

开源分布式计算引擎 & 开源搜索引擎 Iveely 0.5.0 为大数据而生
Iveely Computing
产生背景
08年的时候,我开始接触搜索引擎,当时遇到的第一个难题就是大数据实时并发处理,当时实验室的机器我们可以随便用,至少二三十台机器,可以,却没有程序可以将这些机器的计算性能整合起来,后来听说了Hadoop,但是当时的hadoop还很脆弱(记得没错是0.2.0),源码量也很少,用了很久,发现它不适合我们的搜索引擎。
后来没办法,我在程序中将爬虫和数据处理写成分布式网络通信的。但是导致代码非常臃肿,而且每一个应用程序的运行,都需要写一套网络通信和任务分布。09年下半年,中某地区断网半年,只能访问该地区本地的网络,然后想到我们搜索引擎的商业运营的机会来了,当时用了大约10台机器(实验室超低配置机器,内存512M,单核),可是访问量大了之后,系统直接崩溃,调试和运营都遇到巨大的挑战。后来我不断的重构搜索引擎,发现怎么做都很困难。
于是,我一直在思考,我们需要一个平台或者叫计算引擎,让程序员写的程序,这些程序浑然天成的支持分布式计算,这还不够,还希望能够实时返回计算结果,而程序员却不知道有多少台机器在为运行它的程序。
这就是我构思的分布式计算引擎,而今天,它已经实现,尽管不完美。它是我承诺的Iveely Search Engine 0.5.0 的分布式搜索引擎的基础,它的名字叫Iveely Computing,一款开源分布式计算引擎,为大数据实时处理而生(Iveely是“I void everything,except love you!”的首字母简写)。开源主页、源码下载:https://github.com/Fanping/iveely/releases。最初我们命名的开发代号叫:Dream,Dream平台曾经在新华网出现过,早期版本的数据分析。
基本结构
整个Iveely Computing的基础库是Iveely Framework,Iveely Framework基础结构如下图所示:
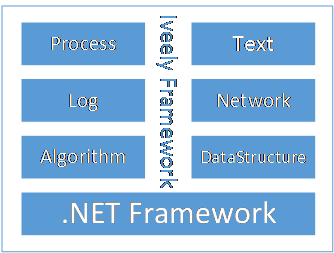
主要是在进程,文本处理、日志、网络、算法和数据结构上,进行了二次封装,整个底层框架依然是.NET Framework。Iveely Framework与Iveely Computing是两个project,但是Computing对Framework会有依赖。Iveely Computing基础结构如下图所示:
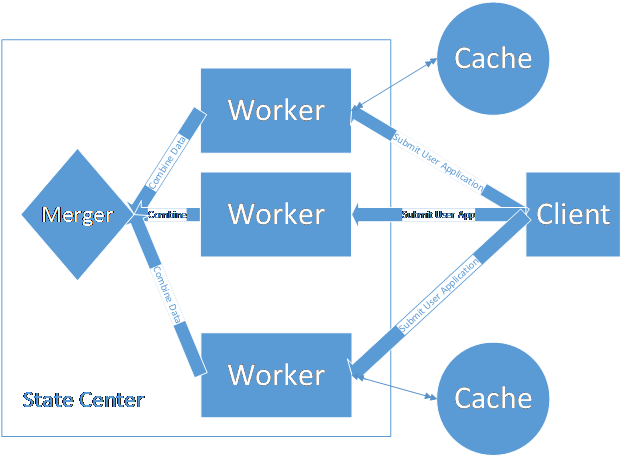
整个过程涉及6个主要exe文件,每个exe都是Iveely Computing中非常重要的一环。
Iveely.CloudComputing.Cacher.exe:分布式缓存。用于分布式存放小数据。采用一致性hash算法。
Iveely.CloudComputing.Merger.exe:全局运算器。在分布式计算中,常常会涉及到全局运算,每一个节点都在计算,那么当遇到全局求和、求平均等等之类的时候,就需要Merger来操作。
Iveely.CloudComputing.StateCenter.exe:状态控制中心。用于当前所有worker、Merger的控制运算中心。
Iveely.CloudComputing.Worker.exe:用户任务的真正执行者。
Iveely.CloudComputing.Supervisor.exe:用于监控Worker的执行情况,倘若Worker异常中断,则自动重启worker。
Iveely.CloudComputing.Client.exe:用户的控制台操作程序,用户提交程序,查看自己应用程序的运行状态。
编译部署
我在微软一年多,离开的时候才发现,学到最多的不是程序、不是架构,而是用户体验,总结一句话:你的程序,不要消极用户心情。所以我在部署的时候,依然采用了“一键式本地部署”。在开源社区,这是很多开源人需要学习微软的一点,很多开源程序,搭建编译部署步骤非常繁琐,很容易消极使用者心情。
