

oracle数据库优化
1 概述
数据库是信息系统中核心的部分,数据库的高效性、安全性、稳定性、延展性,是项目成功的关键之一。一个好的数据库系统,设计当然是关键,但是就像显微镜的粗调和微调,当软件开发完成后,通过不断的对系统的跟踪监控,对数据库系统进行优化也是必不可少的。可以认为优化是数据库设计的一种顺延,和设计是相辅相成的。数据库的优化实际上从设计、数据库的安装就已经开始了,我们不应该就sql语句的效率孤立的谈论数据库的优化问题。实际上很多数据库优化的经验,在设计的时候就必须要考虑。
1.1 文章的组织结构
本文首先谈了一下和性能优化有关的基本概念,之后分六个方面详细讨论了数据库优化的方法、手段。在数据库的监控部分讲述了为什么?什么时候?如何监控数据库,并给出了一些可以直接使用的简单sql,用来直接分析某些方面的问题。从始至终,贯穿了一个实际的例子帮助读者能更好的理解有关理论。由于使用了多个工具参与优化工作,文中对每种工具的使用技巧做了简单提示。本文用到的例子是作者前不久遇到的一个项目,操作系统是DIGITAL ES20(True64UNIX),硬件配置为
2 性能优化有关的基本概念
2.1 响应时间
数据库是否高效的一个重要指标就是响应时间,响应时间短,查询就可以使用更少的时间,所以响应时间短,反应速度快是高效率的一个表现,这里有一个统计的数据。
Ø 1/10秒是用户认为系统能够立即反应的极限
Ø 1 秒是用户觉得没有被中断的极限
Ø 10秒是用户能将注意力继续集中在与计算机的对话上的时间极限
引用自Jakob Nielsen 的 “Usability Engineering” 第五章(Morgan Kaufmann, San Francisco出版)
简单的说,数据库优化就是要缩短系统的响应时间。
2.2 数据库的增长
数据库不是静止不动的,应用程序的螺旋式展开,数据库的规模的不断增大,用户数目的不断增多,最终将会导致响应时间的增加。虽然期间经过硬件的升级和数据库的优化,可以降低响应时间,但是在整个产品周期内,响应时间是会周期性展开的,有一个总体的发展趋势,如图1所示:所以数据库的优化在整个产品的生命周期都是有意义的。
|
响应时间 |
|
数据库规模 |
优化 优化
图1
在数据库的设计阶段,就应该估算数据库的增长率,并作为系统硬件参数、内存参数、数据库空间配置参数、环境参数设置的依据。在数据库的优化阶段,可以通过对数据库的监控来验证和调整我们的估计,并适当改变参数和调整sql,来控制系统的响应时间。
不同的业务特点增长率是不同的,根据在应用中的作用,数据库表基本上可以分为
² 静态参数表(应用相关表):相对稳定,并且比较小
² 动态参数表(事务相关表):于事务大小有关,缓慢增长
² 数据表(事务表):增长的主要因素,并且不稳定
² 临时/接口表:临时使用,之后被删除
3 数据库的具体优化方法
在数据库优化的时候,可以从5个方面调整,我们可以做为数据库优化的思路
Ø 网络
Ø 硬件
ü I/O子系统
ü Cpu子系统
ü 存储器
Ø 操作系统
ü UNIX系统
ü NT系统
ü VMS
Ø 数据库
ü 存储参数调整
ü 环境参数调整
Ø 应用程序
批处理和OLTP应用程序具有不同特点,批处理要考虑整体时间,而OLTP更注重单个sql的性能,在考虑单条sql是重点是:
ü 棘手sql调整
ü 索引调整
3.1 网络
巧妇难为无米只炊,如果分布式应用的网络环境不稳定,那实在是没有办法了。搞好客户关系,花钱买设备吧。
3.2 硬件优化
硬件的调整常在应用程序展开的初期见到,并且能解决很多性能问题,随着应用程序的展开,数据库规模的增长,后期主要的调整手段要放到数据库和应用程序上去。它们往往是影响性能的主要因素,同时也比硬件调整要更加经济。当然,如果客户不计成本向里扔钱,不反对硬件升级。
