

201521123091 《Java程序设计》第7周学习总结
Java 第七周总结
第七周的作业。
目录
1.本章学习总结
2.Java Q&A
3.码云上代码提交记录及PTA实验总结
1.本章学习总结
以你喜欢的方式(思维导图或其他)归纳总结集合相关内容。
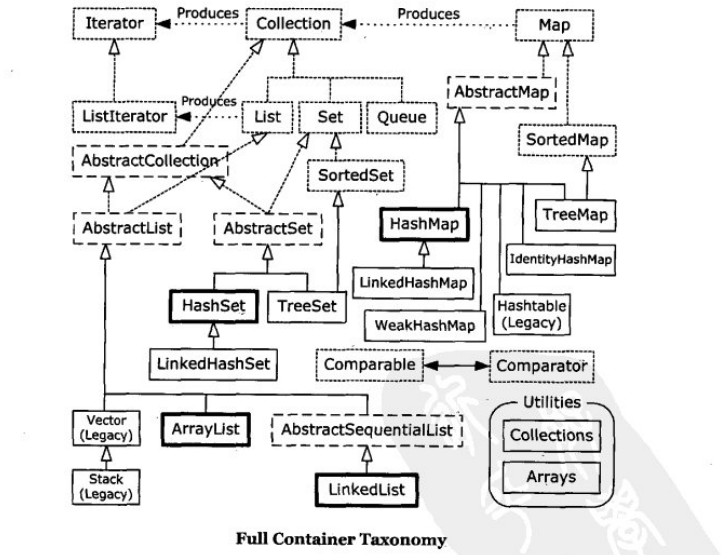
Collection保存单一的元素,而Map保存相关联的键值对。Java的泛型可以指定容器中存放的对象类型,从容器中获取元素时,可以不必进行类型的转换。当我们往Collection和Map中添加更多元素的时候,容器会自动进行扩容。容器是不能装基本类型的,但是可以对基本数据类型自动进行打包和拆包。
List建立数字下标与对象之间的关联,List与数组的差别就在于List能够自动扩充容量。如果要进行大量的随机访问,就用ArrayList,如果经常在中间进行元素的插入或者是删除,就用LinkedList。一般说来,我们总是首选ArrayList。
队列和栈的行为,都可以由LinkedList提供支持。
Map是建立从对象到对象的一种映射的容器。HashMap可以用来进行快速的访问,时间界为O(1),这个散列容器的使用依赖于我们要学会如何正确编写equals()和hashCode()方法。如果没有明显的限制,这应该是我们默认的选择。而TreeMap使键始终保持在排序的状态,它是SortedMap的唯一实现,用一个二叉树来维护数据。所以是没有HashMap快的。
Set是不接受重复元素的,HashSet和TreeSet是用相应的Map容器来实现的,所以在适用场景和时间界的分析上都是差不多的。
Queue的实现有LinkedList、PriorityQueue和Deque。前两个的差异在于排序的行为,而Deque作为双端队列,支持在队首和队尾进行入队和出队的操作。
现在我们写程序,不应该出现过时的Vector和Stack之类的。
Map和Collection是可以通过Map容器的entrySet()和values()方法建立联系的。
迭代器是一个对象,它的工作是遍历并选择序列中的对象。这个Iterator只能用来:
1)使用Iterator()方法来返回容器的一个Iterator。迭代器返回序列中的第一个元素
2)next()方法可以用来获得序列的下一个元素
3)hasNext()方法检查是否已经跑到了序列中的最后一个元素
4)remove()方法将迭代器返回的元素删掉
2.Java Q&A
1.ArrayList代码分析
1.1 解释ArrayList的contains源代码
记得我在第四周的时候说到过这个问题……现在就搬过来再说一遍吧……
//contains()方法
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
//indexOf()方法
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
ArrayList的实质就是一个Object数组,就是我们在第二段代码中看到的那个elementData数组。这是一个会自动扩充的数组,默认一开始开大小为10的数组,如果数组都被用完,还需要添加元素的时候,就会扩容到原来的1.5倍。言归正传,是数组的话,就可以通过下标来随机访问。这个没什么问题……所以我们可以看到contains()方法直接就返回下标是否≥0的布尔值。那么在数组当中,如果要按内容查找的话,时间复杂度就是O(N)。不过这边indexOf方法对于传入的是否是null进行了区分,因为null去调用equals是会报空指针的错误的。如果找到了,就直接返回,找不到跳出循环外面,就返回-1,标记为没找到,那么contains()方法也会直接返回false。
1.2 解释E remove(int index)源代码
上代码:
//remove代码
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
//rangeCheck代码
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
