

20155326刘美岑 2016-2017-2 《Java程序设计》第5周学习总结
教材学习内容总结
使用 try、catch
(1)java中所有的错误都会被打包为对象,如果愿意,可以尝试(try)捕捉(catch)代表错误的对象后做一些处理。
(2)JVM会尝试执行try区块中的程序代码。如果发生错误,执行流程会跳离错误发生点,然后比较catch括号中声明的类型,是否符合被抛出的错误对象类型,如果是的话,就执行catch区块中的程序代码。
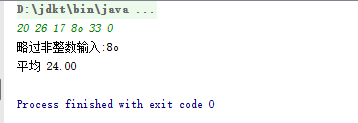
- 代码及运行结果如下
import java.util.*;
public class Average {
public static void main(String[] args) {
Scanner console=new Scanner (System.in);
double sum=0;
int count=0;
while (true){
try{
int number=console.nextInt();
if(number==0){
break;
}
sum+=number;
count++;
}catch(InputMismatchException ex){
System.out.printf("略过非整数输入:%s%n",console.next());
}
}
System.out.printf("平均 %.2f%n",sum/count);
}
}
异常继承架构
(1)解决错误信息有两种方式,一是使用try、catch打包System.in.read()是在main()分分旁声明throws.java.io.IOException。简单来说,编译程序认为调用System.in.read()时有可能发生错误,要求你一定要在程序中明确处理错误。二是在main()方法旁声明throws java.io.IOException。
(2)错误会被包装成对象,这些对象都是可抛出的,因此设计错误对象都继承自java.lang.Throwable类,Throwable定义了取得错误信息、堆栈追踪等方法,它有两个子类:java.lang.Error与java.lang.Exception。
(3)Error与其子类实例代表严重系统错误,如硬件层面错误、JVM错误或内存不足等问题。发生严重系统错误时,java应用程序本身是无力回复的。
(4)程序设计本身的错误,建议使用Exception或其子类实例来表现,所以通常称错误处理为异常处理。
(5)Error属于编译时错误,根本不会编译通过,也就是不会生成.class文件,Exception属于运行时错误,只有在调用的时候才会报错。异常的继承结构基类为Throwable,Error和Exception继承Throwable,RuntimeException和IOException等继承Exception,Error和RuntimeException及其子类成为未受检异常(unchecked),其它异常成为受检异常(checked)。RuntimeException是运行时虚拟机的错误,不能被catch。RuntimeException是Exception的子类,RuntimeException继承Exception。
(6)单就语法与继承架构上来说,如果某个方法声明会抛出Throwable或子类实例,只要不是属于Error、java.lang.RuntimeException或其他子类实例,就必须使用try、catch语法加以处理,或者用throws声明这个方法会抛出异常,否则编译失败。
(7)使用try、catch捕捉异常对象时也要注意,如果父类异常对象在子类异常对象前被捕捉,则catch子类异常对象的区块将永远不会被执行,编译程序会检查出这个错误。要完成这个程序的编译,必须更改异常对象捕捉的顺序。
(8)当发现到数个类型的catch区块在做相同的事情,这种情况常发生在某些异常都要进行日志记录的情况,这时可以使用多重捕捉的语法:
try {
做一些事...
