(转载)微软数据挖掘算法:Microsoft 时序算法之结果预测及其彩票预测(6)
前言
本篇我们将总结的算法为Microsoft时序算法的结果预测值,是上一篇文章微软数据挖掘算法:Microsoft 时序算法(5)的一个总结,上一篇我们已经基于微软案例数据库的销售历史信息表,利用Microsoft时序算法对其结果进行了预测,并且相应形成了折线预测图和模型依赖属性,有兴趣的同学可以点击查看,但是上篇文章的能给出的只是一个描述趋势的折线图,从图中我们能分析出的知识也只能通过语言描述,而这里面缺少更确切的数据支撑,作为一个凡事以数据说话的年代显然这是不够的,本篇我们将根据上一篇的预测过程详细的给出预测结果值,形成一份可供具体参考的数据明细表。
应用场景介绍
作为Microsoft时序算法的应用场景,在上一篇我们已经详细介绍了,本篇就不再赘述,总结一下就是凡事要应用时间总线为依据,根据以往历史事例记录推测以后将要发生的结果值,此种场景我们都会应用到时序算法。
比如:预测销售记录、预测营业额度、预测明年公司员工人数、预测下个月房价、预测明年.....
但其实凡此种种我们要挖掘的其实是一种规律,一种事态进展中的导向,而这些可能不基于数据仅凭经验值是做不到的或者说不准确的,凡事有因必有果,很多事情冥冥中已经注定,汗...有点佛家寓言的味道!时序算法更重要的是展现这注定的过程,然后推算出将要发生的结果。对于本来的事例就无规律可循,这种事情是用Microsoft时序算法无法预测的,或者预测结果是不准的,比如:大师,您帮我算算我下期彩票买什么号能中一等奖???我那个去!....汗......也能算..只是不准!...
技术准备
(1)参照上一篇文章,我们利用微软提供的案例数据仓库(AdventureWorksDW2008R2),这这里我们只需要用到一张表,确切的说是一张视图vTimeSeries,其实这里面就是记录的往年不同月份的销售汇总值,稍后我们将详细分析这部分数据。
(2)VS2008、SQL Server、 Analysis Services
操作步骤
(1)这里我们应用上期中时序算法的解决方案,我们打开:

这里上篇文章我们已经分析的很详细,有兴趣的童鞋可以参照上一篇文章,到此我们来可以验证下该模型的准确度怎么样,我们来查看“挖掘准确性图表”
 可以看到此处为灰色显示,也就是说对于Microsoft时序算法模型,准确度模型是没法预测的,这也是在Microsoft所有的挖掘算法中唯一一个不能利用准确度性图表进行验证的,原因很简单:事情还没发生,你验证个P...
可以看到此处为灰色显示,也就是说对于Microsoft时序算法模型,准确度模型是没法预测的,这也是在Microsoft所有的挖掘算法中唯一一个不能利用准确度性图表进行验证的,原因很简单:事情还没发生,你验证个P...
以往的挖掘模型可以通过历史遗留的部分事例进行验证模型的准确度,而时序算法不行,因为你的时间维度还没演变到此,所有的所有的都还未发生,没法验证。当然我们可以采用交叉验证根据以往的事例来验证当前时间以前发生的事是否准确。咱们后期进行....