rangeCheck代码简单,就是移除之前看看是不是在界外面,然而这个rangeCheck是不会去判断负数的,它只关心你传入的index是否超过了size。如果是负数的话,就直接抛数组下标越界的异常。
关键是这个modCount啊。真是麻烦,我稍微看了一下,首先代表的是修改的次数。这边的修改是让列表的大小出现变化的修改。主要就是迭代器在进行next()或者是remove()之类的操作的时候,要去检查一下modCount是否发生了变化,如果变化了的话,就要抛ConcurrentModificationException()的异常。
然后回到remove()的过程来,将对应下标的元素取出来,再把后面的数组元素全部往前搬一位。最后返回被删除的元素即可。size需要自减一次,然后原来最后一个数组元素所在的位置置为null即可。
1.3 结合1.1与1.2,回答ArrayList存储数据时需要考虑元素的类型吗?
需要吗?不需要吧。ArrayList里面想放什么类型的都可以,只要不是基本数据类型都行。可以先放一个String类,再放一个Integer,再放一个Double类。看实际使用吧,因为实际上是Object数组实现的,Object类又是所有类的父类,也就是说随便放什么类型进去都可以向上转型,当然是没什么问题的。
1.4 分析add源代码,回答当内部数组容量不够时,怎么办?
啊哈,幸好我没有在上面一起讲掉。那就来看看如果内部数组容量不够怎么办。
还是得贴代码。
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
这是追加在尾部的。在中间插入的待会再讲,其实都差不多。
首先要确保内部容量是size + 1。这个很好理解吧。
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
如果elementData是默认长度的空数组的话,那么就确保数组容量是传入参数和默认长度的最大值,也就是说这边至少开大小为10的数组。
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
ensureExplicitCapacity()方法上来就将modCount自增一次,所以大家现在可以理解add那边的注释了吧。不过这边值得注意的是,即使数组长度最后不会改,modCount也是要自增的。如果需要的容量比现有数组长度要大的话,就调用grow()方法。
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
直接扩容1.5倍,没有任何问题。第一个if对于我们这边的add()方法用不上,minCapacity一直都是size +1,不会比1.5倍更大的……然后再和MAX_ARRAY_SIZE比较。private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;我猜我是用不到这么大的数组的……最后确定了新的容量,就使用Arrays.copyOf()方法来生成新的数组,然后将原来的数据拷贝到新数组中去。
至于在中间插入,其实扩容的时候都是一样的,只是还有把该位置后面的元素全部往后搬一位的操作。System.arraycopy(elementData, index, elementData, index + 1,size - index);
1.5 分析private void rangeCheck(int index)源代码,为什么该方法应该声明为private而不声明为public?
上面分析过了,至于为什么是private,这就和之前的封装有关系了,有些具体实现是可以隐藏的。因为ArrayList类的用户是不需要知道remove()的时候发生了什么事情,只要知道是否正确删除就好了。这边引用一下吧:
因此,访问控制的第一个存在原因就是让客户端程序员无法触及他们不应该触及的部分——这些部分对数据类型的内部操作来说是必需的,但并不是用户解决特定问题所需的接口的一部分。这对客户端程序员来说其实是一项服务,因为他们可以很容易地看出哪些东西对他们来说很重要,而哪些东西可以忽略。——《Java编程思想》
2.HashSet原理
2.1 将元素加入HashSet(散列集)中,其存储位置如何确定?需要调用那些方法?