3.3 操作系统的优化
对操作系统的优化要看具体的操作系统而言,下面有一些常用的经验可供参考。
1. 对于unix操作系统,我们经常需要调整如下参数:
Ø 共享内存(Shared Memory)
Ø 信号灯(Semaphores)
对于共享内存主要关注下面四个核心参数:SHMMAX(单个共享内存段最大值)、SHMSEG(能够连到单个进程上共享内存段的最大值)、SHMALL(共享内存段总数目)。oracle建议将单个实例的SGA分配在一个共享内存段里。所以SHMMAX一般为物理内存的一半。具体的调整请看oracle的安装手册。最后,可以使用一些系统级工具进行监测:ipcs –b 可以获得当前共享内存段列表;tstshm 可以评估共享内存段设置。
对于信号灯:主要关注SSEMMNI(系统里信号灯集合的最大数目)、SEMMSL(每个集合里信号灯的最大数目)、SEMMNS(系统范围内可用的信号灯的最大数目)。每个oracle进程使用一个信号灯,信号灯数要比process多,否则数据不能启动,每个核心参数的最佳取值同上,在oracle的安装文档里有详细说明,此不赘述。
最后还要注意,要给操作系统留下足够的内存,不要因为SGA太大而造成过多的页交换,太多的page fault会消耗系统资源。
实战:可以利用操作系统的监视工具来分析系统的瓶颈,下面的示例都是本文实例使用sql*loader导入数据文件时的情况,这是系统资源使用的一个高峰。
ü 使用iostat如图2所示,bps表示每秒传输的kb数、tps表示每秒访问磁盘驱动的次数,关于每个参数的含义大家可以到google搜一下,就能找到。
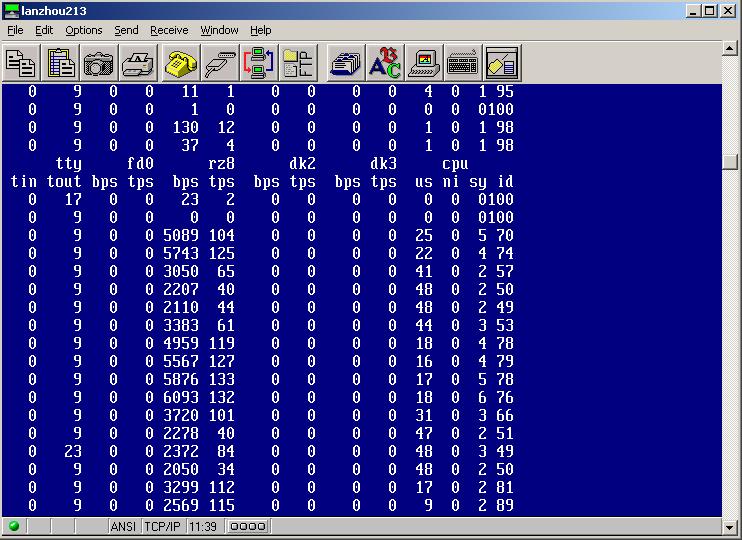
图2
可以看到硬盘平均每秒访问磁盘100次左右,平均每秒传输
ü 使用vmstat如图3所示,大家要主要关心page fault、page pin、page pout,这些数据表明了系统的页交换情况,cpu id显示了cpu资源利用率,procs 表明队列的多少,具体参数的详细含义同样可以用google详细搜到。

图3
图3表明:有大量的页交换产生,空闲内存太少,存在着内存瓶颈。但是cpu有大量的空闲等待时间。这表明SGA太大,导致系统本身的缓存太小。
通过这两个工具的监测,就可以明白原来系统的瓶颈就在内存和硬盘io这两个子系统上,更深层次的原因还有待对oracle的监测来发现。
2. 对于WINDOWNT系列操作系统,可以使用如下手段优化操作系统:
Ø 使不必要的服务失效
Ø 取消屏幕保护
Ø 只将机器用做数据库服务器
Ø 如果是WINDOWSNT系统
² 控制面扳中Network tool –Properties下面四个选项中选择Maximize Throughput for Network Application
² 控制面扳中System tool—Performance中boost选择None,减少文件系统缓冲
Ø 利用性能监视器监视数据库服务器,分析性能瓶颈
Ø 利用微软资源工具箱(resources pake)中的工具(Process Viewer、Process Explode、Quick Slice、Process Stat)监视数据库服务器,决定操作系统是否优化
3.4 数据库系统优化
oracle基本的体系结构如图2所示,每个后台进程将占用
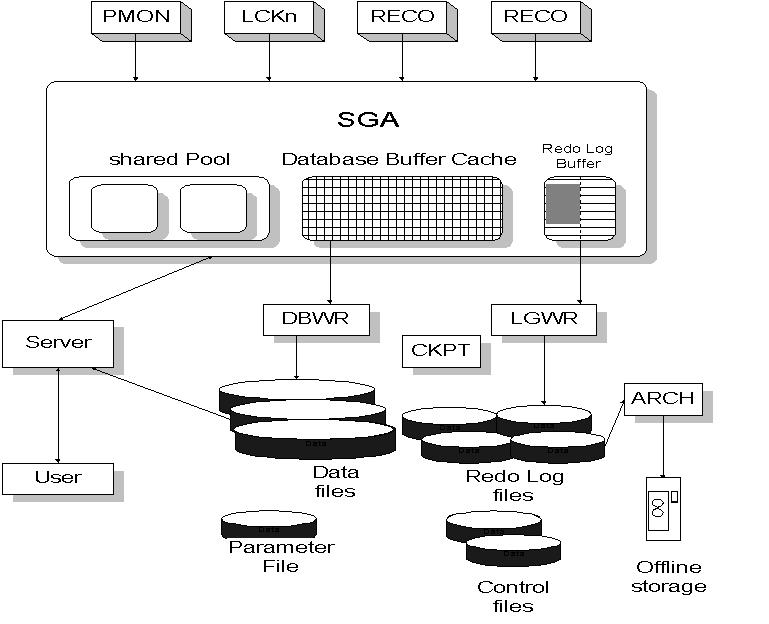
图4
内存结构的优化主要是通过init.ora文件的环境参数来配置,要主要注意下面几个:
db_block_size:数据库中每个数据块的大小,默认是2048字节(2k),一般应该增大到4K、8K,大型数据库也常使用16K和32K,通常SGA也应该增加。
Shared_pool_size:至于shared_pool_size大小是否合适,可以通过对数据库的监控得到,也可以通过一些sql语句实现。我们可以查询v$SGASTAT,查看SGA结构,其中free memory做为一个估计性的指标,如果大于20%可以将shared_pool_size给小些,给其他部分多分配些,如果小于8%,就可以开大些share_pool_size。有一些更精确的sql脚本可以查看其中library_cache,cursor_cache,pl/sql cache大小是否合适,如果数据库规模增长,还需要多少内存,所有这些都可以在附件中找到。
Log_buffer:为了减少LGWR和DBWR冲突,大型数据库的log_buffer一般都是要手工调大些,一般为
所有的环境参数,都可以通过系统的监控工具来分析是否适宜。
实战:对数据库系统可以使用toad和oracle提供的脚本utlbstat、utlestat监控:
ü toad的监控结果如图5、图6,分别使用了dba 下的database monitor和log switch frequence map,toad还有很多工具大家都可以试试,还是很有特色的。
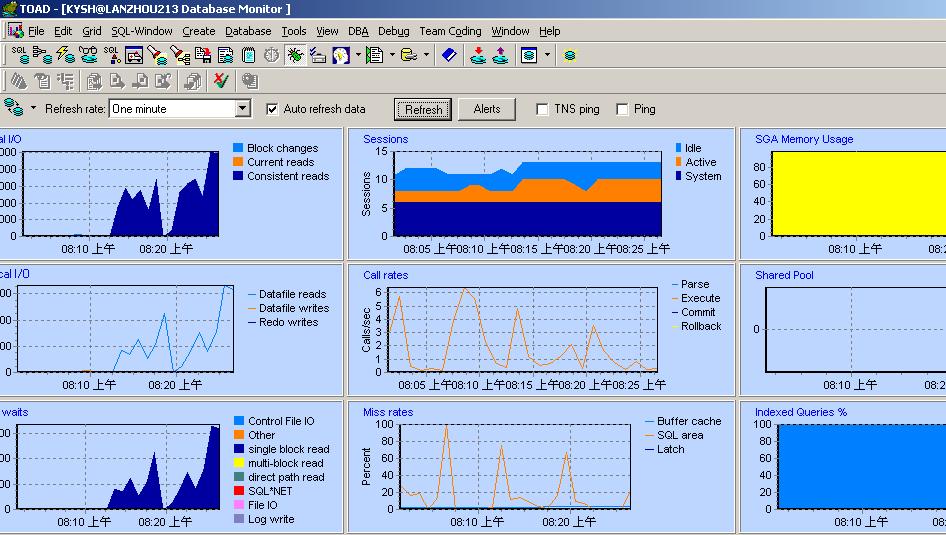
图5
对于logical io:consistent reads表示了逻辑获取,对全表扫描执行一次consistent reads增加1;对通过索引访问表consistent reads的值为索引高度+2*关键字。db_block_change是更新的数据块个数和数据更新的行数之和,表示被修改了的与无效列表连锁的数据块的数目。physical io 是物理读的统计。
Call rate和miss rate、waits也是应该关心的地方,可以看到通常在执行什么工作时系统出现等待。
我们现在一起分析上面的图:在早上8:05至8:25分的监测结果表明Consistent_Get(逻辑读) 的峰值为每秒5000个数据块;phsical read(物理读)的峰值:600个数据块/每秒;主要发生在single block read上,那么应该是通过索引的方式访问表。这里single block read出现大量等待,可能存在没有充分索引的大表、或者使用了选择性低的索引。提醒我们在优化sql语句时要留意。注意,这里的块是oracle数据块,现在数据库块大小是2k,所以每秒传递的数据量为2k/数据块*600数据块/秒=1200k/秒。但是刚才我们在iostat里看到,不是每秒从磁盘传输
再来看另外的部分:最多的call rate 是execute,最多的miss rate是sql area,miss rate中sql area存在峰值说明,部分时间段内sql的命中率较低,需要进一步查看是否是因为不良sql引起的,还是因为sql缓冲区太小。使用toad的health check 可知db_block_buffers的命中率为97%,通过v$sgastat视图可查知shared_pool_size中free mem有只4%左右,看来shared_pool_size太小了,结合上面存在大量页面交换的事实,得出结论:系统需要增加内存或者减少整体SGA,为系统留下更多的缓冲内存,同时还需要增加shared_pool_size的值。由于后面用utlestat脚本监控到sort disk始终为0,为排序分配的内存可以少留些,所以将sort area size从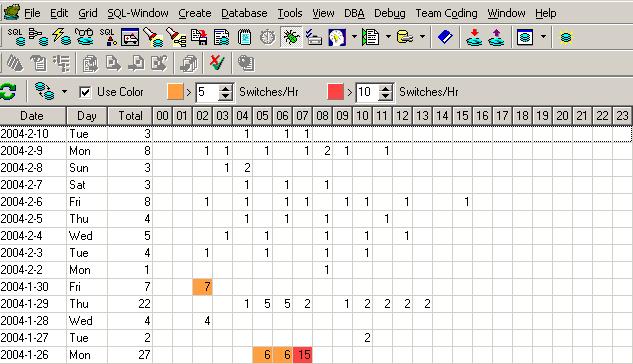
