
Python爬虫入门教程:博客园首页推荐博客排行的秘密
1. 前言
虽然博客园注册已经有五年多了,但是最近才正式开始在这里写博客。(进了博客园才知道这里面个个都是人才,说话又好听,超喜欢这里...)但是由于写的内容都是软件测试相关,热度一直不是很高。看到首页的推荐博客排行时,心里痒痒的,想想看看这些大佬究竟是写了什么文章这么受欢迎,可以被推荐。所以用Python抓取了这100位推荐博客,简单分析了每个博客的文章分类,阅读排行榜,评论排行榜及推荐排行榜,最后统计汇总并生成词云。正好这也算是一篇非常好的Python爬虫入门教程了。
2. 环境准备
2.1 操作系统及浏览器版本
Windows 10
Chrome 62
2.2 Python版本
Python 2.7
2.3 用到的lib库
1. requests Http库
2. re 正则表达式
3. json json数据处理
4. BeautifulSoup Html网页数据提取
5. jieba 分词
6. wordcloud 生成词云
7. concurrent.futures 异步并发
所有模块均可使用pip命令安装,如下:
pip install requests pip install beautifulsoup4 pip install jieba pip install wordcloud pip install futures
3. 编写爬虫
上面的环境准备好之后,我们正式开始编写爬虫,但是写代码之前,我们首先需要对需要爬取的页面进行分析。
3.1 页面分析
3.1.1 博客园首页推荐博客排行
1. 运行Chrome浏览器,按快捷键F12打开开发者工具,打开博客园首页:https://www.cnblogs.com/
2. 在右侧点击Network,选中XHR类型,点击下面的每一个请求都可以看到详细的Http请求信息
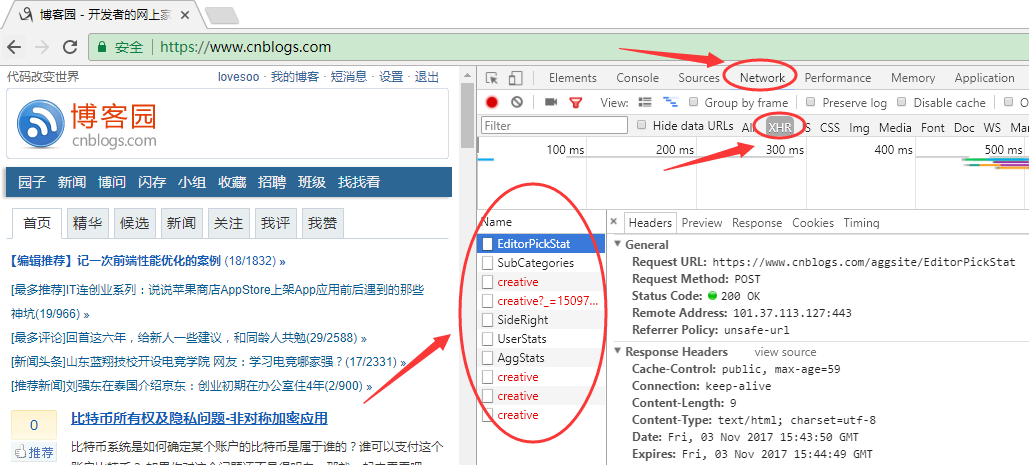
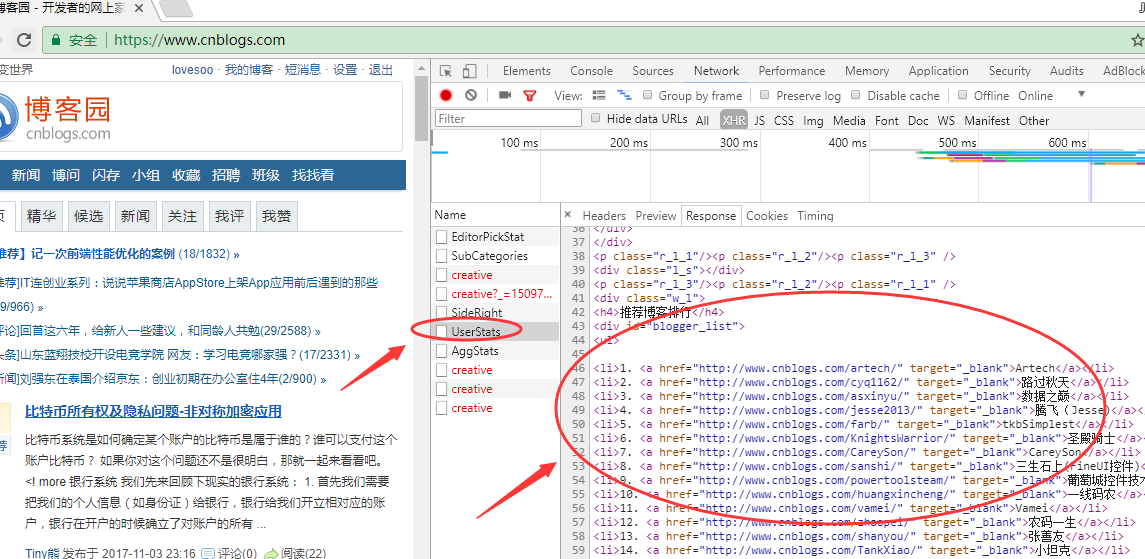
3. 依次选中右侧的Response,查看接口响应,筛选我们需要的接口,这里我们找到了UserStats接口,可以看到这个接口返回了我们需要的“推荐博客排行”信息
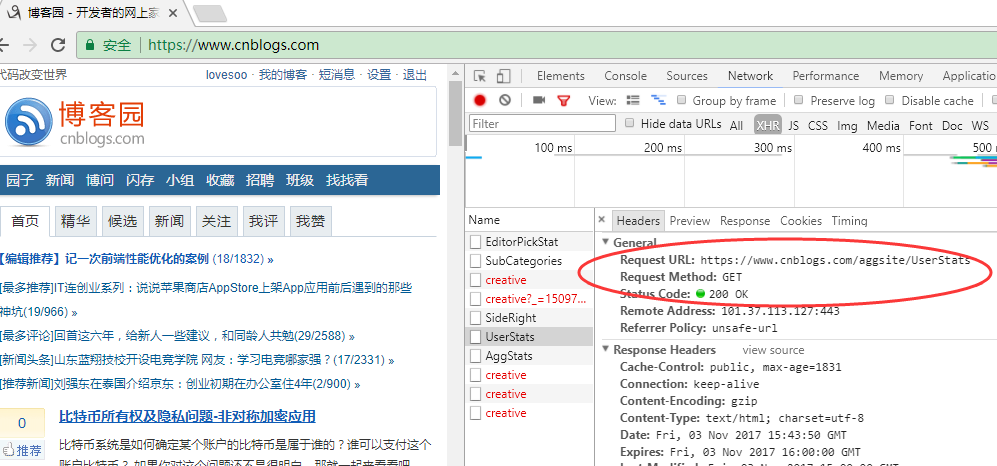
4. 点击右侧Headers查看详细的接口信息,可以看到这是一个简单的Http GET接口,不需要传递任何参数:https://www.cnblogs.com/aggsite/UserStats
5. 这样我们使用requests编写简单的请求就可以获取首页“推荐博客排行”信息
#coding:utf-8 import requests r=requests.get('https://www.cnblogs.com/aggsite/UserStats') print r.text
返回结果如下:


<p class="r_l_3"/><p class="r_l_2"/><p class="r_l_1" /> <div class="w_l"> <h4>博问专家排行</h4> <div> <ul> <li><a href="http://q.cnblogs.com/u/Galactica/" target="_blank">Launcher</a></li> <li><a href="http://q.cnblogs.com/u/astar/" target="_blank">Astar</a></li> <li><a href="http://q.cnblogs.com/u/humin/" target="_blank">幻天芒</a></li> <li><a href="http://q.cnblogs.com/u/dudu/" target="_blank">dudu</a></li> <li><a href="http://q.cnblogs.com/u/puda/" target="_blank">爱编程的大叔</a></li> <li><a href="http://q.cnblogs.com/u/downmoon/" target="_blank">邀月</a></li> <li><a href="http://q.cnblogs.com/u/wrx362114/" target="_blank">吴瑞祥</a></li> <li><a href="http://q.cnblogs.com/u/dingxue/" target="_blank">丁学</a></li> <li><a href="http://q.cnblogs.com/u/GrayZhang/" target="_blank">Gray Zhang</a></li> <li><a href="http://q.cnblogs.com/u/eaglet/" target="_blank">eaglet</a></li> <li class="blogger_more"><a href="http://q.cnblogs.com/q/rank" target="_blank">» 更多博问专家</a></li> </ul> </div> </div> <p class="r_l_1"/><p class="r_l_2"/><p class="r_l_3" /> <div class="l_s"></div> <p class="r_l_3"/><p class="r_l_2"/><p class="r_l_1" /> <div class="w_l"> <h4>最新推荐博客</h4> <div> <ul> <li><a href="http://www.cnblogs.com/RainingNight/" target="_blank">雨夜朦胧</a></li> <li><a href="http://www.cnblogs.com/zhenbianshu/" target="_blank">枕边书</a></li> <li><a href="http://www.cnblogs.com/sparkdev/" target="_blank">sparkdev</a></li> <li><a href="http://www.cnblogs.com/ljhdo/" target="_blank">悦光阴</a></li> <li><a href="http://www.cnblogs.com/emrys5/" target="_blank">Emrys5</a></li> <li class="blogger_more"><a href="http://www.cnblogs.com/expert/" target="_blank">» 更多推荐博客</a></li> </ul> </div> </div> <p class="r_l_1"/><p class="r_l_2"/><p class="r_l_3" /> <div class="l_s"></div> <p class="r_l_3"/><p class="r_l_2"/><p class="r_l_1" /> <div class="w_l"> <h4>推荐博客排行</h4> <div id="blogger_list"> <ul> <li>1. <a href="http://www.cnblogs.com/artech/" target="_blank">Artech</a></li> <li>2. <a href="http://www.cnblogs.com/cyq1162/" target="_blank">路过秋天</a></li> <li>3. <a href="http://www.cnblogs.com/asxinyu/" target="_blank">数据之巅</a></li> <li>4. <a href="http://www.cnblogs.com/jesse2013/" target="_blank">腾飞(Jesse)</a></li> <li>5. <a href="http://www.cnblogs.com/farb/" target="_blank">tkbSimplest</a></li> <li>6. <a href="http://www.cnblogs.com/KnightsWarrior/" target="_blank">圣殿骑士</a></li> <li>7. <a href="http://www.cnblogs.com/CareySon/" target="_blank">CareySon</a></li> <li>8. <a href="http://www.cnblogs.com/sanshi/" target="_blank">三生石上(FineUI控件)</a></li> <li>9. <a href="http://www.cnblogs.com/powertoolsteam/" target="_blank">葡萄城控件技术团队</a></li> <li>10. <a href="http://www.cnblogs.com/huangxincheng/" target="_blank">一线码农</a></li> <li>11. <a href="http://www.cnblogs.com/vamei/" target="_blank">Vamei</a></li> <li>12. <a href="http://www.cnblogs.com/zhaopei/" target="_blank">农码一生</a></li> <li>13. <a href="http://www.cnblogs.com/shanyou/" target="_blank">张善友</a></li> <li>14. <a href="http://www.cnblogs.com/TankXiao/" target="_blank">小坦克</a></li> <li>15. <a href="http://www.cnblogs.com/coco1s/" target="_blank">ChokCoco</a></li> <li>16. <a href="http://www.cnblogs.com/JimmyZhang/" target="_blank">Jimmy Zhang</a></li> <li>17. <a href="http://www.cnblogs.com/edisonchou/" target="_blank">Edison Chou</a></li> <li>18. <a href="http://www.cnblogs.com/kenshincui/" target="_blank">KenshinCui</a></li> <li>19. <a href="http://www.cnblogs.com/heyuquan/" target="_blank">滴答的雨</a></li> <li>20. <a href="http://www.cnblogs.com/insus/" target="_blank">Insus.NET</a></li> <li>21. <a href="http://www.cnblogs.com/rubylouvre/" target="_blank">司徒正美</a></li> <li>22. <a href="http://www.cnblogs.com/aaronjs/" target="_blank">【艾伦】</a></li> <li>23. <a href="http://www.cnblogs.com/toutou/" target="_blank">请叫我头头哥</a></li> <li>24. <a href="http://www.cnblogs.com/savorboard/" target="_blank">Savorboard</a></li> <li>25. <a href="http://www.cnblogs.com/lyhabc/" target="_blank">桦仔</a></li> <li>26. <a