(2)基于现有Microsoft时序算法来推测未来发生结果值
这个步骤没啥复杂的,就是根据上篇我们的时序挖掘模型来推测出未来将要产生的销售额和销售量,我们会推测出详细的结果值表
我们进入“挖掘模型预测”面板
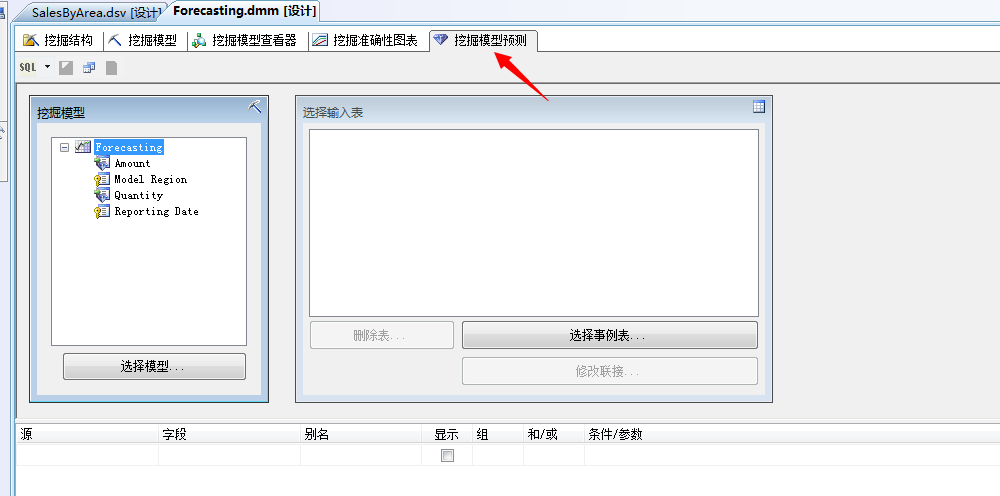
我们选择源为“预测函数”,将Amount、Quantity两个预测值拖到条件/参数窗口,然后输入预测步骤为5,并且将主键列加入或者我们直接填写查询语句:
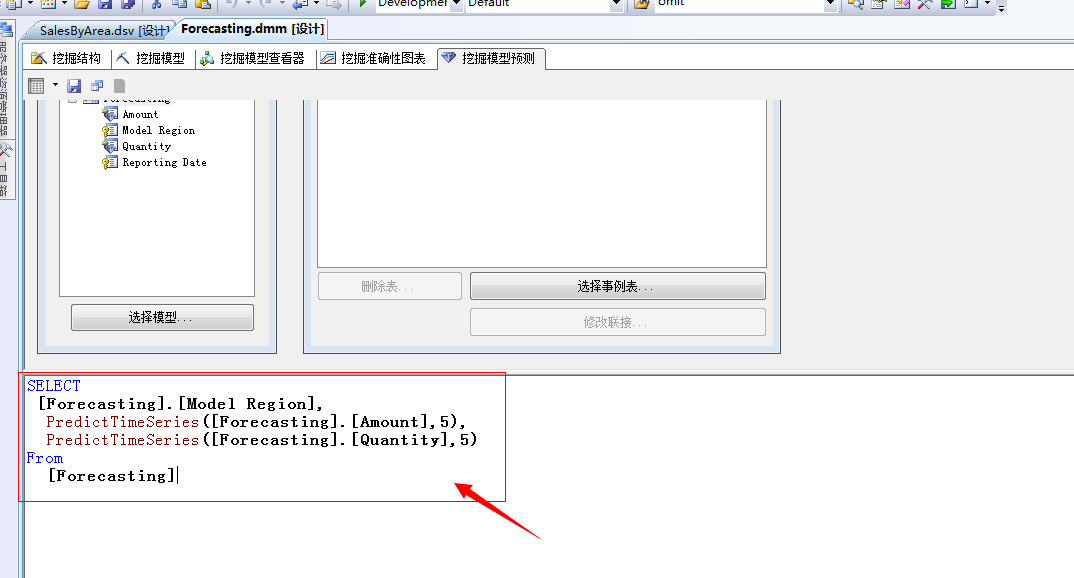
点击运行按钮,我们来查看结果:
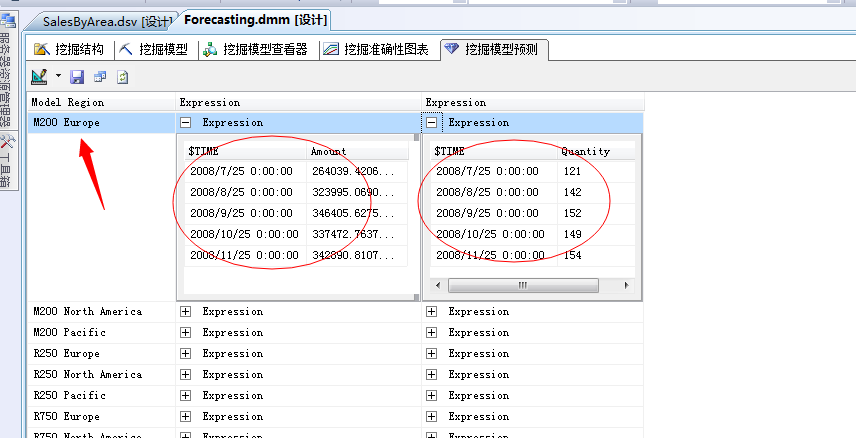
结果出现了,M200这款自行车在欧洲在2008年的销售额和销售量我们已经确切的预测出来了,因为我们只是预测了5个月,其它时间段的也可以推测出,当然其它的产品可以查看,此处我们就不展开了,剩下的工作我们将它们保存到数据库:
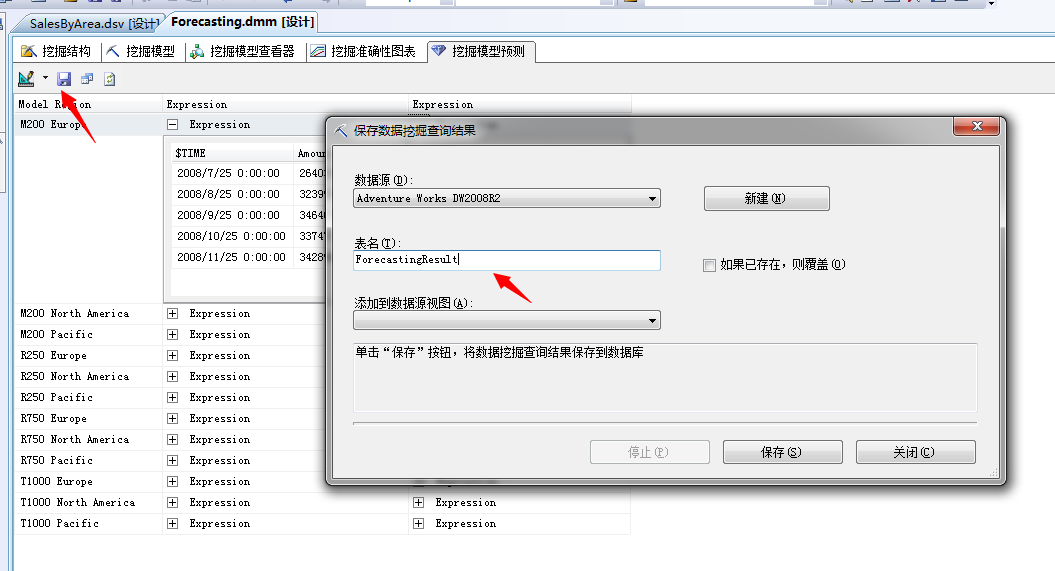
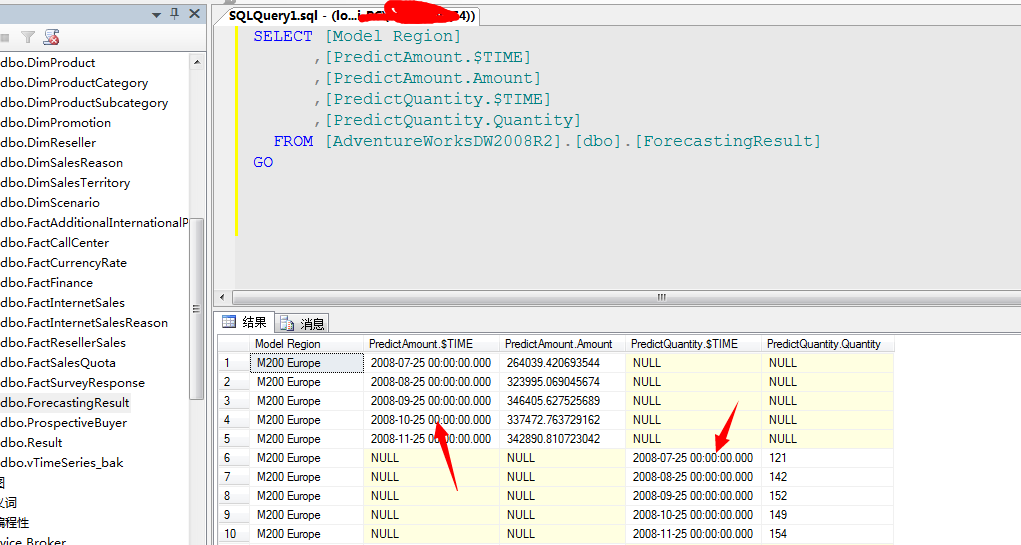
我们来查看数据库明细:
嘿嘿...剩下的事情就是拿着这份数据去找BOSS了....然后...就然后了......
