

hadoop搭建
hadoop版本:2.7.4
java版本:1.8.0
os: ubuntu16.04 server
安装:
1.安装java。
2.下载haddop-2.7.4-bin.tar.gz, 解压,如图

hadoop的配置文件位于 hadoop安装目录下的 etc/hadoop下
通用配置
1.JAVA_HOME
修改hadoop-env.sh, 设置JAVA_HOME=java安装路径
2.HADOOP_HOME
修改/etc/profile, 设置HADOOP_HOME=HADOOP根目录, source /etc/profile
=========================================================
1.单机模式
2.伪分布式模式
1)etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
2) etc/hadoop/hdfs-site.html
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
3)ssh免密码登录
ssh-keygen -t rsa
ssh-copy-id -i ~/.ssh/id_rsa.pub localhost
4)
格式化文件系统 hdfs namenode -format
启动 haddop ./sbin/start-all.sh
查看 hadoop是不是以分布式的方式启动了 jps
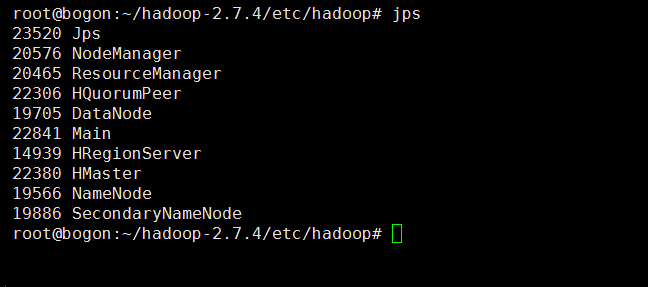
可以看到hadoop有多个进程,而不是在一个进程中。
3. 完全分布式搭建
1) 修改hosts, 比如有3台机器 192.168.233.135(namenode) node1 192.168.233.131(secondnamenode, datanode) node2 192.168.233.134 node3(datanode)
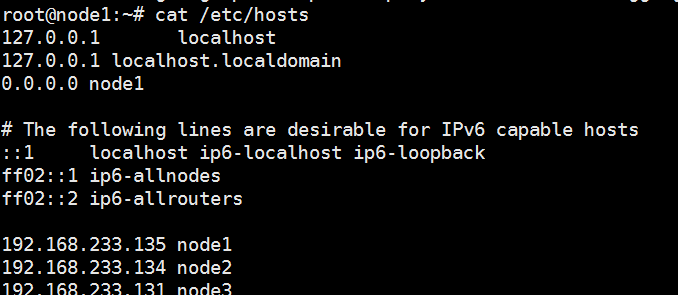
同步到每台机器, 修改每台机器hostname

重启host服务生效
2) 配置ssh免密码登录
namenode免密码访问各个节点包括自己
ssh-keygen -t rsa
ssh-copy-id -i ~/.ssh/id_rsa.pub node2
3)配置core-site.xml
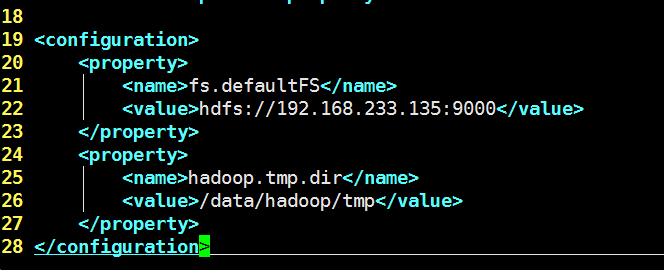
fs.defaultFs配置为namenode的地址
4)配置hdfs-site.xml
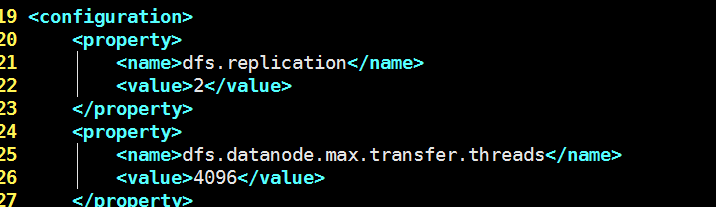
5)配置datanode, vim etc/hadoop/slaves
输入datanode的主机地址,一行一个

