

Tornado源码分析 1.2.x 结合 4.4.x
一、application = tornado.web.Application([(xxx,xxx)])
执行Application类的构造函数,并传入一个列表类型的参数,这个列表里保存的是url规则和对应的处理类,即:当客户端的请求url可以配置这个规则时,那么该请求就交由对应的Handler去执行。
注意:Handler泛指继承自RequestHandler的所有类
Handlers泛指继承自RequestHandler的所有类的集合


class Application(object): def __init__(self, handlers=None, default_host="", transforms=None,wsgi=False, **settings): #设置响应的编码和返回方式,对应的http相应头:Content-Encoding和Transfer-Encoding #Content-Encoding:gzip 表示对数据进行压缩,然后再返回给用户,从而减少流量的传输。 #Transfer-Encoding:chunck 表示数据的传送方式通过一块一块的传输。 if transforms is None: self.transforms = [] if settings.get("gzip"): self.transforms.append(GZipContentEncoding) self.transforms.append(ChunkedTransferEncoding) else: self.transforms = transforms #将参数赋值为类的变量 self.handlers = [] self.named_handlers = {} self.default_host = default_host self.settings = settings #ui_modules和ui_methods用于在模版语言中扩展自定义输出 #这里将tornado内置的ui_modules和ui_methods添加到类的成员变量self.ui_modules和self.ui_methods中 self.ui_modules = {'linkify': _linkify, 'xsrf_form_html': _xsrf_form_html, 'Template': TemplateModule, } self.ui_methods = {} self._wsgi = wsgi #获取获取用户自定义的ui_modules和ui_methods,并将他们添加到之前创建的成员变量self.ui_modules和self.ui_methods中 self._load_ui_modules(settings.get("ui_modules", {})) self._load_ui_methods(settings.get("ui_methods", {})) #设置静态文件路径,设置方式则是通过正则表达式匹配url,让StaticFileHandler来处理匹配的url if self.settings.get("static_path"): #从settings中读取key为static_path的值,用于设置静态文件路径 path = self.settings["static_path"] #获取参数中传入的handlers,如果空则设置为空列表 handlers = list(handlers or []) #静态文件前缀,默认是/static/ static_url_prefix = settings.get("static_url_prefix","/static/") #在参数中传入的handlers前再添加三个映射: #【/static/.*】 --> StaticFileHandler #【/(favicon\.ico)】 --> StaticFileHandler #【/(robots\.txt)】 --> StaticFileHandler handlers = [ (re.escape(static_url_prefix) + r"(.*)", StaticFileHandler,dict(path=path)), (r"/(favicon\.ico)", StaticFileHandler, dict(path=path)), (r"/(robots\.txt)", StaticFileHandler, dict(path=path)), ] + handlers #执行本类的Application的add_handlers方法 #此时,handlers是一个列表,其中的每个元素都是一个对应关系,即:url正则表达式和处理匹配该正则的url的Handler if handlers: self.add_handlers(".*$", handlers) # Automatically reload modified modules #如果settings中设置了 debug 模式,那么就使用自动加载重启 if self.settings.get("debug") and not wsgi: import autoreload autoreload.start()
class Application(object): def add_handlers(self, host_pattern, host_handlers): #如果主机模型最后没有结尾符,那么就为他添加一个结尾符。 if not host_pattern.endswith("$"): host_pattern += "$" handlers = [] #对主机名先做一层路由映射,例如:http://www.wupeiqi.com 和 http://safe.wupeiqi.com #即:safe对应一组url映射,www对应一组url映射,那么当请求到来时,先根据它做第一层匹配,之后再继续进入内部匹配。 #对于第一层url映射来说,由于.*会匹配所有的url,所将 .* 的永远放在handlers列表的最后,不然 .* 就会截和了... #re.complie是编译正则表达式,以后请求来的时候只需要执行编译结果的match方法就可以去匹配了 if self.handlers and self.handlers[-1][0].pattern == '.*$': self.handlers.insert(-1, (re.compile(host_pattern), handlers)) else: self.handlers.append((re.compile(host_pattern), handlers)) #遍历我们设置的和构造函数中添加的【url->Handler】映射,将url和对应的Handler封装到URLSpec类中(构造函数中会对url进行编译) #并将所有的URLSpec对象添加到handlers列表中,而handlers列表和主机名模型组成一个元祖,添加到self.Handlers列表中。 for spec in host_handlers: if type(spec) is type(()): assert len(spec) in (2, 3) pattern = spec[0] handler = spec[1] if len(spec) == 3: kwargs = spec[2] else: kwargs = {} spec = URLSpec(pattern, handler, kwargs) handlers.append(spec) if spec.name: #未使用该功能,默认spec.name = None if spec.name in self.named_handlers: logging.warning("Multiple handlers named %s; replacing previous value",spec.name) self.named_handlers[spec.name] = spec
class URLSpec(object): def __init__(self, pattern, handler_class, kwargs={}, name=None): if not pattern.endswith('$'): pattern += '$' self.regex = re.compile(pattern) self.handler_class = handler_class self.kwargs = kwargs self.name = name self._path, self._group_count = self._find_groups()
上述代码主要完成了以下功能:加载配置信息和生成url映射,并且把所有的信息封装在一个application对象中。
加载的配置信息包括:
- 编码和返回方式信息
- 静态文件路径
- ui_modules(模版语言中使用,暂时忽略)
- ui_methods(模版语言中使用,暂时忽略)
- 是否debug模式运行
以上的所有配置信息,都可以在settings中配置,然后在创建Application对象时候,传入参数即可。如:application = tornado.web.Application([(r"/index", MainHandler),],**settings)
生成url映射:
- 将url和对应的Handler添加到对应的主机前缀中,如:safe.index.com、www.auto.com
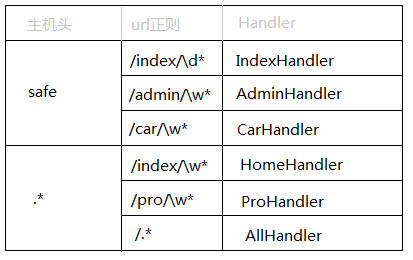
封装数据:
将配置信息和url映射关系封装到Application对象中,信息分别保存在Application对象的以下字段中:
- self.transforms,保存着编码和返回方式信息
- self.settings,保存着配置信息
- self.ui_modules,保存着ui_modules信息
- self.ui_methods,保存这ui_methods信息
- self.handlers,保存着所有的主机名对应的Handlers,每个handlers则是url正则对应的Handler
二、application.listen(xxx)
第一步操作将配置和url映射等信息封装到了application对象中,而这第二步执行application对象的listen方法,该方法内部又把之前包含各种信息的application对象封装到了一个HttpServer对象中,然后继续调用HttpServer对象的liseten方法。
class HTTPServer(object): def __init__(self, request_callback, no_keep_alive=False, io_loop=None,xheaders=False, ssl_options=None): #Application对象 self.request_callback = request_callback #是否长连接 self.no_keep_alive = no_keep_alive #IO循环 self.io_loop = io_loop self.xheaders = xheaders #Http和Http self.ssl_options = ssl_options self._socket = None self._started = False def listen(self, port, address=""): self.bind(port, address) self.start(1) def bind(self, port, address=None, family=socket.AF_UNSPEC): assert not self._socket #创建服务端socket对象,IPV4和TCP连接 self._socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM, 0) flags = fcntl.fcntl(self._socket.fileno(), fcntl.F_GETFD) flags |= fcntl.FD_CLOEXEC fcntl.fcntl(self._socket.fileno(), fcntl.F_SETFD, flags) #配置socket对象 self._socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) self._socket.setblocking(0) #绑定IP和端口 self._socket.bind((address, port)) #最大阻塞数量 self._socket.listen(128) def start(self, num_processes=1): assert not self._started self._started = True if num_processes is None or num_processes <= 0: num_processes = _cpu_count() if num_processes > 1 and ioloop.IOLoop.initialized(): logging.error("Cannot run in multiple processes: IOLoop instance " "has already been initialized. You cannot call " "IOLoop.instance() before calling start()") num_processes = 1 #如果进程数大于1 if num_processes > 1: logging.info("Pre-forking %d server processes", num_processes) for i in range(num_processes): if os.fork() == 0: import random from binascii import hexlify try: # If available, use the same method as # random.py seed = long(hexlify(os.urandom(16)), 16) except NotImplementedError: # Include the pid to avoid initializing two # processes to the same value seed(int(time.time() * 1000) ^ os.getpid()) random.seed(seed) self.io_loop = ioloop.IOLoop.instance() self.io_loop.add_handler( self._socket.fileno(), self._handle_events, ioloop.IOLoop.READ) return os.waitpid(-1, 0) #进程数等于1,默认 else: if not self.io_loop: #设置成员变量self.io_loop为IOLoop的实例,注:IOLoop使用methodclass完成了一个单例模式 self.io_loop = ioloop.IOLoop.instance() #执行IOLoop的add_handler方法,将socket句柄、self._handle_events方法和IOLoop.READ当参数传入 self.io_loop.add_handler(self._socket.fileno(), self._handle_events, ioloop.IOLoop.READ) def _handle_events(self, fd, events): while True: try: #====important=====# connection, address = self._socket.accept() except socket.error, e: if e.args[0] in (errno.EWOULDBLOCK, errno.EAGAIN): return raise if self.ssl_options is not None: assert ssl, "Python 2.6+ and OpenSSL required for SSL" try: #====important=====# connection = ssl.wrap_socket(connection,server_side=True,do_handshake_on_connect=False,**self.ssl_options) except ssl.SSLError, err: if err.args[0] == ssl.SSL_ERROR_EOF: return connection.close() else: raise except socket.error, err: if err.args[0] == errno.ECONNABORTED: return connection.close() else: raise try: if self.ssl_options is not None: stream = iostream.SSLIOStream(connection, io_loop=self.io_loop) else: stream = iostream.IOStream(connection, io_loop=self.io_loop) #====important=====# HTTPConnection(stream, address, self.request_callback,self.no_keep_alive, self.xheaders) except: logging.error("Error in connection callback", exc_info=True)
IOLoop
def wrap(fn): '''Returns a callable object that will resore the current StackContext when executed. Use this whenever saving a callback to be executed later in a different execution context (either in a different thread or asynchronously in the same thread). ''' if fn is None: return None # functools.wraps doesn't appear to work on functools.partial objects #@functools.wraps(fn) def wrapped(callback, contexts, *args, **kwargs): # If we're moving down the stack, _state.contexts is a prefix # of contexts. For each element of contexts not in that prefix, # create a new StackContext object. # If we're moving up the stack (or to an entirely different stack), # _state.contexts will have elements not in contexts. Use # NullContext to clear the state and then recreate from contexts. if (len(_state.contexts) > len(contexts) or any(a[1] is not b[1] for a, b in itertools.izip(_state.contexts, contexts))): # contexts have been removed or changed, so start over new_contexts = ([NullContext()] + [cls(arg) for (cls,arg) in contexts]) else: new_contexts = [cls(arg) for (cls, arg) in contexts[len(_state.contexts):]] if len(new_contexts) > 1: with contextlib.nested(*new_contexts): callback(*args, **kwargs) elif new_contexts: with new_contexts[0]: callback(*args, **kwargs) else: callback(*args, **kwargs) if getattr(fn, 'stack_context_wrapped', False): return fn contexts = _state.contexts result = functools.partial(wrapped, fn, contexts) result.stack_context_wrapped = True return result
备注:stack_context.wrap其实就是对函数进行一下封装,即:函数在不同情况下上下文信息可能不同。
上述代码本质上就干了以下这么四件事:
- 把包含了各种配置信息的application对象封装到了HttpServer对象的request_callback字段中
- 创建了服务端socket对象
- 单例模式创建IOLoop对象,然后将socket对象句柄作为key,被封装了的函数_handle_events作为value,添加到IOLoop对象的_handlers字段中
- 向epoll中注册监听服务端socket对象的读可用事件
目前,我们只是看到上述代码大致干了这四件事,而其目的有什么?他们之间的联系又是什么呢?
答:现在不妨先来做一个猜想,待之后再在源码中确认验证是否正确!猜想:通过epoll监听服务端socket事件,一旦请求到达时,则执行3中被封装了的_handle_events函数,该函数又利用application中封装了的各种配置信息对客户端url来指定判定,然后指定对应的Handler处理该请求。
注意:上述是 tornado 1.2.x版本,而4.4.x版本 accept_handler 中accept() 结尾调用回调函数callback就是 _handle_connection,是TCPServer类中的方法
def _handle_connection(self, connection, address): if self.ssl_options is not None: assert ssl, "Python 2.6+ and OpenSSL required for SSL" try: connection = ssl_wrap_socket(connection, self.ssl_options, server_side=True, do_handshake_on_connect=False) except ssl.SSLError as err: if err.args[0] == ssl.SSL_ERROR_EOF: return connection.close() else: raise except socket.error as err: # If the connection is closed immediately after it is created # (as in a port scan), we can get one of several errors. # wrap_socket makes an internal call to getpeername, # which may return either EINVAL (Mac OS X) or ENOTCONN # (Linux). If it returns ENOTCONN, this error is # silently swallowed by the ssl module, so we need to # catch another error later on (AttributeError in # SSLIOStream._do_ssl_handshake). # To test this behavior, try nmap with the -sT flag. # https://github.com/tornadoweb/tornado/pull/750 if errno_from_exception(err) in (errno.ECONNABORTED, errno.EINVAL): return connection.close() else: raise try: if self.ssl_options is not None: stream = SSLIOStream(connection, io_loop=self.io_loop, max_buffer_size=self.max_buffer_size, read_chunk_size=self.read_chunk_size) else: stream = IOStream(connection, io_loop=self.io_loop, max_buffer_size=self.max_buffer_size, read_chunk_size=self.read_chunk_size) future = self.handle_stream(stream, address) if future is not None: self.io_loop.add_future(future, lambda f: f.result()) except Exception: app_log.error("Error in connection callback", exc_info=True)
注意:使用epoll创建服务端socket
import socket, select EOL1 = b'/n/n' EOL2 = b'/n/r/n' response = b'HTTP/1.0 200 OK/r/nDate: Mon, 1 Jan 1996 01:01:01 GMT/r/n' response += b'Content-Type: text/plain/r/nContent-Length: 13/r/n/r/n' response += b'Hello, world!' serversocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) serversocket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) serversocket.bind(('0.0.0.0', 8080)) serversocket.listen(1) serversocket.setblocking(0) epoll = select.epoll() epoll.register(serversocket.fileno(), select.EPOLLIN) try: connections = {}; requests = {}; responses = {} while True: events = epoll.poll(1) for fileno, event in events: if fileno == serversocket.fileno(): connection, address = serversocket.accept() connection.setblocking(0) epoll.register(connection.fileno(), select.EPOLLIN) connections[connection.fileno()] = connection requests[connection.fileno()] = b'' responses[connection.fileno()] = response elif event & select.EPOLLIN: requests[fileno] += connections[fileno].recv(1024) if EOL1 in requests[fileno] or EOL2 in requests[fileno]: epoll.modify(fileno, select.EPOLLOUT) print('-'*40 + '/n' + requests[fileno].decode()[:-2]) elif event & select.EPOLLOUT: byteswritten = connections[fileno].send(responses[fileno]) responses[fileno] = responses[fileno][byteswritten:] if len(responses[fileno]) == 0: epoll.modify(fileno, 0) connections[fileno].shutdown(socket.SHUT_RDWR) elif event & select.EPOLLHUP: epoll.unregister(fileno) connections[fileno].close() del connections[fileno] finally: epoll.unregister(serversocket.fileno()) epoll.close() serversocket.close()
上述,其实就是利用epoll对象的poll(timeout)方法去轮询已经注册在epoll中的socket句柄,当有读可用的信息时候,则返回包含当前句柄和Event Code的序列,然后在通过句柄对客户端的请求进行处理
三、tornado.ioloop.IOLoop.instance().start()
上一步中创建了socket对象并使得socket对象和epoll建立了关系,该步骤则就来执行epoll的epoll方法去轮询已经注册在epoll对象中的socket句柄,当有读可用信息时,则触发一些操作什么的....