} catch(IOException | InterruptedException | ClassCastException e){
e.printStackTrace();
}
这样的撰写方式简洁许多,不过仍得注意异常的继承。catch括号中列出的异常不得有继承关系,否则会发生编译错误。
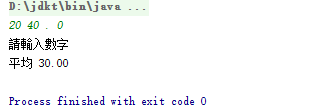
- 代码及运行结果如下
import java.util.Scanner;
public class Average4{
public static void main(String[] args){
double sum=0;
int count=0;
while(true){
int number=console.nextInt();
if(number==0){
break;
}
sum+=number;
count++;
}
System.out.printf("average %.2f%n",sum/count);
}
static Scanner console=new Scanner(System.in);
static int nextInt(){
String input=console.next();
while(!input.matches("\\d*")){
System.out.println("please input a number");
input=console.next();
}
return Integer.parseInt(input);
}
}
要抓还是要抛
(1)如果方法设计流程发生异常,而你设计时并没有充足的信息知道该如何处理,那么可以抛出异常,让调用方法的客户端来处理。
(2)为了告诉编译程序这个事实,必须使用throws声明此方法会抛出的异常类型或父类型,编译程序才会让你通过编译。
(3)在catch区块进行完部分错误处理后,可以使用throw将异常再抛出。可以在任何流程中抛出异常,不一定要在catch区块中。
(4)如果抛出的是受检异常,表示你认为客户端有能力且应处理异常,此时必须在方法上使用throws声明;如果抛出的异常是非受检异常,表示你认为客户端调用方法的时机出错了,抛出异常是要求客户端修正这个漏洞再来调用方法,此时不用throws声明。
- 代码及运行结果如下
import java.io.*;
import java.util.Scanner;
public class FileUtil {
public static String readFile(String name) throws FileNotFoundException {
StringBuilder text = new StringBuilder();
try {
Scanner console = new Scanner(new FileInputStream(name));
while(console.hasNext()) {
text.append(console.nextLine())
.append('\n');
}
} catch (FileNotFoundException ex) {
ex.printStackTrace();
throw ex;
}
return text.toString();
}
}
贴心还是制造麻烦
(1)异常处理的本意:在程序错误发生时,能有有明确的方式通知API客户端,让客户端采取进一步的动作修正错误。
(2)java是唯一采用受检异常的语言。这有两个目的:一是文件化,受检异常声明会是API操作接口的一部分,客户端只要查阅文件,就可以知道方法可能会引发哪些异常。二是提供编译程序信息,让编译程序能够在编译时期就检查出API客户端没有处理异常。
(3)受检异常本意良好,有助于程序设计人员注意到异常的可能性并加以处理,但在应用程序规模扩大时,会逐渐对维护造成困难。
(4)重新抛出异常时,除了能将捕捉到的异常直接抛出,也可以考虑为应用程序自定义专属异常类别,让异常更能表现应用程序特有的错误信息。自定义异常类别时,可以继承Throwable、Error或Exception的相关子类,通常建议继承自Exception或其子类,如果不是继承自Error或RuntimeException,那么就会是受检异常。
public class CustomizedException extends Exception { // 自定义受检异常
...
}
(5)如果流程要抛出异常,思考一下,这是客户端可以处理的异常吗,还是客户端没有准备好前置条件就调用方法才引发的异常。如果是前者,那就自定义受检异常、填入适当错误信息并重新抛出,并在方法上使用throws加以声明; 如果是后者,则自定义非受检异常、填入适当错误信息并重新抛出。
认识堆栈追踪
(1)在多重方法调用下,异常发生点可能是在某个方法之中,若想得知异常发生的根源,以及多重方法调用下异常的堆栈传播,可以利用异常对象自动收集的堆栈追踪来取得相关信息。
(2)查看堆栈追踪最简单的方法,就是直接调用异常对象的printStackTrace()。
(3)如果想要取得个别的堆栈追踪元素进行处理,则可以使用getStackTrace(),这会返回StackTraceElement数组,数组中索引0为异常根源的相关信息。
(4)要善用堆栈追踪,前提是程序代码中不得有私吞异常的行为,例如在捕捉异常后什么都不做。这会对应用程序维护造成严重伤害,因为异常信息会完全终止,之后调用次片段程序代码的客户端,完全不知道发生了什么事,造成除错异常困难,甚至找不出错误根源。另一种对应用程序维护有伤害的方式就是对异常做了不恰当的处理,或显示不正确的信息。
(5)在使用throw重抛异常时,异常的追踪堆栈起点,仍是异常的发生根源,而不是重抛异常的地方。
(6)如果想要让异常堆栈起点为重抛异常的地方,可以使用fillInStackTrace()方法,这个方法会重新装填异常堆栈,将起点设为重抛异常的地方,并返回Throwable对象。
- 代码及运行结果如下
public class StackTraceDemo3 {
public static void main(String[] args) {
try {
c();
} catch(NullPointerException ex) {
ex.printStackTrace();
}
}
static void c() {
try {
b();
} catch(NullPointerException ex) {
ex.printStackTrace();
Throwable t = ex.fillInStackTrace();
throw (NullPointerException) t;
}
}
static void b() {
a();
}
static String a() {
String text = null;
return text.toUpperCase();
}
}
- 关于assert
(1)assert的两种使用语法:
assert boolean_expression
assert boolean_expression : detail_expression
boolean_expression 若为true则什么事都不会发生,若为false则会发生java.lang.Assertionerror,此时若采取的是第二个语法,则会将detail_expression的结果显示出来,如果当中是个对象,则调用toString()显示文字描述结果。
(2)如果要在执行时启动断言检查,可以在执行java指令时,指定-enableassertions或是-ea自变量。
(3)关于何时该使用断言?
