

2017-2018-1 20155232 《信息安全系统设计基础》第四周学习总结以及课上myod练习补充博客
2017-2018-1 20155232 《信息安全系统设计基础》第四周学习总结以及课上myod练习补充博客
课上myod练习
1 参考教材第十章内容
2 用Linux IO相关系统调用编写myod.c 用myod XXX实现Linux下od -tx -tc XXX的功能,注意XXX是文件名,通过命令行传入,不要让用户输入文件名
-
不要把代码都写入main函数中
-
要分模块,不要把代码都写入一个.c中
5 提交测试代码和运行结果截图, 提交调试过程截图,要全屏,包含自己的学号信息
在第一次尝试在我上次编写myod的基础上,通过调用FILE*fp指针到函数
hexdacimal.c
和
output.c
和
ascii.c
中但是出现了段错误的提示后,上网搜索后,发现是野指针,就是段错误是指访问的内存超出了系统给这个程序所设定的内存空间,例如访问了不存在的内存地址、访问了系统保护的内存地址、访问了只读的内存地址等等情况。所以不采用用FILE*fp作为参数传参
后面又改为将number作为总数和将数组传递到函数中去实现,又出现了段错误的提示。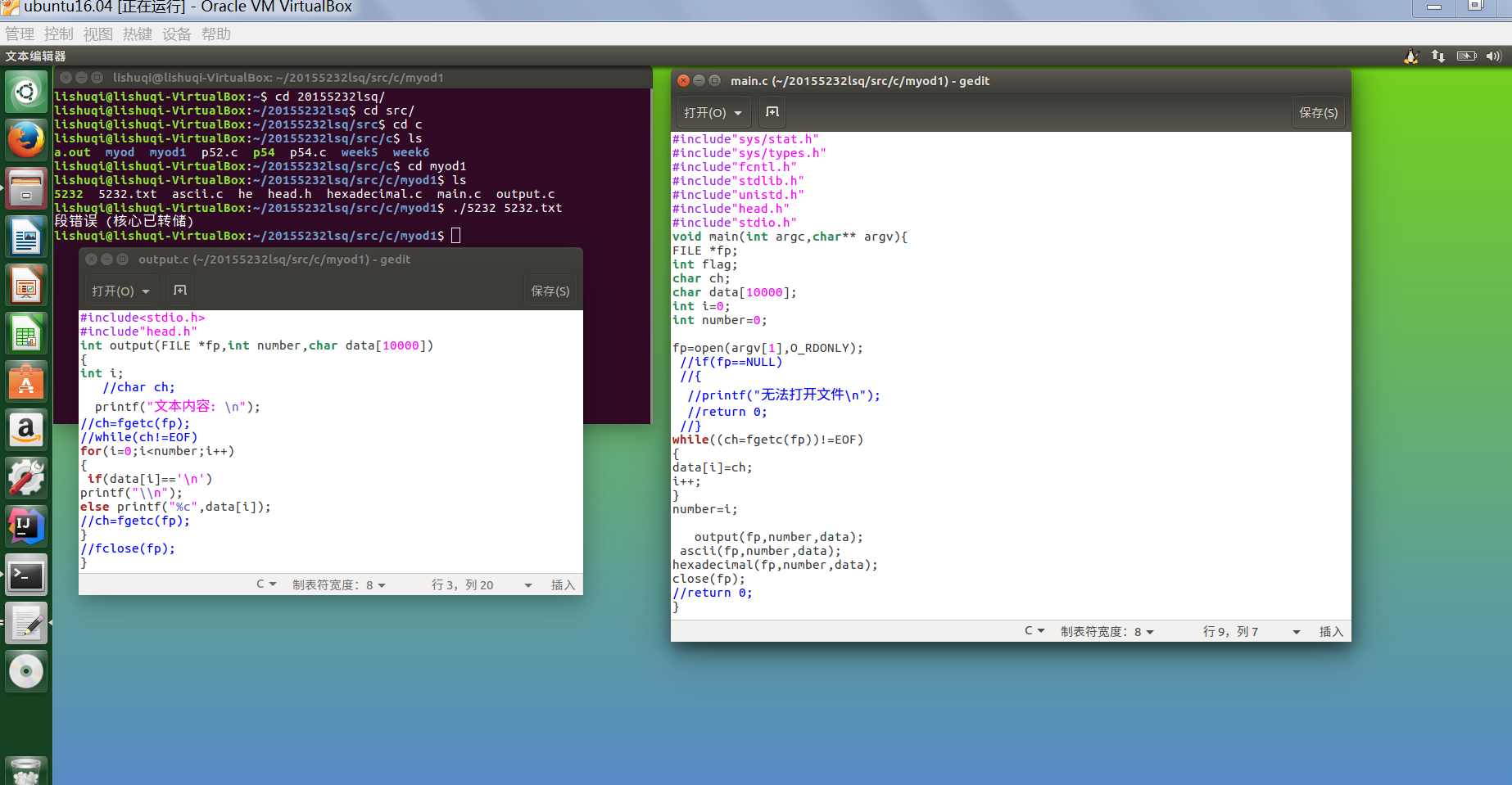