-------------------------------------------------------霸气的分割线------------------------------------------------------------------
到此貌似本篇文章也应该结束了,但是我估计到此结束会有很多朋友骂我是标题党,你丫的不是说要玩彩票预测嘛,丫不是说时序算法可以预测未来的事情嘛....咋认怂了呢....
上面的应用场景中也提到了此问题...鉴于此,我怀揣着成为“大湿”的梦想,小心翼翼的打开了百度,然后输入了:彩票,希望从中找到点数据来瞅瞅:
看到了这霸气的百度乐彩,而且是头条显示,我弱弱的点开了它,然后很仔细的看了一圈,终于在一个小角落里找到了一个比较简单的东西,“排列三”,嗯...就三个数是不是还好弄点,要不推测的数太多了会不会把自己搞死,嘿嘿...我打开了它,有图有真相:
在中间一个猥琐的地方找到了“历史数据”,我点开了它,找的就是它:
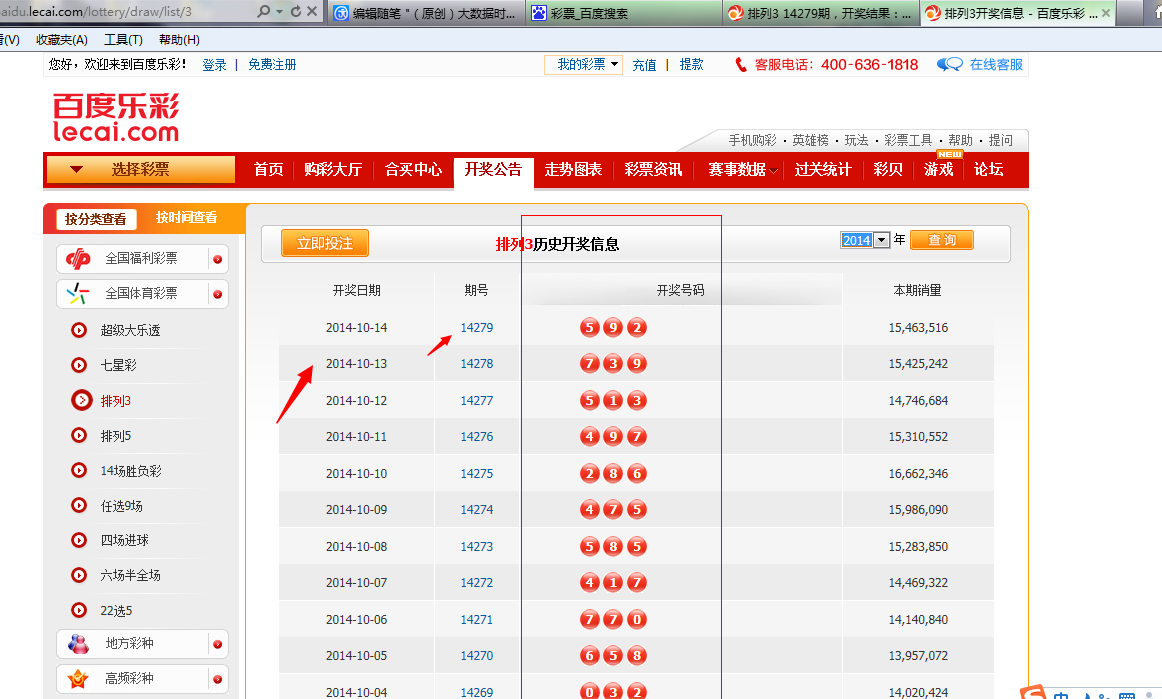
嘿,就是它,我找到了部分历史数据,而且里面数据都很标准,完全符合我们时序预测的算法,期号我们做主键,日期列也有..开奖号码为预测列,嘿嘿..百度做的还是蛮可爱的!
别高兴的太早,丫找到数据就牛了,这些数据随便找个网站一大堆大堆的!