编译
编译之前,请先在开源主页上下载0.5.0源码。无须下载其它任何第三方软件,你所下载的源码,将会是Iveely Computing中任何dll的源码。下载后解压,直接用Visual Studio 2012以上版本打开整个解决方案(Iveely.sln),打开之后,你平时怎么编译,现在就怎么编译。为了更好的在开发中尽可能测试到Iveely Computing,Debug Build和Release Build有一定区别:
Debug Build:解决方案中,所有代码均会被编译,包括测试代码,编译后生成的文件在..\ Iveely\Iveely.CloudComputing\Debug。
Release Build:解决方案中,只有被使用到的代码会被编译,编译后生成的文件在..\Iveely\Iveely.CloudComputing\Release。
本地部署
在本地,一键式部署,只需要在你编译生成的文件加下找到“Deploy-Local-Environment.bat”双击,整个本地环境将会全部搭建完毕。“Deploy-Local-Environment.bat”文件中的批处理内容如下:
start "StateCenter" Iveely.CloudComputing.StateCenter.exe
start "Supervisor" Iveely.CloudComputing.Supervisor.exe
start "Worker:8001" Iveely.CloudComputing.Worker.exe 8001
start "Worker:8002" Iveely.CloudComputing.Worker.exe 8002
start "Merger" Iveely.CloudComputing.Merger.exe
start "Cacher" Iveely.CloudComputing.Cacher.exe
其实就是启动应用程序的命令,Worker的数量可根据自己机器的性能进行调整。当然也有相应的关闭的批处理文件,也是在编程生成的文件夹下“Stop-Local-Environment.bat”,文件中的批处理内容如下:
@taskkill /fi "WINDOWTITLE eq StateCenter"
@taskkill /fi "WINDOWTITLE eq Supervisor"
@taskkill /fi "WINDOWTITLE eq Worker:8001"
@taskkill /fi "WINDOWTITLE eq Worker:8002"
@taskkill /fi "WINDOWTITLE eq Merger"
@taskkill /fi "WINDOWTITLE eq Cacher"
当在启动的时候,如果Worker的数量自己有调整,请记得在“Stop-Local-Environment.bat”文件中也做相应调整。
集群部署
在实际应用当中,更多的是集群部署整个Iveely Computing。不管如何部署,请把编译后的文件夹“..\Iveely\Iveely.CloudComputing\Release”拷贝到你的目标机器上。Merger和StateCenter请拷贝到性能较好的机器中去,并首先双击运行。Worker根据任务的多少去部署,一般100G的数据,部署在4台内存4G、CPUi5双核的机器上就很容易处理,每台机器启动两个worker。Cache根据项目缓存是否经常用到,如果经常用到,建议多放在几台之中,如果整个过程你认为你不会用到缓存,至少请部署一台,但是缓存适合非常高效的小数据交换。建议整个过程中,多用缓存,少用Merge。
编写自己分布式程序
编写您的应用程序之前,您必须了解,Iveely Computing有哪些指令Client.exe支持直接Main函数传递方式和普通命令行方式,二者效果一致。命令行指令格式如下:
1) submit[file path][namespace.classname][app name]
提交应用程序指令。[file path]是指应用程序的脚本路径;[namespace.classname]是指代码脚本中,执行的命名空间和类名;[app name]是这个应用程序的名称。例如:
Submit C:\\Example.cs MyNameSpace.ClassName ExampleApp
2) split[file path][remote path][split string] [partition keys]
切分本地大数据文件到各个节点指令。[file path]是本地大文件的路径;[remote path]是结点里面的路径。例如:
Split C:\\BigData.txt /Data/big.txt
[split string]与[partition keys]属于可选项,当没有此参数时,partition按照大小平均分配,如果有这两个参数,则按照partition key进行分配,有可能数据不均匀。例如:
Split C:\\BigData.txt /Data/big.txt , 2 3
含义是切分本地文件C:\\BigData.txt到远程服务器结点,命名为/Data/big.txt 切分符号为“,”,按照第二列和第三列进行partition。
3) download[remote path][file path]
下载各个节点的数据到本地指令。[remote path]是节点中的数据路径;[file path]是本地存储的路径。例如:
Download /Data/big.txt C:\\BigData.txt
4) delete[remote path]
删除某个数据指令。删除操作将会在整个系统的每一个节点中删除,[remote path]是节点中数据的路径。例如:
Delete /Data/big.txt
5) rename[file path][new file Name]
重命名操作指令。[file path]是在远程节点中的文件路径名称。[new file Name]重新命名的名字。例如:
Rename /Data/big.txt newbig.txt
更改后的实际文件名:/Data/newbig.txt。
6) list[/folder]
显示文件目录指令。[/folder]是指目录路径,默认是根目录。例如:
7) kill [task name]
用于停止正在运行的程序。
8) task
显示所有正在运行的程序。
9) exit
退出指令。
现在开始你的编程之旅,方法及其简单,新建你的C#应用程序,并且添加Iveely.CloudComputing.Client引用如下图
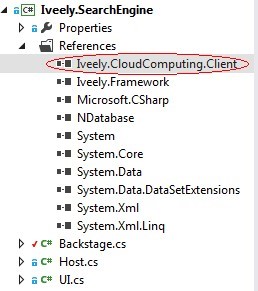
Iveely.Framework和NDatabase也是允许添加的,其它非.NET引用添加将会导致错误。在你的C#工程中,添加一个类,继承类Application,并实现该类的方法Run。this.Init(args)方法需要显示添加。
在这之下,你可以按照您以前的思维编写任意的程序了,写完之后,按照下面的方法提交:
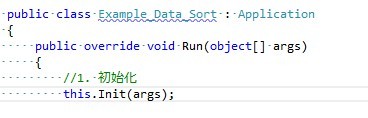
1. 双击Iveely.CloudComputing.Client.exe。
2. 按照submit命令提交您的程序。
实践示例
词频统计(Word Count)应该是所有分布式计算中的“Hello World”程序,不管是Hadoop,还是Storm都是采用“Word Count”为大家打开初步认识。Iveely Computing依然采用“Word Count”作为初级入门应用。
按照常用的逻辑思维,我们会考虑用一个哈希表来存放,如果插入的单词存在,则+1,如果不存在则放入哈希表,次数为1。在Iveely Computing中也是采用这样的方法进行计算。


