【原创】如何写一个框架:模式
模式
接下来去聊一聊框架设计中的一些常见设计模式,这和传统的一些设计模式不同(之前写过 无废话C#设计模式系列文章,有兴趣的读者可以去看一下),这里聊的一些设计模式是比较高层的粗粒度的架构设计模式,主要是用于之前说的构建框架的龙骨,使得框架中的几百个类型可以有结构有条理组织在一起,在这些模式之中你完全可以再去使用各种Gof设计模式,这是不冲突的。
分层
在之前的文章中其实已经强调过这个概念了。即使我们写的是同一个框架,对于框架中的所有类型可能也会有多层的结构:
- 纯抽象类型(接口),用于定义框架的骨骼,比如IController
- 半抽象类型(抽象类或带默认实现的接口),用于定义框架的骨骼并且还是共有逻辑在载体,比如AbstractController
- 具体的实现类型,在骨骼的基础上的不同的实现,比如VelocityViewEngine
在通常情况下是可以把这些类型都放到一个模块内方便阅读和管理,在一些特殊的情况下我们可以把框架直接在层次上拆分成多层多个框架(这些父子框架之间可以继承关系),比如:
- 如果有太多具体类型是过于具体的和业务逻辑相关的实现,而且实现的数量非常庞大
- 框架虽然整体解决的是一个问题,但针对不同的环境(比如网站、桌面和移动)在实现上有比较大的差异,那么我们可以把共同的部分放到父框架中,为不同环境提供单独的扩展框架
- 如果框架会和某个业务逻辑进行衔接,如果业务逻辑的接口不稳定的话,完全可以把这种不稳定的因素隔离出一个单独的子框架,保持父框架的问题
总之,OO的概念不一定可以应用于类型之间的关系,还可以应用到框架本身的层次关系上。
处理器和过滤器
框架就像是空气净化器的主框架它会确保空气吸入并走过所有的过滤器,过滤器就像是空气净化器的多层过滤各司其职,处理器负责把新鲜的空气排出。这是一个非常非常常见的框架的设计模式,几乎所有的面向数据流的框架,比如Web框架、Web MVC框架(ASP.NET MVC、Spring MVC等)、网络框架(Netty、Mina等)都会采用这种模式。因为这种模式:
- 由处理器来定义框架的主要的数据处理模型,由过滤器定义数据的加工模型,非常适合于基于数据处理的框架。
- 可以让框架有极大的扩展性,由框架来搭建主线流程,提供一个抽象模型,由开发人员来真正实现数据的处理业务逻辑。
- 非常符合职责分离的原则,而且非常灵活,有的框架甚至提供了运行时根据实际情况临时构建各种过滤器和处理器的栈。
这种模式有非常多的变种,而且过滤器和处理器之间往往在概念上也会有一些融合:
- 框架会暴露出一些事件由过滤器来处理,有的时候这些事件仅仅是发生在处理器之前(如第一个图)
- 有的时候在处理器执行前和执行后都会有一些事件,甚至过滤器是可以改变已处理的结果的(如第二个图)
- 过滤器只是订阅了所有或部分事件进行处理的一些类,只要过滤器注册到了框架那么框架就会按照一定的顺序去执行过滤器,往往过滤器是会有多个,处理器只会有一个,如果有多个的话也是最终选择一个合适的处理器来处理
- 有框架处理器也是职责链式的(如第三个图),允许多个处理器对数据或部分数据进行处理,这个时候处理器又有一点像过滤器了(也有一些框架没有过滤器,只有处理器链)
- 有一些框架的过滤器和处理器是各自独立的,它们只是管线的一部分,无法感知其它过滤器或处理器
- 而有一些框架的过滤器可以在过滤的过程中直接告知框架跳过后续的过滤器,或告知框架执行哪个处理器,甚至是告知框架跳过处理器直接提供结果
- 类似的,如果框架允许多个处理器,有的框架是允许处理器告知框架是否要执行后续的处理器的
- 大多数框架的过滤器管线在处理器之外,而有一些框架在处理器的内部安排了一组过滤器,也就是下图的整个图就是一个处理器,其中的处理器变为了执行器
- 有的框架的内部有多条过滤处理的管线,甚至是结合了分发器一起使用,我们回想一下我们的Web MVC框架是不是就是由分发器->处理器(处理器本身由前置过滤->处理->后置过滤+另外一组前置过滤->处理->后置过滤构成)的?