href="http://www.cnblogs.com/Wayou/" target="_blank">刘哇勇</a></li> <li>27. <a href="http://www.cnblogs.com/gaochundong/" target="_blank">匠心十年</a></li> <li>28. <a href="http://www.cnblogs.com/keepfool/" target="_blank">keepfool</a></li> <li>29. <a href="http://www.cnblogs.com/zuoxiaolong/" target="_blank">左潇龙</a></li> <li>30. <a href="http://www.cnblogs.com/stoneniqiu/" target="_blank">stoneniqiu</a></li> <li>31. <a href="http://www.cnblogs.com/alamiye010/" target="_blank">深蓝色右手</a></li> <li>32. <a href="http://www.cnblogs.com/mindwind/" target="_blank">mindwind</a></li> <li>33. <a href="http://www.cnblogs.com/yanweidie/" target="_blank">焰尾迭</a></li> <li>34. <a href="http://www.cnblogs.com/baihmpgy/" target="_blank">道法自然</a></li> <li>35. <a href="http://www.cnblogs.com/netfocus/" target="_blank">netfocus</a></li> <li>36. <a href="http://www.cnblogs.com/ityouknow/" target="_blank">纯洁的微笑</a></li> <li>37. <a href="http://www.cnblogs.com/snandy/" target="_blank">snandy</a></li> <li>38. <a href="http://www.cnblogs.com/CreateMyself/" target="_blank">Jeffcky</a></li> <li>39. <a href="http://www.cnblogs.com/JustRun1983/" target="_blank">JustRun</a></li> <li>40. <a href="http://www.cnblogs.com/daxnet/" target="_blank">dax.net</a></li> <li>41. <a href="http://www.cnblogs.com/wolf-sun/" target="_blank">wolfy</a></li> <li>42. <a href="http://www.cnblogs.com/index-html/" target="_blank">EtherDream</a></li> <li>43. <a href="http://www.cnblogs.com/wangiqngpei557/" target="_blank">王清培</a></li> <li>44. <a href="http://www.cnblogs.com/kerrycode/" target="_blank">潇湘隐者</a></li> <li>45. <a href="http://www.cnblogs.com/chenxizhang/" target="_blank">陈希章</a></li> <li>46. <a href="http://www.cnblogs.com/freeflying/" target="_blank">自由飞</a></li> <li>47. <a href="http://www.cnblogs.com/lyj/" target="_blank">李永京</a></li> <li>48. <a href="http://www.cnblogs.com/xiaozhi_5638/" target="_blank">周见智</a></li> <li>49. <a href="http://www.cnblogs.com/OceanEyes/" target="_blank">木宛城主</a></li> <li>50. <a href="http://www.cnblogs.com/haogj/" target="_blank">冠军</a></li> <li>51. <a href="http://www.cnblogs.com/highend/" target="_blank">dotNetDR_</a></li> <li>52. <a href="http://www.cnblogs.com/downmoon/" target="_blank">邀月</a></li> <li>53. <a href="http://www.cnblogs.com/hustskyking/" target="_blank">Barret Lee</a></li> <li>54. <a href="http://www.cnblogs.com/chengxingliang/" target="_blank">程兴亮</a></li> <li>55. <a href="http://www.cnblogs.com/sparkdev/" target="_blank">sparkdev</a></li> <li>56. <a href="http://www.cnblogs.com/subconscious/" target="_blank">计算机的潜意识</a></li> <li>57. <a href="http://www.cnblogs.com/murongxiaopifu/" target="_blank">慕容小匹夫</a></li> <li>58. <a href="http://www.cnblogs.com/iamzhanglei/" target="_blank">【当耐特】</a></li> <li>59. <a href="http://www.cnblogs.com/vajoy/" target="_blank">vajoy</a></li> <li>60. <a href="http://www.cnblogs.com/yjmyzz/" target="_blank">菩提树下的杨过</a></li> <li>61. <a href="http://www.cnblogs.com/weidagang2046/" target="_blank">Todd Wei</a></li> <li>62. <a href="http://www.cnblogs.com/huang0925/" target="_blank">黄博文</a></li> <li>63. <a href="http://www.cnblogs.com/LoveJenny/" target="_blank">LoveJenny</a></li> <li>64. <a href="http://www.cnblogs.com/webabcd/" target="_blank">webabcd</a></li> <li>65. <a href="http://www.cnblogs.com/ljhdo/" target="_blank">悦光阴</a></li> <li>66. <a href="http://www.cnblogs.com/leslies2/" target="_blank">风尘浪子</a></li> <li>67. <a href="http://www.cnblogs.com/liuhaorain/" target="_blank">木小楠</a></li> <li>68. <a href="http://www.cnblogs.com/yukaizhao/" target="_blank">玉开</a></li> <li>69. <a href="http://www.cnblogs.com/over140/" target="_blank">农民伯伯</a></li> <li>70. <a href="http://www.cnblogs.com/TerryBlog/" target="_blank">Terry_龙</a></li> <li>71. <a href="http://www.cnblogs.com/bitzhuwei/" target="_blank">BIT祝威</a></li> <li>72. <a href="http://www.cnblogs.com/zjutlitao/" target="_blank">beautifulzzzz</a></li> <li>73. <a href="http://www.cnblogs.com/GoodHelper/" target="_blank">刘冬.NET</a></li> <li>74. <a href="http://www.cnblogs.com/legendxian/" target="_blank">传说中的弦哥</a></li> <li>75. <a href="http://www.cnblogs.com/luminji/" target="_blank">最课程陆敏技</a></li> <li>76. <a href="http://www.cnblogs.com/zichi/" target="_blank">韩子迟</a></li> <li>77. <a href="http://www.cnblogs.com/daizhj/" target="_blank">代震军</a></li> <li>78. <a href="http://www.cnblogs.com/lsxqw2004/" target="_blank">hystar</a></li> <li>79. <a href="http://www.cnblogs.com/dowinning/" target="_blank">随它去吧</a></li> <li>80. <a href="http://www.cnblogs.com/hongru/" target="_blank">岑安</a></li> <li>81. <a href="http://www.cnblogs.com/skyme/" target="_blank">skyme</a></li> <li>82. <a href="http://www.cnblogs.com/DebugLZQ/" target="_blank">DebugLZQ</a></li> <li>83. <a href="http://www.cnblogs.com/unruledboy/" target="_blank">灵感之源</a></li> <li>84. <a href="http://www.cnblogs.com/jyk/" target="_blank">金色海洋(jyk)阳光男孩</a></li> <li>85. <a href="http://www.cnblogs.com/skyivben/" target="_blank">银河</a></li> <li>86. <a href="http://www.cnblogs.com/lovecindywang/" target="_blank">lovecindywang</a></li> <li>87. <a href="http://www.cnblogs.com/graphics/" target="_blank">zdd</a></li> <li>88. <a href="http://www.cnblogs.com/foreach-break/" target="_blank">foreach_break</a></li> <li>89. <a