好吧,我们低调的打开了Office的Excel软件,然后把这些数据搞到Excel中来:
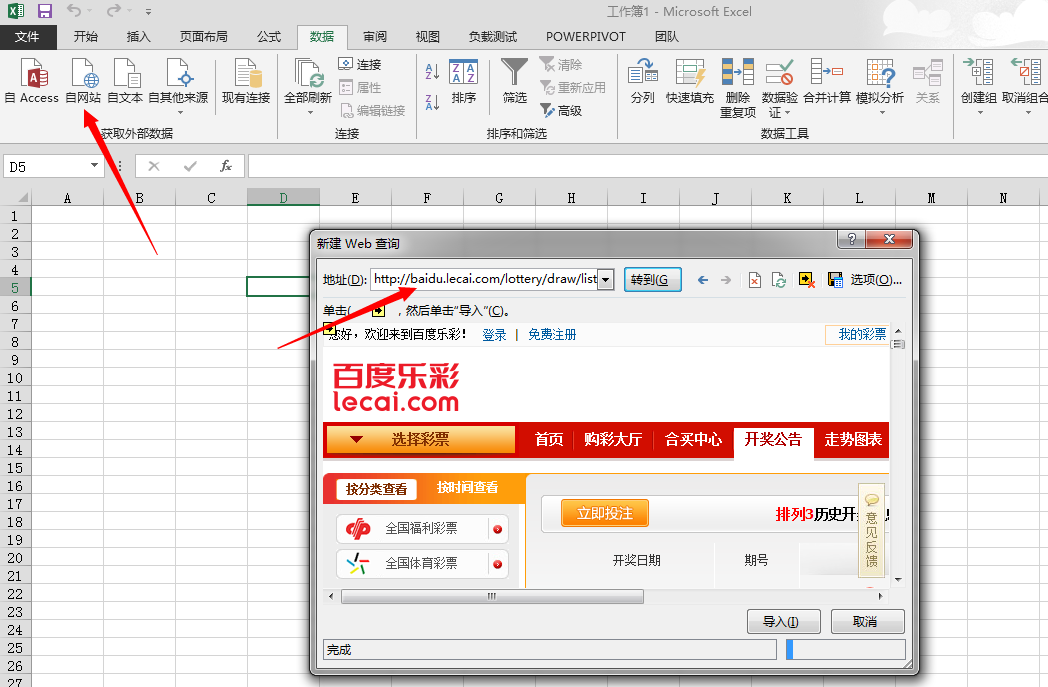
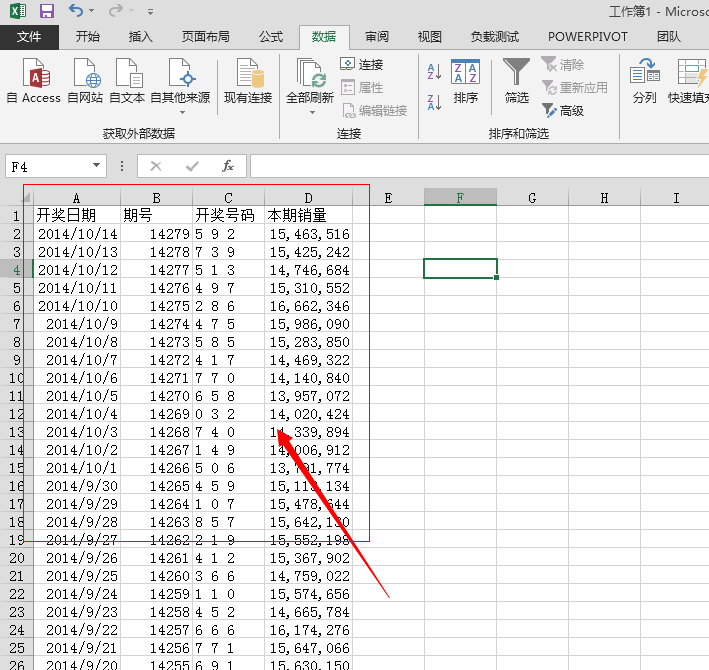
点击导入按钮,新建一个Sheet来存储数据,清理掉不需要的冗余数据,得到标准的规范数据:
然后通过SQL Server自带的导入工具,顺利的导入到数据库中,为了研究好这三个数,单个数字之间有没有关联性,为此我单独创建了一张表,将这三个数字拆分开来研究,希望这样得到的数据会准确一点点...以防被拍砖的风险,我们来看下建库脚本:

SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[TicketResult](
[开奖日期] [datetime] NULL,
[期号] [float] primary key not NULL,
[开奖号码] [nvarchar](255) NULL,
[本期销量] [float] NULL,
[FirstNo] [int] NULL,
[TwoNo] [int] NULL,
[ThirdNo] [int] NULL
) ON [PRIMARY]