1 public override void Run(object[] args) 2 { 3 //0.先初始化 4 this.Init(args); 5 6 //1.虚拟数据构建 7 string[] contents = 8 { 9 "This is Iveely Computing", 10 "Weclome here", 11 "Iveely is I void every thing,except love", 12 "Thanks,Iveely Team." 13 }; 14 StringBuilder dataBuilder = new StringBuilder(); 15 for (int i = 0; i < 1000; i++) 16 { 17 Random random = new Random(i); 18 int index = random.Next(0, 4); 19 dataBuilder.AppendLine(contents[index]); 20 } 21 22 string[] words = dataBuilder.ToString().Split(new[] { ' ', ',', '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries); 23 WriteToConsole("local words count:" + words.Length); 24 int globalWordCount = Mathematics.Sum<int>(words.Length); 25 WriteToConsole("global words count:" + globalWordCount); 26 27 //2.子节点处理数据 28 Hashtable table = new Hashtable(); 29 foreach (string word in words) 30 { 31 if (table.ContainsKey(word)) 32 { 33 table[word] = int.Parse(table[word].ToString()) + 1; 34 } 35 else 36 { 37 table.Add(word, 1); 38 } 39 } 40 41 //3.归并所有结点处理结果 42 WriteToConsole("local word frequency count:" + table.Keys.Count); 43 table = Mathematics.CombineTable(table); 44 WriteToConsole("global word frequency count:" + table.Keys.Count); 45 46 //4.写入文件 47 StringBuilder builder = new StringBuilder(); 48 foreach (DictionaryEntry dictionaryEntry in table) 49 { 50 builder.AppendLine(dictionaryEntry.Key + " " + dictionaryEntry.Value); 51 } 52 WriteText(builder.ToString(), "WordCount.result", true); 53 }
这就是Iveely Computing中实际用到的代码,唯一不同的地方在于最后一行代码Mathematics.CombineTable(table),其实也就是开发需要清楚的知道,某些代码是本地运行代码,某些代码是全局运行代码。如果不执行Mathematic.CombineTable(table),则table将是本地运行的结果,而非全局运行的结果,结果理所当然是错误的。在此,再次说明,如果本地代码运行完毕,需要生成全局数据,则需要调用Mathematic里面的方法,生成全局数据,调用完后的数据如果需要写到文件,则记得global=true。反之,global=false。示例源码请参见源码包中的Example_WordCount.cs文件。演示视频下载[8M]。