通过刚才给出的链接中,进行调试后,又将代码进行了改进后,运行结果如下:

无法打开文件,也就是文件打开失败,在读取时出现了问题,于是又做了进一步的改进:
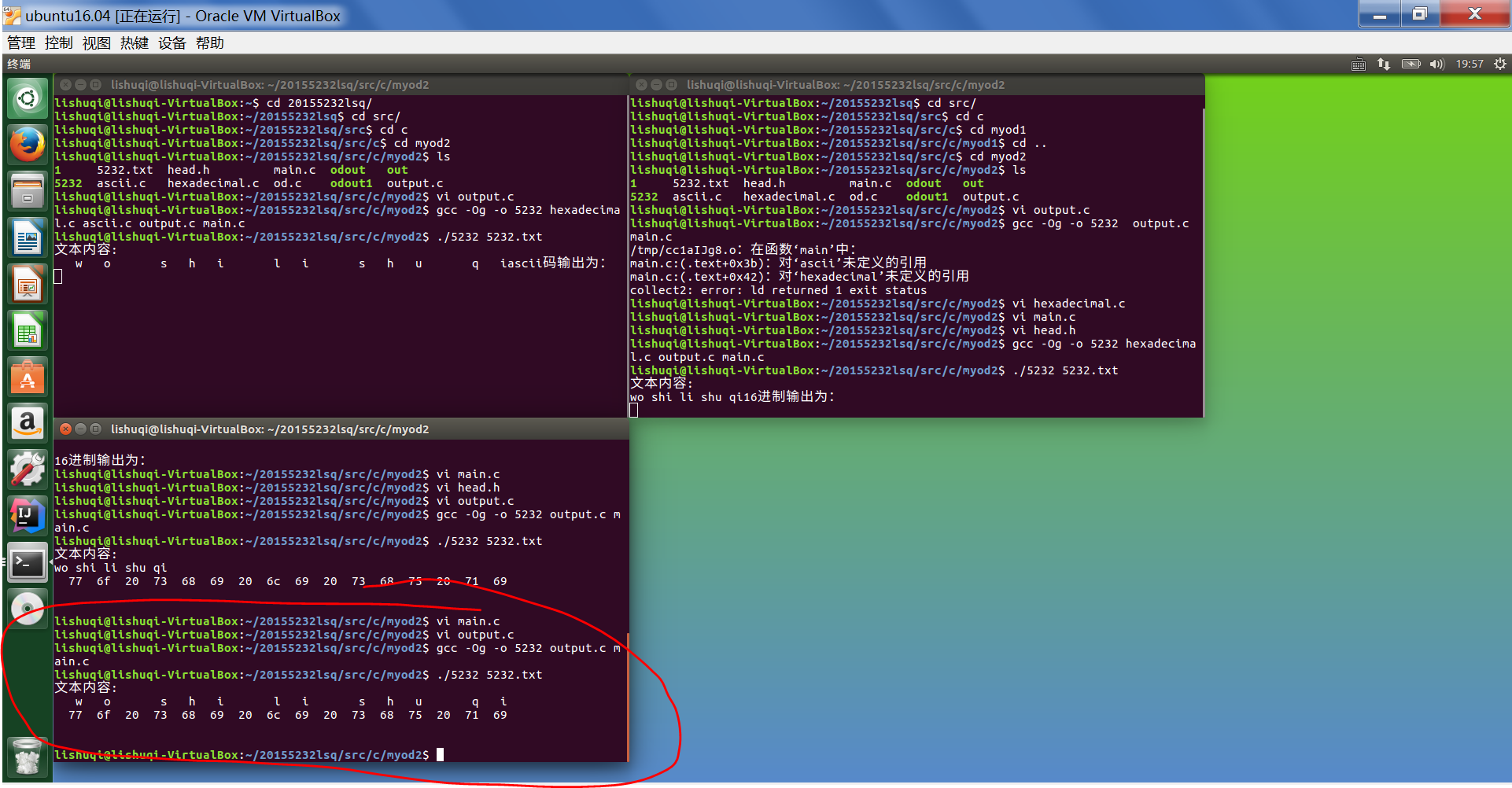
终于运行成功。代码如下:
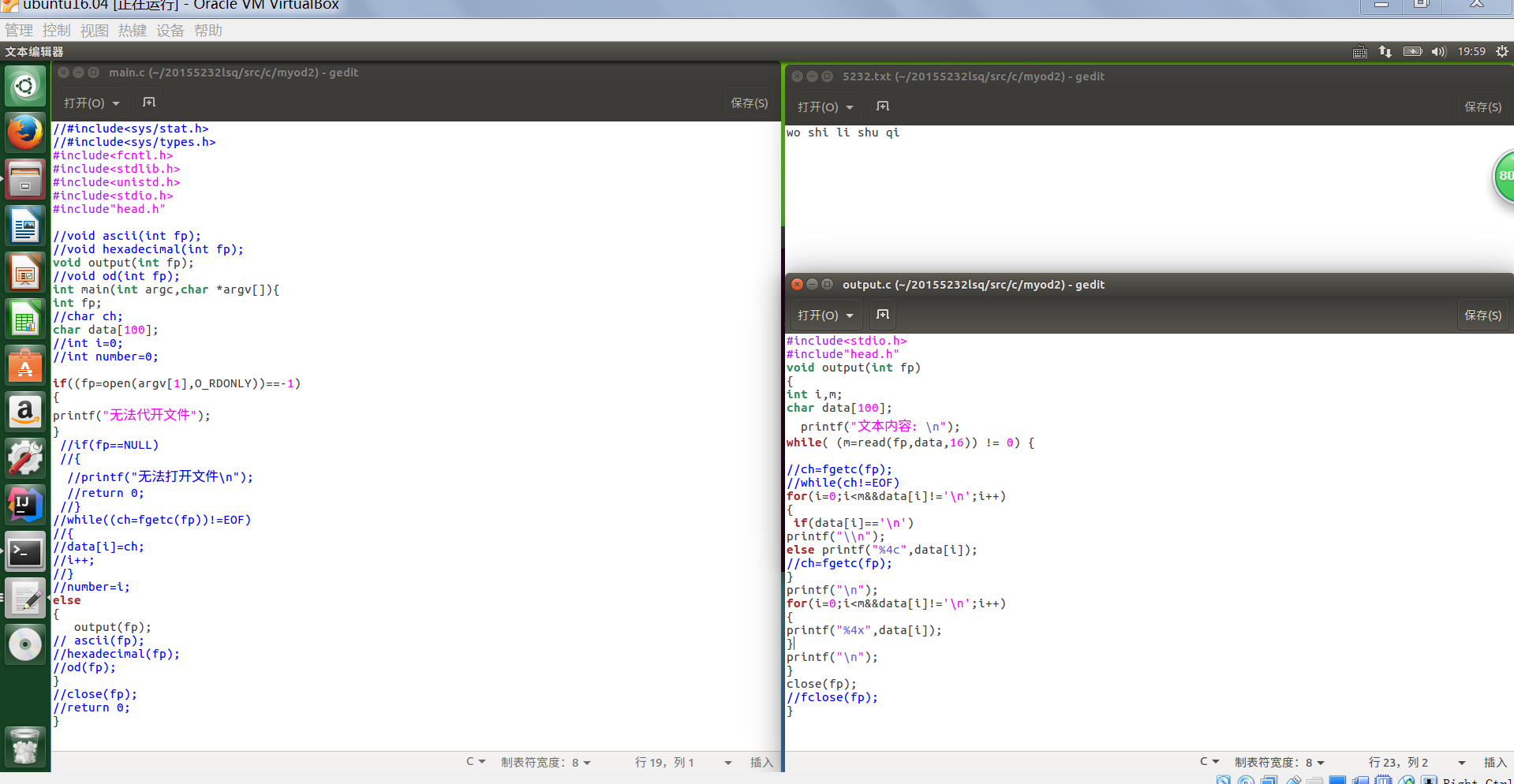
在命令行输入文件名,即可显示出文件的内容。
掌握两个重要命令:
man -k key1 | grep key2| grep 2
根据关键字检索系统调用
grep -nr XXX /usr/include
:查找宏定义,类型定义
man命令,
man3是查找函数
man2是查找系统调用
man1是查找命令。
在输入如下命令就是查找从文件读取的系统调用有哪些。
man -k read | grep 2 | grep file

然后再输入
man 2 read
命令就能查看read的帮助
grep -nr "struct utmp" /usr/include
查找struct utmp在哪个头文件中定义linux头文件都在此目录下)。
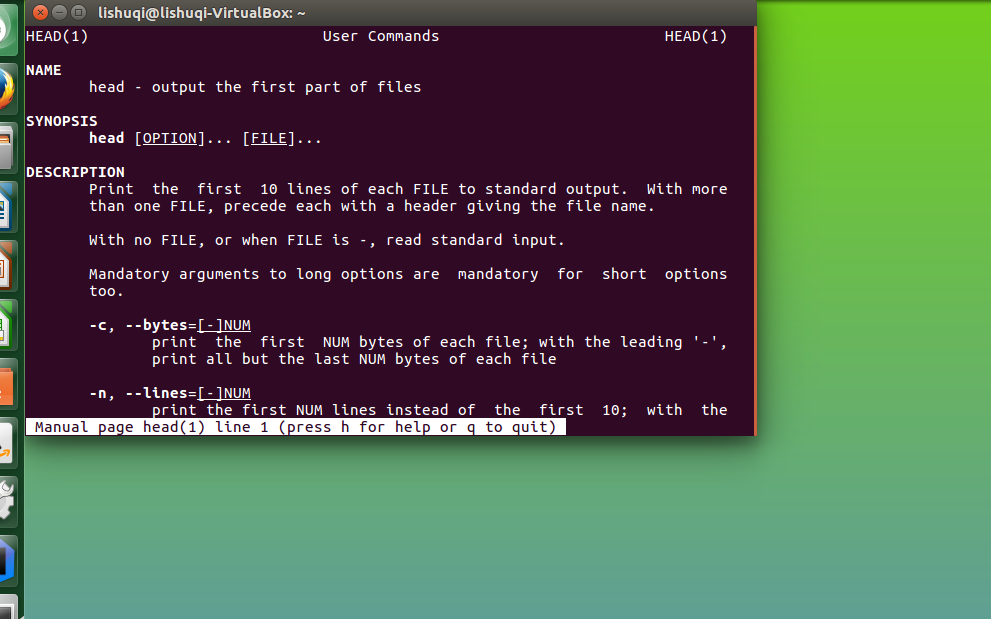
学习head,tail的使用