首先存入Set的每个元素都必须是唯一的,因为Set不保存重复元素。所以必须要定义equals()方法来确保对象的唯一性。其次存入HashSet当中的元素还要定义hashCode()方法。
HashSet实质上使用HashMap来实现的,键就是我们打算放入集合当中的对象,值就是一个空的(dummy)Object对象。将元素加入HashSet的add()方法的过程就是将元素和空对象作为键值对加入HashMap的过程。
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
所以我们只要看看HashMap中的put()方法是怎么实现的就好。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
然后再看这个putVal是个什么东西
//略去41行代码
(吐血并瘫倒在地上……)还是拆开来讲吧:
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
如果table没有初始化,就初始化,然后n - 1与hash值做与运算进行快速定位,如果这个位置没有值,就放在这个位置。
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//结合下面的
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
如果原先位置不为空,且存在键一样的结点,那么当onlyIfAbsent的值为false的时候,就要把原来的值给替代掉。这个出现了两次,一种情况是有且仅有一个结点,另一种情况就是在链表的中间找到了键相同的结点。散列数组是不保存值的,而是保存值的列表。就是分离链接法。大致的过程就是计算散列值,找到对应下标,从对应列表里面进行查找,如果有键相同的替换,没有就追加在后面。下面就是这样。
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
在Java8对于HashMap有了改进,如果链表太长的话,就用红黑树来替换,将原来在一个桶内搜索的时间界从O(N)降到O(logN)。
然后我们再回去,put()方法中调用的putVal()方法的第四个参数是false,也就是新值要覆盖旧值。第一个就是根据key算出来的hash值。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
如果key是空,返回0,否则返回hashCode与自身右移16位的或。
2.2 选做:尝试分析HashSet源代码后,重新解释2.1
上面分析完了。
3.ArrayListIntegerStack
3.1 比较自己写的ArrayListIntegerStack与自己在题集jmu-Java-04-面向对象2-进阶-多态、接口与内部类中的题目5-3自定义接口ArrayIntegerStack,有什么不同?(不要出现大段代码)
数据结构:ArrayListIntegerStack是用ArrayList来实现栈,ArrayIntegerStack是用Integer数组来实现栈。
入栈:ArrayIntegerStack是会存在栈满的情况,当数组的空间全部被用完的情况下,而ArrayListIntegerStack不存在,因为ArrayList在数组空间被用完之后会自动扩容。
出栈:ArrayIntegerStack在出栈的时候需要移动top指针,ArrayListIntegerStack需要。但是我们之前说过了ArrayList也是用Object数组来实现的,所以其实我们只是把ArrayList在调用remove()方法时的内部实现显式地写出来了而已。
其他几个操作,基本上都没有太大的差别。就像我在出栈这部分说的,ArrayIntegerStack其实只是将ArrayList的内部实现写了出来,其实两个都是差不多的,所以用ArrayListIntegerStack会更好一点,因为写源文档的人技术比我们高超,那就用现成的吧。
3.2 简单描述接口的好处。
首先,针对这一道题来说,我们两个类都继承了一个接口,那就是IntegerStack。这样做的好处就是我可以使用一个接口来操作不同的类,至于到底操作哪一个类,就可以交由动态绑定来搞定。我可以修改操作接口的类的具体实现(比如修改ArrayListIntegerStack的pop()方法),甚至把接口具体操作的那个类整个换掉(比如把ArrayListIntegerStack换成ArrayIntegerStack),都不会影响用户和接口的交互。即改变内部的工作方式而不会造成影响。
还有,就是可以并行进行编程的工作,提高效率。只要有接口,我知道接口定义了哪些抽象方法,就可以编写出与这个接口进行交互的代码,而不需要管到时跑代码的时候到底实现的是哪一个接口。其实跟上面差不多的意思,只是从使用和编程两个方面提出了些看法。
很简单,这样就够了。
4.Stack and Queue
4.1 编写函数判断一个给定字符串是否是回文,一定要使用栈,但不能使用java的Stack类(具体原因自己搜索)。请粘贴你的代码,类名为Main你的学号。
首先java.util.Stack类是不推荐使用的,它继承了Vector类,Vector类本身就不推荐使用,因为这个类比较旧,一开始设计的时候,里面有很多名字比较长的方法名,后面又操作了List接口,所以又和List定义的方法重复了……然后这个Vector类又是线程安全的,这样的话效率就会慢很多,而且后面写了个更好的支持线程安全的类,总之这个Vector类的待遇可不像在C++那样。其次,很重要的一点就是继承啊,这个Stack类不是使用,而是继承了这个Vector类,导致Vector类的方法,它也能用,比如我们可以用个什么elementAt()方法,也就是这个Stack不是一个真正的Stack类,操作并不受限,也可以不先进后出,完全靠使用者的自觉。
import java.util.LinkedList;
class Stack<T> {
private LinkedList<T> storage = new LinkedList<T>();