href="http://www.cnblogs.com/zgynhqf/" target="_blank">BloodyAngel</a></li> <li>90. <a href="http://www.cnblogs.com/jeffwongishandsome/" target="_blank">JeffWong</a></li> <li>91. <a href="http://www.cnblogs.com/zhongweiv/" target="_blank">porschev</a></li> <li>92. <a href="http://www.cnblogs.com/me-sa/" target="_blank">坚强2002</a></li> <li>93. <a href="http://www.cnblogs.com/leefreeman/" target="_blank">飘扬的红领巾</a></li> <li>94. <a href="http://www.cnblogs.com/hlxs/" target="_blank">啊汉</a></li> <li>95. <a href="http://www.cnblogs.com/del/" target="_blank">万一</a></li> <li>96. <a href="http://www.cnblogs.com/dinglang/" target="_blank">丁浪</a></li> <li>97. <a href="http://www.cnblogs.com/oppoic/" target="_blank">心态要好</a></li> <li>98. <a href="http://www.cnblogs.com/1-2-3/" target="_blank">1-2-3</a></li> <li>99. <a href="http://www.cnblogs.com/scy251147/" target="_blank">程序诗人</a></li> <li>100. <a href="http://www.cnblogs.com/xinz/" target="_blank">SoftwareTeacher</a></li> <li class="blogger_more"><a href="http://www.cnblogs.com/expert/" target="_blank">» 更多推荐博客</a></li> <li class="blogger_more"><a href="http://www.cnblogs.com/AllBloggers.aspx" target="_blank">» 博客列表(按积分)</a></li> </ul> </div> </div> <p class="r_l_1"/><p class="r_l_2"/><p class="r_l_3" />
可以看到返回的内容是HTML格式,这里我们有两种方法可以获取“推荐博客排行”,一种是使用Beautiful Soup解析Html内容,另外一种是使用正则表达式筛选内容。代码如下:
#coding:utf-8 import requests import re import json from bs4 import BeautifulSoup # 获取推荐博客列表 r = requests.get('https://www.cnblogs.com/aggsite/UserStats') # 使用BeautifulSoup解析 soup = BeautifulSoup(r.text, 'lxml') users = [(i.text, i['href']) for i in soup.select('#blogger_list > ul > li > a') if 'AllBloggers.aspx' not in i['href'] and 'expert' not in i['href']] print json.dumps(users,ensure_ascii=False) # 也可以使用使用正则表达式 user_re=re.compile('<a href="(http://www.cnblogs.com/.+)" target="_blank">(.+)</a>') users=[(name,url) for url,name in re.findall(user_re,r.text) if 'AllBloggers.aspx' not in url and 'expert' not in url] print json.dumps(users,ensure_ascii=False)
运行结果如下:
[["Artech", "http://www.cnblogs.com/artech/"], ["路过秋天", "http://www.cnblogs.com/cyq1162/"], ["数据之巅", "http://www.cnblogs.com/asxinyu/"], ["腾飞(Jesse)", "http://www.cnblogs.com/jesse2013/"], ["tkbSimplest", "http://www.cnblogs.com/farb/"], ["圣殿骑士", "http://www.cnblogs.com/KnightsWarrior/"], ["CareySon", "http://www.cnblogs.com/CareySon/"], ["三生石上(FineUI控件)", "http://www.cnblogs.com/sanshi/"], ["葡萄城控件技术团队", "http://www.cnblogs.com/powertoolsteam/"], ["一线码农", "http://www.cnblogs.com/huangxincheng/"], ["Vamei", "http://www.cnblogs.com/vamei/"], ["农码一生", "http://www.cnblogs.com/zhaopei/"], ["张善友", "http://www.cnblogs.com/shanyou/"], ["小坦克", "http://www.cnblogs.com/TankXiao/"], ["ChokCoco", "http://www.cnblogs.com/coco1s/"], ["Jimmy Zhang", "http://www.cnblogs.com/JimmyZhang/"], ["Edison Chou", "http://www.cnblogs.com/edisonchou/"], ["KenshinCui", "http://www.cnblogs.com/kenshincui/"], ["滴答的雨", "http://www.cnblogs.com/heyuquan/"], ["Insus.NET", "http://www.cnblogs.com/insus/"], ["司徒正美", "http://www.cnblogs.com/rubylouvre/"], ["【艾伦】", "http://www.cnblogs.com/aaronjs/"], ["请叫我头头哥", "http://www.cnblogs.com/toutou/"], ["Savorboard", "http://www.cnblogs.com/savorboard/"], ["桦仔", "http://www.cnblogs.com/lyhabc/"], ["刘哇勇", "http://www.cnblogs.com/Wayou/"], ["匠心十年", "http://www.cnblogs.com/gaochundong/"], ["keepfool", "http://www.cnblogs.com/keepfool/"], ["左潇龙", "http://www.cnblogs.com/zuoxiaolong/"], ["stoneniqiu", "http://www.cnblogs.com/stoneniqiu/"], ["深蓝色右手", "http://www.cnblogs.com/alamiye010/"], ["mindwind", "http://www.cnblogs.com/mindwind/"], ["焰尾迭", "http://www.cnblogs.com/yanweidie/"], ["道法自然", "http://www.cnblogs.com/baihmpgy/"], ["netfocus", "http://www.cnblogs.com/netfocus/"], ["纯洁的微笑", "http://www.cnblogs.com/ityouknow/"], ["snandy", "http://www.cnblogs.com/snandy/"], ["Jeffcky", "http://www.cnblogs.com/CreateMyself/"], ["JustRun", "http://www.cnblogs.com/JustRun1983/"], ["dax.net", "http://www.cnblogs.com/daxnet/"], ["wolfy", "http://www.cnblogs.com/wolf-sun/"], ["EtherDream", "http://www.cnblogs.com/index-html/"], ["王清培", "http://www.cnblogs.com/wangiqngpei557/"], ["潇湘隐者", "http://www.cnblogs.com/kerrycode/"], ["陈希章", "http://www.cnblogs.com/chenxizhang/"], ["自由飞", "http://www.cnblogs.com/freeflying/"], ["李永京", "http://www.cnblogs.com/lyj/"], ["周见智", "http://www.cnblogs.com/xiaozhi_5638/"], ["木宛城主", "http://www.cnblogs.com/OceanEyes/"], ["冠军", "http://www.cnblogs.com/haogj/"], ["dotNetDR_", "http://www.cnblogs.com/highend/"], ["邀月", "http://www.cnblogs.com/downmoon/"], ["Barret Lee", "http://www.cnblogs.com/hustskyking/"], ["程兴亮", "http://www.cnblogs.com/chengxingliang/"], ["sparkdev", "http://www.cnblogs.com/sparkdev/"], ["计算机的潜意识", "http://www.cnblogs.com/subconscious/"], ["慕容小匹夫", "http://www.cnblogs.com/murongxiaopifu/"], ["【当耐特】", "http://www.cnblogs.com/iamzhanglei/"], ["vajoy", "http://www.cnblogs.com/vajoy/"], ["菩提树下的杨过", "http://www.cnblogs.com/yjmyzz/"], ["Todd