- 有框架没有使用过滤器这个名词而是叫拦截器,本质上差异不大,如果拦截器和处理器并存那么需要辨别其差异
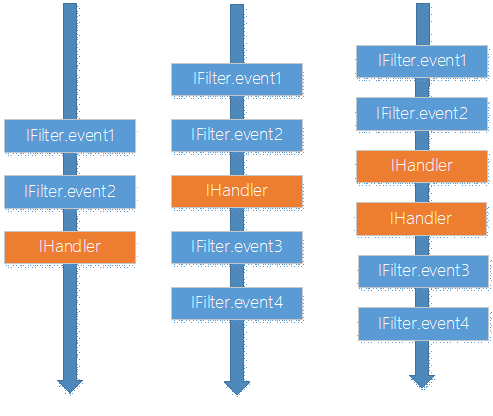
总之,掌握了这个重要的模式不但对自己写框架有帮助,对使用其它框架也非常有帮助。
依赖注入
首先想说一个比较偏激的观点,有很多框架对于其内部的组件采用了全面的外部依赖注入,框架整体的灵活性很高耦合很低,但是这样就会导致框架本身不是那么高内聚而且会造成框架使用者一些困扰,我是不太喜欢这么做的,我框架内部的组件可以是由依赖注入的,但是最好提供一个配置中心,提供统一的注入点而不是由使用者在用的时候来初始化这个框架的结构。所以对于框架提供的依赖注入,我更觉得它应该为各种由框架使用者提供的代码(比如插件、过滤器、处理器)进行依赖的解析。
对于很多框架如果它本身就是会和业务逻辑进行绑定的,那么提供一个依赖注入的入口可能必不可少(不是提供依赖解析的功能),我们可以提供类似一个IDependencyResolver/Adapter的接口,由框架的使用者去选择合适的IOC框架或类库进行实现,使得框架创建的外部对象都能够得到依赖的解析。
对于一些全栈框架,甚至可以在框架内部自带一个默认的IOC实现,使用和框架更为契合的API为使用者进行自动的依赖解析,在大多数时候我们真的不需要一个复杂且完整的东西,我们只需要一个简单且高效的东西。
各种器/者(Er/Or)
如下列出了各种ErOr,其中粗粒度的一些类型在之前的一些模式中有提到过部分,其余部分也是很多框架的老面孔了:
粗粒度/高抽象层的:
- Dispatcher
- Consumer
- Producer
- Publisher
- Subscriber
- Handler
- Filter
- Interceptor
- Provider
- Container
- ……
中粒度/中抽象层的:
- Locator
- Creator
- Initializer
- Reader
- Writer
- Activator
- Finder
- Builder
- Selector
- Visitor
- Loader
- Descriptor
- Generator
- Adapter
- Listener
- Wrapper
- Mapper
- Binder
- Invoker
- Executor
- Detector
- Tracer
- Decorator
- Mapper
- Resolver
- Processor
- Advisor
- ……
细粒度/底层的:
- Locker
- Iterator
- Extractor
- Accessor
- Validator
- Formatter
- Converter
- Replacer
- Comparer
- Manager
- Combiner
- Parser
- Encoder
- Decoder
- Importer
- Exporter
- Editor
- Modifier
- Evaluator
- ……
这里列的这些都是类型(类或接口)而不是方法,它们的共性就是以动词的名词形式来命名类型,一般很多时候动词对应的是方法或函数是某个操作,之所以很多框架把函数往上提成了方法的原因是:
- 框架的组件一般会有很多重用并且要支持组件扩展,把函数提取为类型才可以享受到抽象、继承、多态。
- 很多高层次和中层次的这些ErOr往往对应的是一种设计模式,设计模式能让复杂的代码变得有调理和充实饱满。
- 框架的代码一般比较复杂,只有让每一个组件都有很明确的职责,才能让代码清晰。当然,如果你的Replacer真的是一句replace(),你的Encoder()真是只是一句encode(),那是没有必要搞这么复杂的。如果在重构的时候我们发现方法的逻辑有重复,并且逻辑涉及到多种实现,我们就可以考虑把方法提升到ErOr然后通过模版方法避免重复。
在这里无法一一对每一种类型进行详细的阐述,如果大家有兴趣可以去下载一些框架的源码,进一步学习一下每种ErOr背后的模式和用法,很多名词都已经成为了标准,所以如果你也采用同样的名词来命名相关类型的话,会助于阅读你框架源码的人理解。
发布订阅和消息总线
对于分布式应用程序,我们经常会采用消息总线或发布订阅队列来解耦各种组件。
通过发布订阅,我们可以解耦发布者和订阅者:
- 让关心某个数据的组件可以订阅某个话题,且不用关心数据的来源
- 让产生某个数据的组件可以谈论某个话题,且不用关心是否诱人订阅了我的话题
- 同时可以实现很多高级功能,比如按照模式来订阅话题,消息的持久化等等
如果你的系统中有大量的异步事件,实现了发布订阅模式,那么不管将来扩展了多少事件以及事件的处理变得多少复杂,我们都不用去改变既有的实现。
总线是一种特殊的发布订阅模式,通过总线,我们解耦提供者和消费者:
- 让所有服务的提供者自己注册到总线上,告知总线提供某个服务
- 让所有服务的消费者在无需知道下游提供者的情况下进行服务的调用
- 同时总线可以做很多额外的工作,比如负载、心跳、限流、短路等
如果你的系统中提供了非常多的服务,使用了总线,服务之间的调用就不会有任何具体实现的依赖。
其实我想画一个图的,但Visio总是把箭头乱指,折腾了老半天箭头永远是斜着的,太难看了算了
你可能会问,用于分布式应用程序的模式和我们框架的设计有什么关联?个人觉得如果你从事的是一个具有状态的框架(比如IOC就是一种具有状态的框架,但MVC不应该是,或应用程序,特别是桌面和移动应用程序)的开发,那么有些时候可能会使用到一下这两种模式来进行大规模的解耦。怎么使用?用RabbitMQ、Kafka? 不是,可以自己尝试实现:
- 一个基于内存的容器(作为Broker),由容器来管理话题(元数据)以及上下游对象,并且进行消息的路由(转发),这就实现了发布订阅
- 如果要实现总线,在这个基础上扩展一下即可,可以想到如果有人订阅Request且发布Response那么它是服务的提供者(不过Request只用推送给任意一个订阅者即可),如果有人发布Request且订阅Response那么它是服务的消费者
- 当然,作为框架内使用的总线,我们可能不需要去实现诸如负载、心跳、限流等功能,数据的流转也可以是同步模式的
放到最后说这个模式是因为这其实是一个不错的练习,如果你有兴趣的话看了本文可以自己去尝试使用本文介绍的一些步骤和模式实现一个基于内存的轻量级的RabbitMQ/Kafka作为练习,谢谢阅读。另外推荐大家可以去看一下POSA面向模式的软件架构的前两卷。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号