1.断言客户端调用方法前,已经准备好某些前置条件。
2.断言客户端调用方法后名具有方法承诺的结果。
3.断言对象某个时间点下的状态。
4.使用断言取代批注。
5.断言程序流程中绝对不会执行到的程序代码部分。
- 使用finally
(1)如果想要无论如何,最后一定要执行关闭资源的动作,try、catch语法还可以搭配finally,无论try区块中有无发生异常,若撰写有finally区块,则finally区块一定会被执行。
(2)如果程序撰写的流程中先return了,而且也有finally区块,那么finally区块会先执行完后,再将值返回。
- 代码及运行结果如下
public class FinallyDemo {
public static void main(String[] args) {
System.out.println(test(true));
}
static int test(boolean flag) {
try {
if(flag) {
return 1;
}
} finally {
System.out.println("finally...");
}
return 0;
}
}

- 自动尝试关闭资源
(1)想要尝试自动关闭资源的对象,是撰写在try之后的括号中,如果无须catch处理任何异常,可以不用撰写,也不用撰写finally自行尝试关闭资源。
(2)使用自动尝试关闭资源语法时,也可以搭配catch。
(3)使用自动尝试关闭资源语法时,并不影响对特定异常的处理,实际上,自动尝试关闭资源语法也仅仅是协助你关闭资源,而不是用于处理异常。使用时不要试图自行撰写程序代码关闭资源,这样会造成重复调用close()方法。
- 代码及运行结果如下
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.util.Scanner;
public class FileUtil2 {
public static String readFile(String name) throws FileNotFoundException {
StringBuilder text = new StringBuilder();
try(Scanner console = new Scanner(new FileInputStream(name))) {
while (console.hasNext()) {
text.append(console.nextLine())
.append('\n');
}
}
return text.toString();
}
}
- java.lang.AutoCloseable接口
(1)JDK7的尝试关闭资源语法可套用的对象,必须操作java.lang.AutoCloseable接口。
(2)AutoCloseable是JDK7新增的接口,仅定义了close()方法。
(3)所有继承AutoCloseable的子接口,或操作AutoCloseable的类,可在AutoCloseable的API文件上查询得知。
(4)只要操作AutoCloseable接口,就可以套用至尝试关闭资源语法。
(5)尝试关闭资源语法也可以同时关闭两个以上的对象资源,只要中间以分号间隔。
(6)在try的括号中,越后面撰写的对象资源会越早被关闭。
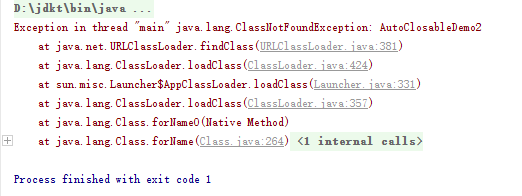
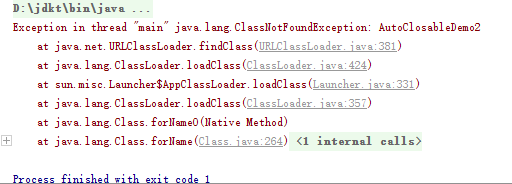
- 代码及运行结果如下
import static java.lang.System.out;
public class AutoClosableDemo2 {
public static void main(String[] args) {
try(ResourceSome some = new ResourceSome();
ResourceOther other = new ResourceOther()) {
some.doSome();
other.doOther();
} catch(Exception ex) {
ex.printStackTrace();
}
}
}
class ResourceSome implements AutoCloseable {
void doSome() {
out.println("作一些事");
}
@Override
public void close() throws Exception {
out.println("资源Some被关闭");
}
}
class ResourceOther implements AutoCloseable {
void doOther() {
out.println("作其它事");
}
@Override
public void close() throws Exception {
out.println("资源Other被关闭");
}
}
- 认识Collection架构
(1)程序中常有收集对象的需求,在javaSE中其实就提供了数个收集对象的类,可以直接取用这些类,而不用重新打造类似的API。
(2)收集对象的行为,像是新增对象的add()方法,移除对象的remove()方法等,都是定义在java.util.Collection中。
(3)既能收集对象,也能逐一取得对象,这就是java.lang.Iterable定义的行为,它定义了iterator()方法返回java.util.Iterator操作对象,可以让你逐一取得对象。