4.4.x版本的start被分装在了IOLoop的派生类中
class IOLoop(object):
def add_handler(self, fd, handler, events):
#HttpServer的Start方法中会调用该方法
self._handlers[fd] = stack_context.wrap(handler)
self._impl.register(fd, events | self.ERROR)
def start(self):
while True:
poll_timeout = 0.2
try:
#epoll中轮询
event_pairs = self._impl.poll(poll_timeout)
except Exception, e:
#省略其他
#如果有读可用信息,则把该socket对象句柄和Event Code序列添加到self._events中
self._events.update(event_pairs)
#遍历self._events,处理每个请求
while self._events:
fd, events = self._events.popitem()
try:
#以socket为句柄为key,取出self._handlers中的stack_context.wrap(handler),并执行
#stack_context.wrap(handler)包装了HTTPServer类的_handle_events函数的一个函数
#是在上一步中执行add_handler方法时候,添加到self._handlers中的数据。
self._handlers[fd](fd, events)
except:
#省略其他
class IOLoop(object): def start(self): """Starts the I/O loop. The loop will run until one of the I/O handlers calls stop(), which will make the loop stop after the current event iteration completes. """ if self._stopped: self._stopped = False return self._running = True while True: # Never use an infinite timeout here - it can stall epoll poll_timeout = 0.2 # Prevent IO event starvation by delaying new callbacks # to the next iteration of the event loop. callbacks = self._callbacks self._callbacks = [] for callback in callbacks: self._run_callback(callback) if self._callbacks: poll_timeout = 0.0 if self._timeouts: now = time.time() while self._timeouts and self._timeouts[0].deadline <= now: timeout = self._timeouts.pop(0) self._run_callback(timeout.callback) if self._timeouts: milliseconds = self._timeouts[0].deadline - now poll_timeout = min(milliseconds, poll_timeout) if not self._running: break if self._blocking_signal_threshold is not None: # clear alarm so it doesn't fire while poll is waiting for # events. signal.setitimer(signal.ITIMER_REAL, 0, 0) try: event_pairs = self._impl.poll(poll_timeout) except Exception, e: # Depending on python version and IOLoop implementation, # different exception types may be thrown and there are # two ways EINTR might be signaled: # * e.errno == errno.EINTR # * e.args is like (errno.EINTR, 'Interrupted system call') if (getattr(e, 'errno', None) == errno.EINTR or (isinstance(getattr(e, 'args', None), tuple) and len(e.args) == 2 and e.args[0] == errno.EINTR)): continue else: raise if self._blocking_signal_threshold is not None: signal.setitimer(signal.ITIMER_REAL, self._blocking_signal_threshold, 0) # Pop one fd at a time from the set of pending fds and run # its handler. Since that handler may perform actions on # other file descriptors, there may be reentrant calls to # this IOLoop that update self._events self._events.update(event_pairs) while self._events: fd, events = self._events.popitem() try: self._handlers[fd](fd, events) except (KeyboardInterrupt, SystemExit): raise except (OSError, IOError), e: if e.args[0] == errno.EPIPE: # Happens when the client closes the connection pass else: logging.error("Exception in I/O handler for fd %d", fd, exc_info=True) except: logging.error("Exception in I/O handler for fd %d", fd, exc_info=True) # reset the stopped flag so another start/stop pair can be issued self._stopped = False if self._blocking_signal_threshold is not None: signal.setitimer(signal.ITIMER_REAL, 0, 0)
对于上述代码,执行start方法后,程序就进入“死循环”,也就是会一直不停的轮询的去检查是否有请求到来,如果有请求到达,则执行封装了HttpServer类的_handle_events方法和相关上下文的stack_context.wrap(handler)(其实就是执行HttpServer类的_handle_events方法),详细见下篇博文,简要代码如下:
class HTTPServer(object): def _handle_events(self, fd, events): while True: try: connection, address = self._socket.accept() except socket.error, e: if e.args[0] in (errno.EWOULDBLOCK, errno.EAGAIN): return raise if self.ssl_options is not None: assert ssl, "Python 2.6+ and OpenSSL required for SSL" try: connection = ssl.wrap_socket(connection, server_side=True, do_handshake_on_connect=False, **self.ssl_options) except ssl.SSLError, err: if err.args[0] == ssl.SSL_ERROR_EOF: return connection.close() else: raise except socket.error, err: if err.args[0] == errno.ECONNABORTED: return connection.close() else: raise try: if self.ssl_options is not None: stream = iostream.SSLIOStream(connection, io_loop=self.io_loop) else: stream = iostream.IOStream(connection, io_loop=self.io_loop) HTTPConnection(stream, address, self.request_callback, self.no_keep_alive, self.xheaders) except: logging.error("Error in connection callback", exc_info=True)
结束
本文介绍了“待请求阶段”的所作所为,简要来说其实就是三件事:其一、把setting中的各种配置以及url和Handler之间的映射关系封装到来application对象中(application对象又被封装到了HttpServer对象的request_callback字段中);其二、结合epoll创建服务端socket;其三、当请求到达时交由HttpServer类的_handle_events(4.4.x中是_handle_connection)方法处理请求,即:处理请求的入口。对于处理请求的详细,请参见下篇博客(客官莫急,加班编写中...)
3 请求到达处理
【start】是一个死循环,其中利用epoll监听服务端socket句柄,一旦客户端发送请求,则立即调用HttpServer对象的_handle_events方法来进行请求的处理。
对于整个3系列按照功能可以划分为四大部分:
- 获取用户请求数据(上图3.4)
- 根据用户请求URL进行路由匹配,从而使得某个方法处理具体的请求(上图3.5~3.19)
- 将处理后的数据返回给客户端(上图3.21~3.23)
- 关闭客户端socket(上图3.24~3.26)
3.1、HTTPServer对象的_handle_events方法
此处代码主要有三项任务:
1、 socket.accept() 接收了客户端请求。
2、创建封装了客户端socket对象和IOLoop对象的IOStream实例(用于之后获取或输出数据)。
3、创建HTTPConnection对象,其内容是实现整个功能的逻辑。
class HTTPServer(object): def _handle_events(self, fd, events): while True: try: #======== 获取客户端请求 =========# connection, address = self._socket.accept() except socket.error, e: if e.args[0] in (errno.EWOULDBLOCK, errno.EAGAIN): return raise if self.ssl_options is not None: assert ssl, "Python 2.6+ and OpenSSL required for SSL" try: connection = ssl.wrap_socket(connection, server_side=True, do_handshake_on_connect=False, **self.ssl_options) except ssl.SSLError, err: if err.args[0] == ssl.SSL_ERROR_EOF: return connection.close() else: raise except socket.error, err: if err.args[0] == errno.ECONNABORTED: return connection.close() else: raise try: #这是的条件是选择https和http请求方式 if self.ssl_options is not None: stream = iostream.SSLIOStream(connection, io_loop=self.io_loop) else: #将客户端socket对象和IOLoop对象封装到IOStream对象中 #IOStream用于从客户端socket中读取请求信息 stream = iostream.IOStream(connection, io_loop=self.io_loop) #创建HTTPConnection对象 #address是客户端IPdizhi #self.request_callback是Application对象,其中包含了:url映射关系和配置文件等.. #so,HTTPConnection的构造函数就是下一步处理请求的位置了.. HTTPConnection(stream, address, self.request_callback,self.no_keep_alive, self.xheaders) except: logging.error("Error in connection callback", exc_info=True)
在4.4.x中tcpserver TCPSever====add_socketet======add_accept_handler 传入回调 _handle_connection
3.2、IOStream的__init__方法
此处代码主要两项目任务:
- 封装客户端socket和其他信息,以便之后执行该对象的其他方法获取客户端请求的数据和响应客户信息
- 将客户端socket对象添加到epoll,并且指定当客户端socket对象变化时,就去执行 IOStream的_handle_events方法(调用socket.send给用户响应数据)
class IOStream(object):
def __init__(self, socket, io_loop=None, max_buffer_size=104857600,
read_chunk_size=4096):
#客户端socket对象
self.socket = socket
self.socket.setblocking(False)
self.io_loop = io_loop or ioloop.IOLoop.instance()
self.max_buffer_size = max_buffer_size
self.read_chunk_size = read_chunk_size
self._read_buffer = collections.deque()
self._write_buffer = collections.deque()
self._write_buffer_frozen = False
self._read_delimiter = None
self._read_bytes = None
self._read_callback = None
