

函数(二)
内置函数
一、全部内置函数汇总

二、ads() :取绝对值
s = abs(-1) print(s) #运行结果:1
三、all()、any()
1、何为True?何为False?
布尔值中0、None、空字符串(空格为True)、空列表、空字典、空元组都为False,其他为True
s = bool(0) s1 = bool("") s2 = bool([]) s3 = bool({}) s4 = bool(()) s5 = bool(" ") print(s,s1,s2,s3,s4,s5) #运行结果:False False False False False True
2、all()函数
all(可以被循环/迭代的对象(列表、字典等)),里面的元素全部都为真就为真,不然就是False
s = all([11,22,34,0]) print(s) #运行结果:False
3、any()函数
any(可以被循环/迭代的对象(列表、字典等)),里面的元素全部都为假就为假,不然就是True
s = any([11,22,34,0]) print(s) #运行结果:True
四、ascii():自动执行某个对象的__repr__方法
class Foo: def __repr__(self): return "111" n = ascii(Foo()) print(n) #运行结果:111
五、bin()、oct()、hex()
1、bin():将十进制转换成二进制
0b:表示二进制
2、oct():将十进制转换成八进制
0o:表示八进制
3、hex():将十进制转换成十六进制
0x:表示十六进制
print(bin(5)) print(oct(9)) print(hex(15)) #运行结果 ''' 0b101 0o11 0xf '''
六、bool():布尔函数
s = bool(0) s1 = bool("") s2 = bool([]) s3 = bool({}) s4 = bool(()) s5 = bool(" ") print(s,s1,s2,s3,s4,s5) #运行结果:False False False False False True
七、bytes()、bytearray()
1、bytes():将字符串转换成字符串形式的字节
s = '张三' #一个字节8位,一个汉字用gbk编码的话是2个字节,用UTF-8编码是3个字节 # 100100 100100 100100 100100 100100 100100 计算机存储的二进制 # 23 23 23 23 23 23 十进制 # 2f 2f 2f 2f 2f 2f 十六进制 #将字符串转换成字节类型 #bytes(需要转换的字符串,按照什么编码进行转换) n = bytes(s,encoding='utf-8') print(n) n = bytes(s,encoding='gbk') print(n) #运行结果 ''' b'\xe5\xbc\xa0\xe4\xb8\x89' b'\xd5\xc5\xc8\xfd'
2、bytearray()将字符串转换成列表的形式的字节
s = '张三' n = bytearray(s,encoding='utf-8') print(n) n = bytearray(s,encoding='gbk') print(n) #打印结果 ''' bytearray(b'\xe5\xbc\xa0\xe4\xb8\x89') bytearray(b'\xd5\xc5\xc8\xfd') '''
3、数字转换成字符串:str()
s = 123 s10 = str(s) print(type(s10)) print(s10) #打印结果 ''' <class 'str'> 123 '''
4、将字节转换成字符串:
字符串转换成字节用的是什么方式的编码,如果要再编译回来的时候也需要用同样的编码
s = '张三' s10 = str(bytes(s,encoding='utf-8'),encoding='utf-8') print(type(s10)) print(s10) #打印结果 ''' <class 'str'> 张三 '''
