
决策树(decision tree)
代码还好懂,但是后面选择更好的划分数据集的方法,有点不知道为什么那样选。
还要好好理解推导。
from math import log #计算香农熵 def calcShannonEnt(dataSet): numEntries = len(dataSet) labelCount = {} for featVector in dataSet: currentlabel = featVector[-1] labelCount[currentlabel] = labelCount.get(currentlabel,0) + 1 shannonEnt = 0.0 for key in labelCount: prob = float(labelCount[key])/numEntries shannonEnt -= prob * log(prob, 2) return shannonEnt #训练样本 def createDataSet(): dataSet = [[1,1,'yes'],[1,1,'yes'],[1,0,'no'], [0,1,'no'],[0,1,'no']] labels = ['no surfacing','flippers'] return dataSet,labels #按照给定特征划分数据集 def splitDataSet(dataSet,axis,value): retDataSet = [] for featVec in dataSet: if(featVec[0]==value): reducedFeatVec = featVec[:axis] #这个变量干嘛的? reducedFeatVec.extend(featVec[axis+1:]) retDataSet.append(reducedFeatVec) return retDataSet def main(): dataSet,labels = createDataSet() # shannonEnt = calcShannonEnt(dataSet) #香农熵 # print(shannonEnt) print(splitDataSet(dataSet,0,1)) print(splitDataSet(dataSet,0,0)) main()
append和extend区别:
a = [1,2,3] c = [1,2,3] b = [4,5,6] a.append(b) c.extend(b) print(a) print(c)
[1, 2, 3, [4, 5, 6]]
[1, 2, 3, 4, 5, 6]
1月18日
今天上午从 网上搜了一些其他人的笔记,加上自己思考,才明白这里要干什么,书上推导部分都省略了。
关于条件熵: http://blog.csdn.net/xwd18280820053/article/details/70739368
http://blog.csdn.net/HerosOfEarth/article/details/52347820


from math import log import operator #计算香农熵 def calcShannonEnt(dataSet): numEntries = len(dataSet) labelCount = {} for featVector in dataSet: currentlabel = featVector[-1] labelCount[currentlabel] = labelCount.get(currentlabel,0) + 1 shannonEnt = 0.0 for key in labelCount: prob = float(labelCount[key])/numEntries shannonEnt -= prob * log(prob, 2) return shannonEnt #训练样本 def createDataSet(): dataSet = [[1,1,'yes'],[1,1,'yes'],[1,0,'no'], [0,1,'no'],[0,1,'no']] labels = ['no surfacing','flippers'] return dataSet,labels #按照给定特征划分数据集 def splitDataSet(dataSet,axis,value): retDataSet = [] for featVec in dataSet: if(featVec[axis]==value): reducedFeatVec = featVec[:axis] #这个变量干嘛的? reducedFeatVec.extend(featVec[axis+1:]) retDataSet.append(reducedFeatVec) return retDataSet def chooseBestFeatureToSplit(dataSet): numFeatures = len(dataSet[0]) - 1 #最后一个标签不需要拿来分类 baseEntropy = calcShannonEnt(dataSet) #计算不分组的无序值 #print(baseEntropy) bestinfoGain = 0.0;bestFeature = -1 for i in range(numFeatures): featList = [example[i] for example in dataSet] #将数据集中所有第i个特征值写入新list中 [1, 1, 1, 0, 0] #print(featList) uniqueFeatures = set(featList) #{0, 1} newEntropy = 0.0 for value in uniqueFeatures: subDataSet = splitDataSet(dataSet, i, value) #print(subDataSet) prob = len(subDataSet)/float(len(dataSet)) newEntropy += prob * calcShannonEnt(subDataSet) #对所有唯一值得到的熵求和 tempinfoGain = baseEntropy - newEntropy #print("%d %f"%(i,newEntropy)) #print('\n') if(tempinfoGain > bestinfoGain): bestinfoGain = tempinfoGain bestFeature = i return bestFeature def majorityCnt(classList): classCount = {} #dict for vote in classList: classCount[vote] = classCount.get(vote,0) + 1 sortedClassCount = sorted(classCount.items(),key = operator.itemgetter(1),reverse=True) return sortedClassCount[0][0] #创建树 def createTree(dataSet,labels): classList = [example[-1] for example in dataSet] if classList.count(classList[0]) == len(classList): #所有类标签全部相同 return classList[0] if len(dataSet[0]) == 1: return majorityCnt(classList) #返回出现次数最多的类别 bestFeat = chooseBestFeatureToSplit(dataSet) bestFeatlabel = labels[bestFeat] myTree = {bestFeatlabel:{}} del(labels[bestFeat]) featList = [example[bestFeat] for example in dataSet] uniqueFeatures = set(featList) for value in uniqueFeatures: sublabels = labels[:] myTree[bestFeatlabel][value] = createTree(splitDataSet(dataSet,bestFeat,value), sublabels) return myTree def main(): dataSet,labels = createDataSet() # shannonEnt = calcShannonEnt(dataSet) #香农熵 # print(shannonEnt) myTree = createTree(dataSet,labels) print(myTree) main() #0.9709505944546686 # [1, 1, 1, 0, 0] # [[1, 'no'], [1, 'no']] # [[1, 'yes'], [1, 'yes'], [0, 'no']] # 0 0.550978 # [1, 1, 0, 1, 1] # [[1, 'no']] # [[1, 'yes'], [1, 'yes'], [0, 'no'], [0, 'no']] # 1 0.800000