图6
可以看到未优化前redo log 频繁发生,说明需要增加重写日志缓冲区和重写日志,看来LGWR和DBWR的竞争也是硬盘io瓶颈的原因之一。优化的措施是Log buffer增加到
当然也可以使用sql语句分析oracle,许多人也喜欢这样做。感兴趣的朋友可以在附录的文件中找到对自己有用的sql直接使用。还有许多人是自己开发软件来分析数据库的,据说这是最有效的方法。毕竟oracle已经提供了使用方便的许多视图,toad也是如此实现的。
ü Linux下面也有个类似toad的工具tora,如果谁的工作环境是linux就可以用用看。

ü Utlbstat和utlestat是非常好的监控脚本,toad能发现的问题使用它同样也能发现,可以指定监控的时间段,是发现问题的一种更量化的方法,推荐使用。
这两个文件在oracle_home/rdbms/admin下,在运行脚本前注意更改tiemed_statistic为true,否则cpu used by this session将始终为0。运行完毕后在此目录下会产生report文件,就是监测结果。在文件中每段前都有简短的说明,可以帮助我们阅读。
ü Statspack包
从oracle
STATSPACK包的安装非常方便,以system/manger用户作为sysdba权限的用户登陆,运行$ORACLE_HOME/RDBMS/spcreate.sql语句将创建perfstat用户,同时在perfstat的schema(模式)下将创建一些对象,大约有36个表、37个索引、1个序列和1个包。安装的关键是要注意在安装过程中要求指定perfstat用户的默认表空间和临时表空间,其默认表空间至少要大于
统计数据采集表以stats$开头,字段从我们常说的v$视图中提取,其实就是通过V$视图获得的基于时间点的统计数据集合。可以利用脚本创建的包STATSPACK中的方法SNAP填充数据采集表,具体的方法是首先调整数据库的timed_statistics参数为True,其次以PERFSTAT用户登陆,在pl/sql中执行execute statspack.snap生成快照。如果有2个以上的快照,运行$ORACLE_HOME/RDBMS/ADMIN/spreport.sql脚本,按照提示输入起始和结束SNAP(快照)ID,将产生sp_beginning_ending.lst输出文件。文件中将会显示I/O统计数据,SGA数据和初始化数据相关的诸多数据,意思和Utlbstat/Utlestat差不多,这里就不一一解释了。
使用时有些要注意的地方:第一要在运行spreport.sql前分析PERFSTAT这个schema
execute dbms_utility.analyze_schema(‘perfstat’,’compute’);第二要及时清除陈旧数据,清除陈旧数据可以使用rdbms/admin/spurge.sql;第三删除STATSPACK包要使用同目录下的spdrop.sql;
ü OEM(oracle enterprise manager)是大型数据库环境最理想的监控工具,可以在控制台上轻松管理所有安装了inteligent agent的数据库,如果没有安装就只能使用dba studio的有限功能了。Oem中有些工具还是非常好用的:分别是性能管理器、锁管理器、会话监视器、空间管理器、oracle Expert、oracle trace。我个人觉的OEM是监控工具中最有效的一种工具。图7为oem的界面;

图7
使用OEM,基本的使用方法是:
1. 用emca或者Enterprise Manager Configuration Assistant配置档案资料库。