(4)然而收集对象会有不同的需求,如果希望收集时记录每个对象的索引顺序,并可依索引取回对象,这样的行为定义在java.util.List接口中。如果希望收集的对象不重复,具有集合的行为,则由java.util.Set定义。如果希望收集对象时,以队列排列。收集的对象加入至尾端,取得对象时从前端,则可以使用java.util.Queue。如果希望对Queue的两端进行加入、移除等动作,则可以使用java.util.Deque。
(5)收集对象时,会依需求使用不同的接口操作对象。
- 具有索引的List
(1)List是一种Collection,作用是收集对象,并以索引方式保留收集的对象顺序,其操作类之一是java.util.ArrayList。
(2)查看API文件的时候发现,List接口定义了add()、remove()、set()等许多依索引操作的方法。
(3)ArrayList中数组在内存中会是连续的线性空间,根据索引随机存取时速度快。有可指定容量的构造函数。适合排序的时候用,可得到较好的速度表现。而LinkedList采用了链接结构,若收集的对象经常会有变动索引的情况,考虑链接方式的操作的List会比较好,也就是说LinkedList效率更高。
- 内容不重复的Set
(1)同样是收集对象,在收集过程中若有相同对象,则不再重复收集,若有这类需求则可以使用Set接口的操作对象。
(2)String的Split()方法,可以指定切割字符串的方式。
(3)一般用hashcode()与equals()来判断对象是否重复。
- 代码及运行结果如下
import java.util.*;
class Student2 {
private String name;
private String number;
Student2(String name, String number) {
this.name = name;
this.number = number;
}
@Override
public int hashCode()
{
int hash = 7;
hash = 47 * hash + Objects.hashCode(this.name);
hash = 47 * hash + Objects.hashCode(this.number);
return hash;
}
@Override
public boolean equals(Objects obj) {
if (obj == null) {
return false;
}
if (getClass() != obj.getClass()) {
return false;
}
final Student2 other = (Student2) obj;
if (!Objects.equals(this.name, other.name)) {
return false;
}
if (!Objects.equals(this.number, other.number)) {
return false;
}
return true;
}
@Override
public String toString()
{
return String.format("(%s,%s)", name, number);
}
}
public class Students2
{
public static void main(String[] args)
{
Set students = new HashSet();
students.add(new Student2("Justin","B835031"));
students.add(new Student2("Monica","B835032"));
students.add(new Student2("Justin","B835031"));
System.out.println(students);
}
}
- 支持队列操作的Queue
(1)收集对象时以队列方式,收集的对象加入至尾端,取得对象时从前端,则可使用Queue接口的操作对象。
(2)Queue继承自Collection,所以也具有Collection的add()、remove()、element()等方法,然而Queue定义了自己的offer()、poll()与peek()等方法。然而Queue定义了自己的add()、remove()、element()等方法操作失败时会抛出异常,而offer()、poll()、peek()等方法操作失败时会返回特定值。
(3)希望对Quece的前端与尾端进行操作,在前端加入对象与取出对象,在尾端加入对象与取出对象,则可使用java.util.Deque。
- 代码及运行结果如下
import java.util.*;
interface Request {
void execute();
}
public class RequestQueue {
public static void main(String[] args) {
Queue requests = new LinkedList();
offerRequestTo(requests);
process(requests);
}
static void offerRequestTo(Queue requests) {
// 模擬將請求加入佇列
for (int i = 1; i < 6; i++) {
Request request = new Request() {