GO
这个脚本很土,很多地方不标准,玩过多年数据库的银们不要喷我,中文字段名、没建索引等等吧,为了演示方便我就先凑着用着。我们将Excel导入到库中通过语句插入到这张表中,这过程简单的很,我们就不贴图了。有问题的可以私信我,我们直接看结果:
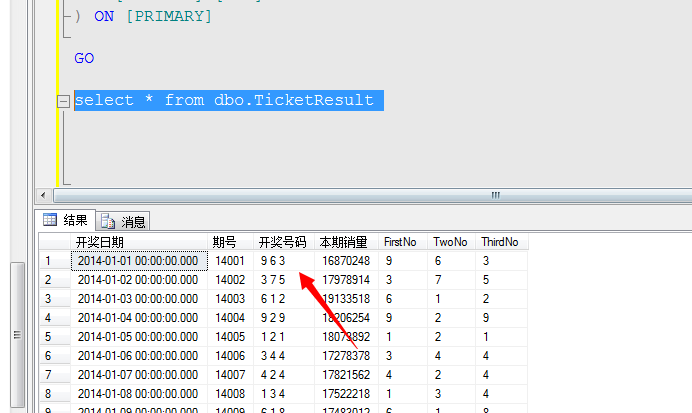
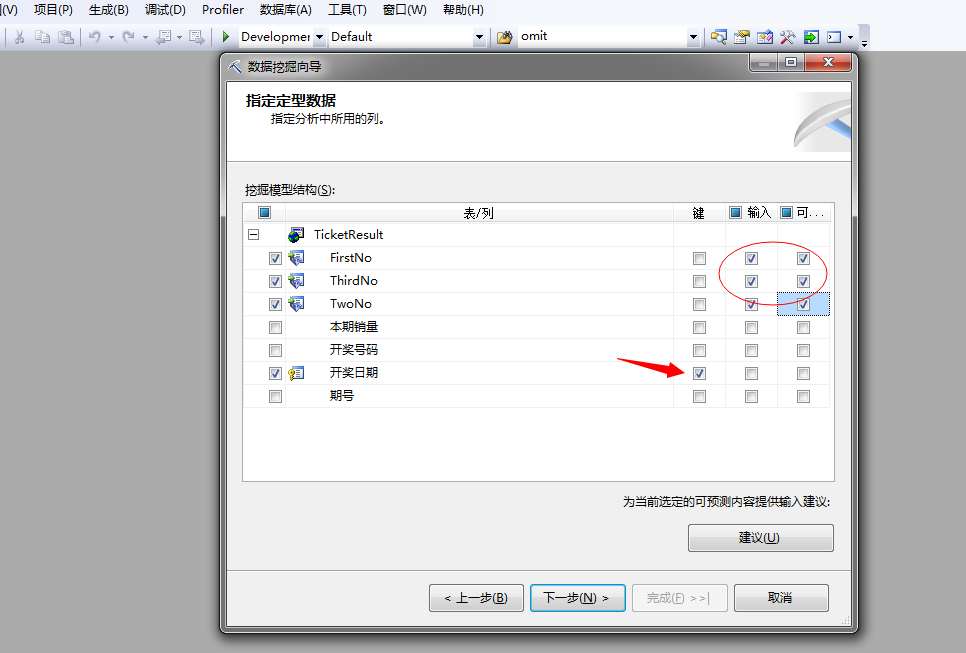
数据有了,剩下的步骤就是打开我们的解决方案,然后新建数据源,然后新建数据源视图,然后新建数据挖掘结构,具体的详细步骤不清楚的可以参考我之前文章或者私信我,这里我们只看一下新建挖掘结构的过程中的输入、输出和键的设置:
然后完成该模型的建立,我们来看看此模型方案:
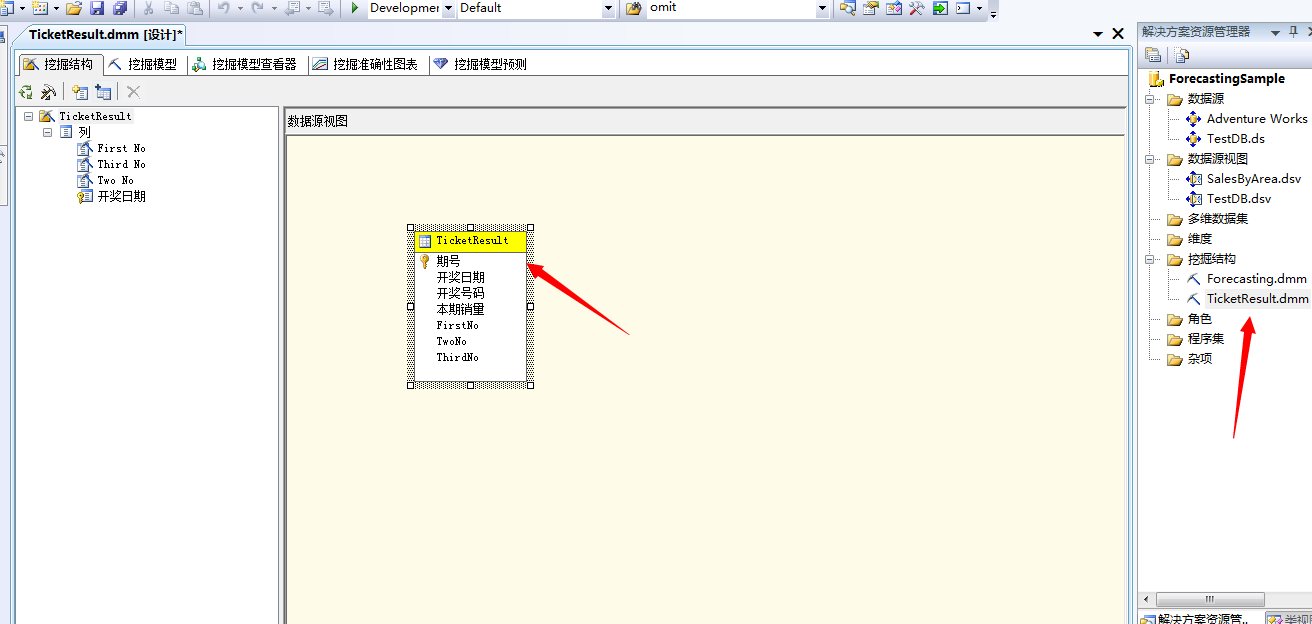
到此我们的数挖掘模型已经建立完毕,然后部署下,然后处理下,我们就可以浏览结果了!
怀着沉重的心情,我悄悄的打开了“挖掘模型查看器”,结果,你懂得...

你妹呀,这是神马?一堆乱码...一片混沌嘛...
但是、但是我不能对不起“大湿”的称号,我要从中找到点神马...哪怕是一点点蛛丝马迹..我小心翼翼的选择了第一个数字的预测:FirstNO:
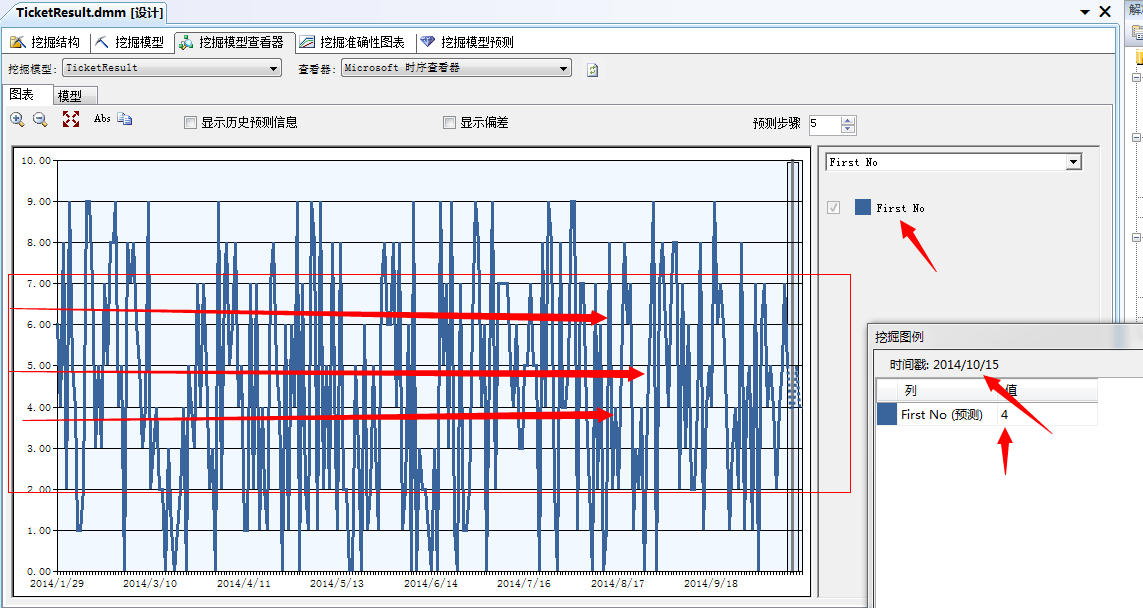
从选择第一个数字的预测图我们可以看到,历史结果值集中在中间值,以4为最佳值,并且以此值作为分割点向两侧逐渐减少出现次数,然后我通过点击顺利的预测出来明天也就是2014年10月15号的第一个数字应该是4!...我去...好数字...这个数字出现概率最高,为了给自己挽回颜面,可爱的VS也将它作为明天最佳的预测值。
然后..然后我又看了其它数字的预测,通过上面的方法将明天的结果预测结果值保存到了数据库,我们来看:

我们点击来看运行结果:
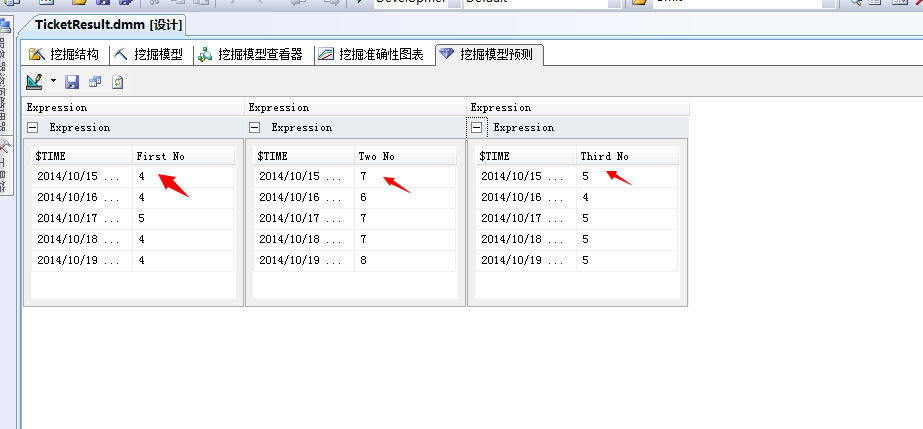
哈哈...明天的彩票值我已经顺利的预测出来了:看看...4、7、5!嘿嘿...就是这个值了..有兴趣的童鞋可以去买了,中了算你的,不中也算你的...明天不中我还会赠送后天...大后天!。。。
其实经过上面的分析已经得到对于排列三这种彩票他是有规律就是出现的概率集中于中间值,也就是4,如果从长期来看买这块数据肯定能赚。
然后我们将这部分值保存到数据库,然后拿着这部分胜利的数据,去到彩票网站买彩票去!
嘿嘿...接下来的事我就等着:升职、加薪、出任CEO、赢取白富美、走上人生巅峰.....哈哈...