public void push(T v) {
storage.addFirst(v);
}
public T peek() {
return storage.getFirst();
}
public T pop() {
return storage.removeFirst();
}
public boolean empty() {
return storage.isEmpty();
}
public String toString() {
return storage.toString();
}
}
public class Main201521123091 {
public static void main(String[] args) {
Stack<Character> stack = new Stack<Character>();
// String string = "201521123091";
String string = "201521125102";
for (int i = 0; i < string.length(); i++) {
stack.push(string.charAt(i));
}
boolean flag = true;
for (int i = 0; i < string.length(); i++) {
if (stack.pop() != string.charAt(i)) {
flag = false;
break;
}
}
if (flag) {
System.out.println("yes");
} else {
System.out.println("no");
}
}
}
好好地听Java编程思想的话,用LinkedList来实现栈。如果是自己的学号,那么就输出no,如果是某人的学号(是回文串),就输出yes。就是将字符串全部入栈,再一个个出栈从左到右和字符串相交,如果没有出现不同的,就是回文串,否则不是。如果是空串,也是返回yes。这个就没什么了,因为判断空串是不是回文串没什么意义。
4.2 题集jmu-Java-05-集合之5-6银行业务队列简单模拟。(不要出现大段代码)
for (int i = 1; i <= n; i++) {
int x = scanner.nextInt();
if (x % 2 == 0) {
linkedList2.offer(x);
} else {
linkedList1.offer(x);
}
}
根据奇偶分别入两队。
while (!linkedList1.isEmpty() && !linkedList2.isEmpty()) {
dosth();
System.out.print(linkedList1.poll());
if (!linkedList1.isEmpty()) {
dosth();
System.out.print(linkedList1.poll());
}
dosth();
System.out.print(linkedList2.poll());
}
当两个队列非空的时候,则队列1出两个,队列2出一个。直到其中至少有一个队列为空的时候跳出循环,然后再将非空队列全部出列。而且后面跟的两个循环只会执行一个,就这一点跟归并排序的流程差不多了。感觉没什么好说的,就这样吧。
5.统计文字中的单词数量并按单词的字母顺序排序后输出
关于这道题还有个小插曲(手动斜眼笑),当时交了要10次都过不了,不过最后幸好还是过去了。
Set<String> set = new TreeSet<String>();
while (scanner.hasNextLine()) {
String string = scanner.nextLine();
if (string.equals("!!!!!")) {
break;
} else {
if (string.length() == 0) {
continue;
}
String[] strings = string.split(" +");
for (String string2 : strings) {
set.add(string2);
}
}
}
这道题有陷阱,不能相信题目!因为单词之间根本就不是以一个空格分开的,存在多个空格,因为我用任意数量的分隔,过了一组数据。这边用的是正则表达式的贪婪原则。正则表达式感觉是一个很高深的东西啊。这边mark一下。java中split任意数量的空白字符
第二个陷阱是存在空行,这个其实还好,因为题目中并没有说不允许空行,所以只要判断一下长度是否为0即可。当然也可以把每一行当做是一个输入流,比较省力,也好理解。
6.选做:加分考察-统计文字中的单词数量并按出现次数排序
6.1 伪代码
for line in text
for word in line
get the num of it
put the word and the new num that has been incremented in the map
6.2 实验总结
抛开输入输出,这道题也是挺弱的。按部就班往下做就是了。
ArrayList<Map.Entry<String, Integer>> arrayList = new ArrayList<Map.Entry<String, Integer>>(treeMap.entrySet());
Collections.sort(arrayList, new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2) {
if(o2.getValue() - o1.getValue()!=0)
return o2.getValue() - o1.getValue();
return o1.getKey().compareTo(o2.getKey());
}
});
最值得一提的就是这个,把Map当中的键值对放在ArrayList当中,然后用Collections.sort()方法对ArrayList进行排序。
7.向对象设计大作业-改进
7.1 完善图形界面(说明与上次作业相比增加与修改了些什么)
老师说用JTabel会好很多,那这边试试用JTabel的方法吧!