通过使用命令
man head
查看head的帮助文档。
- head命令默认显示头部的前N行
- -q 隐藏文件名
- -v 显示文件名
- -c<字节> 显示字节数
- -n<行数> 显示的行数
通过命令
head -3 1234.txt
显示文件前三行:

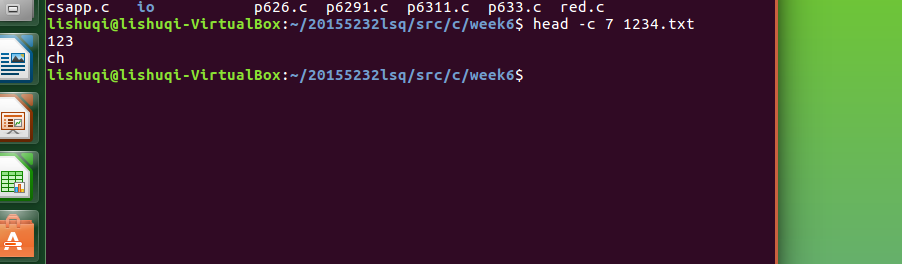
通过命令
head -c 7 1234.txt
显示文件前n个字节
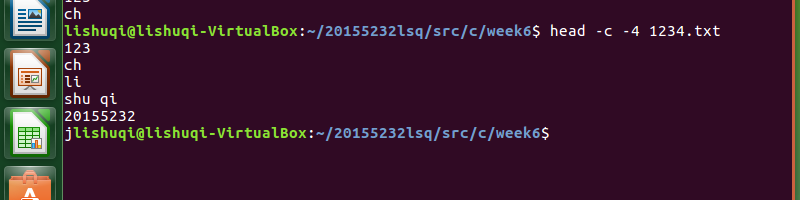
通过命令
head -c -4 1234.txt
显示文件的除了最后n个字节以外的内容
通过命令
head -n -2 1234.txt
输出文件除了最后n行的全部内容:

- 与head命令相反,tail命令是用来查看具体文件后面几行的内容
- 查看tail命令的API

- -f 循环读取
- -q 不显示处理信息
- -v 显示详细的处理信息
- -c<数目> 显示的字节数
- -n<行数> 显示行数
- –pid=PID 与-f合用,表示在进程ID,PID死掉之后结束.
- -q, –quiet, –silent 从不输出给出文件名的首部