Wei", "http://www.cnblogs.com/weidagang2046/"], ["黄博文", "http://www.cnblogs.com/huang0925/"], ["LoveJenny", "http://www.cnblogs.com/LoveJenny/"], ["webabcd", "http://www.cnblogs.com/webabcd/"], ["悦光阴", "http://www.cnblogs.com/ljhdo/"], ["风尘浪子", "http://www.cnblogs.com/leslies2/"], ["木小楠", "http://www.cnblogs.com/liuhaorain/"], ["玉开", "http://www.cnblogs.com/yukaizhao/"], ["农民伯伯", "http://www.cnblogs.com/over140/"], ["Terry_龙", "http://www.cnblogs.com/TerryBlog/"], ["BIT祝威", "http://www.cnblogs.com/bitzhuwei/"], ["beautifulzzzz", "http://www.cnblogs.com/zjutlitao/"], ["刘冬.NET", "http://www.cnblogs.com/GoodHelper/"], ["传说中的弦哥", "http://www.cnblogs.com/legendxian/"], ["最课程陆敏技", "http://www.cnblogs.com/luminji/"], ["韩子迟", "http://www.cnblogs.com/zichi/"], ["代震军", "http://www.cnblogs.com/daizhj/"], ["hystar", "http://www.cnblogs.com/lsxqw2004/"], ["随它去吧", "http://www.cnblogs.com/dowinning/"], ["岑安", "http://www.cnblogs.com/hongru/"], ["skyme", "http://www.cnblogs.com/skyme/"], ["DebugLZQ", "http://www.cnblogs.com/DebugLZQ/"], ["灵感之源", "http://www.cnblogs.com/unruledboy/"], ["金色海洋(jyk)阳光男孩", "http://www.cnblogs.com/jyk/"], ["银河", "http://www.cnblogs.com/skyivben/"], ["lovecindywang", "http://www.cnblogs.com/lovecindywang/"], ["zdd", "http://www.cnblogs.com/graphics/"], ["foreach_break", "http://www.cnblogs.com/foreach-break/"], ["BloodyAngel", "http://www.cnblogs.com/zgynhqf/"], ["JeffWong", "http://www.cnblogs.com/jeffwongishandsome/"], ["porschev", "http://www.cnblogs.com/zhongweiv/"], ["坚强2002", "http://www.cnblogs.com/me-sa/"], ["飘扬的红领巾", "http://www.cnblogs.com/leefreeman/"], ["啊汉", "http://www.cnblogs.com/hlxs/"], ["万一", "http://www.cnblogs.com/del/"], ["丁浪", "http://www.cnblogs.com/dinglang/"], ["心态要好", "http://www.cnblogs.com/oppoic/"], ["1-2-3", "http://www.cnblogs.com/1-2-3/"], ["程序诗人", "http://www.cnblogs.com/scy251147/"], ["SoftwareTeacher", "http://www.cnblogs.com/xinz/"]] [["雨夜朦胧", "http://www.cnblogs.com/RainingNight/"], ["枕边书", "http://www.cnblogs.com/zhenbianshu/"], ["sparkdev", "http://www.cnblogs.com/sparkdev/"], ["悦光阴", "http://www.cnblogs.com/ljhdo/"], ["Emrys5", "http://www.cnblogs.com/emrys5/"], ["Artech", "http://www.cnblogs.com/artech/"], ["路过秋天", "http://www.cnblogs.com/cyq1162/"], ["数据之巅", "http://www.cnblogs.com/asxinyu/"], ["腾飞(Jesse)", "http://www.cnblogs.com/jesse2013/"], ["tkbSimplest", "http://www.cnblogs.com/farb/"], ["圣殿骑士", "http://www.cnblogs.com/KnightsWarrior/"], ["CareySon", "http://www.cnblogs.com/CareySon/"], ["三生石上(FineUI控件)", "http://www.cnblogs.com/sanshi/"], ["葡萄城控件技术团队", "http://www.cnblogs.com/powertoolsteam/"], ["一线码农", "http://www.cnblogs.com/huangxincheng/"], ["Vamei", "http://www.cnblogs.com/vamei/"], ["农码一生", "http://www.cnblogs.com/zhaopei/"], ["张善友", "http://www.cnblogs.com/shanyou/"], ["小坦克", "http://www.cnblogs.com/TankXiao/"], ["ChokCoco", "http://www.cnblogs.com/coco1s/"], ["Jimmy Zhang", "http://www.cnblogs.com/JimmyZhang/"], ["Edison Chou", "http://www.cnblogs.com/edisonchou/"], ["KenshinCui", "http://www.cnblogs.com/kenshincui/"], ["滴答的雨", "http://www.cnblogs.com/heyuquan/"], ["Insus.NET", "http://www.cnblogs.com/insus/"], ["司徒正美", "http://www.cnblogs.com/rubylouvre/"], ["【艾伦】", "http://www.cnblogs.com/aaronjs/"], ["请叫我头头哥", "http://www.cnblogs.com/toutou/"], ["Savorboard", "http://www.cnblogs.com/savorboard/"], ["桦仔", "http://www.cnblogs.com/lyhabc/"], ["刘哇勇", "http://www.cnblogs.com/Wayou/"], ["匠心十年", "http://www.cnblogs.com/gaochundong/"], ["keepfool", "http://www.cnblogs.com/keepfool/"], ["左潇龙", "http://www.cnblogs.com/zuoxiaolong/"], ["stoneniqiu", "http://www.cnblogs.com/stoneniqiu/"], ["深蓝色右手", "http://www.cnblogs.com/alamiye010/"], ["mindwind", "http://www.cnblogs.com/mindwind/"], ["焰尾迭", "http://www.cnblogs.com/yanweidie/"], ["道法自然", "http://www.cnblogs.com/baihmpgy/"], ["netfocus", "http://www.cnblogs.com/netfocus/"], ["纯洁的微笑", "http://www.cnblogs.com/ityouknow/"], ["snandy", "http://www.cnblogs.com/snandy/"], ["Jeffcky", "http://www.cnblogs.com/CreateMyself/"], ["JustRun", "http://www.cnblogs.com/JustRun1983/"], ["dax.net", "http://www.cnblogs.com/daxnet/"], ["wolfy", "http://www.cnblogs.com/wolf-sun/"], ["EtherDream", "http://www.cnblogs.com/index-html/"], ["王清培", "http://www.cnblogs.com/wangiqngpei557/"], ["潇湘隐者", "http://www.cnblogs.com/kerrycode/"], ["陈希章", "http://www.cnblogs.com/chenxizhang/"], ["自由飞", "http://www.cnblogs.com/freeflying/"], ["李永京", "http://www.cnblogs.com/lyj/"], ["周见智", "http://www.cnblogs.com/xiaozhi_5638/"], ["木宛城主", "http://www.cnblogs.com/OceanEyes/"], ["冠军", "http://www.cnblogs.com/haogj/"], ["dotNetDR_", "http://www.cnblogs.com/highend/"], ["邀月", "http://www.cnblogs.com/downmoon/"], ["Barret Lee", "http://www.cnblogs.com/hustskyking/"], ["程兴亮", "http://www.cnblogs.com/chengxingliang/"], ["sparkdev", "http://www.cnblogs.com/sparkdev/"], ["计算机的潜意识", "http://www.cnblogs.com/subconscious/"], ["慕容小匹夫", "http://www.cnblogs.com/murongxiaopifu/"], ["【当耐特】", "http://www.cnblogs.com/iamzhanglei/"], ["vajoy", "http://www.cnblogs.com/vajoy/"], ["菩提树下的杨过", "http://www.cnblogs.com/yjmyzz/"], ["Todd