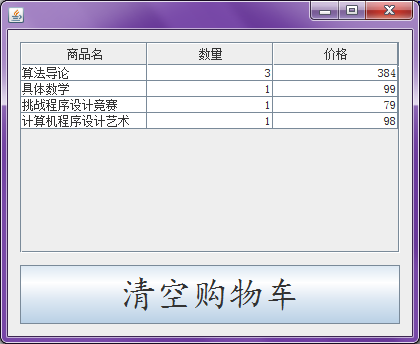
JTable类有一个构造器能够将一个二维对象数组包装进一个默认的模型。所以我们这边把购物车里面的条目以一维数组的方式逐个加进表格中去。
for (Item item : shoppingCart.getItems()) {
model.addRow(new Object[]
{item.getGoods().getName(),
item.getNum(),
item.getGoods().getPrice() * item.getNum()});
}
然后也是右键弹出菜单进行删除,这个D现在同样只是摆设。

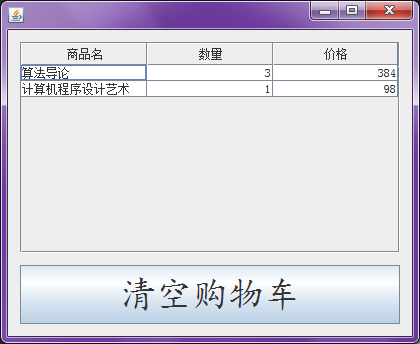
int rowIndex = jTable2.getSelectedRow();
String string = (String)jTable2.getValueAt(rowIndex, 0);
JPopupMenu popupMenu = new JPopupMenu();
JMenuItem menuItem = new JMenuItem("删除(D)");
menuItem.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
DefaultTableModel model = (DefaultTableModel)jTable2.getModel();
Item item = shoppingCart.get(string);
shoppingCart.getItems().remove(item);
model.removeRow(rowIndex);
shoppingCart.setTotalPrice(
shoppingCart.getTotalPrice()
- item.getGoods().getPrice() * item.getNum());
}
});
与上回的代码稍稍不同的是,这边选择被选行的第一列,也就是商品名来进行删除。这段代码和上面一段代码的addRow和removeRow都是用默认的表格模型进行增删的。
看上去的确会比上次的好些?有没有?
7.2 使用集合类改进大作业
集合类主要有List,Set,Queue这三大类。用的比较多的就是List,List用的最多的就是ArrayList。这个我用的很多,不过暂时没有考虑到用其他集合的必要。大致想了一下,可能对于商品列表来说,应该用Set来保证商品的不可重复的性质,但是只要在ArrayList的插入过程中进行一下判断就好了。至于Queue?是不是处理的时候是一个单服务台的排队模型,所以需要用Queue来处理多个顾客的结算请求?不过这个我现在应该是做不了的。
至于Map,倒是有个用处,就是搜索商品的时候,用HashMap来实现快速查询的功能。试一下吧……一开始还以为都用不着的……
在要开始写代码的时候想了一下,我的查询肯定不是全名搜索,才能查到对应商品的,也就是说如果用Map,或者说HashMap的话就要允许多个关键字映射到一个商品,也就是冲突的情况,这显然是是不可能的。一种比较好的方法,是用倒排索引,对于可能的关键字,都映射到对应的商品中去。对于英文来说是比较方便的,因为有实际意义的单词都用空格分隔,然而中文的词语表达方式相对于英文会复杂不少。所以我这边不做,只是提出一种可以实现的方式。
3.码云上代码提交记录及PTA实验总结
3.1 码云代码提交记录
- 在码云的项目中,依次选择“统计-Commits历史-设置时间段”, 然后搜索并截图
看的不过瘾的请点下面
回到顶部
这周没什么废话,看上去很少,但是做起来,也不容易。容器也算是Java比较核心的东西吧。