- -s, –sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒
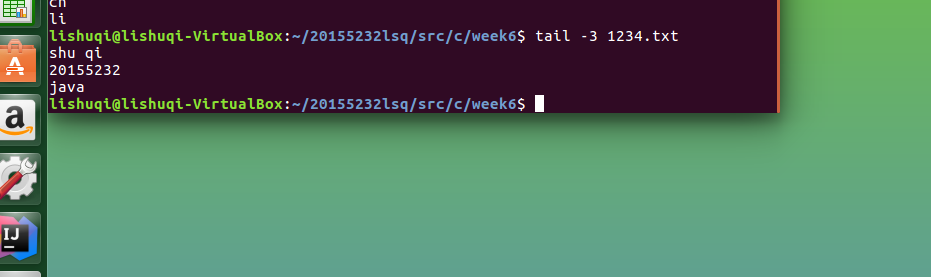
查看文件后面几行的内容:
通过命令
tail -f 1234.txt
循环查看文件内容,用Ctrl+c来终止。
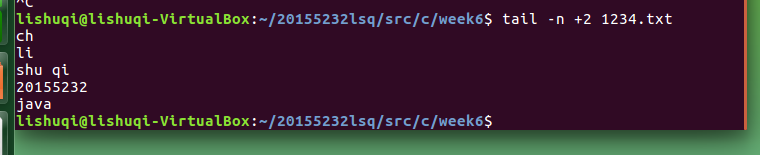
通过命令
tail -n +2 1234.txt
从第2行开始显示文件:
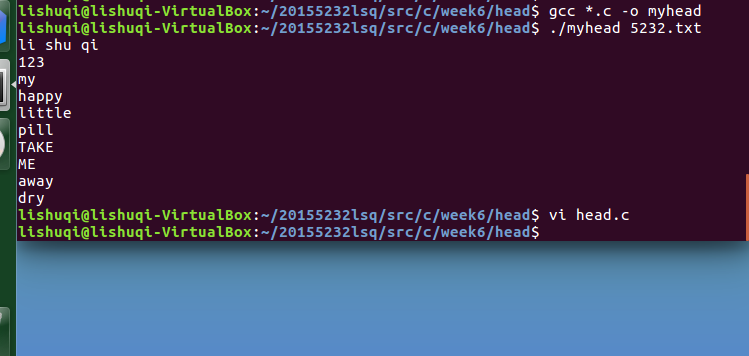
- 编写伪代码
- head和tail命令+文件名 默认输出10行内容。
main函数中命令行传入参数命令
调用head函数
将数组data及数组长度传入head函数中
利用循环中嵌套if条件
for( ;小于总长且小于10行; )
if(判断是否读取到的为换行符)
{
若为换行符
行数++且打印换行符
若不是
则打印字符
}
运行结果:(显示前10行内容)
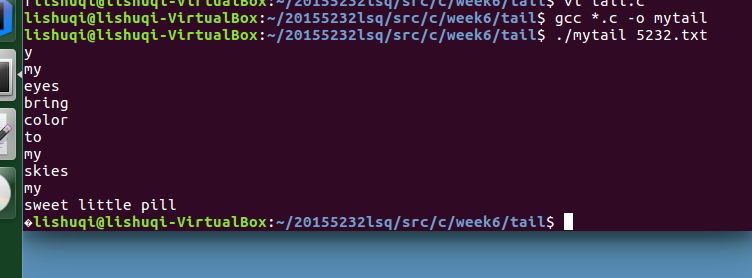
tail伪代码:
main函数中命令行传入参数命令
调用tail函数
将数组data及数组长度传入head函数中
利用循环中嵌套if条件
for{(从后开始;大于0且小于10行;循环变量递减 )