self._write_callback = None
self._close_callback = None
self._connect_callback = None
self._connecting = False
self._state = self.io_loop.ERROR
with stack_context.NullContext():
#将客户端socket句柄添加的epoll中,并将IOStream的_handle_events方法添加到 Start 的While循环中
#Start 的While循环中监听客户端socket句柄的状态,以便再最后调用IOStream的_handle_events方法把处理后的信息响应给用户
self.io_loop.add_handler(self.socket.fileno(), self._handle_events, self._state)
3.3、HTTPConnections的__init__方法
此处代码主要两项任务:
- 获取请求数据
- 调用 _on_headers 继续处理请求
对于获取请求数据,其实就是执行IOStream的read_until函数来完成,其内部通过socket.recv(4096)方法获取客户端请求的数据,并以 【\r\n\r\n】作为请求信息结束符(http请求头和内容通过\r\n\r\n分割)。
class HTTPConnection(object):
def __init__(self, stream, address, request_callback, no_keep_alive=False,xheaders=False):
self.stream = stream #stream是封装了客户端socket和IOLoop实例的IOStream对象
self.address = address #address是客户端IP地址
self.request_callback = request_callback #request_callback是封装了URL映射和配置文件的Application对象。
self.no_keep_alive = no_keep_alive
self.xheaders = xheaders
self._request = None
self._request_finished = False
#获取请求信息(请求头和内容),然后执行 HTTPConnection的_on_headers方法继续处理请求
self._header_callback = stack_context.wrap(self._on_headers)
self.stream.read_until("\r\n\r\n", self._header_callback)
请求数据格式:
GET / HTTP/1.1
Host: localhost:8888
Connection: keep-alive
Cache-Control: max-age=0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
User-Agent: Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.118 Safari/537.36
Accept-Encoding: gzip, deflate, sdch
Accept-Language: zh-CN,zh;q=0.8,en;q=0.6,zh-TW;q=0.4
If-None-Match: "e02aa1b106d5c7c6a98def2b13005d5b84fd8dc8"
详细代码解析:
class IOStream(object): def read_until(self, delimiter, callback): """Call callback when we read the given delimiter.""" assert not self._read_callback, "Already reading" #终止界定 \r\n\r\n self._read_delimiter = delimiter #回调函数,即:HTTPConnection的 _on_headers 方法 self._read_callback = stack_context.wrap(callback) while True: #代码概述: #先从socket中读取信息并保存到buffer中 #然后再读取buffer中的数据,以其为参数执行回调函数(HTTPConnection的 _on_headers 方法) #buffer其实是一个线程安装的双端队列collections.deque #从buffer中读取数据,并执行回调函数。 #注意:首次执行时buffer中没有数据 if self._read_from_buffer(): return self._check_closed() #从socket中读取信息到buffer(线程安全的一个双向消息队列) if self._read_to_buffer() == 0: break self._add_io_state(self.io_loop.READ)
class IOStream(object): def _read_to_buffer(self): #省略部分代码 chunk = self._read_from_socket() self._read_buffer.append(chunk) return len(chunk) def _read_from_socket(self): #socket对象的recv函数接收数据 #read_chunk_size在构造函数中默认设置为:4096 chunk = self.socket.recv(self.read_chunk_size) if not chunk: self.close() return None return chunk
class IOStream(object): def _read_from_buffer(self): """Attempts to complete the currently-pending read from the buffer. Returns True if the read was completed. """ #构造函数中默认设置为None if self._read_bytes: if self._read_buffer_size() >= self._read_bytes: num_bytes = self._read_bytes callback = self._read_callback self._read_callback = None self._read_bytes = None self._run_callback(callback, self._consume(num_bytes)) return True #_read_delimiter的值为 \r\n\r\n elif self._read_delimiter: #buffer列表首元素合并,合并详细见_merge_prefix函数 _merge_prefix(self._read_buffer, sys.maxint) #获取 \r\n\r\n 所在 buffer 首元素的位置索引 loc = self._read_buffer[0].find(self._read_delimiter) if loc != -1: #如果在请求中找到了 \r\n\r\n #self._read_callback 是HTTPConnection对象的 _on_headers 方法 callback = self._read_callback delimiter_len = len(self._read_delimiter) #获取 \r\n\r\n 的长度 self._read_callback = None self._read_delimiter = None #============ 执行HTTPConnection对象的 _on_headers 方法 ============= #self._consume(loc + delimiter_len)用来获取 buffer 的首元素(请求的信息其实就被封装到了buffer的首个元素中) self._run_callback(callback,self._consume(loc + delimiter_len)) return True return False
3.4、HTTPConnnection的 _on_headers 方法(含3.5)
上述代码主要有两个任务:
- 根据获取的请求信息生成响应的请求头键值对,并把信息封装到HttpRequest对象中
- 调用Application的__call__方法,继续处理请求
class HTTPConnection(object):
def _on_headers(self, data):
try:
data = native_str(data.decode('latin1'))
eol = data.find("\r\n")
#获取请求的起始行数据,例如:GET / HTTP/1.1
start_line = data[:eol]
try:
#请求方式、请求地址、http版本号
method, uri, version = start_line.split(" ")
except ValueError:
raise _BadRequestException("Malformed HTTP request line")
if not version.startswith("HTTP/"):
raise _BadRequestException("Malformed HTTP version in HTTP Request-Line")
#把请求头信息包装到一个字典中。(不包括第一行)
headers = httputil.HTTPHeaders.parse(data[eol:])
#把请求信息封装到一个HTTPRequest对象中
#注意:self._request = HTTPRequest,
#HTTPRequest中封装了HTTPConnection
#HTTPConnection中封装了stream和application
self._request = HTTPRequest(connection=self, method=method, uri=uri, version=version,headers=headers, remote_ip=self.address[0])
#从请求头中获取 Content-Length
content_length = headers.get("Content-Length")
if content_length:
content_length = int(content_length)
if content_length > self.stream.max_buffer_size:
raise _BadRequestException("Content-Length too long")
if headers.get("Expect") == "100-continue":
self.stream.write("HTTP/1.1 100 (Continue)\r\n\r\n")
self.stream.read_bytes(content_length, self._on_request_body)
return
#**************** 执行Application对象的 __call__ 方法,也就是路由系统的入口 *******************
self.request_callback(self._request)
except _BadRequestException, e:
logging.info("Malformed HTTP request from %s: %s",
self.address[0], e)
self.stream.close()
return
class HTTPRequest(object): def __init__(self, method, uri, version="HTTP/1.0", headers=None, body=None, remote_ip=None, protocol=None, host=None, files=None, connection=None): self.method = method self.uri = uri self.version = version self.headers = headers or httputil.HTTPHeaders() self.body = body or "" if connection and connection.xheaders: # Squid uses X-Forwarded-For, others use X-Real-Ip self.remote_ip = self.headers.get( "X-Real-Ip", self.headers.get("X-Forwarded-For", remote_ip)) # AWS uses X-Forwarded-Proto self.protocol = self.headers.get( "X-Scheme", self.headers.get("X-Forwarded-Proto", protocol)) if self.protocol not in ("http", "https"): self.protocol = "http" else: self.remote_ip = remote_ip if protocol: self.protocol = protocol elif connection and isinstance(connection.stream, iostream.SSLIOStream): self.protocol = "https" else: self.protocol = "http" self.host = host or self.headers.get("Host") or "127.0.0.1" self.files = files or {} self.connection = connection self._start_time = time.time() self._finish_time = None scheme, netloc, path, query, fragment = urlparse.urlsplit(uri) self.path = path self.query = query arguments = cgi.parse_qs(query) self.arguments = {} for name, values in arguments.iteritems(): values = [v for v in values if v] if values: self.arguments[name] = values
3.6、Application的__call__方法(含3.7、3.8、3.9)
此处代码主要有三个项任务:
- 根据请求的url和封装在Application对象中的url映射做匹配,获取url所对应的Handler对象。ps:Handlers泛指继承RequestHandler的类
- 创建Handler对象,即:执行Handler的__init__方法
- 执行Handler对象的 _execute 方法
注意:
1、执行Application的 __call__ 方法时,其参数request是HTTPRequest对象(其中封装HTTPConnetion、Stream、Application对象、请求头信息)
2、Handler泛指就是我们定义的用于处理请求的类并且她还继承自RequestHandler
class Application(object):
def __call__(self, request):
"""Called by HTTPServer to execute the request."""