Iveely Search Engine 0.5.0
如果您觉得WordCount的示例,不足以为您证明Iveely Computing强大的能力,那么下面一个希望您能够喜欢-迟来的Iveely Search Engine 0.5.0。Iveely SE沉寂了大半年,很多社区朋友,问我是否停止了Iveely SE前进的步伐,我说没有,沉寂是为了更大一步的跨越。在0.4.0的时候,我说IveelySE的0.5.0版本要实现分布式。今天它结合Iveely Computing一起诞生了。源码在这里下载。
IveelySE 0.5.0的代码量不足800行,也许你觉得吃惊,但这正是Iveely Computing的魅力。先看下运行截图。
Iveely SE 0.5.0在0.4.0上的至少有下列三大突破:
1. 强大的分布式计算引擎的支持,即Iveely Computing的支持。将0.4.0的独立应用程序变成了分布式应用。将Iveely Computing中的分布式缓存、存储、计算引入,使得0.5.0的计算性能获得超越。基于Iveely Computing也使得容灾处理变得自动化,而无须人工干涉。
2. 插件式功能扩展,模块更加独立。在0.4.0中,若为搜索引擎添加了新的功能,则需要停止0.4.0然后重新启动。在0.5.0中,添加的新功能将不会影响以前的功能正常运行,只需将新的功能写成基于Iveely Computing的应用程序,随时监控该功能的运行情况,也可随时中止。
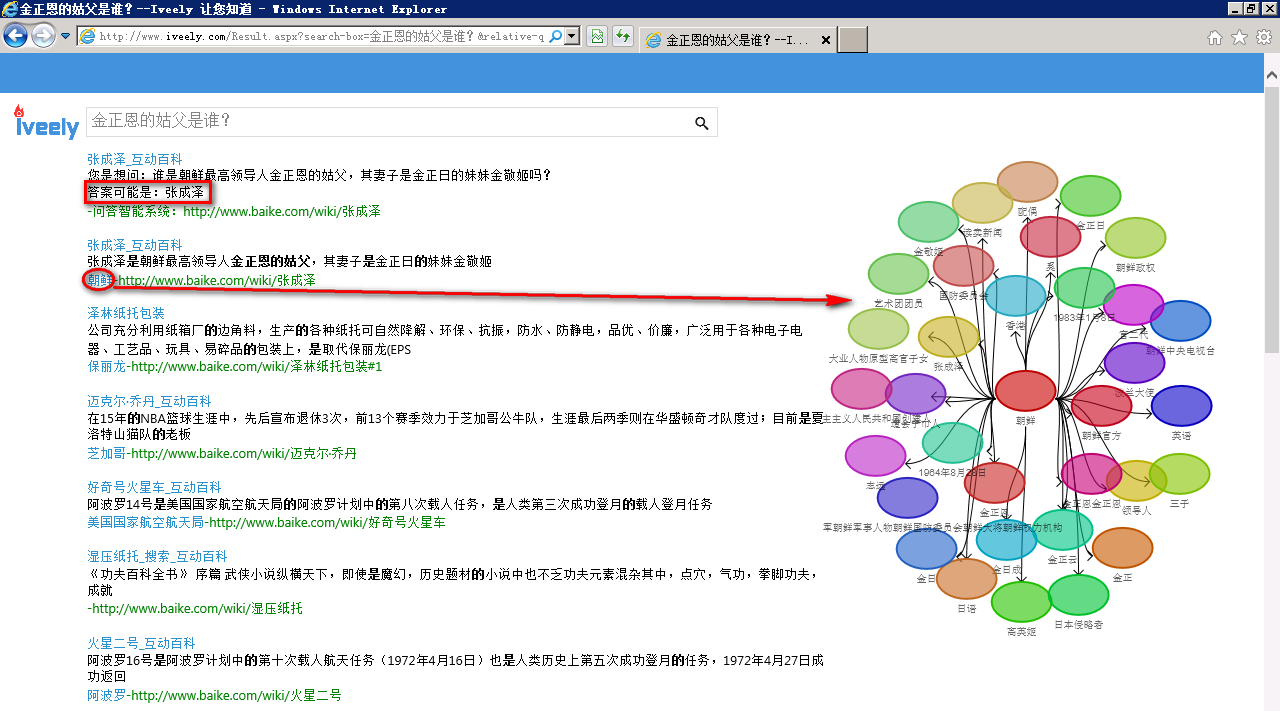
3. 支持问题式搜索、关联性搜索。问题式搜索是指,例如搜索“金正恩的姑父是谁?”的时候,答案直接能够给出“张成泽”,下列截图中的第一条记录及时问题式搜索结构[更多这样的示例,参见我的微博]。关联性搜索,是指给出一个事或物,能够直接给出与它相关联的事物。下图中的右边关系图即是。
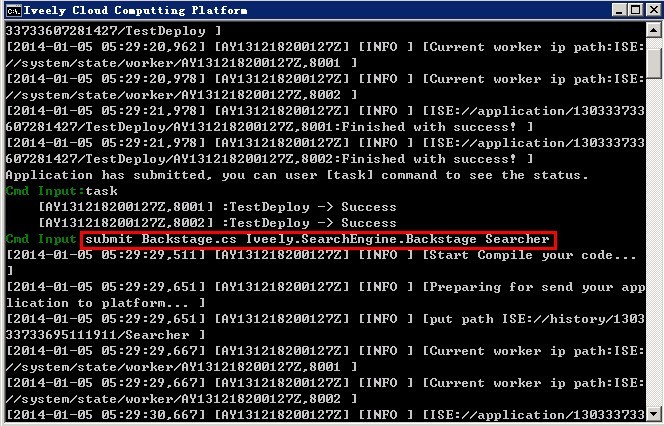
Iveely SE 0.5.0是基于Iveely Computing上运行起来的,因此在Iveely Computing环境搭建完毕之后,需要通过Iveely.CloudComputing.Client.exe提交搜索程序:submit Backstage.cs Iveely.SearchEngine.Backstage Searcher。如下图所示:
然后通过task指令,查看运行状态,可以看到当前有两个结点正在运行,这就表示搜索引擎已经在两个结点运行起来。搜索页面需要自己定制,在Iveely.SearchEngine中有一个Library类,可以直接调用。若您采用其它编程语言,可以调用Query.asmx这个Web Service。这样很简单的就把搜索引擎搭建好了。搜索效果如前面两图所示。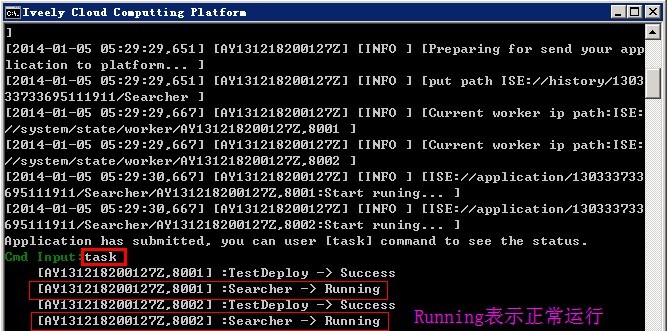
捐助我们
也许您会很奇怪,为何需要捐助,我们需要服务器。数据量越来越大,我们自身的服务器已经不能继续支撑我们的服务器,我们渴望将Iveely.com运行起来,可是硬件限制了我们。因此,我们恳请若您想在硬件上捐助我们,可以捐助服务器[这里捐助]或者支付宝资助[这里资助],我们将心存感激。我们正如wiki一样,让每个人平等自由的获得知识,我们将继续致力于开源事业,倘若达到一定条件,我们将会让Iveely.com正式运行起来。
结 语
世界变化很快,在我们这个浮躁的世界,我们希望自己能坚持理想,总有一天,我们都会逝去,不管是在过去,还是当前,甚至未来,我们需要的不仅仅的是生活的物质基础,我们还需要生活的快乐,而最快乐的,莫过于为理想而奋斗。