Wei", "http://www.cnblogs.com/weidagang2046/"], ["黄博文", "http://www.cnblogs.com/huang0925/"], ["LoveJenny", "http://www.cnblogs.com/LoveJenny/"], ["webabcd", "http://www.cnblogs.com/webabcd/"], ["悦光阴", "http://www.cnblogs.com/ljhdo/"], ["风尘浪子", "http://www.cnblogs.com/leslies2/"], ["木小楠", "http://www.cnblogs.com/liuhaorain/"], ["玉开", "http://www.cnblogs.com/yukaizhao/"], ["农民伯伯", "http://www.cnblogs.com/over140/"], ["Terry_龙", "http://www.cnblogs.com/TerryBlog/"], ["BIT祝威", "http://www.cnblogs.com/bitzhuwei/"], ["beautifulzzzz", "http://www.cnblogs.com/zjutlitao/"], ["刘冬.NET", "http://www.cnblogs.com/GoodHelper/"], ["传说中的弦哥", "http://www.cnblogs.com/legendxian/"], ["最课程陆敏技", "http://www.cnblogs.com/luminji/"], ["韩子迟", "http://www.cnblogs.com/zichi/"], ["代震军", "http://www.cnblogs.com/daizhj/"], ["hystar", "http://www.cnblogs.com/lsxqw2004/"], ["随它去吧", "http://www.cnblogs.com/dowinning/"], ["岑安", "http://www.cnblogs.com/hongru/"], ["skyme", "http://www.cnblogs.com/skyme/"], ["DebugLZQ", "http://www.cnblogs.com/DebugLZQ/"], ["灵感之源", "http://www.cnblogs.com/unruledboy/"], ["金色海洋(jyk)阳光男孩", "http://www.cnblogs.com/jyk/"], ["银河", "http://www.cnblogs.com/skyivben/"], ["lovecindywang", "http://www.cnblogs.com/lovecindywang/"], ["zdd", "http://www.cnblogs.com/graphics/"], ["foreach_break", "http://www.cnblogs.com/foreach-break/"], ["BloodyAngel", "http://www.cnblogs.com/zgynhqf/"], ["JeffWong", "http://www.cnblogs.com/jeffwongishandsome/"], ["porschev", "http://www.cnblogs.com/zhongweiv/"], ["坚强2002", "http://www.cnblogs.com/me-sa/"], ["飘扬的红领巾", "http://www.cnblogs.com/leefreeman/"], ["啊汉", "http://www.cnblogs.com/hlxs/"], ["万一", "http://www.cnblogs.com/del/"], ["丁浪", "http://www.cnblogs.com/dinglang/"], ["心态要好", "http://www.cnblogs.com/oppoic/"], ["1-2-3", "http://www.cnblogs.com/1-2-3/"], ["程序诗人", "http://www.cnblogs.com/scy251147/"], ["SoftwareTeacher", "http://www.cnblogs.com/xinz/"]]
其中BeautifulSoup解析时,我们使用的是CSS选择器.select方法,查找id="blogger_list" > ul >li下的所有a标签元素,同时对结果进行处理,去除了"更多推荐博客"及""博客列表(按积分)链接。
使用正则表达式筛选也是同理:我们首先构造了符合条件的正则表达式,然后使用re.findall找出所有元素,同时对结果进行处理,去除了"更多推荐博客"及""博客列表(按积分)链接。
这样我们就完成了第一步,获取了首页推荐博客列表。
3.1.2 博客随笔分类
1. 同理,我们使用Chrome开发者工具,打开博客页面(如本人博客:http://www.cnblogs.com/lovesoo/)进行分析
2. 我们找到了接口sidecolumn.aspx,这个接口返回了我们需要的信息:随笔分类
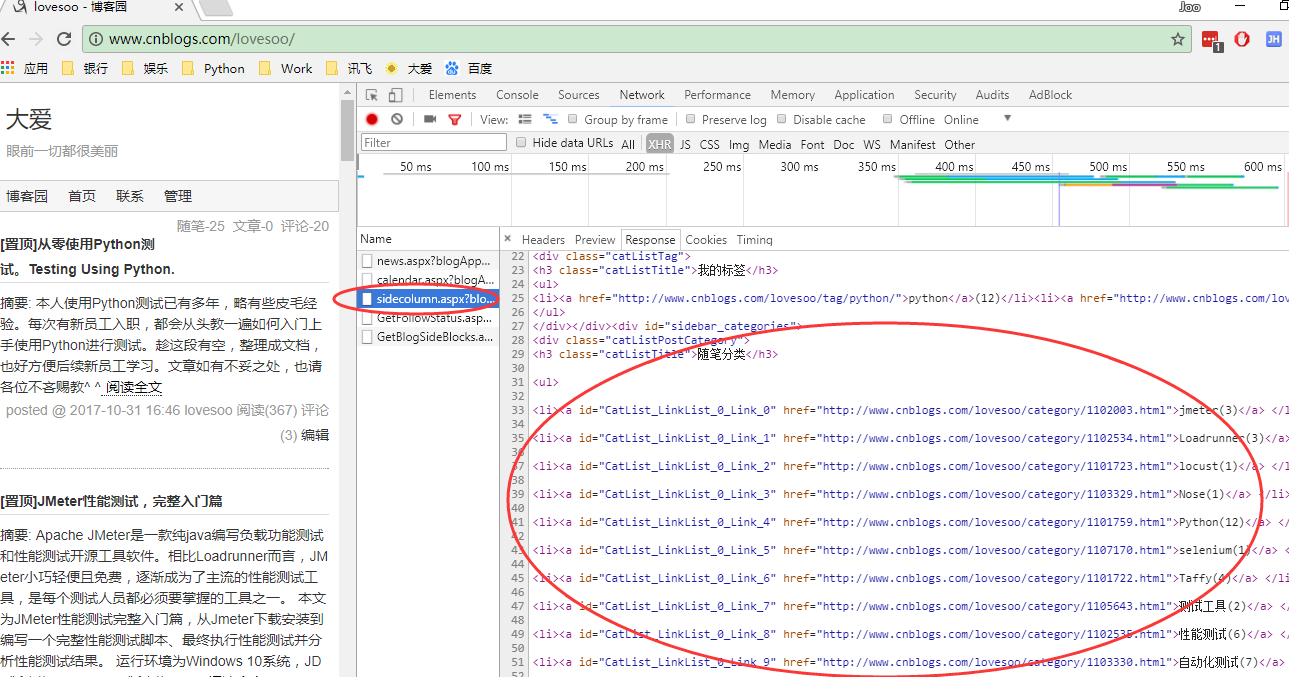
3. 点击Headers查看接口调用信息,可以看到这也是一个GET类型接口,路径含有博客用户名,且传入参数blogApp=用户名:http://www.cnblogs.com/lovesoo/mvc/blog/sidecolumn.aspx?blogApp=lovesoo
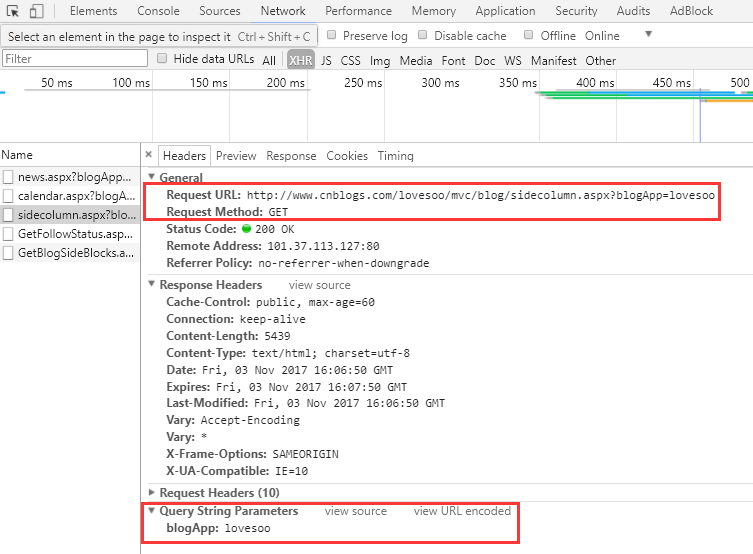
4. 使用Requests发送GET请求,获取“随笔分类”示例代码如下:
#coding:utf-8 import requests user='lovesoo' url = 'http://www.cnblogs.com/{0}/mvc/blog/sidecolumn.aspx'.format(user) blogApp = user payload = dict(blogApp=blogApp) r = requests.get(url, params=payload) print r.text
返回结果如下:
<div id="sidebar_search" class="sidebar-block"> <div id="sidebar_search" class="mySearch"> <h3 class="catListTitle">搜索</h3> <div id="sidebar_search_box"> <div id="widget_my_zzk" class="div_my_zzk"><input type="text" id="q" onkeydown="return zzk_go_enter(event);" class="input_my_zzk"/> <input onclick="zzk_go()" type="button" value="找找看" id="btnZzk" class="btn_my_zzk"/></div> <div id="widget_my_google" class="div_my_zzk"><input type="text" name="google_q" id="google_q" onkeydown="return google_go_enter(event)" class="input_my_zzk"/> <input onclick="google_go()" type="button" value="谷歌搜索" class="btn_my_zzk"/></div> </div> </div> </div><div id="sidebar_shortcut" class="sidebar-block"> <div class="catListLink"> <h3 class ="catListTitle">常用链接</h3> <ul> <li><a href="http://www.cnblogs.com/lovesoo/p/" title="我的博客的随笔列表">我的随笔</a></li><li><a href="http://www.cnblogs.com/lovesoo/MyComments.html" title="我发表过的评论列表">我的评论</a></li><li><a href="http://www.cnblogs.com/lovesoo/OtherPosts.html" title="我评论过的随笔列表">我的参与</a></li><li><a href="http://www.cnblogs.com/lovesoo/RecentComments.html" title="我的博客的评论列表">最新评论</a></li><li><a href="http://www.cnblogs.com/lovesoo/tag/" title="我的博客的标签列表">我的标签</a></li> </ul> <div id="itemListLin_con" style="display:none;"> <ul> </ul> </div> </div></div><div id="sidebar_toptags" class="sidebar-block"> <div class="catListTag"> <h3 class="catListTitle">我的标签</h3> <ul> <li><a href="http://www.cnblogs.com/lovesoo/tag/python/">python</a>(12)</li><li><a href="http://www.cnblogs.com/lovesoo/tag/http/">http</a>(7)</li><li><a href="http://www.cnblogs.com/lovesoo/tag/%E6%80%A7%E8%83%BD%E6%B5%8B%E8%AF%95/">性能测试</a>(7)</li><li><a href="http://www.cnblogs.com/lovesoo/tag/%E8%87%AA%E5%8A%A8%E5%8C%96%E6%B5%8B%E8%AF%95/">自动化测试</a>(4)</li><li><a href="http://www.cnblogs.com/lovesoo/tag/taffy/">taffy</a>(4)</li><li><a href="http://www.cnblogs.com/lovesoo/tag/webservice/">webservice</a>(3)</li><li><a href="http://www.cnblogs.com/lovesoo/tag/jmeter/">jmeter</a>(3)</li><li><a href="http://www.cnblogs.com/lovesoo/tag/nose/">nose</a>(3)</li><li><a href="http://www.cnblogs.com/lovesoo/tag/LoadRunner/">LoadRunner</a>(3)</li><li><a href="http://www.cnblogs.com/lovesoo/tag/%E8%87%AA%E5%8A%A8%E5%8C%96/">自动化</a>(3)</li><li><a href="http://www.cnblogs.com/lovesoo/tag/">更多</a></li> </ul> </div></div><div id="sidebar_categories"> <div class="catListPostCategory"> <h3 class="catListTitle">随笔分类</h3> <ul> <li><a id="CatList_LinkList_0_Link_0" href="http://www.cnblogs.com/lovesoo/category/1102003.html">jmeter(3)</a> </li> <li><a id="CatList_LinkList_0_Link_1" href="http://www.cnblogs.com/lovesoo/category/1102534.html">Loadrunner(3)</a> </li> <li><a id="CatList_LinkList_0_Link_2" href="http://www.cnblogs.com/lovesoo/category/1101723.html">locust(1)</a> </li> <li><a id="CatList_LinkList_0_Link_3" href="http://www.cnblogs.com/lovesoo/category/1103329.html">Nose(1)</a> </li> <li><a