我果断的掏出了手机,进入到了彩票网站,选择排列三这种彩票,准备购买:

4+7+5=16...哈哈,我利用“求和”这种方案就买16这个数字了!
但是我详细看了看...
尼玛!...选择的数字得到的回报率是不一样的!也就是说越选择接近4的中奖概率高,但是得到的奖金回报率也少,选择离4远的数值中奖概率低,但是得到的奖金回报率也高!...
我那个去...
我的高富帅梦、我的大湿梦!.....
结语
呵呵...通过上面的分析基本上我们能看到时序算法的好处,从上面的结果预测值来看..其实和他们官网给出的奖金方案还是有出入的,比如我预测求和值的大部分是16、14、17...这些值全部大于11...而根据它上面的图片可以看到他们推荐的最高中奖数应该是10和11...返回金额都是9块钱!
有兴趣的可以继续分析这块..可能对于彩票这种概率事件的预测没有规律可循,但是生活中大部分事件都有规律可循的,而这些是我们所要挖掘和分析的。
文章的最后我们给出前几篇算法的文章连接:
微软数据挖掘算法:Microsoft Naive Bayes 算法(3)
原文地址:(原创)大数据时代:基于微软案例数据库数据挖掘知识点总结(Microsoft 时序算法——结果预算+下期彩票预测篇)