八、callable()、chr()、ord()
1、callable()
检测传的值 是否可以被执行或者被调用
def f1(): pass f1()
f2 = 123
print(callable(f1)) print(callable(f2)) #运行结果: ''' True 表示函数可以被调用 False 表示不能被调用 '''
2、chr()、ord()
2.1、ascii码表的对应关系
2.2、chr():十进制对应的字符;ord():字符对应的十进制
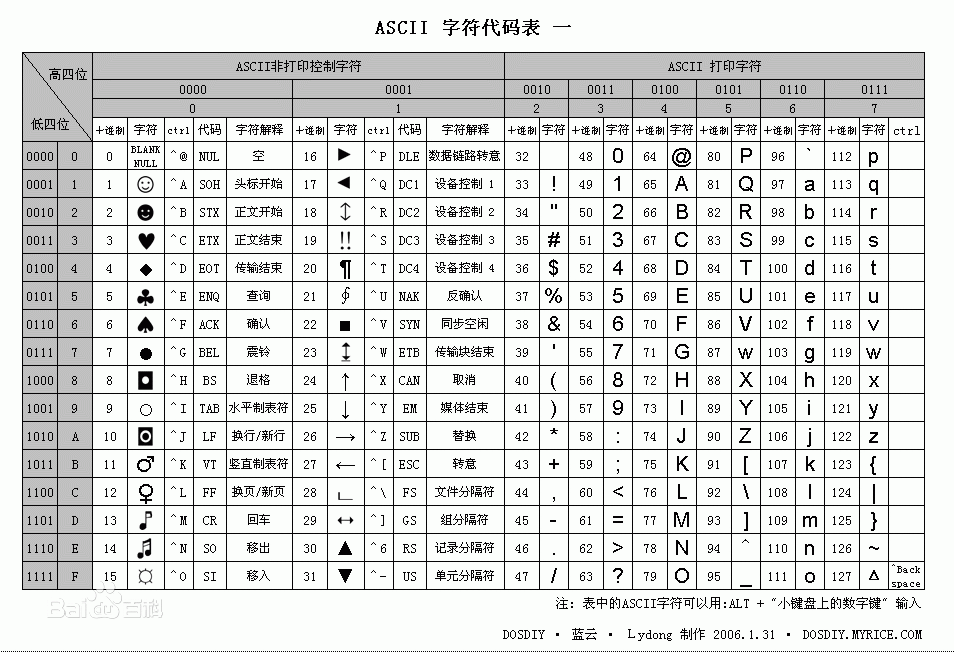
2.3、相关代码
print(chr(65)) print(ord("a"))
#运行结果 ''' A 97 '''
九、classmethod()--面向对象(后续补充)
十、compile()、eval()、exec()
1、文件运行步骤
1.1、文件保存在硬盘里面就是以0101的模式进行保存的
1.2、操作文件的步骤
打开文件拿到的数据类型就是字符串(open)
运行的时候一般用的是python解释器去打开文件
- 读取文件内容(open函数)到内存,拿到的是字符串--将字符串保存到内存
- 存在特殊的结构(for循环之类的),解释器如何知道遇到for循环的时候执行循环:python内部,将字符串编译成特殊的代码--complied()
- 执行代码--exec()
2、compile()、exec():
1.1、compile():
将字符串编译成python代码
支持字符串(<string>)(如下代码)、文件名(传文件名)
1.2、exec():执行编译后的代码
1.3、编译完成后的不同模式:single(单行)、eval(表达式)、exec
single:将代码编译成单行的 python程序
eval:将代码编译成表达式
exec:将代码编译成与python代码一模一样的东西
1.4、用途:Django
1.5、相关代码
#将字符串编译成代码
s = "print(123)" #字符串 x = compile(s,"<string>","exec") #编译字符串 print(x) #运行结果: #<code object <module> at 0x102978660, file "<string>", line 1>
#执行编译后的代码
exec (x) #执行编译后的代码 #运行结果:123
2、eval()
将字符串变成python的表达式(通过运算符表示出来的)进行执行,并且拿到执行结果
s = "8*8" ret = eval(s) print(ret) #运行结果:64
3、总结
编译
compile():将字符串、文件编译成python代码
执行
exec():能够执行python的所有东西,无返回值,接收:代码或字符串
eval():只能执行表达式,有返回值,可以自行进行编译(可以直接自己编译字符串)
十一、complex():处理复数
十二、dict()、dir()、 help()
1、dict():字典
2、dir():快速获取一个对象、模块、类为你提供了哪些功能
print(dir(dict)) #打印结果 ''' ['__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'clear', 'copy', 'fromkeys', 'get', 'items', 'keys', 'pop', 'popitem', 'setdefault', 'update', 'values'] '''
3、help():具体功能的解释(读取源码)
print(help(dict))
十四、divmod()
总共97条数据,每页显示10页,需要多少页,利用python的逻辑进行实现
r = divmod(97,10) print(r) #运行结果 ''' (9, 7)(商,余数) '''
十五、enumerate() 待完善
十六、isinstance()
1、对象与类的关系:对象是类的实例