if(判断是否读取到的为换行符)
{
若为换行符
行数++}
}
若不是跳出循环
for(等于行数;小于等于len;循环变量增加)
打印字符
}
运行结果(显示后10行):
第四周教材学习内容总结
本周学习第十章和附录A:
- Unix I/O(打开文件,改变当前的文件位置,读写文件,关闭文件)
- RIO包读写
健壮的包,会自动为你处理之前所述的不足值。
1.无缓冲的输入输出函数(调用rio_readn和writen函数)
2.带缓冲的输入函数(调用一个包装函数rio_readlineb)
-
linux内核用三个相关的数据结构来表示打开的文件
1.描述符表
2.文件表
3.v-node表
-
每个进程有单独的描述符表,但所有进程共享同一打开文件表和v-node表
-
标准I/O
附录A:
- unix中错误处理
1.Unix风格
2.Posix风格
3.GAI风格
- 错误处理包装函数
教材学习中的问题和解决过程
-
问题1:系统i/o重定向如何具体实现?
-
解决:
在网上查阅资料时,看到相关资料非常的详细:
I/O重定向的原理和实现 -
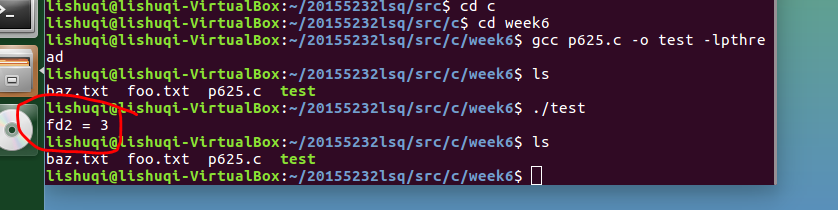
问题2:课本练习题代码10.1中运行结果的值为什么是3?