id="CatList_LinkList_0_Link_4" href="http://www.cnblogs.com/lovesoo/category/1101759.html">Python(12)</a> </li> <li><a id="CatList_LinkList_0_Link_5" href="http://www.cnblogs.com/lovesoo/category/1107170.html">selenium(1)</a> </li> <li><a id="CatList_LinkList_0_Link_6" href="http://www.cnblogs.com/lovesoo/category/1101722.html">Taffy(4)</a> </li> <li><a id="CatList_LinkList_0_Link_7" href="http://www.cnblogs.com/lovesoo/category/1105643.html">测试工具(2)</a> </li> <li><a id="CatList_LinkList_0_Link_8" href="http://www.cnblogs.com/lovesoo/category/1102535.html">性能测试(6)</a> </li> <li><a id="CatList_LinkList_0_Link_9" href="http://www.cnblogs.com/lovesoo/category/1103330.html">自动化测试(7)</a> </li> </ul> </div> <div class="catListPostArchive"> <h3 class="catListTitle">随笔档案</h3> <ul> <li><a id="CatList_LinkList_1_Link_0" href="http://www.cnblogs.com/lovesoo/archive/2017/11.html">2017年11月 (4)</a> </li> <li><a id="CatList_LinkList_1_Link_1" href="http://www.cnblogs.com/lovesoo/archive/2017/10.html">2017年10月 (21)</a> </li> </ul> </div> </div><div id="sidebar_scorerank" class="sidebar-block"> <div class="catListBlogRank"> <h3 class="catListTitle">积分与排名</h3> <ul> <li class="liScore"> 积分 - 4540 </li> <li class="liRank"> 排名 - 51509 </li> </ul> </div> </div><div id="sidebar_recentcomments" class="sidebar-block"><div id="recent_comments_wrap"> <div class="catListComment"> <h3 class = "catListTitle">最新评论</h3> <div id="RecentCommentsBlock"></div> </div> </div></div><div id="sidebar_topviewedposts" class="sidebar-block"><div id="topview_posts_wrap"> <div class="catListView"> <h3 class = "catListTitle">阅读排行榜</h3> <div id="TopViewPostsBlock"></div> </div> </div></div><div id="sidebar_topcommentedposts" class="sidebar-block"><div id="topfeedback_posts_wrap"> <div class="catListFeedback"> <h3 class="catListTitle">评论排行榜</h3> <div id="TopFeedbackPostsBlock"></div> </div> </div></div><div id="sidebar_topdiggedposts" class="sidebar-block"><div id="topdigg_posts_wrap"> <div class="catListView"> <h3 class = "catListTitle">推荐排行榜</h3> <div id="TopDiggPostsBlock"></div> </div></div></div>
同理,我们使用BeautifulSoup解析获取分类信息,同时使用正则表达式获取分类名及文章数目,代码如下:
#coding:utf-8 import requests import re import json from bs4 import BeautifulSoup # 获取博客随笔分类 user='lovesoo' category_re = re.compile('(.+)\((\d+)\)') url = 'http://www.cnblogs.com/{0}/mvc/blog/sidecolumn.aspx'.format(user) blogApp = user payload = dict(blogApp=blogApp) r = requests.get(url, params=payload) soup = BeautifulSoup(r.text, 'lxml') category = [re.search(category_re, i.text).groups() for i in soup.select('.catListPostCategory > ul > li') if re.search(category_re, i.text)] print json.dumps(category,ensure_ascii=False)
返回结果如下:
[["jmeter", "3"], ["Loadrunner", "3"], ["locust", "1"], ["Nose", "1"], ["Python", "12"], ["selenium", "1"], ["Taffy", "4"], ["测试工具", "2"], ["性能测试", "6"], ["自动化测试", "7"]]
这样我们就完成了第二步,获取了博客的分类目录及文章数量信息。
3.1.3 博客阅读\评论\推荐排行榜
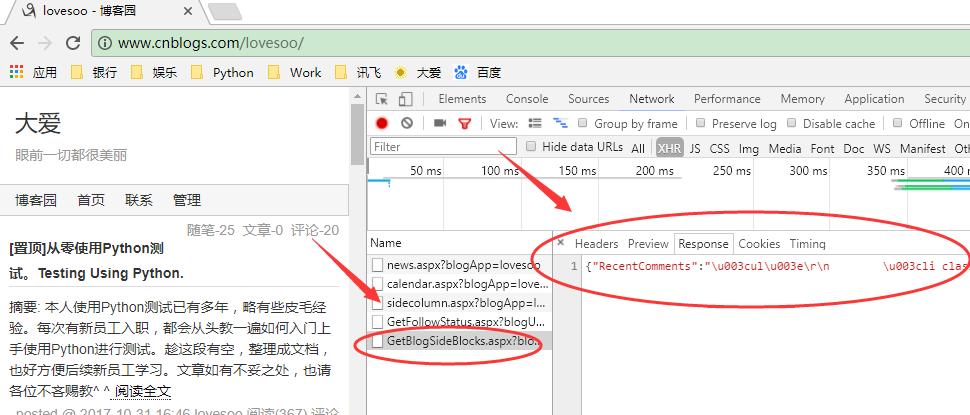
1. 下面我们开始获取博客的排行榜信息,同理我们找到了接口GetBlogSideBlocks.aspx,它返回了我们需要的排行榜信息
2. 点击Headers查看接口调用信息,可以看到这是一个GET请求接口,传入参数有2个,分别是blogApp和showFlag,其中blogApp是博客用户名,showFlag是显示标记,默认值为ShowRecentComment,ShowTopViewPosts,ShowTopFeedbackPosts,ShowTopDiggPosts分别代表返回最新评论,阅读排行榜,评论排行榜,推荐排行榜。根据需要我们配置只返回3个排行榜信息即可:http://www.cnblogs.com/mvc/Blog/GetBlogSideBlocks.aspx?blogApp=lovesoo&showFlag=ShowTopViewPosts%2CShowTopFeedbackPosts%2CShowTopDiggPosts
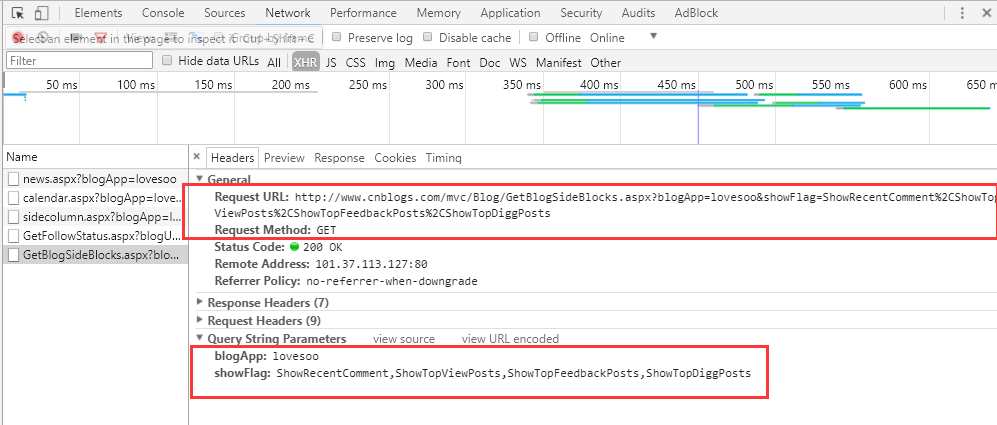
3. 使用Requests调用GET接口获取排行榜信息,示例代码如下:
#coding:utf-8 import requests import json # 获取博客阅读排行榜,评论排行榜及推荐排行榜信息 user='lovesoo' url = 'http://www.cnblogs.com/mvc/Blog/GetBlogSideBlocks.aspx' blogApp = user showFlag = 'ShowTopViewPosts,ShowTopFeedbackPosts,ShowTopDiggPosts' payload = dict(blogApp=blogApp, showFlag=showFlag) r = requests.get(url, params=payload) print json.dumps(r.json(),ensure_ascii=False)
返回结果如下:
{"RecentComments": "", "TopFeedbackPosts": "<ul><li><a href=\"http://www.cnblogs.com/lovesoo/p/7742189.html\">1. JMeter性能测试,完整入门篇(6)</a></li><li><a href=\"http://www.cnblogs.com/lovesoo/p/7762796.html\">2. Web性能测试工具之ab入门篇(4)</a></li><li><a href=\"http://www.cnblogs.com/lovesoo/p/7754067.html\">3. 初识Http协议抓包工具—Fiddler(3)</a></li><li><a href=\"http://www.cnblogs.com/lovesoo/p/7762148.html\">4. 从零使用Python测试。Testing Using Python.(3)</a></li><li><a href=\"http://www.cnblogs.com/lovesoo/p/7719070.html\">5. Locust性能测试框架,从入门到精通(2)</a></li></ul>", "TopDiggPosts": "<ul><li><a href=\"http://www.cnblogs.com/lovesoo/p/7754067.html\">1. 初识Http协议抓包工具—Fiddler(6)</a></li><li><a href=\"http://www.cnblogs.com/lovesoo/p/7742189.html\">2. JMeter性能测试,完整入门篇(4)</a></li><li><a href=\"http://www.cnblogs.com/lovesoo/p/7727042.html\">3. Loadrunner 11检查点使用方法总结(2)</a></li><li><a href=\"http://www.cnblogs.com/lovesoo/p/7762796.html\">4. Web性能测试工具之ab入门篇(1)</a></li><li><a href=\"http://www.cnblogs.com/lovesoo/p/7762148.html\">5. 从零使用Python测试。Testing Using Python.(1)</a></li></ul>", "TopViewPosts": "<ul><li><a href=\"http://www.cnblogs.com/lovesoo/p/7754067.html\">1. 初识Http协议抓包工具—Fiddler(954)</a></li><li><a href=\"http://www.cnblogs.com/lovesoo/p/7742189.html\">2. JMeter性能测试,完整入门篇(441)</a></li><li><a href=\"http://www.cnblogs.com/lovesoo/p/7762796.html\">3. Web性能测试工具之ab入门篇(384)</a></li><li><a href=\"http://www.cnblogs.com/lovesoo/p/7762148.html\">4. 从零使用Python测试。Testing Using Python.(367)</a></li><li><a href=\"http://www.cnblogs.com/lovesoo/p/7748487.html\">5. Robot Framework自动化测试框架初探(274)</a></li></ul>"}