transforms = [t(request) for t in self.transforms]
handler = None
args = []
kwargs = {}
#根据请求的目标主机,匹配主机模版对应的正则表达式和Handlers
handlers = self._get_host_handlers(request)
if not handlers:
handler = RedirectHandler(
self, request, url="http://" + self.default_host + "/")
else:
for spec in handlers:
match = spec.regex.match(request.path)
if match:
# None-safe wrapper around url_unescape to handle
# unmatched optional groups correctly
def unquote(s):
if s is None: return s
return escape.url_unescape(s, encoding=None)
handler = spec.handler_class(self, request, **spec.kwargs) #创建RquestHandler对象
# Pass matched groups to the handler. Since
# match.groups() includes both named and unnamed groups,
# we want to use either groups or groupdict but not both.
# Note that args are passed as bytes so the handler can
# decide what encoding to use.
kwargs = dict((k, unquote(v))
for (k, v) in match.groupdict().iteritems())
if kwargs:
args = []
else:
args = [unquote(s) for s in match.groups()]
break
if not handler:
handler = ErrorHandler(self, request, status_code=404)
# In debug mode, re-compile templates and reload static files on every
# request so you don't need to restart to see changes
if self.settings.get("debug"):
if getattr(RequestHandler, "_templates", None):
for loader in RequestHandler._templates.values():
loader.reset()
RequestHandler._static_hashes = {}
#==== 执行RequestHandler的_execute方法 ====
handler._execute(transforms, *args, **kwargs)
return handler
class Application(object): def _get_host_handlers(self, request): #将请求的host和handlers中的主机模型进行匹配 host = request.host.lower().split(':')[0] for pattern, handlers in self.handlers: if pattern.match(host): return handlers # Look for default host if not behind load balancer (for debugging) if "X-Real-Ip" not in request.headers: for pattern, handlers in self.handlers: if pattern.match(self.default_host): return handlers return None
class RequestHandler(object): SUPPORTED_METHODS = ("GET", "HEAD", "POST", "DELETE", "PUT", "OPTIONS") def __init__(self, application, request, **kwargs): self.application = application self.request = request self._headers_written = False self._finished = False self._auto_finish = True self._transforms = None # will be set in _execute #获取在application中设置的 ui_modules 和ui_method self.ui = _O((n, self._ui_method(m)) for n, m in application.ui_methods.iteritems()) self.ui["modules"] = _O((n, self._ui_module(n, m)) for n, m in application.ui_modules.iteritems()) self.clear() #设置服务器、内容类型编码和连接 # Check since connection is not available in WSGI #检查连接是否可用,应该是长短连接有关。 if hasattr(self.request, "connection"): self.request.connection.stream.set_close_callback(self.on_connection_close) self.initialize(**kwargs) def initialize(self): pass def clear(self): """Resets all headers and content for this response.""" self._headers = { "Server": "TornadoServer/%s" % tornado.version, "Content-Type": "text/html; charset=UTF-8", } if not self.request.supports_http_1_1(): if self.request.headers.get("Connection") == "Keep-Alive": self.set_header("Connection", "Keep-Alive") self._write_buffer = [] self._status_code = 200
上述过程中,首先根据请求的URL去路由规则中匹配,一旦匹配成功,则创建路由相对应的handler的实例。例如:如果请求 的url是【/index/11】则会创建IndexHandler实例,然后再执行该对象的 _execute 方法。由于所有的 xxxHandler 类是RequestHandler的派生类,所以会默认执行 RequestHandler的 _execute 方法。
3.10 RequestHandler的_execute方法 (含有3.11、3.12、3.13)
此处代码主要有三项任务:
- 扩展点,因为self.prepare默认是空方法,所有可以在这里被重写
- 通过反射执行Handler的get/post/put/delete等方法
- 完成请求处理后,执行finish方法
class RequestHandler(object):
def _execute(self, transforms, *args, **kwargs):
"""Executes this request with the given output transforms."""
self._transforms = transforms
with stack_context.ExceptionStackContext(
self._stack_context_handle_exception):
if self.request.method not in self.SUPPORTED_METHODS:
raise HTTPError(405)
# If XSRF cookies are turned on, reject form submissions without
# the proper cookie
if self.request.method not in ("GET", "HEAD") and \
self.application.settings.get("xsrf_cookies"):
self.check_xsrf_cookie()
self.prepare()
if not self._finished:
#通过反射的方法,执行 RequestHandler 派生类的的 get、post、put方法
getattr(self, self.request.method.lower())(*args, **kwargs)
if self._auto_finish and not self._finished:
self.finish()
例:用户发送get请求
class MyHandler(tornado.web.RequestHandler):
def get(self):
self.write("Hello, world")
class RequestHandler(object): def write(self, chunk): assert not self._finished if isinstance(chunk, dict): chunk = escape.json_encode(chunk) self.set_header("Content-Type", "text/javascript; charset=UTF-8") chunk = _utf8(chunk) self._write_buffer.append(chunk)
上述在执行RequestHandler的write方法时,讲数据保存在Handler对象的 _write_buffer 列表中,在之后执行finish时再讲数据写到IOStream对象的_write_buffer字段中,其类型是双向队列collections.deque()。
3.14、执行RequestHandler的finish
此段代码主要有两项任务:
- 将用户处理请求后返回的数据发送到IOStream的_write_buffer队列中
- 纪录操作日志
def finish(self, chunk=None):
"""Finishes this response, ending the HTTP request."""
if self._finished:
raise RuntimeError("finish() called twice")
if chunk is not None:
self.write(chunk)
# Automatically support ETags and add the Content-Length header if
# we have not flushed any content yet.
if not self._headers_written:
if (self._status_code == 200 and
self.request.method in ("GET", "HEAD") and
"Etag" not in self._headers):
self.set_etag_header()
if self.check_etag_header():
self._write_buffer = []
self.set_status(304)
if self._status_code in (204, 304):
assert not self._write_buffer, "Cannot send body with %s" % self._status_code
self._clear_headers_for_304()
elif "Content-Length" not in self._headers:
content_length = sum(len(part) for part in self._write_buffer)
self.set_header("Content-Length", content_length)
if hasattr(self.request, "connection"):
# Now that the request is finished, clear the callback we
# set on the HTTPConnection (which would otherwise prevent the
# garbage collection of the RequestHandler when there
# are keepalive connections)
self.request.connection.set_close_callback(None)
self.flush(include_footers=True)
self.request.finish()
self._log()
self._finished = True
self.on_finish()
# Break up a reference cycle between this handler and the
# _ui_module closures to allow for faster GC on CPython.
self.ui = None
3.15、执行RequestHandler的flush方法
此处代码主要有一项任务:
- 将处理请求返回的数据发送到IOStream的_write_buffer队列中
def flush(self, include_footers=False):
"""Flushes the current output buffer to the network."""
if self.application._wsgi:
raise Exception("WSGI applications do not support flush()")
chunk = "".join(self._write_buffer)
self._write_buffer = []
if not self._headers_written:
self._headers_written = True
for transform in self._transforms:
self._headers, chunk = transform.transform_first_chunk(
self._headers, chunk, include_footers)
headers = self._generate_headers()
else:
for transform in self._transforms:
chunk = transform.transform_chunk(chunk, include_footers)
headers = ""
# Ignore the chunk and only write the headers for HEAD requests
if self.request.method == "HEAD":
if headers: self.request.write(headers)
return
if headers or chunk:
#执行HTTPReqeust的write方法
self.request.write(headers + chunk)
def write(self, chunk, callback=None): """Writes the given chunk to the response stream. .. deprecated:: 4.0 Use ``request.connection`` and the `.HTTPConnection` methods to write the response. """ assert isinstance(chunk, bytes) assert self.version.startswith("HTTP/1."), \ "deprecated interface only supported in HTTP/1.x" self.connection.write(chunk, callback=callback)
class IOStream(object): def write(self, data, callback=None): self._check_closed() #将数据保存到collections.deque()类型的双向队列中_write_buffer中 self._write_buffer.append(data) self._add_io_state(self.io_loop.WRITE) self._write_callback = stack_context.wrap(callback)
3.20、执行RequestHandler的_log方法
此处代码主要有一项任务:
- 记录操作日志(利用logging模块)
|
1
2
3
4
|
class RequestHandler: def _log(self): self.application.log_request(self)
|