-
解决:
因为生命周期开始时0、1、2被占用,所以以后从3开始,所以对open的返回描述符为3。
代码调试中的问题和解决过程
-
问题1:在编写如下代码时,遇到了问题:
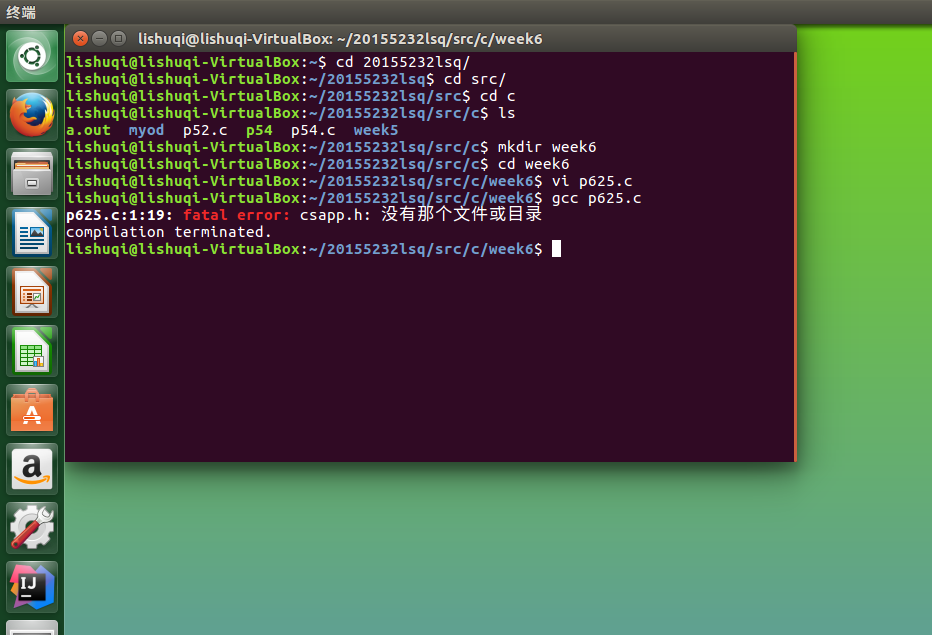
提示出现没有那个文件或目录。 -
问题1解决方案:
在上网查询后,发现因为没有导入csapp.h和csapp.c这两个头文件的原因。结果如下:

首先在网上输入下载头文件地址,找到两个头文件,并把内容分别复制下来。在当前目录下输入命令,
vi csapp.c
vi csapp.h
并把代码粘贴进去。
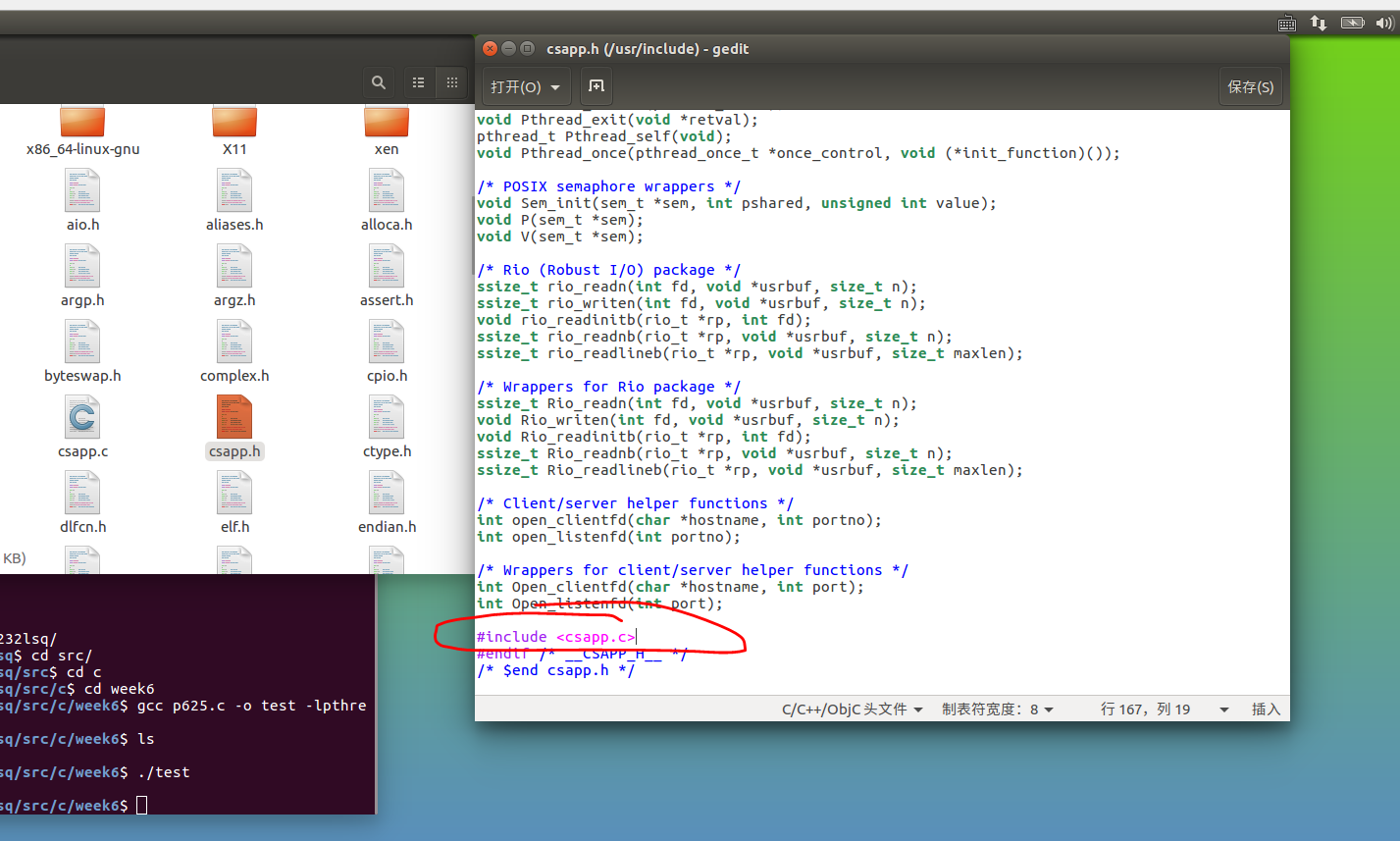
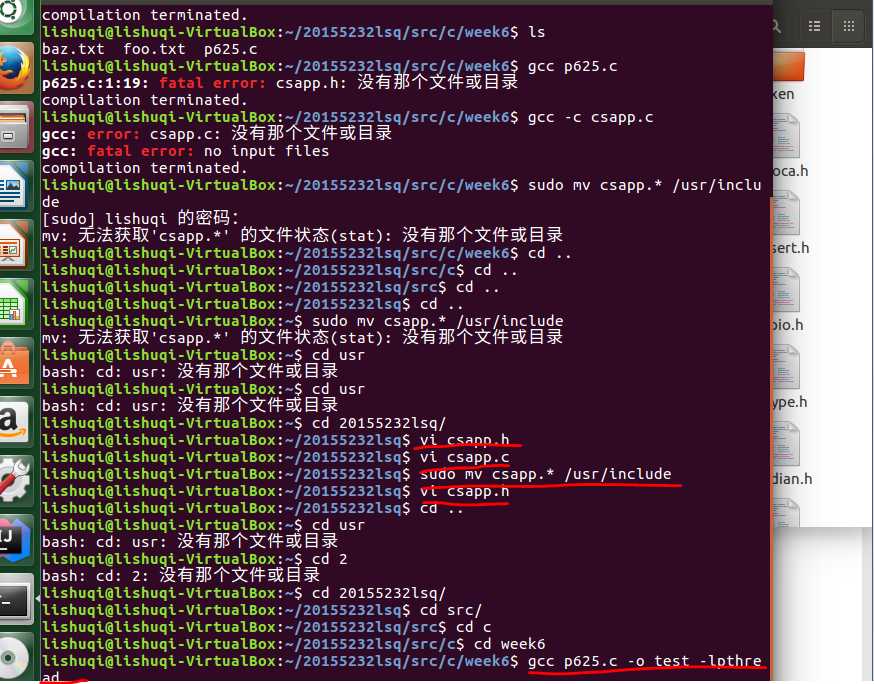
在用命令sudo进行移动的操作,移动到/usr/include中。
在将csapp.h中的内容做一部分修改增加代码,然后用命令
gcc ***.c -o **** -lpthread
进行编译,然后再运行,问题得以解决。