public void execute() {
System.out.printf("處理資料 %f%n", Math.random());
}
};
requests.offer(request);
}
}
// 處理佇列中的請求
static void process(Queue requests) {
while(requests.peek() != null) {
Request request = (Request) requests.poll();
request.execute();
}
}
}
- 使用泛型
(1)JDK5之后增加了泛型语法,在设计API时可以指定类或方法支持泛型,而使用API的客户端在语法上会更为简洁,并得到编译时期检查。
(2)使用泛型语法,会对设计API造成一些语法上的麻烦,但对客户端会多一些友好。
(3)Java的Collection API都支持泛型语法,若在API文件上看到角括号,表示支持泛型语法。
(4)若接口支持泛型,在操作时也会比较方便,只要声明参考时有指定类型,那么创建对象时就不用再写类型了,泛型也可以仅定义在方法上,最常见的是在静态方法上定义泛型。
- 代码及运行结果如下
import java.util.Arrays;
import java.util.Objects;
public class ArrayList<E>
{
private Object[] elems;
private int next;
public ArrayList(int capacity)
{
elems = new Object [capacity];
}
public ArrayList()
{
this(16);
}
public void add(E e)
{
if(next == elems.length)
{
elems = Arrays.copyOf(elems,elems.length * 2);
}
elems[next++] = e;
}
public E get (int index)
{
return (E) elems[index];
}
public int size()
{
return next;
}
}
- 简介Lambda表达式
(1)当信息重复了,接口只有一个必须实现,则可以使用Lambda。
(2)相对于匿名类语法来说,Lambda表达式的语法省略了接口类型与方法名称,->左边是参数列,右边是方法本体。
(3)在使用Lambda表达式,编译程序在推断类型时,还可以用泛型声明的类型作为信息来源。
(4)在Lambda表达式中使用区块时,如果方法必须返回值,在区块中就必须使用return。
- Interable与Iterator
iterator()方法会返回java.util.Iterator接口的操作对象,这个对象包括了Collection收集的所有对象。
- Comparable与Comparator
(1)java.lang.Comparable接口有个compareTo()方法必须返回大于0、等于0或小于0的数。使用如下:a.compareTo(b),如果a对象顺序上小于b对象则返回小于0的值,若顺序上相等则返回0,若顺序上a大于b则返回大于0的值。
(2)Comparator的compare()会传入两个对象,如果o1顺序上小于o2则返回小于0
的值,顺序相等则返回0,顺序上o1大于o2则返回大于0的值。
(3)在Java的规范中,与顺序有关的行为,通常要不对象本身是Comparable,要不就是另行指定Comparator对象如何排序。
- 键值对应的Map
(1)若有根据某个键来取得对应的值这类需求,可以事先利用java.util.Map接口的操作对象来建立键值对应数据,之后若要取得值,只要用对应的键就可以迅速取得。
(2)常用的Map操作类为java.util.HashMap与java.util.TreeMap,其继承自抽象类java.util.AbstractMap。
(3)建立Map操作对象时,可以使用泛型语法指定键与值的类型。要建立键值对应,可以使用put()方法,第一个自变量是键,第二个自变量是值,对于Map而言,键不会重复,判断键是否重复是根据hashCode()与equals(),所以作为键的对象必须操作hashCode()与equals()。
(4)在HashMap中建立键值对应之后,键是无序的。如果要想让键是有序的,则可以使用TreeMap。
(5)如果使用TreeMap建立键值对应,则键的部分将会排序,条件是作为键的对象必须操作Coomparable接口,或是在创建TreeMap时指定操作Comparator接口的对象。
(6)一般常用Properties的setProperty()指定字符串类型的键值,getProperty()指定字符串类型的键,取回字符串类型的值,通常称为属性名称与属性值。
(7)Properties也可以从文档中读取属性。.properties的=左边设定属性名称,右边设定属性值。
- 访问Map键值
(1)如果想取得Map中所有键,可以调用Map的keySet()返回Set对象,如果想取得Map中所有的值,则可以使用values()返回Collection对象。
(2)如果想同时取得Map的键与值,可以使用entrySet()方法,这会返回一个set对象,每个元素都是Map.Entry实例,可以调用getKey()取得键,调用getValue()取得值。
教材学习中的问题和解决过程
问题:Deque和Queue的区别以及使用应该注意什么?
