,n2,n3对应的值,然后讲所有的值做位运算(求并集),然后将结果保存 new_name 对应的值中
strlen(name)
# 返回name对应值的字节长度(一个汉字3个字节)
incr(self, name, amount=1)
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。
# 参数:
# name,Redis的name
# amount,自增数(必须是整数)
# 注:同incrby
incrbyfloat(self, name, amount=1.0)
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。
# 参数:
# name,Redis的name
# amount,自增数(浮点型)
decr(self, name, amount=1)
# 自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。
# 参数:
# name,Redis的name
# amount,自减数(整数)
append(key, value)
# 在redis name对应的值后面追加内容
# 参数:
key, redis的name
value, 要追加的字符串
Hash操作,redis中Hash在内存中的存储格式如下图:
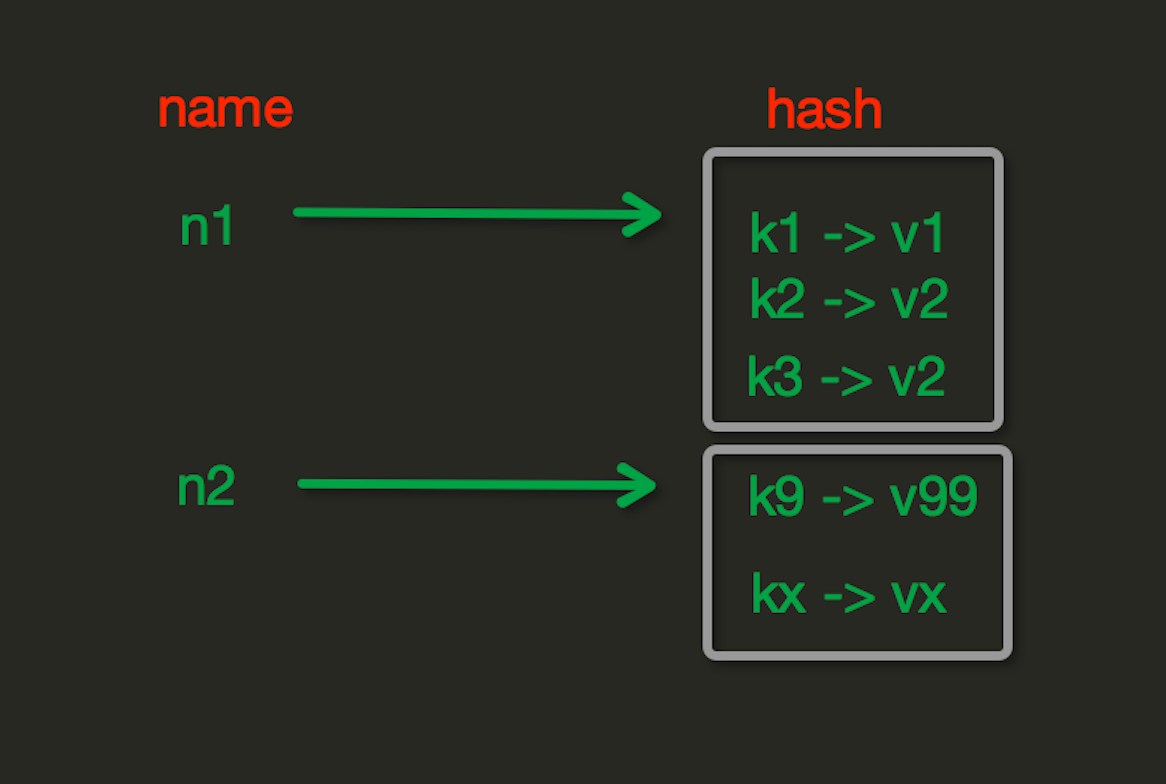
hset(name, key, value)
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
# 参数:
# name,redis的name
# key,name对应的hash中的key
# value,name对应的hash中的value
# 注:
# hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
hmset(name, mapping)
# 在name对应的hash中批量设置键值对
# 参数:
# name,redis的name
# mapping,字典,如:{'k1':'v1', 'k2': 'v2'}
# 如:
# r.hmset('xx', {'k1':'v1', 'k2': 'v2'})
hget(name,key)
# 在name对应的hash中获取根据key获取value
hmget(name, keys, *args)
# 在name对应的hash中获取多个key的值
# 参数:
# name,reids对应的name
# keys,要获取key集合,如:['k1', 'k2', 'k3']
# *args,要获取的key,如:k1,k2,k3
# 如:
# r.mget('xx', ['k1', 'k2'])
# 或
# print r.hmget('xx', 'k1', 'k2')
hgetall(name)
获取name对应hash的所有键值
hlen(name)
# 获取name对应的hash中键值对的个数
hkeys(name)
# 获取name对应的hash中所有的key的值
hvals(name)
# 获取name对应的hash中所有的value的值
hexists(name, key)
# 检查name对应的hash是否存在当前传入的key
hdel(name,*keys)
# 将name对应的hash中指定key的键值对删除
hincrby(name, key, amount=1)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(整数)
hincrbyfloat(name, key, amount=1.0)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(浮点数)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
hscan(name, cursor=0, match=None, count=None)
# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆
# 参数:
# name,redis的name
# cursor,游标(基于游标分批取获取数据)
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
# 如:
# 第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None)
# 第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None)
# ...
# 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕
hscan_iter(name, match=None, count=None)
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据
# 参数:
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
# 如:
# for item in r.hscan_iter('xx'):
# print item
List操作,redis中的List在在内存中按照一个name对应一个List来存储。如图:
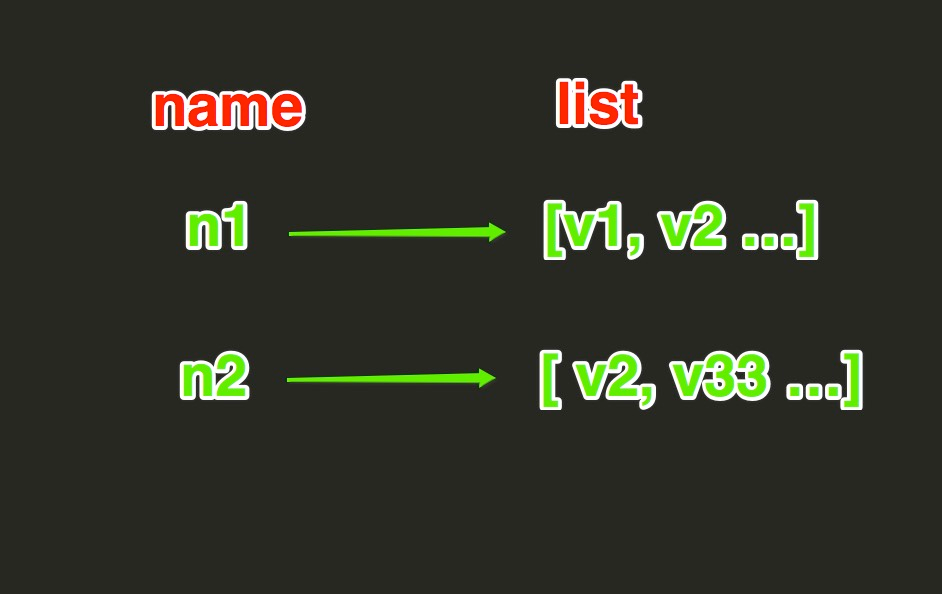
lpush(name,values)
# 在name对应的list中添加元素,每个新的元素都添加到列表的最左边
# 如:
# r.lpush('oo', 11,22,33)
# 保存顺序为: 33,22,11
# 扩展:
# rpush(name, values) 表示从右向左操作
lpushx(name,value)
# 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边
# 更多:
# rpushx(name, value) 表示从右向左操作
llen(name)
# name对应的list元素的个数
linsert(name, where, refvalue, value))
# 在name对应的列表的某一个值前或后插入一个新值
# 参数:
# name,redis的name
# where,BEFORE或AFTER
# refvalue,标杆值,即:在它前后插入数据
# value,要插入的数据
r.lset(name, index, value)
# 对name对应的list中的某一个索引位置重新赋值
# 参数:
# name,redis的name
# index,list的索引位置
# value,要设置的值
r.lrem(name, value, num)
# 在name对应的list中删除指定的值
# 参数:
# name,redis的name
# value,要删除的值
# num, num=0,删除列表中所有的指定值;
# num=2,从前到后,删除2个;
# num=-2,从后向前,删除2个
lpop(name)
# 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素
# 更多:
# rpop(name) 表示从右向左操作
lindex(name, index)
在name对应的列表中根据索引获取列表元素
lrange(name, start, end)
# 在name对应的列表分片获取数据
# 参数:
# name,redis的name
# start,索引的起始位置
# end,索引结束位置
ltrim(name, start, end)
# 在name对应的列表中移除没有在start-end索引之间的值
# 参数:
# name,redis的name
# start,索引的起始位置
# end,索引结束位置
rpoplpush(src, dst)
# 从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边
# 参数:
# src,要取数据的列表的name
# dst,要添加数据的列表的name
blpop(keys, timeout)
# 将多个列表排列,按照从左到右去pop对应列表的元素
# 参数:
# keys,redis的name的集合
# timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞
# 更多:
# r.brpop(keys, timeout),从右向左获取数据
brpoplpush(src, dst, timeout=0)
# 从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧
# 参数:
# src,取出并要移除元素的列表对应的name
# dst,要插入元素的列表对应的name
# timeout,当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞
自定义增量迭代
# 由于redis类库中没有提供对列表元素的增量迭代,如果想要循环name对应的列表的所有元素,那么就需要:
# 1、获取name对应的所有列表
# 2、循环列表
# 但是,如果列表非常大,那么就有可能在第一步时就将程序的内容撑爆,所有有必要自定义一个增量迭代的功能:
def list_iter(name):
"""
自定义redis列表增量迭代
:param name: redis中的name,即:迭代name对应的列表
:return: yield 返回 列表元素
"""
list_count = r.llen(name)
for index in xrange(list_count):
yield r.lindex(name, index)
# 使用
for item in list_iter('pp'):