2. 使用oemapp console登录,也可以使用图形界面登录,注意mangerment server中是能解析的主机名,用户也不是数据库用户,而是具有网络管理权限的用户。默认是sysman/oem_temp
3. 搜索可以管理的结点,可以使用ip地址或者可以解析的主机名,如果没有安装intelligent agent需要手工配置(注意SID)
4. 在WINNT下只有http service 和 agent service 服务都启动,才可以自动搜索到
5. 添加作业和事件进行管理
3.4.1 修改数据库块大小
根据上面分析我们需要改变数据库块大小,在安装完数据库后改变数据库块,只能导出所有数据,并重新重建整个数据库。如果您使用的是oracle8i、9i那么恭喜您,使用dbassist(oracle database assistent)命令太方便了,在创建时选择custom选项,就可以调整db_block_size大小。如果是oracle
3.4.2 一些常用经验
oracle的内部空间管理和表空间需要遵守一些经验,这些都是设计数据库时要考虑的问题。比如表空间设计的时候应遵循oracle的最优化体系结构建议;db_block_buffers和library_cache都要保证合理的命中率;为了使全表扫描的效率最高,每个extent(数据区)都应该db_block_size*db_fiel_multiblock_read_count的倍数;如果是非常大的表,做sql*loader或者export操作时要使用direct选项,创建非常大的表和索引时要使用nologing选项。(oracle7上面是unrecoverable选项)
实战:本例中创建一个大索引开始没有使用nologing选项,使用后创建速度提高了3倍。
如果数据缓冲区太小,命中率较低,那么就需要经常从磁盘上访问数据。经常的io操作会严重影响效率,比从SGA中直接读取数据多8倍的时间并消耗更多的cpu资源。
在对表进行全表扫描时,数据库将采用多块读机制,每次读的块数由multi_block_read决定,如果块大小2k,每次读32个块,那么一次读出的量为64k。对于一个
技巧:SELECT Segment_Name,BYTES/1024/1024,BLOCKS,EXTENTS FROM USER_SEGMENTS where Segment_Name = '&table_name';可以查看表的大小,占用多少个数据块,在segment上的extent数目;select Segment_Name,extent_id,bytes/64,blocks from user_extents where Segment_Name = '&table_name'可以查看每个extents上有多少数据块,每个extent需要做多少次多块读取;
优化了数据库环境后,我们就可以考虑sql语句的优化了。
3.5 应用程序优化
在实际应用中批处理和OLTP应用程序具有不同特点,批处理要考虑整体时间,而OLTP更注重单个sql的性能,在报表系统和数据仓库中批处理的应用比较常见,往往需要一批sql语句完成数据的汇总、分类整理等工作,数据经过清洗和整理后,可以作为报表的基础数据。这些工作中的sql都是批量完成的。
3.5.1 批处理应用的优化
对批处理的应用的优化主要是在一些设计技巧上下工夫,有一些经验列举如下:使用存储过程比在开发工具中使用嵌入式sql更有优势;如果这批sql中经常检索一些小表,那么就可以把这些小表缓存起来,实现手段还是比较多的,可以在创建表的时候指明是可以缓存的,也可以在select中使用cache hint(提示)实现;如果许多sql都涉及对某个大表的查询,那么可以先对这个大对象进行整理,比如:如果where语句中日期条件最有优势,可以得到最少的记录,或者说日期字段最具有选择性,我们就可以先对表进行排序,使记录非常接近,非常接近的记录将使oracle使用较少的io,提高整体性能。