可以看出,这个接口返回数据格式与前2个不同,返回的是json格式,有四个key:RecentComments,TopViewPosts,TopFeedbackPosts,TopDiggPosts分别对应最新评论,阅读排行榜,评论排行榜,推荐排行榜,而每个key里的value又是html格式,针对这个value我们编写统一的信息提取方法:使用BeautifulSoup解析获取文本及链接信息,同时使用正则表达式获取文章标题及次数,示例代码如下:
#coding:utf-8 import requests import re import json from bs4 import BeautifulSoup def getPostsDetail(Posts): # 获取文章详细信息:标题,次数,URL post_re = re.compile('\d+\. (.+)\((\d+)\)') soup = BeautifulSoup(Posts, 'lxml') return [list(re.search(post_re, i.text).groups()) + [i['href']] for i in soup.find_all('a')] # 获取博客阅读排行榜,评论排行榜及推荐排行榜信息 user='lovesoo' url = 'http://www.cnblogs.com/mvc/Blog/GetBlogSideBlocks.aspx' blogApp = user showFlag = 'ShowTopViewPosts,ShowTopFeedbackPosts,ShowTopDiggPosts' payload = dict(blogApp=blogApp, showFlag=showFlag) r = requests.get(url, params=payload) TopViewPosts = getPostsDetail(r.json()['TopViewPosts']) TopFeedbackPosts = getPostsDetail(r.json()['TopFeedbackPosts']) TopDiggPosts = getPostsDetail(r.json()['TopDiggPosts']) print json.dumps(dict(TopViewPosts=TopViewPosts, TopFeedbackPosts=TopFeedbackPosts, TopDiggPosts=TopDiggPosts),ensure_ascii=False)
运行结果如下:
{"TopFeedbackPosts": [["JMeter性能测试,完整入门篇", "6", "http://www.cnblogs.com/lovesoo/p/7742189.html"], ["Web性能测试工具之ab入门篇", "4", "http://www.cnblogs.com/lovesoo/p/7762796.html"], ["初识Http协议抓包工具—Fiddler", "3", "http://www.cnblogs.com/lovesoo/p/7754067.html"], ["从零使用Python测试。Testing Using Python.", "3", "http://www.cnblogs.com/lovesoo/p/7762148.html"], ["Locust性能测试框架,从入门到精通", "2", "http://www.cnblogs.com/lovesoo/p/7719070.html"]], "TopDiggPosts": [["初识Http协议抓包工具—Fiddler", "6", "http://www.cnblogs.com/lovesoo/p/7754067.html"], ["JMeter性能测试,完整入门篇", "4", "http://www.cnblogs.com/lovesoo/p/7742189.html"], ["Loadrunner 11检查点使用方法总结", "2", "http://www.cnblogs.com/lovesoo/p/7727042.html"], ["Web性能测试工具之ab入门篇", "1", "http://www.cnblogs.com/lovesoo/p/7762796.html"], ["从零使用Python测试。Testing Using Python.", "1", "http://www.cnblogs.com/lovesoo/p/7762148.html"]], "TopViewPosts": [["初识Http协议抓包工具—Fiddler", "954", "http://www.cnblogs.com/lovesoo/p/7754067.html"], ["JMeter性能测试,完整入门篇", "441", "http://www.cnblogs.com/lovesoo/p/7742189.html"], ["Web性能测试工具之ab入门篇", "384", "http://www.cnblogs.com/lovesoo/p/7762796.html"], ["从零使用Python测试。Testing Using Python.", "367", "http://www.cnblogs.com/lovesoo/p/7762148.html"], ["Robot Framework自动化测试框架初探", "274", "http://www.cnblogs.com/lovesoo/p/7748487.html"]]}
至此,我们完成了第三步也是最重要的,提取博客排行榜信息。下面我们开始使用异步并发抓取100位大佬的博客信息。
3.2 异步并发抓取
我们把上面的三步提取信息操作均封装成函数,并将博客提取信息的两步(提取分类及排行榜)封装成一个统一的函数供异步并发调用即可。这里我们推荐使用多进程的方式,配置的并发数与CPU核数一致即可,示例代码如下:
# coding:utf-8 import requests import re import json from bs4 import BeautifulSoup from concurrent import futures def getUsers(): # 获取推荐博客列表 r = requests.get('https://www.cnblogs.com/aggsite/UserStats') # 使用BeautifulSoup解析 soup = BeautifulSoup(r.text, 'lxml') users = [(i.text, i['href']) for i in soup.select('#blogger_list > ul > li > a') if 'AllBloggers.aspx' not in i['href'] and 'expert' not in i['href']] # 也可以使用使用正则表达式 # user_re=re.compile('<a href="(http://www.cnblogs.com/.+)" target="_blank">(.+)</a>') # users=[(name,url) for url,name in re.findall(blog_re,r.text) if 'AllBloggers.aspx' not in url and 'expert' not in url] return users def getPostsDetail(Posts): # 获取文章详细信息:标题,次数,URL post_re = re.compile('\d+\. (.+)\((\d+)\)') soup = BeautifulSoup(Posts, 'lxml') return [list(re.search(post_re, i.text).groups()) + [i['href']] for i in soup.find_all('a')] def getViews(user): # 获取博客阅读排行榜,评论排行榜及推荐排行榜信息 url = 'http://www.cnblogs.com/mvc/Blog/GetBlogSideBlocks.aspx' blogApp = user showFlag = 'ShowTopViewPosts,ShowTopFeedbackPosts,ShowTopDiggPosts' payload = dict(blogApp=blogApp, showFlag=showFlag) r = requests.get(url, params=payload) TopViewPosts = getPostsDetail(r.json()['TopViewPosts']) TopFeedbackPosts = getPostsDetail(r.json()['TopFeedbackPosts']) TopDiggPosts = getPostsDetail(r.json()['TopDiggPosts']) return dict(TopViewPosts=TopViewPosts, TopFeedbackPosts=TopFeedbackPosts, TopDiggPosts=TopDiggPosts) def getCategory(user): # 获取博客随笔分类 category_re = re.compile('(.+)\((\d+)\)') url = 'http://www.cnblogs.com/{0}/mvc/blog/sidecolumn.aspx'.format(user) blogApp = user payload = dict(blogApp=blogApp) r = requests.get(url, params=payload) soup = BeautifulSoup(r.text, 'lxml') category = [re.search(category_re, i.text).groups() for i in soup.select('.catListPostCategory > ul > li') if re.search(category_re, i.text)] return dict(category=category) def getTotal(url): # 获取博客全部信息,包括分类及排行榜信息 # 初始化博客用户名 print 'Spider blog:\t{0}'.format(url) user = url.split('/')[-2] return dict(getViews(user), **getCategory(user)) def mutiSpider(max_workers=4): try: # with futures.ThreadPoolExecutor(max_workers=max_workers) as executor: # 多线程 with futures.ProcessPoolExecutor(max_workers=max_workers) as executor: # 多进程 for blog in executor.map(getTotal, [i[1] for i in users]): blogs.append(blog) except Exception as e: print e if __name__ == '__main__': blogs = [] # 获取推荐博客列表 users = getUsers() print json.dumps(users, ensure_ascii=False) # 多线程/多进程获取博客信息 mutiSpider() print json.dumps(blogs,ensure_ascii=False)
运行结果:略
3.3 数据处理