print item
Set操作,Set集合就是不允许重复的列表
sadd(name,values)
# name对应的集合中添加元素
scard(name)
获取name对应的集合中元素个数
sdiff(keys, *args)
在第一个name对应的集合中且不在其他name对应的集合的元素集合
sdiffstore(dest, keys, *args)
# 获取第一个name对应的集合中且不在其他name对应的集合,再将其新加入到dest对应的集合中
sinter(keys, *args)
# 获取多一个name对应集合的并集
sinterstore(dest, keys, *args)
# 获取多一个name对应集合的并集,再讲其加入到dest对应的集合中
sismember(name, value)
# 检查value是否是name对应的集合的成员
smembers(name)
# 获取name对应的集合的所有成员
smove(src, dst, value)
# 将某个成员从一个集合中移动到另外一个集合
spop(name)
# 从集合的右侧(尾部)移除一个成员,并将其返回
srandmember(name, numbers)
# 从name对应的集合中随机获取 numbers 个元素
srem(name, values)
# 在name对应的集合中删除某些值
sunion(keys, *args)
# 获取多一个name对应的集合的并集
sunionstore(dest,keys, *args)
# 获取多一个name对应的集合的并集,并将结果保存到dest对应的集合中
sscan(name, cursor=0, match=None, count=None)
sscan_iter(name, match=None, count=None)
# 同字符串的操作,用于增量迭代分批获取元素,避免内存消耗太大
有序集合,在集合的基础上,为每元素排序;元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。
zadd(name, *args, **kwargs)
# 在name对应的有序集合中添加元素
# 如:
# zadd('zz', 'n1', 1, 'n2', 2)
# 或
# zadd('zz', n1=11, n2=22)
zcard(name)
# 获取name对应的有序集合元素的数量
zcount(name, min, max)
# 获取name对应的有序集合中分数 在 [min,max] 之间的个数
zincrby(name, value, amount)
# 自增name对应的有序集合的 name 对应的分数
r.zrange( name, start, end, desc=False, withscores=False, score_cast_func=float)
# 按照索引范围获取name对应的有序集合的元素
# 参数:
# name,redis的name
# start,有序集合索引起始位置(非分数)
# end,有序集合索引结束位置(非分数)
# desc,排序规则,默认按照分数从小到大排序
# withscores,是否获取元素的分数,默认只获取元素的值
# score_cast_func,对分数进行数据转换的函数
# 更多:
# 从大到小排序
# zrevrange(name, start, end, withscores=False, score_cast_func=float)
# 按照分数范围获取name对应的有序集合的元素
# zrangebyscore(name, min, max, start=None, num=None, withscores=False, score_cast_func=float)
# 从大到小排序
# zrevrangebyscore(name, max, min, start=None, num=None, withscores=False, score_cast_func=float)
zrank(name, value)
# 获取某个值在 name对应的有序集合中的排行(从 0 开始)
# 更多:
# zrevrank(name, value),从大到小排序
zrangebylex(name, min, max, start=None, num=None)
# 当有序集合的所有成员都具有相同的分值时,有序集合的元素会根据成员的 值 (lexicographical ordering)来进行排序,而这个命令则可以返回给定的有序集合键 key 中, 元素的值介于 min 和 max 之间的成员
# 对集合中的每个成员进行逐个字节的对比(byte-by-byte compare), 并按照从低到高的顺序, 返回排序后的集合成员。 如果两个字符串有一部分内容是相同的话, 那么命令会认为较长的字符串比较短的字符串要大
# 参数:
# name,redis的name
# min,左区间(值)。 + 表示正无限; - 表示负无限; ( 表示开区间; [ 则表示闭区间
# min,右区间(值)
# start,对结果进行分片处理,索引位置
# num,对结果进行分片处理,索引后面的num个元素
# 如:
# ZADD myzset 0 aa 0 ba 0 ca 0 da 0 ea 0 fa 0 ga
# r.zrangebylex('myzset', "-", "[ca") 结果为:['aa', 'ba', 'ca']
# 更多:
# 从大到小排序
# zrevrangebylex(name, max, min, start=None, num=None)
zrem(name, values)
# 删除name对应的有序集合中值是values的成员
# 如:zrem('zz', ['s1', 's2'])
zremrangebyrank(name, min, max)