class Application: def log_request(self, handler): if "log_function" in self.settings: self.settings["log_function"](handler) return if handler.get_status() < 400: log_method = logging.info elif handler.get_status() < 500: log_method = logging.warning else: log_method = logging.error request_time = 1000.0 * handler.request.request_time() log_method("%d %s %.2fms", handler.get_status(), handler._request_summary(), request_time)
3.21、IOStream的Handle_event方法
由于epoll中不但监听了服务器socket句柄还监听了客户端sokcet句柄,所以当客户端socket对象变化时,就会去调用之前指定的IOStream的_handler_events方法。
此段代码主要有一项任务:
- 将处理之后的响应数据发送给客户端
class IOStream(object):
def _handle_events(self, fd, events):
if not self.socket:
logging.warning("Got events for closed stream %d", fd)
return
try:
if events & self.io_loop.READ:
self._handle_read()
if not self.socket:
return
if events & self.io_loop.WRITE:
if self._connecting:
self._handle_connect()
#执行_handle_write方法,内部调用socket.send将数据响应给客户端
self._handle_write()
if not self.socket:
return
if events & self.io_loop.ERROR:
self.close()
return
state = self.io_loop.ERROR
if self.reading():
state |= self.io_loop.READ
if self.writing():
state |= self.io_loop.WRITE
if state != self._state:
self._state = state
self.io_loop.update_handler(self.socket.fileno(), self._state)
except:
logging.error("Uncaught exception, closing connection.",
exc_info=True)
self.close()
raise
3.22、IOStream的_handle_write方法
此段代码主要有两项任务:
- 调用socket.send给客户端发送响应数据
- 执行回调函数HTTPConnection的_on_write_complete方法
class IOStream(object):
def _handle_write(self):
while self._write_buffer:
try:
if not self._write_buffer_frozen:
_merge_prefix(self._write_buffer, 128 * 1024)
#调用客户端socket对象的send方法发送数据
num_bytes = self.socket.send(self._write_buffer[0])
self._write_buffer_frozen = False
_merge_prefix(self._write_buffer, num_bytes)
self._write_buffer.popleft()
except socket.error, e:
if e.args[0] in (errno.EWOULDBLOCK, errno.EAGAIN):
self._write_buffer_frozen = True
break
else:
logging.warning("Write error on %d: %s",
self.socket.fileno(), e)
self.close()
return
if not self._write_buffer and self._write_callback:
callback = self._write_callback
self._write_callback = None
#执行回调函数关闭客户端socket连接(HTTPConnection的_on_write_complete方法)
self._run_callback(callback)
class IOStream(object): def _run_callback(self, callback, *args, **kwargs): try: with stack_context.NullContext(): callback(*args, **kwargs) except: logging.error("Uncaught exception, closing connection.", exc_info=True) self.close() raise
注:IOStream的_run_callback方法内部调用了HTTPConnection的_on_write_complete方法
3.23、执行HTTPConnection的_on_write_complete方法
此处代码主要有一项任务:
- 更新客户端socket所在epoll中的状态为【READ】,以便之后执行3.24时关闭socket客户端。
class HTTPConnection(object):
def _on_write_complete(self):
if self._request_finished:
self._finish_request()
def _finish_request(self):
if self.no_keep_alive:
disconnect = True
else:
connection_header = self._request.headers.get("Connection")
if self._request.supports_http_1_1():
disconnect = connection_header == "close"
elif ("Content-Length" in self._request.headers
or self._request.method in ("HEAD", "GET")):
disconnect = connection_header != "Keep-Alive"
else:
disconnect = True
self._request = None
self._request_finished = False
if disconnect:
self.stream.close()
return
self.stream.read_until("\r\n\r\n", self._header_callback)
class IOStream(object): def read_until(self, delimiter, callback): """Call callback when we read the given delimiter.""" assert not self._read_callback, "Already reading" self._read_delimiter = delimiter self._read_callback = stack_context.wrap(callback) while True: # See if we've already got the data from a previous read if self._read_from_buffer(): return self._check_closed() if self._read_to_buffer() == 0: break #更新为READ self._add_io_state(self.io_loop.READ)
class IOStream(object): def _add_io_state(self, state): if self.socket is None: # connection has been closed, so there can be no future events return if not self._state & state: self._state = self._state | state #执行IOLoop对象的update_handler方法 self.io_loop.update_handler(self.socket.fileno(), self._state)
class IOLoop(object):
def update_handler(self, fd, events):
"""Changes the events we listen for fd."""
#self._impl就是epoll对象
self._impl.modify(fd, events | self.ERROR)
3.24、IOStream的_handle_write方法(含3.25、3.26)
此段代码主要有一项任务:
- 关闭客户端socket
class IOStream(object):
def _handle_events(self, fd, events):
if not self.socket:
logging.warning("Got events for closed stream %d", fd)
return
try:
#由于在 2.23 步骤中已经将epoll的状态更新为READ,所以这次会执行_handle_read方法
if events & self.io_loop.READ:
self._handle_read()
#执行完_handle_read后,客户端socket被关闭且置空,所有此处就会执行return
if not self.socket:
return
#===============================终止===========================
if events & self.io_loop.WRITE:
if self._connecting:
self._handle_connect()
self._handle_write()
if not self.socket:
return
if events & self.io_loop.ERROR:
self.close()
return
state = self.io_loop.ERROR
if self.reading():
state |= self.io_loop.READ
if self.writing():
state |= self.io_loop.WRITE
if state != self._state:
self._state = state
self.io_loop.update_handler(self.socket.fileno(), self._state)
except:
logging.error("Uncaught exception, closing connection.",
exc_info=True)
self.close()
raise
class IOStream(object): def _handle_read(self): while True: try: # Read from the socket until we get EWOULDBLOCK or equivalent. # SSL sockets do some internal buffering, and if the data is # sitting in the SSL object's buffer select() and friends # can't see it; the only way to find out if it's there is to # try to read it. result = self._read_to_buffer() except Exception: self.close() return if result == 0: break else: if self._read_from_buffer(): return
class IOStream(object): def _read_from_socket(self): """Attempts to read from the socket. Returns the data read or None if there is nothing to read. May be overridden in subclasses. """ try: chunk = self.socket.recv(self.read_chunk_size) except socket.error, e: if e.args[0] in (errno.EWOULDBLOCK, errno.EAGAIN): return None else: raise if not chunk: #执行close方法 self.close() return None return chunk
class IOStream(object): def close(self): """Close this stream.""" if self.socket is not None: #将客户端socket句柄在epoll中的移除,即:不再监听此客户端请求。 self.io_loop.remove_handler(self.socket.fileno()) #关闭客户端socket self.socket.close() #将socket置空 self.socket = None if self._close_callback: self._run_callback(self._close_callback)
class IOLoop(object): def remove_handler(self, fd): """Stop listening for events on fd.""" self._handlers.pop(fd, None) self._events.pop(fd, None) try: self._impl.unregister(fd) except (OSError, IOError): logging.debug("Error deleting fd from IOLoop", exc_info=True)
以上就是tornado源码针对请求的主要内容,另外,大家可能注意到我们返回给用户的只是一个简单的“hello world”,tornado返回复杂的内容时又需要使用模板语言
执行字符串表示的函数,并为该函数提供全局变量
# !usr/bin/env python
# coding:utf-8
from tornado.util import exec_in
namespace = {'name': 'liujianzuo', 'data': [18, 73, 84]}
code = '''def hellocute():return "name %s ,age %d" %(name,data[0],) '''
func = compile(code, '<string>', "exec")
# exec func in namespace # 2.7
exec_in(func,namespace) # tornado 封装的
print(namespace)
result = namespace['hellocute']()
print(result)
此段代码的执行结果是:name wupeiqi,age 18
上述代码解析:
- 第6行,code是一个字符串,该字符串的内容是一个函数体。
- 第8行,将code字符串编译成函数 hellocute
- 第10行,将函数 hello 添加到namespace字典中(key为hellocute),同时也将python的所有内置函数添加到namespace字段中(key为__builtins__),如此一来,namespace中的内容好比是一个个的全局变量,即
name = liujianzuo
data = [18,73,84]
def hellocute():
return "name %s ,age %d" %(name,data[0],)
- 第12行,执行Hellocute函数并将返回值复制给result
- 第14行,输入result
对于该功能,它就是python的web框架中模板语言部分至关重要的部分,因为在模板处理过程中,首先会读取html文件,然后分割html文件,再然后讲分割的文件组成一个字符串表示的函数,再再然后就是利用上述方法执行字符串表示的函数。
上图是返回给用户一个html文件的整个流程,较之前的Demo多了绿色流线的步骤,其实就是把【self.write('hello world')】变成了【self.render('main.html')】,对于所有的绿色流线只做了五件事:
- 使用内置的open函数读取Html文件中的内容
- 根据模板语言的标签分割Html文件的内容,例如:{{}} 或 {%%}
- 将分割后的部分数据块格式化成特殊的字符串(表达式)
- 通过python的内置函数执行字符串表达式,即:将html文件的内容和嵌套的数据整合
- 将数据返回给请求客户端
所以,如果要返回给客户端对于一个html文件来说,根据上述的5个阶段其内容的变化过程应该是这样:
class MainHandler(tornado.web.RequestHandler): def get(self): self.render("main.html",**{'data':['11','22','33'],'title':'main'}) [main.html] <!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8"> <title></title> </head> <body> <h1>{{title}}</h1> {% for item in data %} <h3>{{item}}</h3> {% end %} </body> </html>
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8"> <title></title> </head> <body> <h1>{{title}}</h1> {% for item in data %} <h3>{{item}}</h3> {% end %} </body> </html>
第1块:'<!DOCTYPE html><html><head lang="en"><meta charset="UTF-8"><title></title></head><h1>' 第2块:'title' 第3块:'</h1> \n\n' 第4块:'for item in data' 第4.1块:'\n <h3>' 第4.2块:'item' 第4.3块:'</h3> \n' 第五块:'</body>'
'def _execute(): _buffer = [] _buffer.append(\\'<!DOCTYPE html>\\n<html>\\n<head lang="en">\\n<meta charset="UTF-8">\\n<title></title>\\n</head>\\n<body>\\n<h1>\\') _tmp = title if isinstance(_tmp, str): _buffer.append(_tmp) elif isinstance(_tmp, unicode): _buffer.append(_tmp.encode(\\'utf-8\\')) else: _buffer.append(str(_tmp)) _buffer.append(\\'</h1>\\n\\') for item in data: _buffer.append(\\'\\n<h3>\\') _tmp = item if isinstance(_tmp, str): _buffer.append(_tmp) elif isinstance(_tmp, unicode): _buffer.append(_tmp.encode(\\'utf-8\\')) else: _buffer.append(str(_tmp)) _buffer.append(\\'</h3>\\n\\') _buffer.append(\\'\\n</body>\\n</html>\\') return \\'\\'.join(_buffer) '
a、全局变量有 title = 'main';data = ['11','22','33']
在第4步中,执行第3步生成的字符串表示的函数后得到的返回值就是要返回给客户端的响应信息主要内容。
3.13、RequestHandler的render方法
此段代码主要有三项任务:
- 获取Html文件内容并把数据(程序数据或框架自带数据)嵌套在内容中的指定标签中
- 执行ui_modules,再次在html中插入内容,例:head,js文件、js内容、css文件、css内容和body
- 内部调用客户端socket,将处理请求后的数据返回给请求客户端
class RequestHandler(object):
def render(self, template_name, **kwargs):
#根据Html文件名称获取文件内容并把参数kwargs嵌入到内容的指定标签内
html = self.render_string(template_name, **kwargs)
#执行ui_modules,再在html的内容中插入head,js文件、js内容、css文件、css内容和body信息。
js_embed = []
js_files = []
css_embed = []
css_files = []
html_heads = []
html_bodies = []
for module in getattr(self, "_active_modules", {}).itervalues():
embed_part = module.embedded_javascript()
if embed_part: js_embed.append(_utf8(embed_part))
file_part = module.javascript_files()
if file_part:
if isinstance(file_part, basestring):
js_files.append(file_part)
else:
js_files.extend(file_part)
embed_part = module.embedded_css()
if embed_part: css_embed.append(_utf8(embed_part))
file_part = module.css_files()
if file_part:
if isinstance(file_part, basestring):
css_files.append(file_part)
else:
css_files.extend(file_part)
head_part = module.html_head()
if head_part: html_heads.append(_utf8(head_part))
body_part = module.html_body()
if body_part: html_bodies.append(_utf8(body_part))
if js_files:#添加js文件
# Maintain order of JavaScript files given by modules
paths = []
unique_paths = set()
for path in js_files:
if not path.startswith("/") and not path.startswith("http:"):
path = self.static_url(path)
if path not in unique_paths:
paths.append(path)
unique_paths.add(path)
js = ''.join('<script src="' + escape.xhtml_escape(p) +
'" type="text/javascript"></script>'
for p in paths)
sloc = html.rindex('</body>')
html = html[:sloc] + js + '\n' + html[sloc:]
if js_embed:#添加js内容
js = '<script type="text/javascript">\n//<![CDATA[\n' + \
'\n'.join(js_embed) + '\n//]]>\n</script>'
sloc = html.rindex('</body>')
html = html[:sloc] + js + '\n' + html[sloc:]
if css_files:#添加css文件
paths = []
unique_paths = set()
for path in css_files:
if not path.startswith("/") and not path.startswith("http:"):
path = self.static_url(path)
if path not in unique_paths:
paths.append(path)
unique_paths.add(path)
css = ''.join('<link href="' + escape.xhtml_escape(p) + '" '
'type="text/css" rel="stylesheet"/>'
for p in paths)
hloc = html.index('</head>')
html = html[:hloc] + css + '\n' + html[hloc:]
if css_embed:#添加css内容
css = '<style type="text/css">\n' + '\n'.join(css_embed) + \
'\n</style>'
hloc = html.index('</head>')
html = html[:hloc] + css + '\n' + html[hloc:]
if html_heads:#添加html的header
hloc = html.index('</head>')
html = html[:hloc] + ''.join(html_heads) + '\n' + html[hloc:]
if html_bodies:#添加html的body
hloc = html.index('</body>')
html = html[:hloc] + ''.join(html_bodies) + '\n' + html[hloc:]
#把处理后的信息响应给客户端
self.finish(html)
对于上述三项任务,第一项是模板语言的重中之重,读取html文件并将数据嵌套到指定标签中,以下的步骤用于剖析整个过程(详情见下文);第二项是对返会给用户内容的补充,也就是在第一项处理完成之后,利用ui_modules再次在html中插入内容(head,js文件、js内容、css文件、css内容和body);第三项是通过socket将内容响应给客户端(见上篇)。
对于ui_modules,每一个ui_module其实就是一个类,一旦注册并激活了该ui_module,tornado便会自动执行其中的方法:embedded_javascript、javascript_files、embedded_css、css_files、html_head、html_body和render ,从而实现对html内容的补充。(执行过程见上述代码)
自定义UI Modules
此处是一个完整的 创建 --> 注册 --> 激活 的Demo
目录结构:
├── index.py
├── static
└── views
└── index.html
#!/usr/bin/env python # -*- coding:utf-8 -*- import tornado.ioloop import tornado.web class CustomModule(tornado.web.UIModule): def embedded_javascript(self): return 'embedded_javascript' def javascript_files(self): return 'javascript_files' def embedded_css(self): return 'embedded_css' def css_files(self): return 'css_files' def html_head(self): return 'html_head' def html_body(self): return 'html_body' def render(self): return 'render' class MainHandler(tornado.web.RequestHandler): def get(self): self.render('index.html') settings = { 'static_path': 'static', "template_path": 'views', "ui_modules": {'Foo': CustomModule}, } application = tornado.web.Application([(r"/", MainHandler), ], **settings) if __name__ == "__main__": application.listen(8888) tornado.ioloop.IOLoop.instance().start()
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8"> <title></title> </head> <body> <hr> {% module Foo() %} <hr> </body> </html>
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8"> <title></title> <!-- css_files --> <link href="/static/css_files" type="text/css" rel="stylesheet"> <!-- embedded_css --> <style type="text/css"> embedded_css </style> </head> <body> <!-- html_head --> html_head <hr> <!-- redner --> render <hr> <!-- javascript_files --> <script src="/static/javascript_files" type="text/javascript"></script> <!-- embedded_javascript --> <script type="text/javascript"> //<![CDATA[ embedded_javascript //]]> </script> <!-- html_body --> html_body </body> </html>
3.13.1~6、RequestHandler的render_string方法
该方法是模板的重中之重,它负责去处理Html模板并返回最终结果,【上面概述】中提到的5件事中前四件都是此方法来完成的,即:
- 创建Loader对象,并执行load方法
-- 通过open函数打开html文件并读取内容,并将内容作为参数又创建一个 Template 对象
-- 当执行Template的 __init__ 方法时,根据模板语言的标签 {{}}、{%%}等分割并html文件,最后生成一个字符串表示的函数 - 获取所有要嵌入到html模板中的变量,包括:用户返回和框架默认
- 执行Template对象的generate方法
-- 编译字符串表示的函数,并将用户定义的值和框架默认的值作为全局变量
-- 执行被编译的函数获取被嵌套了数据的内容,然后将内容返回(用于响应给请求客户端)
注意:详细编译和执行Demo请参见上面
class RequestHandler(object):
def render_string(self, template_name, **kwargs):
#获取配置文件中指定的模板文件夹路径,即:template_path = 'views'
template_path = self.get_template_path()
#如果没有配置模板文件的路径,则默认去启动程序所在的目录去找
if not template_path:
frame = sys._getframe(0)
web_file = frame.f_code.co_filename
while frame.f_code.co_filename == web_file:
frame = frame.f_back
template_path = os.path.dirname(frame.f_code.co_filename)
if not getattr(RequestHandler, "_templates", None):
RequestHandler._templates = {}
#创建Loader对象,第一次创建后,会将该值保存在RequestHandler的静态字段_template_loaders中
if template_path not in RequestHandler._templates:
loader = self.application.settings.get("template_loader") or\
template.Loader(template_path)
RequestHandler._templates[template_path] = loader
#执行Loader对象的load方法,该方法内部执行执行Loader的_create_template方法
#在_create_template方法内部使用open方法会打开html文件并读取html的内容,然后将其作为参数来创建一个Template对象
#Template的构造方法被执行时,内部解析html文件的内容,并根据内部的 {{}} {%%}标签对内容进行分割,最后生成一个字符串类表示的函数并保存在self.code字段中
t = RequestHandler._templates[template_path].load(template_name)
#获取所有要嵌入到html中的值和框架默认提供的值
args = dict(
handler=self,
request=self.request,
current_user=self.current_user,
locale=self.locale,
_=self.locale.translate,
static_url=self.static_url,
xsrf_form_html=self.xsrf_form_html,
reverse_url=self.application.reverse_url
)
args.update(self.ui)
args.update(kwargs)
#执行Template的generate方法,编译字符串表示的函数并将namespace中的所有key,value设置成全局变量,然后执行该函数。从而将值嵌套进html并返回。
return t.generate(**args)
