《Flask Web开发——基于Python的Web应用开发实践》一字一句上机实践(上)
目录
前言
学习Python也有一个半月时间了,学到现在感觉还是初步入门阶段,如果不借助网上Demo资源,几乎不能自己写出相关称心的东西。目前感觉自己还是有点失败啊,学的太慢了点。主要感觉还是自己刚开始学习时有点浮躁,一心求快,看资料时前期都是囫囵吞枣。
刚开始买了一本《Python基础教程 第2版》,大约花了10天看完,初步了解了Python语法相关特性以及如何链接后台数据库。那时,看完后又买了《Python Web开发实践》和《Flask Web开发——基于Python的Web应用开发实践》。然后,花了5天时间把《Flask Web开发——基于Python的Web应用开发实践》看了一遍,之所以这么快,是因为看到了第八章时,发现代码有点弄不懂,而且从作者GitHub上克隆下来的代码运行还有Bug,所以选择了快速看完了后面几章,大概了解一下实现思路。然后,开始看《Python Web开发实践》,发现这本书的要求好高啊,初学者想看懂它,花的时间没有两三周还搞不定(PS:主要是里面讲的注重经验,没有实践项目),于是也选择了4天时间初步浏览了一遍。到了这里,我开始选择看网络教程,把廖雪峰老师的Python教程从基础部分一章一章上机实践操作了一遍(PS:最后的项目实战没操作),这个也差不多花了8天时间。后面又花了5天时间在网上找了几篇高质量关于使用Flask+MySQL实现用户登陆注册功能的Demo。到此,感觉对于Python基础掌握的更好了一点。发现学技术,尤其是新技术,要踏实,求稳。
所以,我选择了重新再看一遍《Flask Web开发——基于Python的Web应用开发实践》,并争取把书中每一个示例运行出来,如果发现Bug,就解决。在这一趟学习过程中,发现有关Flask的中文学习资源普遍没有英文高,而且相关技术学习书籍都是英文版翻译过来的。翻译过来的问题就是,书已经出版了两三年,有些模块库更新,导致书中代码实际就不能运行,还加上作者自己当时的微小错误没跟新。
本文先上传第1章到第7章的学习实践记录(PS:第8-14章见《Flask Web开发——基于Python的Web应用开发实践》一字一句上机实践(下)),目前我也是重新学到了这里。如果有学过Flask的前辈路过,有什么好的学习资源推荐,不甚感激。
叨叨絮絮有点多,本文主要内容就是记载自己在学习《Flask Web开发——基于Python的Web应用开发实践》时,上机运行相关示例遇到的坑以及一点心得体会,希望对于其他初学Flask的同学有点帮助。
附:《Flask Web开发——基于Python的Web应用开发实践》作者博客、作者网络教程版、作者本书GitHub代码链接
本书封面

第1章 安装
本部分内容安装书上内容一步一步来操作,很简单,基本不会出现问题。
注:本章主要教会初学者,如何安装虚拟环境。使用虚拟环境一段时间后,会发现学习Python,使用虚拟环境真的是很强大,可以避免Python解释器中包的混乱和版本的冲突,而且还不需要依赖管理员权限。
第2章 程序的基本结构
1.书本15页上方第二段代码:

上图中所示问题我特地查看了一下关于load_user()方法的调用及其作用,官方文档写明如下:
你需要提供一个 user_loader 回调。这个回调用于从会话中存储的用户 ID 重新加载用户对象。它应该接受一个用户的 unicode ID,并返回相应的用户对象。 例如:
@login_manager.user_loader
def load_user(userid):
return User.get(userid)
如果 ID 无效,它应该返回 None ( 而不是抛出异常 )。(在这种情况下,ID 会 被手动从会话中移除且处理会继续。)
2.书本16页左上角示例错误更改(PS:此处问题应该是包版本升级导致,不过作者关于该项目github上源码已更新):

此处错误,在后续章节中,出现类似flask.ext.**均修改为flask_**即可。
注:通过第2章,让我简单了解了Flask框架的基本运用方式。其中关键在于路由和视图函数的实现以及如何启动服务器,难点在于请求钩子概念的理解,我把这段概念反复看了好几遍,也只能理解讲解的文字表面意思,关于如何运用依旧是一头雾水。
第3章 模板
按照书本上所述,一步一步进行操作,即可得到如下运行结果:

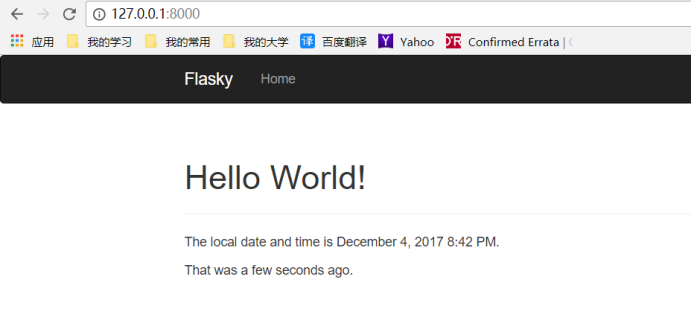
此处要注意一点就是,直接从GitHub上克隆出的代码,直接运行hello.py文件是行不通的。需要在hello.py文件最末端添加如下两行代码:
if __name__ == '__main__': app.run(port = 8000,debug = True)
上述代码意思是,打开Flask自带服务器,开启端口是8000,且处于调试模式。
注:第3章内容没有难点,认真看一下书上解释,很快就能弄懂相关代码意图。本章重点介绍了Jinja2模板引擎的运用(PS:此处建议初学者到网上看一下Jinja2的开发文档,加深理解),以及Flask-Bootstrap和Flask-Moment模块的使用方法,感觉所有功能都是已经写好的,只管调用即可,很方便。
第4章 Web表单
1.书本34页示例4-2代码更新(PS:引入包也要改成from flask_wtf import Form,后续章节一样):
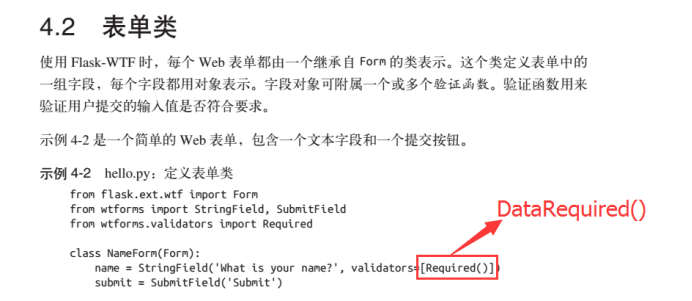
Class wtforms.validators.DataRequired(message=None)
此验证器将会检测field是否输入了数值,实际上是进行了if field.data操作。并且,如数数据是一个字符串,那么只包含空格的字符串将会被认为是False。
参数:message-当验证失败时返回的错误消息数:message-当验证失败时返回的错误消息。
此处作者GitHub上已更新。具体应用原理可以查看Flask-WTF开发文档。
2.看看学习本章内容实际运行效果图:
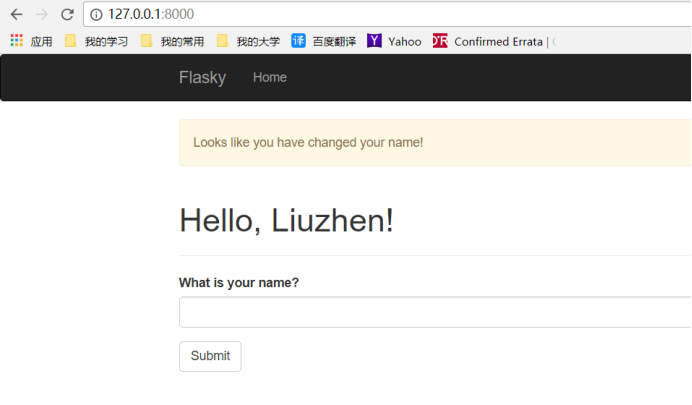
注:本章内容主要讲解了Flask-WTF的应用,此处强烈建议初学者先看一下Flask-WTF的开发文档,再来进行第四章的学习,这样理解会更加深刻一点,学的也会更快一点。
除此之外,还详细介绍了重定向和用户会话功能:主要是Post/重定向/Get模式,通过重定向实现了页面刷新仍然可以记住之前请求的数据,使得网页功能更加人性化和智能化。
最后,就是Flash消息功能的应用,通过此功能结合Flask-BootStrap包,在网页上进行相关提示操作简直是完美。
本章节从作者GitHub上下载的代码均是修过正的,不过书本是2014年出版,相关错误以及代码更新部分需注意即可。
第5章 数据库
1.书本47页示例5-1代码部分有bug,按照书本后续讲解进行操作会报以下错误:

按照报错提示,需要在app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True该行代码下添加如下一行代码:app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False

SQLALCHEMY_TRACK_MODIFICATIONS:如果设置成True(默认情况),Flask-SQLAlchemy 将会追踪对象的修改并且发送信号。这需要额外的内存, 如果不必要的可以禁用它。如果你不显示的调用它,在最新版的运行环境下,会显示警告。
2.书本50页5.8.1创建表,图中显示的操作符应该是在Mac或者Linux环境下进行的命令操作,如果是在Windows环境下,是达不到效果的,具体如下:

具体操作方法如下(WIndows版本):
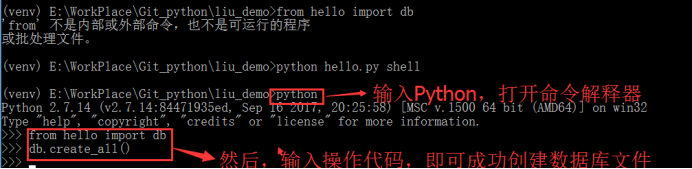
此处如何要按照书本上命令达到效果,可以参照第2章关于Flask-Scrip包的讲解,设置manager变量,然后就可以直接打开shell进行相关操作。
3.书本50页5.8节数据库操作部分示例运行结果
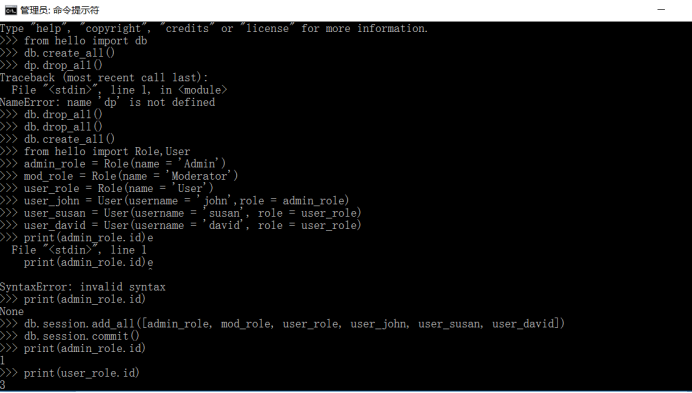

4.书本55页示例5-5部分关于操作数据库部分代码有问题

此处之所以这样修改代码,是因为设计的数据库角色和用户是一对多的关系,用户表中包含一个角色id外键。在对用户表进行插入操作时,必须要确认一个用户角色,否则无法插入。
附运行成功页面截图:

5.书本57页有关Flask-MIgrate相关配置命令如何正确实现问题
如果纯粹安装书本代码来进行相关命令操作,会发现输入python hello.py db init命令根本没有输出任何提示信息,即不能成功创建迁移仓库。如果从作者GitHub上克隆下来的代码,直接进行此命令操作,也是没有任何信息提示。此处需要在hello.py文件最末端,加上如下两行代码(PS:作者最新修改代码,未定义manager变量,此处需要查看第2章关于Flask-Script包讲解,自己定义好manager变量):
if __name__ == '__main__': manager.run()
再去控制台输入相关命令,即可实现相关操作,操作成功结果如下(PS:此处推荐一篇博客文章https://www.cnblogs.com/caicairui/p/7821586.html):

