

关于编码的笔记
(根据【金角大王alex】博客整理)
编码概述:
首先来看一下不同的编码方式:
- ASCII 占1个字节,只支持英文
- GB2312 占2个字节,支持6700+汉字
- GBK GB2312的升级版,支持21000+汉字
- Shift-JIS 日本字符
- ks_c_5601-1987 韩国编码
- TIS-620 泰国编码
由于每个国家都有自己的字符,所以其对应关系也涵盖了自己国家的字符,但是以上编码都存在局限性,即:仅涵盖本国字符,无其它国家字符的对应关系。应运而生出现了万国码(Unicode),它涵盖了全球所有的文字和二进制的对应关系:
Unicode:
- Unicode 2-4字节已经收录了136690个字符,目前还在不断扩张中...
Unicode有两个作用:
1. 直接支持全球所有语言,每个国家都可以不再使用自己之前的就编码了(类似于英语是全球的通用语言)
2. unicode包含了和全球所有国家编码的映射关系。
Unicode虽然解决了字符和二进制之间的关系,但是使用Unicode存储一个字符太浪费内存空间了,例如使用ASCII存储“Python”字符串仅仅需要6个字节,但是使用unicode则需要十二个字节。
使用Unicode编码在硬盘或者内存上存储空间过大的问题还是个小事情,但是在进行网络传输上则存在较大的问题,以"Python"这个字符串为例,使用Unicode相比ASCII则需要多传一倍的内容,但是本质上传输的内容还是相同的。
为了解决存储空间过大和网络传输增加带宽的问题,出现了Unicode Transformation Format(即UTF),它的作用是对unicode进行转换,以便于在存储和网络传输时可以节省空间。
UTF:
- utf-8:是通用1、2、3、4个字节表示所有字符;优先使用1个字节,无法满足则增加一个字节,最多4个字节。
- 英文:1个字节
- 欧洲语系:2个字节
- 东亚:3个字节
- 其它及特殊字符:4个字节
- utf-16:使用2、4个字节表示所有字符;优先使用2个字节,否则使用4个字节表示。
- utf-32:使用4个字节表示所有字符。
UTF是为unicode编码设计的一种在存储和传输时节省空间的编码方案。
字符在硬盘上的存储:
无论字符以什么编码在内存里显示,存到硬盘上都是2进制。
存储到硬盘上时以何种编码存的,再从硬盘上读出来,就必须以何种编码读,不然就会出现乱码。
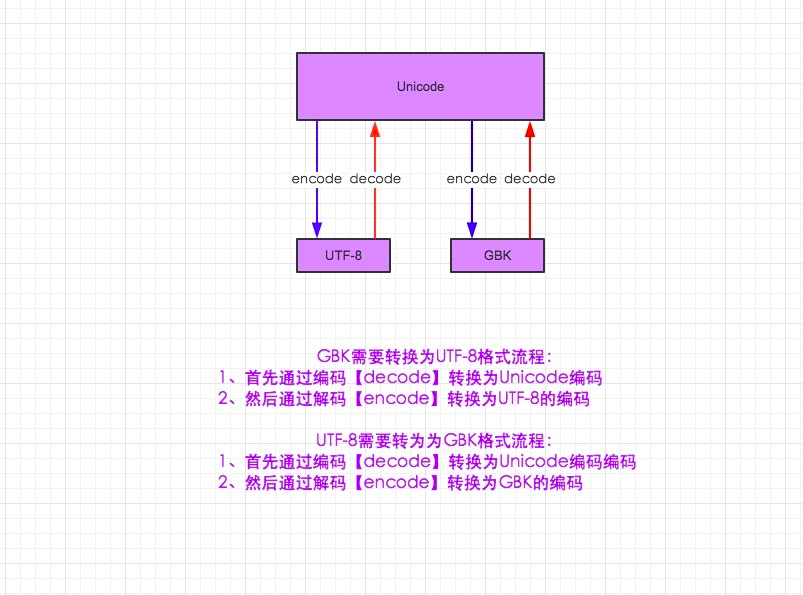
编码的转换:
unicode其中的一个功能是其包含了和全球所有国家编码的映射关系,换一句话说,就是使用gbk编码的“刘十一”,unicode能自动知道它在unicode中的“刘十一”的编码是什么。
在python2中,python文件默认的以ascii格式进行编码:
>>> import sys >>> sys.getdefaultencoding() 'ascii'
在python3中, python文件默认以utf-8方式进行编码:
liushiyi@bizhehaodeMacBook-Air ~ python3 Python 3.6.3 (v3.6.3:2c5fed86e0, Oct 3 2017, 00:32:08) [GCC 4.2.1 (Apple Inc. build 5666) (dot 3)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> import sys >>> sys.getdefaultencoding() 'utf-8'
Python3的执行过程:
1. 解释器找到代码文件,把代码字符串按文件头定义的编码加载到内存,转成unicode;
2. 把代码字符串按照语法规则进行解释;
3. 所有的变量字符都会以unicode编码进行声明。