class Loader(object): """A template loader that loads from a single root directory. You must use a template loader to use template constructs like {% extends %} and {% include %}. Loader caches all templates after they are loaded the first time. """ def __init__(self, root_directory): self.root = os.path.abspath(root_directory) self.templates = {}
def load(self, name, parent_path=None): """Loads a template.""" name = self.resolve_path(name, parent_path=parent_path) with self.lock: if name not in self.templates: self.templates[name] = self._create_template(name) return self.templates[name]
def _create_template(self, name): path = os.path.join(self.root, name) with open(path, "rb") as f: template = Template(f.read(), name=name, loader=self) return template
class Template(object): def __init__(self, template_string, name="<string>", loader=None,compress_whitespace=None): # template_string是Html文件的内容 self.name = name if compress_whitespace is None: compress_whitespace = name.endswith(".html") or name.endswith(".js") #将内容封装到_TemplateReader对象中,用于之后根据模板语言的标签分割html文件 reader = _TemplateReader(name, template_string) #分割html文件成为一个一个的对象 #执行_parse方法,将html文件分割成_ChunkList对象 self.file = _File(_parse(reader)) #将html内容格式化成字符串表示的函数 self.code = self._generate_python(loader, compress_whitespace) try: #将字符串表示的函数编译成函数 self.compiled = compile(self.code, self.name, "exec") except: formatted_code = _format_code(self.code).rstrip() logging.error("%s code:\n%s", self.name, formatted_code) raise
class Template(object): def generate(self, **kwargs): """Generate this template with the given arguments.""" namespace = { "escape": escape.xhtml_escape, "xhtml_escape": escape.xhtml_escape, "url_escape": escape.url_escape, "json_encode": escape.json_encode, "squeeze": escape.squeeze, "linkify": escape.linkify, "datetime": datetime, } #创建变量环境并执行函数,详细Demo见上一篇博文 namespace.update(kwargs) exec self.compiled in namespace execute = namespace["_execute"] try: #执行编译好的字符串格式的函数,获取嵌套了值的html文件 return execute() except: formatted_code = _format_code(self.code).rstrip() logging.error("%s code:\n%s", self.name, formatted_code) raise
其中涉及的类有:
class _TemplateReader(object): def __init__(self, name, text): self.name = name self.text = text self.line = 0 self.pos = 0 def find(self, needle, start=0, end=None): assert start >= 0, start pos = self.pos start += pos if end is None: index = self.text.find(needle, start) else: end += pos assert end >= start index = self.text.find(needle, start, end) if index != -1: index -= pos return index def consume(self, count=None): if count is None: count = len(self.text) - self.pos newpos = self.pos + count self.line += self.text.count("\n", self.pos, newpos) s = self.text[self.pos:newpos] self.pos = newpos return s def remaining(self): return len(self.text) - self.pos def __len__(self): return self.remaining() def __getitem__(self, key): if type(key) is slice: size = len(self) start, stop, step = key.indices(size) if start is None: start = self.pos else: start += self.pos if stop is not None: stop += self.pos return self.text[slice(start, stop, step)] elif key < 0: return self.text[key] else: return self.text[self.pos + key] def __str__(self): return self.text[self.pos:]
class _ChunkList(_Node): def __init__(self, chunks): self.chunks = chunks def generate(self, writer): for chunk in self.chunks: chunk.generate(writer) def each_child(self): return self.chunks
def _parse(reader, in_block=None): #默认创建一个内容为空列表的_ChunkList对象 body = _ChunkList([]) # 将html块添加到 body.chunks 列表中 while True: # Find next template directive curly = 0 while True: curly = reader.find("{", curly) if curly == -1 or curly + 1 == reader.remaining(): # EOF if in_block: raise ParseError("Missing {%% end %%} block for %s" %in_block) body.chunks.append(_Text(reader.consume())) return body # If the first curly brace is not the start of a special token, # start searching from the character after it if reader[curly + 1] not in ("{", "%"): curly += 1 continue # When there are more than 2 curlies in a row, use the # innermost ones. This is useful when generating languages # like latex where curlies are also meaningful if (curly + 2 < reader.remaining() and reader[curly + 1] == '{' and reader[curly + 2] == '{'): curly += 1 continue break # Append any text before the special token if curly > 0: body.chunks.append(_Text(reader.consume(curly))) start_brace = reader.consume(2) line = reader.line # Expression if start_brace == "{{": end = reader.find("}}") if end == -1 or reader.find("\n", 0, end) != -1: raise ParseError("Missing end expression }} on line %d" % line) contents = reader.consume(end).strip() reader.consume(2) if not contents: raise ParseError("Empty expression on line %d" % line) body.chunks.append(_Expression(contents)) continue # Block assert start_brace == "{%", start_brace end = reader.find("%}") if end == -1 or reader.find("\n", 0, end) != -1: raise ParseError("Missing end block %%} on line %d" % line) contents = reader.consume(end).strip() reader.consume(2) if not contents: raise ParseError("Empty block tag ({%% %%}) on line %d" % line) operator, space, suffix = contents.partition(" ") suffix = suffix.strip() # Intermediate ("else", "elif", etc) blocks intermediate_blocks = { "else": set(["if", "for", "while"]), "elif": set(["if"]), "except": set(["try"]), "finally": set(["try"]), } allowed_parents = intermediate_blocks.get(operator) if allowed_parents is not None: if not in_block: raise ParseError("%s outside %s block" % (operator, allowed_parents)) if in_block not in allowed_parents: raise ParseError("%s block cannot be attached to %s block" % (operator, in_block)) body.chunks.append(_IntermediateControlBlock(contents)) continue # End tag elif operator == "end": if not in_block: raise ParseError("Extra {%% end %%} block on line %d" % line) return body elif operator in ("extends", "include", "set", "import", "from", "comment"): if operator == "comment": continue if operator == "extends": suffix = suffix.strip('"').strip("'") if not suffix: raise ParseError("extends missing file path on line %d" % line) block = _ExtendsBlock(suffix) elif operator in ("import", "from"): if not suffix: raise ParseError("import missing statement on line %d" % line) block = _Statement(contents) elif operator == "include": suffix = suffix.strip('"').strip("'") if not suffix: raise ParseError("include missing file path on line %d" % line) block = _IncludeBlock(suffix, reader) elif operator == "set": if not suffix: raise ParseError("set missing statement on line %d" % line) block = _Statement(suffix) body.chunks.append(block) continue elif operator in ("apply", "block", "try", "if", "for", "while"): # parse inner body recursively block_body = _parse(reader, operator) if operator == "apply": if not suffix: raise ParseError("apply missing method name on line %d" % line) block = _ApplyBlock(suffix, block_body) elif operator == "block": if not suffix: raise ParseError("block missing name on line %d" % line) block = _NamedBlock(suffix, block_body) else: block = _ControlBlock(contents, block_body) body.chunks.append(block) continue else: raise ParseError("unknown operator: %r" % operator)
class Template(object): def _generate_python(self, loader, compress_whitespace): buffer = cStringIO.StringIO() try: named_blocks = {} ancestors = self._get_ancestors(loader) ancestors.reverse() for ancestor in ancestors: ancestor.find_named_blocks(loader, named_blocks) self.file.find_named_blocks(loader, named_blocks) writer = _CodeWriter(buffer, named_blocks, loader, self, compress_whitespace) ancestors[0].generate(writer) return buffer.getvalue() finally: buffer.close()
so,上述整个过程其实就是将一个html转换成一个函数,并为该函数提供全局变量,然后执行该函数!!


上述就是对于模板语言的整个流程,其本质就是处理html文件内容将html文件内容转换成函数,然后为该函数提供全局变量环境(即:我们想要嵌套进html中的值和框架自带的值),再之后执行该函数从而获取到处理后的结果,再再之后则执行UI_Modules继续丰富返回结果,例如:添加js文件、添加js内容块、添加css文件、添加css内容块、在body内容第一行插入数据、在body内容最后一样插入数据,最终,通过soekct客户端对象将处理之后的返回结果(字符串)响应给请求用户。