- 解决方案:经过百度后知道了,队列(queue)是一种常用的数据结构,可以将队列看做是一种特殊的线性表,该结构遵循的先进先出原则。在Java中,LinkedList实现了Queue接口,因为LinkedList进行插入、删除操作效率较高
代码调试中的问题和解决过程
代码托管
代码量截图:

上周考试错题总结
错题:5.填空:System.out.println( “HELLO”.( ++toLowerCase()++ ) ) 会输出“hello”.
理解情况:这道题是要将大写转换为小写输出。在Java中,toLowerCase的意思是将所有的英文字符转换为小写字母;toUpperCase的意思是将所有的英文字符转换为大写字母。本题中,要求将所有的大写字母转换为小写字母输出。
错题:CH06 判断:被声明为protected的方法,只能中继承后的子类中访问。(X)
理解情况:protected定义的方法和成员在同一包类中也可以存取。
结对及互评
评分标准
-
正确使用Markdown语法(加1分):
- 不使用Markdown不加分
- 有语法错误的不加分(链接打不开,表格不对,列表不正确...)
- 排版混乱的不加分
-
模板中的要素齐全(加1分)
- 缺少“教材学习中的问题和解决过程”的不加分
- 缺少“代码调试中的问题和解决过程”的不加分
- 代码托管不能打开的不加分
- 缺少“结对及互评”的不能打开的不加分
- 缺少“上周考试错题总结”的不能加分
- 缺少“进度条”的不能加分
- 缺少“参考资料”的不能加分
-
教材学习中的问题和解决过程, 一个问题加1分
-
代码调试中的问题和解决过程, 一个问题加1分
-
本周有效代码超过300分行的(加2分)
- 一周提交次数少于20次的不加分
-
其他加分:
- 周五前发博客的加1分
- 感想,体会不假大空的加1分
- 排版精美的加一分
- 进度条中记录学习时间与改进情况的加1分
- 有动手写新代码的加1分
- 课后选择题有验证的加1分
- 代码Commit Message规范的加1分
- 错题学习深入的加1分
-
扣分:
- 有抄袭的扣至0分
- 代码作弊的扣至0分
点评模板:
- 基于评分标准,我给本博客打分:9分。得分情况如下:
- 正确使用Markdown语法:+1
- 模板中的要素基本齐全:+1
- 教材学习中的问题和解决过程:+2
- 代码调试中的问题和解决过程:+2
- 进度条中记录学习时间与改进情况:+1
- 排版精美:+1
- 感想,体会不假大空:+1
点评过的同学博客和代码
其他(感悟、思考等,可选)
对于书上有些方法不太熟悉,用时不知其语法或不知其意义,总得翻书查找。这两章都是陌生的东西,要想弄懂各种具体事例,前几章的基础很重要。前面的内容也有一些没有弄懂的地方,接下来得用时间来弥补学习的空白之处了。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 15篇 | 400小时 | |
| 第一周 | 20/20 | 1/1 | 20/20 | 安装了各种程序 |
| 第二周 | 126/100 | 1/1 | 25/25 | 掌握了托管代码 |
| 第三周 | 197/200 | 1/1 | 30/30 | 大体了解java的对象和对象封装 |
| 第四周 | 533/500 | 1/1 | 45/40 | 知道了继承接口等 |
| 第五周 | 733/700 | 1/1 | 50/50 | try、catch语法的使用来纠错 |
-
计划学习时间:50小时
-
实际学习时间:50小时
-
改进情况:
这次对书上的内容看得比较细,所以看代码时结合书上讲的知识比较容易理解。
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步