数据处理主要是对上面生成的好的大批量数据进行处理,主要是数据合并分组,其中相对复杂的是分类数据,基本处理逻辑如下:
1. 第一步,将所有的分类数据合并保存在一个list中,示例代码:
# 获取所有分类目录信息 category = [category for blog in blogs if blog['category'] for category in blog['category']]
2. 第二步,合并计算相同目录(由于不用的博客可能存在相同的分类,如都有叫做Python的分类,则该分类文章数量需要累加计算),示例代码如下:
def countCategory(category, category_name): # 合并计算目录数 n = 0 for name, count in category: if name.lower() == category_name: n += int(count) return n # 获取所有分类目录信息 category = [category for blog in blogs if blog['category'] for category in blog['category']] # 合并相同目录 new_category = {} for name, count in category: # 全部转换为小写 name = name.lower() if name not in new_category: new_category[name] = countCategory(category, name)
3. 第三步,根据数量进行排序,直接使用sorted方法根据count数进行排序即可,示例代码如下:
sorted(new_category.items(), key=lambda i: int(i[1]), reverse=True)
排行榜数据处理相对比较简单,只需先合并成一个list后再进行排序即可,如阅读排行榜数据处理示例代码:
TopViewPosts = [post for blog in blogs for post in blog['TopViewPosts']] sorted(TopViewPosts, key=lambda i: int(i[1]), reverse=True
3.4 生成词云
生成词云主要步骤如下:
1. 使用join方法拼接list为长文本
2. 使用jieba进行中文分词
3. 使用wordcloud生成词云并保存及展示相关图片
示例代码如下:
# 拼接为长文本 contents = ' '.join([i[0] for i in words]) # 使用结巴分词进行中文分词 cut_texts = ' '.join(jieba.cut(contents)) # 设置字体为黑体,最大词数为2000,背景颜色为白色,生成图片宽1000,高667 cloud = WordCloud(font_path='C:\Windows\Fonts\simhei.ttf', max_words=2000, background_color="white", width=1000, height=667, margin=2) # 生成词云 wordcloud = cloud.generate(cut_texts) # 保存图片 wordcloud.to_file('wordcloud\{0}.png'.format(file_name)) # 展示图片 wordcloud.to_image().show()
4. 结果展示
至此我们完成了一个完整的爬虫逻辑讲解,从页面分析到数据获取,从数据处理到生成词云。下面给大家展示下,我们爬虫的运行结果。
4.1 随笔分类
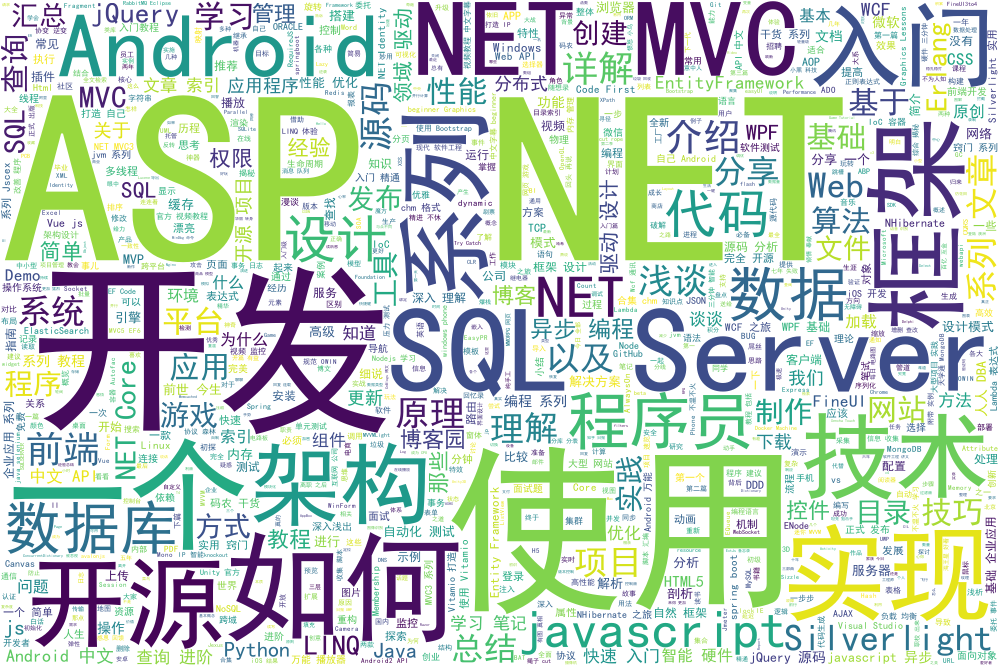
我们分析了所有100位推荐博客的分类(这里发现,居然有不少大佬从来没对文章进行过分类...),并按文章数量进行排序,前10名为:
asp.net, 1246 javascript, 505 c#, 479 ms sql server, 416 asp.net mvc, 392 [01] 技术剖析, 375 jquery, 320 开源项目, 285 15.java/scala, 265 .net framework, 262
生成的词云如下:

4.2 阅读排行榜
我们分析了所有100位推荐博客的阅读排行榜,并按文章阅读数量进行排序,前10名文章为:
CSS中怎么让DIV居中, 899884, http://www.cnblogs.com/DebugLZQ/archive/2011/08/09/2132381.html Python快速教程, 486582, http://www.cnblogs.com/vamei/archive/2012/09/13/2682778.html 我的WCF之旅(1):创建一个简单的WCF程序, 484371, http://www.cnblogs.com/artech/archive/2007/02/26/656901.html 8天学通MongoDB——第一天 基础入门, 413732, http://www.cnblogs.com/huangxincheng/archive/2012/02/18/2356595.html C# 中的委托和事件, 338284, http://www.cnblogs.com/JimmyZhang/archive/2007/09/23/903360.html Java快速教程, 321205, http://www.cnblogs.com/vamei/archive/2013/03/31/2991531.html iOS开发系列--音频播放、录音、视频播放、拍照、视频录制, 278658, http://www.cnblogs.com/kenshincui/p/4186022.html 【原创】说说JSON和JSONP,也许你会豁然开朗,含jQuery用例, 243654, http://www.cnblogs.com/dowinning/archive/2012/04/19/json-jsonp-jquery.html SQL Server 2008 r2 安装过程图解, 235395, http://www.cnblogs.com/downmoon/archive/2010/05/18/1738479.html Wireshark基本介绍和学习TCP三次握手, 235288, http://www.cnblogs.com/TankXiao/archive/2012/10/10/2711777.html
生成的词云如下:

4.3 评论排行榜
我们分析了所有100位推荐博客的评论排行榜,并按文章评论数量进行排序(免费大法好呀~),前10名文章为:
赠书:血战HTML5消除游戏,赢《HTML5实验室:Canvas世界》, 6902, http://www.cnblogs.com/iamzhanglei/archive/2012/07/03/2574083.html 感恩回馈,《ASP.NET Web API 2框架揭秘》免费赠送, 3471, http://www.cnblogs.com/artech/p/book-as-a-present.html 感恩回馈,新鲜出炉的《ASP.NET MVC 5框架揭秘》免费赠送, 1374, http://www.cnblogs.com/artech/p/book-as-a-present-2.html 暴力英语学习法 + 严格的目标管理 = 成功快速靠谱的学好英语, 1369, http://www.cnblogs.com/jesse2013/p/how-to-learn-english.html C# 中的委托和事件, 924, http://www.cnblogs.com/JimmyZhang/archive/2007/09/23/903360.html 【6年开源路】FineUI家族今日全部更新(FineUI + FineUI3to4 + FineUI.Design + AppBox)!, 876, http://www.cnblogs.com/sanshi/p/3577327.html 新书出版《.NET框架设计—模式、配置、工具》感恩回馈社区!, 815, http://www.cnblogs.com/wangiqngpei557/p/4253836.html 我的WCF之旅(1):创建一个简单的WCF程序, 751, http://www.cnblogs.com/artech/archive/2007/02/26/656901.html 扩展GridView控件(索引) - 增加多个常用功能, 577, http://www.cnblogs.com/webabcd/archive/2007/02/04/639830.html 屌丝的出路, 472, http://www.cnblogs.com/JimmyZhang/archive/2012/06/26/2563000.html
生成的词云如下:

4.4 推荐排行榜
我们分析了所有100位推荐博客的推荐排行榜,并按文章推荐数量进行排序,前10名文章为:
暴力英语学习法 + 严格的目标管理 = 成功快速靠谱的学好英语, 1439, http://www.cnblogs.com/jesse2013/p/how-to-learn-english.html 我的WCF之旅(1):创建一个简单的WCF程序, 1203, http://www.cnblogs.com/artech/archive/2007/02/26/656901.html HTTP协议详解, 1166, http://www.cnblogs.com/TankXiao/archive/2012/02/13/2342672.html, 【6年开源路】FineUI家族今日全部更新(FineUI + FineUI3to4 + FineUI.Design + AppBox)!, 806, http://www.cnblogs.com/sanshi/p/3577327.html C# 中的委托和事件, 621, http://www.cnblogs.com/JimmyZhang/archive/2007/09/23/903360.html 【原创】说说JSON和JSONP,也许你会豁然开朗,含jQuery用例, 563, http://www.cnblogs.com/dowinning/archive/2012/04/19/json-jsonp-jquery.html 你必须知道的EF知识和经验, 532, http://www.cnblogs.com/zhaopei/p/5721789.html, 讨论:程序员高手和菜鸟的区别是什么?, 499, http://www.cnblogs.com/baihmpgy/p/3790296.html 从机器学习谈起, 494, http://www.cnblogs.com/subconscious/p/4107357.html 好的用户界面-界面设计的一些技巧, 453, http://www.cnblogs.com/Wayou/p/goodui.html
生成的词云如下:
5. 总结
博客园原来主要是一个ASP.NET技术站!那么,我现在开始学还来得及吗...
6. 脚本下载
脚本我已经上传到了GitHub: https://github.com/lovesoo/test_demo/tree/master/spider_demo,欢迎Star!
7. 参考资料
1. Requests官网中文手册: http://cn.python-requests.org/zh_CN/latest/
2. Beautiful Soup的用法:http://cuiqingcai.com/1319.html
3. python异步并发模块concurrent.futures入门详解:http://www.cnblogs.com/lovesoo/p/7741576.html
4. 词云GitHub:https://github.com/amueller/word_cloud/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号