6)配置SecondaryNameNode, vim etc/hadoop/masters
输入SecondaryNameNode的主机地址, 一行一个

修改hdfs-site.xml
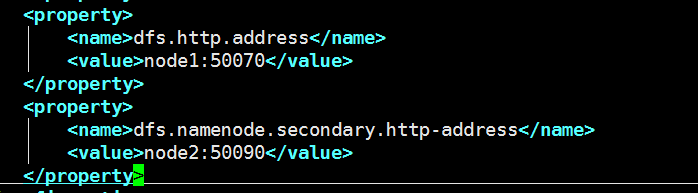
7)上述文件都同步到每一台机器
8)修改环境变量, hadoop-env.sh设置java路径
9)格式化文件系统 hadoop namenode -format
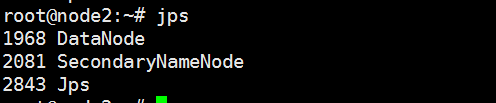
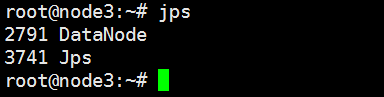
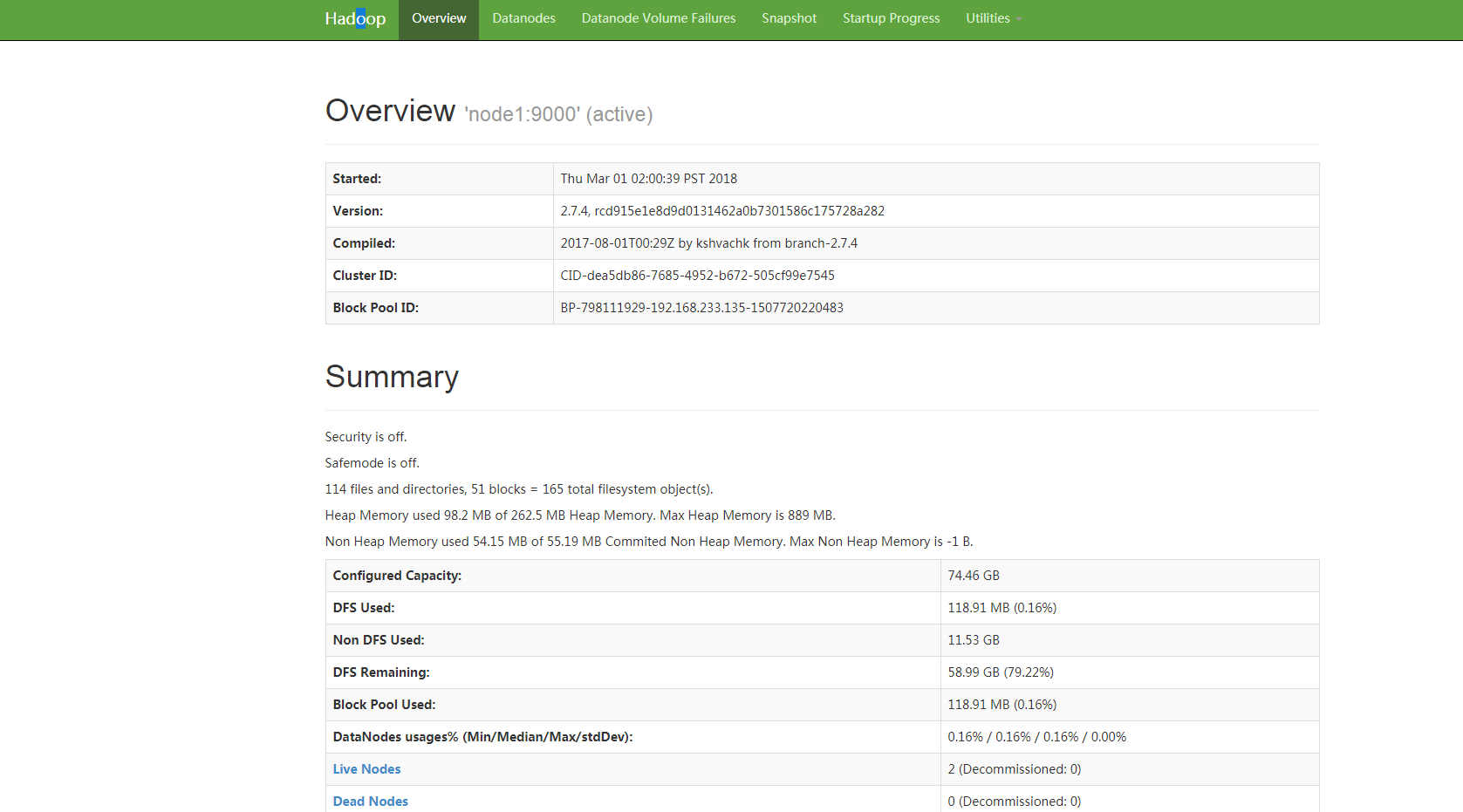
10) 启动hdfs ./sbin/start-dfs.sh, 正常情况查看java进程如图
node1

node2
node3
4. hadoop用户权限管理
hadoop的用户权限管理依赖于posix平台的权限管理, 文件或目录的权限分为rwx, 对于文件而言,r代表是否可读, w代表可写,x没有意义, 对于目录而言, r代表是否可以列出目录下子文件或子目录, w代表是否可以增删改目录,x是是否可以访问子目录
类似于*nix系统, 文件权限分为owner(所有者), group(所有者所属组), other(其他), 比如
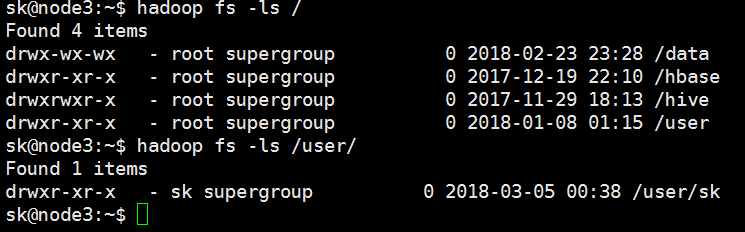
如上图所示, /user/sk 的owner为sk(rwx), group为supergroup(rx), other(rx)
hadoop会识别启动hadoop进程的用户,和组,比如以linux下sk用户执行 hadoop fs -ls /, 当前用户则为sk,组为sk所属用户组.
eg: /data的权限为owner(rwx), group(wx), other(wx), 如果以sk用户执行hadoop fs -ls /data, 则会报如下错误:

hdfs支持类似unix的chmod, chgrp, chown操作。如果要为hadoop新增多个用户,实现访问控制, 可以如下操作:
1) 在*unix上新增用户test adduser test --group hadoop
2) 以supergroup在hdfs上新建一个用户目录, 比如 hadoop fs -mkdir -p /user/test
3) 更改hdfs目录权限, hadoop fs -chown sk[:xx] /user/test, hadoop fs -chmod 777 /user/test/
4) 切换到test用户, 就可以以test用户向hdfs /user/test下增加文件或执行hadoop程序了