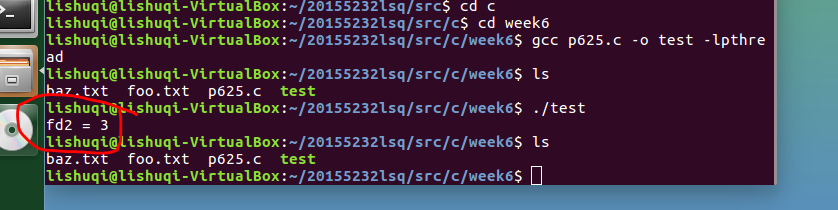
-
问题2:在运行课本p633页代码时,出现错误:地址错误的问题
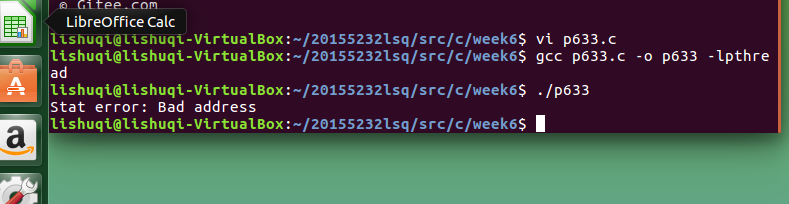
-
问题2解决方案:
在网上搜索后暂未解决。
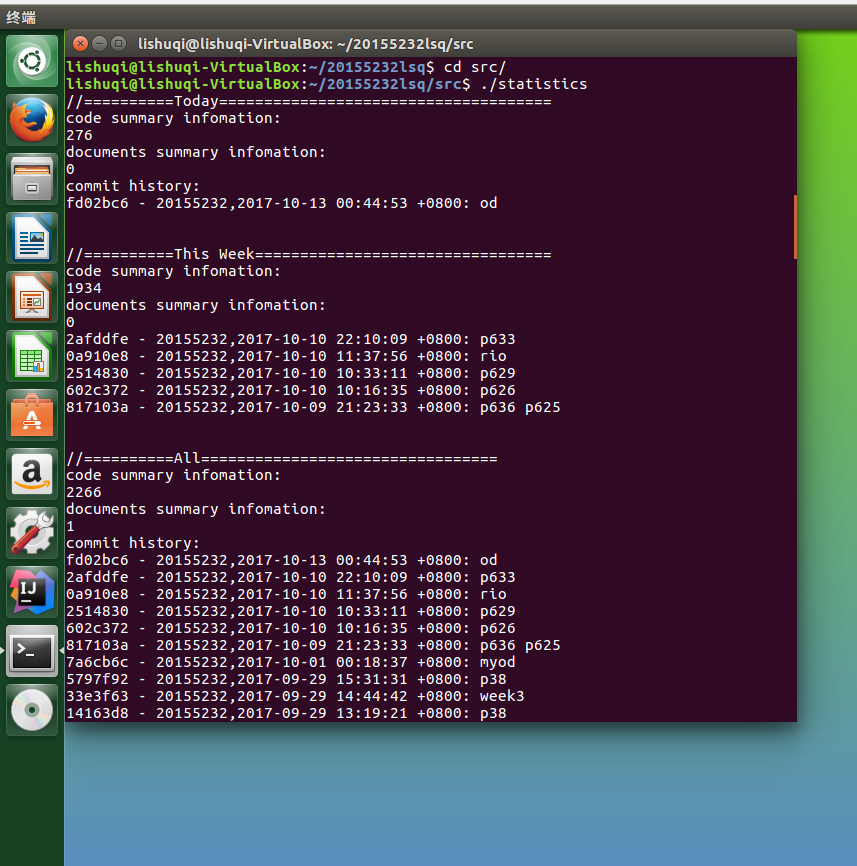
代码托管

上周考试错题总结
无
结对及互评
点评模板:
暂无
本周结对学习情况
- [20155215](http://www.cnblogs.com/xuanyan/p/7673735.html)
- 结对学习内容
- 共同学习课本第十章和附录A内容
- 分析课本中代码遇到的问题
思考
这周的学习内容主要是对文件的处理操作。教材中有很多的代码,通过自己运行加深了理解。而且在遇到问题后能通过自己查询然后解决会记忆更加深刻,也对以后的学习奠定了基础。
- 运行课本p636页课后习题:
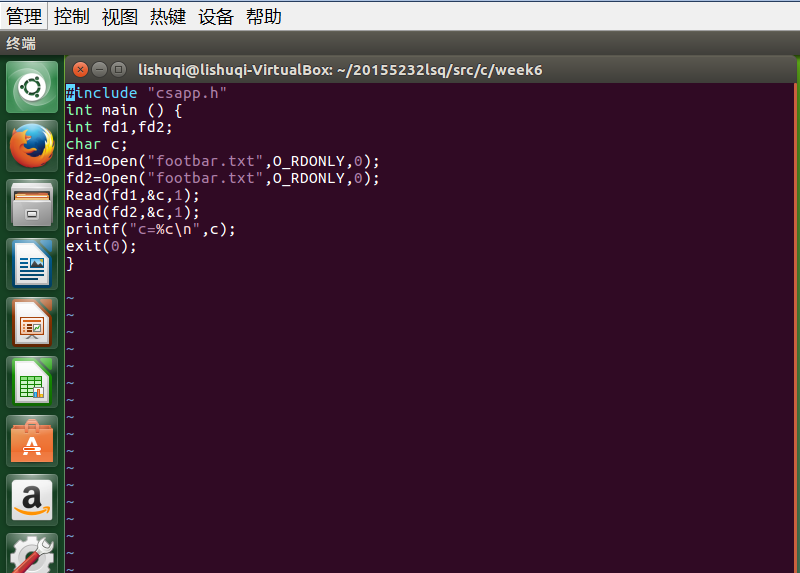