# 根据排行范围删除
zremrangebyscore(name, min, max)
# 根据分数范围删除
zremrangebylex(name, min, max)
# 根据值返回删除
zscore(name, value)
# 获取name对应有序集合中 value 对应的分数
zinterstore(dest, keys, aggregate=None)
# 获取两个有序集合的交集,如果遇到相同值不同分数,则按照aggregate进行操作 # aggregate的值为: SUM MIN MAX
zunionstore(dest, keys, aggregate=None)
# 获取两个有序集合的并集,如果遇到相同值不同分数,则按照aggregate进行操作 # aggregate的值为: SUM MIN MAX
zscan(name, cursor=0, match=None, count=None, score_cast_func=float)
zscan_iter(name, match=None, count=None,score_cast_func=float)
# 同字符串相似,相较于字符串新增score_cast_func,用来对分数进行操作
其他常用操作
delete(*names)
# 根据删除redis中的任意数据类型
exists(name)
# 检测redis的name是否存在
keys(pattern='*')
# 根据模型获取redis的name
# 更多:
# KEYS * 匹配数据库中所有 key 。
# KEYS h?llo 匹配 hello , hallo 和 hxllo 等。
# KEYS h*llo 匹配 hllo 和 heeeeello 等。
# KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
expire(name ,time)
# 为某个redis的某个name设置超时时间
rename(src, dst)
# 对redis的name重命名为
move(name, db))
# 将redis的某个值移动到指定的db下
randomkey()
# 随机获取一个redis的name(不删除)
type(name)
# 获取name对应值的类型
scan(cursor=0, match=None, count=None)
scan_iter(match=None, count=None)
# 同字符串操作,用于增量迭代获取key
4、管道
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import redis
pool = redis.ConnectionPool(host='10.211.55.4', port=6379)
r = redis.Redis(connection_pool=pool)
# pipe = r.pipeline(transaction=False)
pipe = r.pipeline(transaction=True)
pipe.set('name', 'alex')
pipe.set('role', 'sb')
pipe.execute()
5、发布订阅

发布者:服务器
订阅者:Dashboad和数据处理
Demo如下:


#!/usr/bin/env python # -*- coding:utf-8 -*- import redis class RedisHelper: def __init__(self): self.__conn = redis.Redis(host='10.211.55.4') self.chan_sub = 'fm104.5' self.chan_pub = 'fm104.5' def public(self, msg): self.__conn.publish(self.chan_pub, msg) return True def subscribe(self): pub = self.__conn.pubsub() pub.subscribe(self.chan_sub) pub.parse_response() return pub
发布者:
import redis
pool = redis.ConnectionPool(host='192.168.152.134', port=6379,)
conn = redis.Redis(connection_pool=pool)
conn.publish('fm104.5', 'bigsb')
订阅者1:
import redis
pool = redis.ConnectionPool(host='192.168.152.134', port=6379, )
conn = redis.Redis(connection_pool=pool)
pb = conn.pubsub()
pb.subscribe('fm104.5')
while True:
msg = pb.parse_response()
print(msg)
订阅者2:
import redis
pool = redis.ConnectionPool(host='192.168.152.134', port=6379, )
conn = redis.Redis(connection_pool=pool)
pb = conn.pubsub()
pb.subscribe('fm104.5')
while True:
msg = pb.parse_response()
print(msg)
更多参见:
https://github.com/andymccurdy/redis-py/
Redis 命令参考:
http://doc.redisfans.com/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号