6.有关使用MySQL数据库实现相关增删查改操作问题
只要认真看完第5章内容,转用MySQL数据库实现增删查改操作非常简单,仅仅只需要把定义数据库URL地址改一下就可以,其他部分代码均不需要改动。具体修改如下:
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:root@localhost/test_flask' #app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///' + os.path.join(basedir,'data.sqlite')
上述代码意思,使用用户名和密码均为root的mysql数据库账号,进入已经创建好的test_flask数据库,进行相关表的创建以及数据的增删查改操作。自处可以仔细看一下书本46页表5-1。
注:通过本章的学习,让我基本了解了如何使用Flask-SQLAlchemy相关功能,以及实现对关系型数据库SQLite、MySQL的增删查改操作,最后最重要的就是学会了使用Flask-Migrate实现数据库迁移。为了能够较好的理解和掌握第5章内容,建议初学者认真看一下Flask-SQLAlchemy和Flask-Migrate的官方文档。
第6章 电子邮件
1.书本60页发送邮件示例
由于书本上使用googlemail邮箱,一般国内同学都不会使用这个邮箱。大部分都会使用QQ邮箱吧。此处只需要把设置写成app.config['MAIL_SERVER'] = 'smtp.qq.com',即把电子邮件服务器主机名中间的googlemail换成qq就行啦。
完成这些,如果仅仅使用自己的QQ邮箱号和QQ密码登陆发送邮件的话,会报以下错误:
smtplib.SMTPSenderRefused: (503, 'Error: need EHLO and AUTH first !', u'****’...)
解决办法(PS:此处关于QQ邮箱和登陆密码我是直接写在代码里的,没有用环境变量获取):
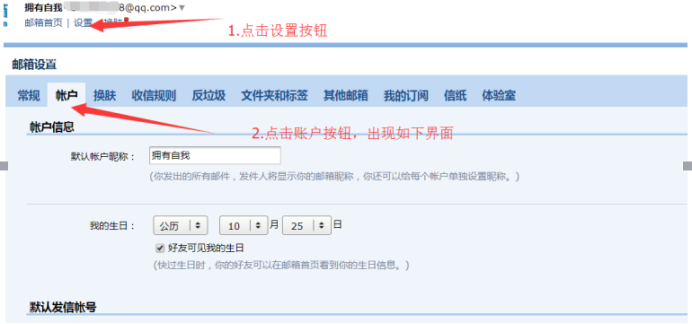
进入自己的QQ邮箱,完成如下设置操作:

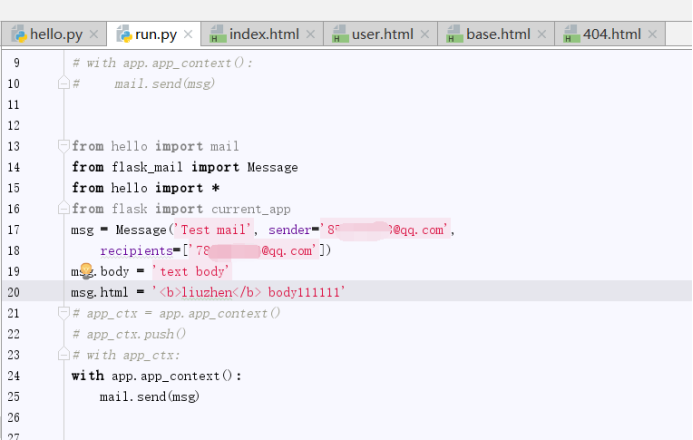
发送邮件测试代码(PS:上面获取QQ邮箱测试登陆临时密码有点坑的是,发送完短信后,可能30秒后浏览器上开启的QQ邮箱界面直接崩溃,不过这没关系,崩溃后也依旧可以发送邮件):
发送成功后的截图:
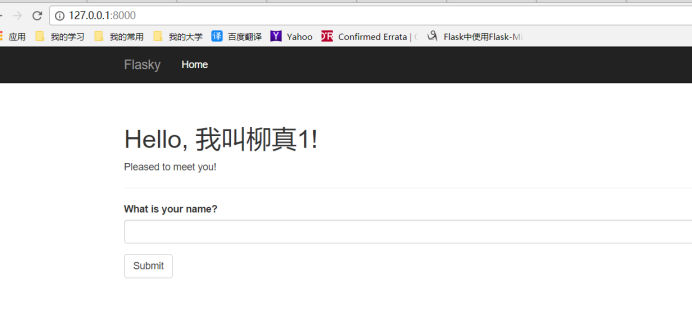
2.关于61页在程序中集成发送电子邮件功能
注意此处要结合第5章数据库功能,所以前提要确定在运行成功的页面上能够有效地把数据插入后台数据库。其次,要注意的是在templates文件下要自己动手新建一个mail文件夹,并在这个文件夹里新建new_user.txt和new_user.html两个文本文件,这样才能真正实现邮件发送功能。(PS:new_user.txt、new_user.html文件中内容,请查看从作者GitHub上克隆下来的代码)
运行成功结果页面如下(PS:此处实现功能获取邮箱信息,我都是直接写在代码中的,未使用环境变量获取):
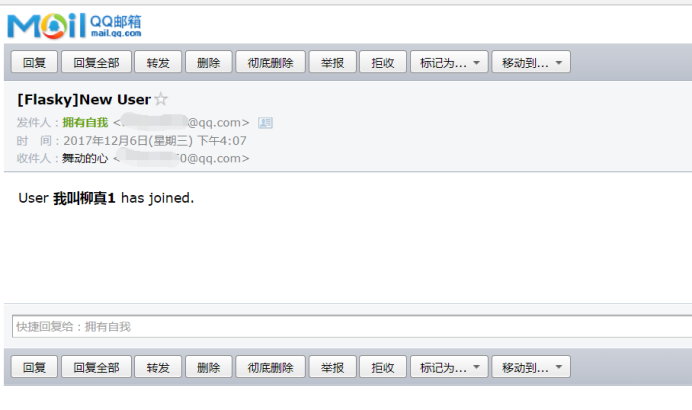
注:本章主要讲解了Flask-Mail的应用,功能应用不难,主要是涉及邮箱发送邮件时登陆需要相关服务器许可的配置问题有点麻烦。不过,整体来说,本章的应用,也从另一方面看到了Python的魅力,简单的几行代码即可实现一些比较复杂的功能。
第7章 大型程序的结构
1.书本66页示例7-2代码有bug
此处如果完全按照书本上代码,到了后续上机运行时会报以下错误:
E:\WorkPlace\Git_python\liu_demo\venv\lib\site-packages\flask_sqlalchemy\__init__.py:794: FSADeprecationWarning: SQLALCHEMY_TRACK_MODIFICATIONS adds significant overhead and will be disabled by default in the future. Set it to True or False to suppress this warning.
此处需要添加一行代码,如下图:

附Flask-SQLAlchemy配置键相关功能定义:
|
SQLALCHEMY_DATABASE_URI |
用于连接数据的数据库。例如:
|
|
SQLALCHEMY_BINDS |
一个映射绑定 (bind) 键到 SQLAlchemy 连接 URIs 的字典。 更多的信息请参阅 绑定多个数据库。 |
|
SQLALCHEMY_ECHO |
如果设置成 True,SQLAlchemy 将会记录所有 发到标准输出(stderr)的语句,这对调试很有帮助。 |
|
SQLALCHEMY_RECORD_QUERIES |
可以用于显式地禁用或者启用查询记录。查询记录 在调试或者测试模式下自动启用。更多信息请参阅 get_debug_queries()。 |
|
SQLALCHEMY_NATIVE_UNICODE |
可以用于显式地禁用支持原生的 unicode。这是 某些数据库适配器必须的(像在 Ubuntu 某些版本上的 PostgreSQL),当使用不合适的指定无编码的数据库 默认值时。 |
|
SQLALCHEMY_POOL_SIZE |
数据库连接池的大小。默认是数据库引擎的默认值 (通常是 5)。 |
|
SQLALCHEMY_POOL_TIMEOUT |
指定数据库连接池的超时时间。默认是 10。 |
|
SQLALCHEMY_POOL_RECYCLE |
自动回收连接的秒数。这对 MySQL 是必须的,默认 情况下 MySQL 会自动移除闲置 8 小时或者以上的连接。 需要注意地是如果使用 MySQL 的话, Flask-SQLAlchemy 会自动地设置这个值为 2 小时。 |
|
SQLALCHEMY_MAX_OVERFLOW |
控制在连接池达到最大值后可以创建的连接数。当这些额外的 连接回收到连接池后将会被断开和抛弃。 |
|
SQLALCHEMY_TRACK_MODIFICATIONS |
如果设置成 True (默认情况),Flask-SQLAlchemy 将会追踪对象的修改并且发送信号。这需要额外的内存, 如果不必要的可以禁用它。 |
添加上面一行代码后,再次去CMD进行相关命令操作,发现运行正常,结果如下:

2.书本74页创建数据库示例运行结果


注:第7章内容初看很简单,不重要,但是如果不仔细看懂每一个配置步骤以及相关代表含义,会发现学习后面章节,很难读懂相关代码。本章最重要的部分,得读懂7.2配置选项中config.py实现配置的具体方式,以及程序是如何调用这些设置好的配置。最后,需要注意的就是学会7.4启动脚本中manage.py代码具体内涵,因为写好的程序能否正常开启服务,一般都是通过这段代码来实现,说白了这里原理还是要回到第2章关于Flask-Script模块的讲解(PS:即有关使用manage.run()间接开启系统服务)。
最后,附加一份我自己学习前7章内容上机代码,都是按照书本上一行代码一行手动敲进去的,出现错误再修改,本部分代码和作者GitHub上最新版代码有些许不同。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号