运行结果:
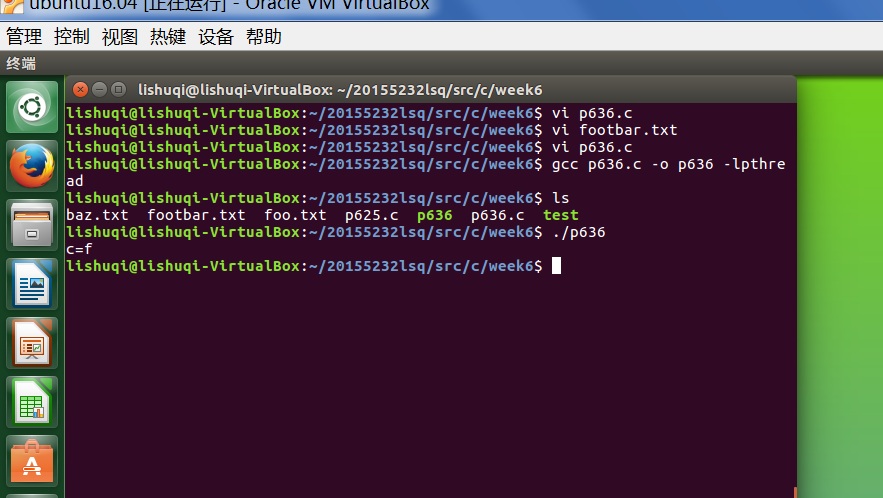
从而更加说明了通过对代码的编译运行对代码的理解又加深了印象,也能得到正确的答案。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第四周 | 12/12 | 1/1 | 20/20 | |
| 第五周 | 271/283 | 1/2 | 15/15 | |
| 第6周 | 276/283 | 2/3 | 18/18 | |
| 尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。 | ||||
| 耗时估计的公式 | ||||
| :Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。 |
-
计划学习时间:12小时
-
实际学习时间:18小时
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理