对OLTP等联机处理系统,单条sql语句是优化的重点,往往少量的几条sql语句会占用大部分资源。首先当然是找到这些sql,可能您能很清楚的知道是那些sql ,因为它们都很有特点,常常访问一些大表,也可能不很明确,这时可以用下面的sql 查一下:
select Executions,
Disk_Reads,
Buffer_Gets,
Round((Buffer_Gets - Disk_Reads) / Buffer_Gets, 2) Hit_Radio,
Round(Disk_Reads / Executions, 2) Reads_Per_Run,
Sql_Text
from V$sqlarea
where Executions > 0
and Buffer_Gets > 0
and (Buffer_Gets - Disk_Reads) / Buffer_Gets < 0.8
order by 4 desc;
如果找到了最影响性能的sql语句,我们就可以教育改造这些不良sql,让它们改过自新。
3.5.2 单条sql语句优化
请容许我再罗嗦一下,在优化sql语句之间要首先对oracle的环境先进行优化,只有优化了oracle数据库环境,谈论sql语句的优化才是有意义的。道生一、一生二、二生三,数据库设计就是道,sql语句的优化只是其上的衍生。内存的命中率、数据库锁、数据库内部空间参数设计对sql效率的影响是深远的。环境的优化我们已经提过,如果已经优化了环境,剩下的就要考虑是否对要访问的表是否使用了充分索引、是否使用了最优的执行计划。
得到表中的数据途径很多,可以全表扫描,可以通过索引访问,可以使用先使用索引再使用rowid…,因为sql是4GL(第四代语言),描述的是应该做什么而不是怎么做,处理细节是被系统隐藏起来的,所以可能有多种途径来完成同一个sql。优化器的作用就是分析使用那条途径的成本更低。优化器的执行原理如图8所示:优化器将会产生多种执行计划,并且会选择cost值最低的sql执行。图中的执行计划就好比是一条条路径,要找的是两点之间最短的那条。Oracle的优化器分为三种选则:rule、cost、choose,现在默认都是choose。如果表被analyze过就使用cost(Cost-Based Optimizer)形式,否则就使用rule形式。在rule模式下表名顺序,where条件中的连接顺序都会影响执行计划计划,在choose模式下,优化器会自动识别。对oracle的优化器,我们是可以放心的。

图8
创建了索引和没有创建索引的表的究竟谁的效率更高呢?如何创建索引能最好的优化sql的性能呢?这些都是在使用索引时要考虑的。因为通过索引扫描到的数据上不会立刻从SGA的db_block_buffers中清理掉,而全表扫描的数据块是不保存在DB_BLOCK_BUFFERS中的。从内存中直接获得数据自然比从磁盘读数据要快的多。但是如果一个表很大,它对应的索引也可能很大,假设扫描一个
一般来说oracle的优化器是最优的,但是也有可能要使用hint(提示)强制改变执行计划。例如如果使用DB_LINK连接远程数据库,那么使用merger的hint会更有效果,可以用LECCO SQL expert for oracle分析执行计划。首先它能够用更多的时间更充分的分析执行计划,其次它可以帮助我们分析是否需要hint。SQL expert的使用在去年csdn的开发高手里有介绍。
实战:
ü 使用LECCO SQL expert for oracle分析执行计划
LECCO SQL expert中非常好用的一个工具是sql formatter,可以先用它来格式化我们的sql。打开sql editor将格式化好的sql拷贝上去点击optimize按纽,expert会自动分析所有的执行计划,稍等一下就出现了窗口,告诉我们有多少个执行计划被分析,多少相同的执行计划被舍弃,点确定显示剩余执行计划。点击batch run,将按照cost有低到高的顺序执行sql如图9(这将是耗时的操作,需要一定时间等待):
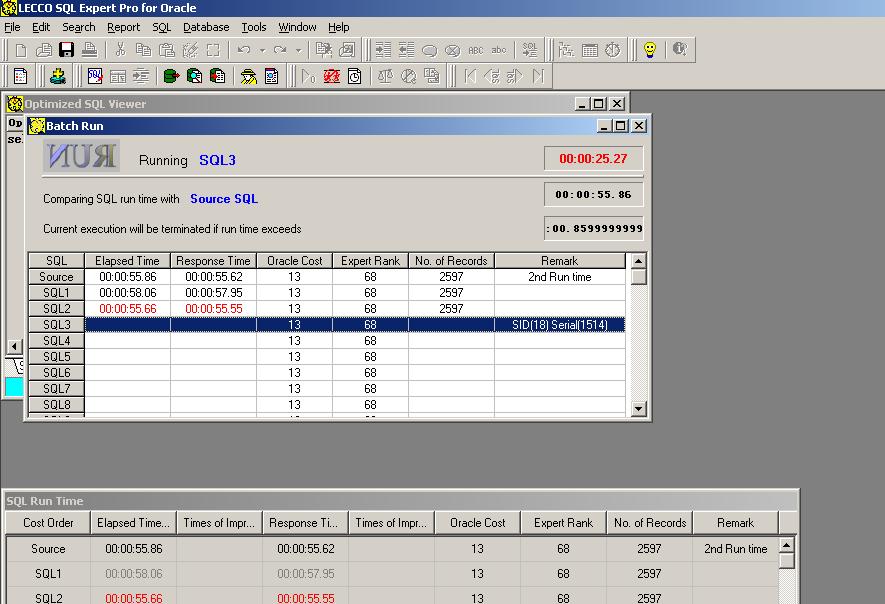
图9
运行完毕,就可以仔细分析每种执行计划,点sql comparer按钮,来比较每个执行计划的资源消耗情况图10

图10
ü plsql developer是我推荐使用的工具,用这个东东写存储过程什么的非常方便。写好sql,按一下F5,就可以显示执行计划如图11,太方便了。随手看一下sql是采用了什么执行计划,是否是自己希望的那样,对写出高水平的sql非常有用。

图11
ü Tkprof的是分析sql语句的另一个重要工具
使用思路是先利用sql_trace得到sql的trc文件,可以用下面的方法。在pl/sql中执行下面的两条sql语句:
alter session set sql_trace true;
alter session set timed_statistics = true;
之后运行需要分析的sql语句,就可以得到trc文件,就在oracle参数user_dump_dest设置的目录下面。但是trc文件是看不懂的,要使用TKPORF工具,语法是:tkprof ‘trc文件的路径’ 转化后的文件名。下面是一个转化后的文件。
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 29 0.11 0.11 71 103 2 2900
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 31 0.11 0.11 71 103 2 2900
Misses in library cache during parse: 1
Optimizer goal: CHOOSE
Parsing user id: 14
说明本条sql使用的cpu时间为11秒、物理读71次、逻辑读103次、共访问2900条记录、sql语句对象以前不存在于shared_pool_size中,被重新读入sql缓冲区,优化模式为CHOOSE。最后不要忘记了要关闭sql_trace。
alter session set sql_trace false
alter session set timed_statistics = false
ü 评估索引的使用(只在oracle9i中):
在oracle9i中,可以启用索引监控确定索引是否被正确使用,如果索引没有使用,可以删除它,节约空间,同时在DML时减少不必要的开销。
Alter index ‘index_name’ monitoring usage;
启动索引监控后,可以查询v$object_usage视图,确定索引是否被使用,是否被监控制。
4 总结
优良的sql性能被许多相互制约、关联的因素影响,总的来说如果满足下面的条件就可以得到优良的sql性能
Ø 好的数据库设计
Ø 好的体系结构设计
Ø 良好的平台(硬件平台、网络平台)
Ø 合理的环境参数(操作系统环境参数、oracle环境参数)
Ø 合理充分的索引
Ø 好的dba来不断优化
本人才疏学浅,相信文中必有可以商榷的地方,大家可以放言评论指正,如果能共同进步那就不胜感谢了