import matplotlib.pyplot as plt decisionNode = dict(boxstyle="sawtooth",fc="0.8") #判断节点 leafNode = dict(boxstyle="round4",fc="0.8") #叶节点 arrow_args = dict(arrowstyle="<-") def plotNode(nodeTxt,centerPt,parentPt,nodeType): createPlot.ax1.annotate(nodeTxt,xy=parentPt,xycoords='axes fraction',xytext=centerPt,textcoords='axes fraction',\ va="center", ha="center",bbox=nodeType,arrowprops=arrow_args) def createPlot(): fig = plt.figure(1,facecolor='white') fig.clf() createPlot.ax1 = plt.subplot(111,frameon=False) #print("汉字") plotNode(R'决策节点', (0.5,0.1), (0.1,0.5), decisionNode) plotNode(R'叶节点', (0.8,0.1), (0.3,0.8), leafNode) plt.show() createPlot()
绘制中显示汉字还是没有解决。
绘制决策树。
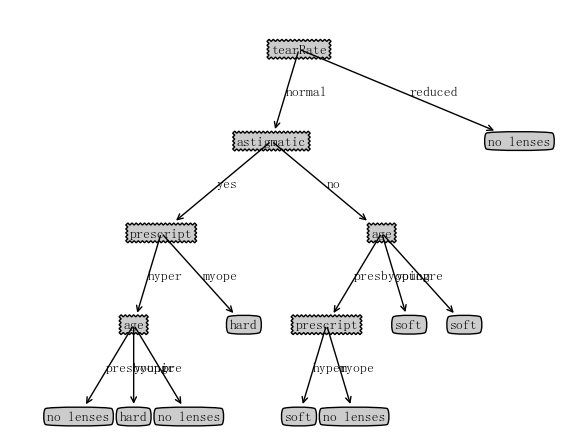
隐形眼镜选择。
import matplotlib.pyplot as plt from pylab import mpl import trees mpl.rcParams['font.sans-serif'] = ['FangSong'] decisionNode = dict(boxstyle="sawtooth",fc="0.8") #判断节点 leafNode = dict(boxstyle="round4",fc="0.8") #叶节点 arrow_args = dict(arrowstyle="<-") def plotNode(nodeTxt,centerPt,parentPt,nodeType): createPlot.ax1.annotate(nodeTxt,xy=parentPt,xycoords='axes fraction',xytext=centerPt,textcoords='axes fraction',\ va="center", ha="center",bbox=nodeType,arrowprops=arrow_args) def createPlot(myTree): fig = plt.figure(1,facecolor='white') fig.clf() axprops = dict(xticks=[],yticks=[]) createPlot.ax1 = plt.subplot(111,frameon=False,**axprops) plotTree.totalW = float(getNumLeafs(myTree)) #3 plotTree.totalD = float(getTreeDepth(myTree)) plotTree.xOff = -0.5/plotTree.totalW;plotTree.yOff = 1.0 # x,y属于[0,1.0] plotTree(myTree, (0.5,1.0), "") plt.show() def getNumLeafs(myTree): numLeafs = 0 firstStr = list(myTree.keys())[0] #py3.x中返回一个dict_keys对象,py2.x返回一个列表 secondDict = myTree[firstStr] # #print(type(myTree.keys())) # print(type(secondDict[1])) # #print(secondDict) # #print(firstStr) for key in secondDict.keys(): if type(secondDict[key]).__name__ == 'dict': numLeafs += getNumLeafs(secondDict[key]) else: numLeafs += 1 #print(numLeafs) #print(numLeafs) return numLeafs def getTreeDepth(myTree): maxDepth = 0 firstStr = list(myTree.keys())[0] #py3.x中返回一个dict_keys对象,py2.x返回一个列表 secondDict = myTree[firstStr] for key in secondDict.keys(): if type(secondDict[key]).__name__ == 'dict': thisDepth = getTreeDepth(secondDict[key]) + 1 else: thisDepth = 1 if thisDepth > maxDepth: maxDepth = thisDepth #print(maxDepth) return maxDepth #createPlot() def plotMidText(centerPt,parentPt,txtString): xMid = (parentPt[0]-centerPt[0])/2.0+centerPt[0] yMid = (parentPt[1]-centerPt[1])/2.0+centerPt[1] createPlot.ax1.text(xMid,yMid,txtString) def plotTree(myTree,parentPt,nodeTxt): numLeafs = getNumLeafs(myTree) depth = getTreeDepth(myTree) firstStr = list(myTree.keys())[0] secondDict = myTree[firstStr] centerPt = (plotTree.xOff + (1.0+float(numLeafs))/2.0/plotTree.totalW,plotTree.yOff) #决策点单独画 plotNode(firstStr, centerPt, parentPt, decisionNode) plotMidText(centerPt, parentPt, nodeTxt) plotTree.yOff -= 1.0/plotTree.totalD for key in secondDict.keys(): if type(secondDict[key]).__name__ == 'dict': plotTree(secondDict[key], centerPt, str(key)) else: plotTree.xOff += 1.0/plotTree.totalW plotNode(secondDict[key], (plotTree.xOff,plotTree.yOff), centerPt, leafNode) plotMidText((plotTree.xOff,plotTree.yOff), centerPt, str(key)) plotTree.yOff += 1.0/plotTree.totalD myTree = {'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}} #getNumLeafs(myTree) def main(): fr = open('lenses.txt') lenses = [inst.strip().split('\t') for inst in fr.readlines()] lenseslabels = ['age','prescript','astigmatic','tearRate'] lensesTree = trees.createTree(lenses,lenseslabels) print(lensesTree) #print(getTreeDepth(myTree)) createPlot(lensesTree) #createPlot(myTree) main()
自己前面怎么也解决不了在treePlotter中调用trees的代码,书上都是在命令行上输的,试了好多种方法都不行,结果在玩跳一跳的时候,突然想到能不能在代码中直接import trees,结果就可以……