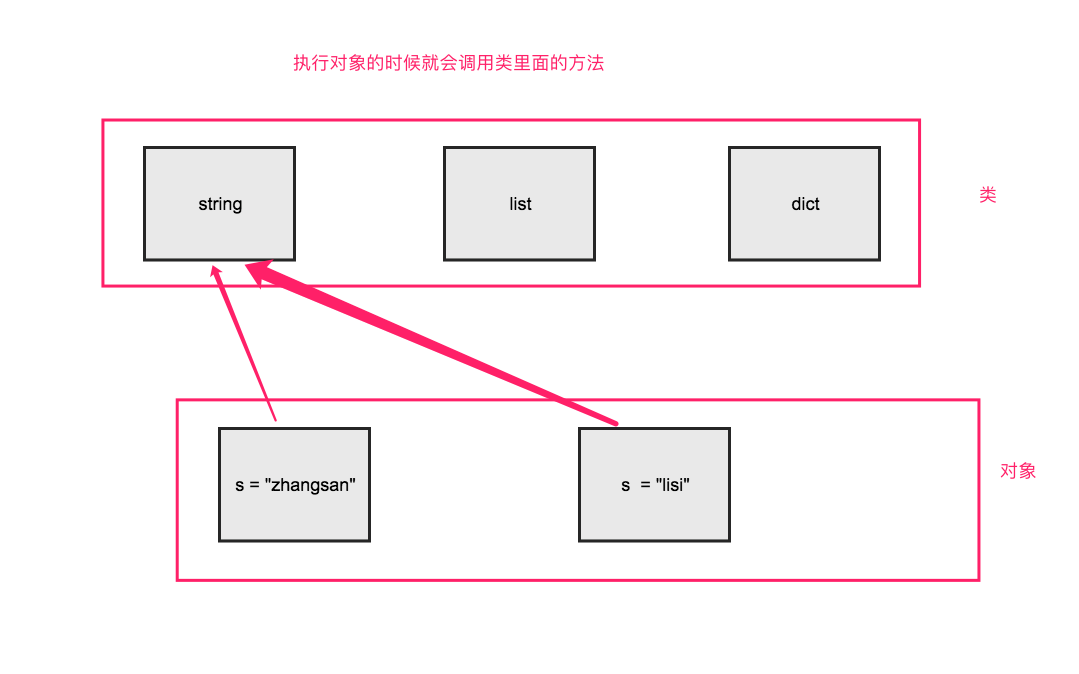
2、isinstance():判断某对象是某个类的实例
s = "zhangsan" r = isinstance(s,str) print(r) #打印结果:True
十七、filter()、map()
1、filter()
1.1、需求:给一个列表,将列表中 >22的值筛选出来,其余的剔除
方法一、通过for循环筛选出来
def f1(args): result = [] for item in args: if item > 22: result.append(item) return result li = [11,22,33,44,55] ret = f1(li) print(ret) #运行结果:[33, 44, 55]
方法二、filter(函数,可迭代的对象)
可迭代的对象:列表、元组、字典
li = [11,22,33,44,55] ret = filter(None,li) print(list(ret)) #运行结果:[11,22,33, 44, 55]
def f2(a): if a > 22: return True li = [11,22,33,44,55] ret = filter(f2,li) print(list(ret)) #运行结果:[33, 44, 55]
1.2、filter()运行原理:
def f2(a):
if a > 22:
return True
li = [11,22,33,44,55]
result = [] for item in 第二个参数: #在filter内部,会循环第二个参数(li) r = 第二个参数(item) #在每一次循环的内部又会执行第一个参数 if r: result(item) #将拿到的结果进行判断,如果为真的话就会将元素添加进来,如果是假的话不添加 return result ret = filter(f2,li)
print(list(ret))
2、map()
内置函数文件操作篇
一、文件处理流程
打开文件open()--操作文件(通过源码查看功能)--关闭文件(close、pass)
二、“r”、“w”、“x”、“a”
1、打开文件
f = open('db','r') #只读 f = open('db','w') #只写(写的时候将文件清空原文件) f = open('db','x') #python3新加的,如果当文件存在的时候就报错,如果不存在的话就打开文件并且往文件里面写入内容(写入的时候与w模式一样) f = open('db','a') #追加
2、格式
open(‘打开的文件名’,‘打开的方式’)
3、例子
3.1、“r”方式打开
在硬盘里面,文件是以二进制形式保存的,通过python读取出来的是字符串,所以中间会有默认一个二进制转换成字符串的过程。
默认编码:encoding
如果在打开文件的时候,出现乱码的话,一般就是encoding(编码)出现不一致的情况,可以查看下文件保存的时候是以什么样的编码方式保存的,一般使用utf-8
f = open('test','r',encoding="utf-8") data = f.read() print(data,type(data)) f.close() #打印结果 ''' admin|123 哈哈哈|1234 <class 'str'> '''
3.2、“r”、“w”、“x”、“a”读取、写入、保存的方式都是字符串的形式
3.3、“a”方式
f = open('test','a') data = f.write('hello') print(data,type(data)) f.close() #打印结果 ''' 5 <class 'int'> '''
f = open('test','ab') data = f.write(bytes('hllo',encoding='utf-8')) print(data,type(data)) f.close() #打印结果 ''' 4 <class 'int'> '''
三、“rb”、“wb”、“xb”、“ab”
“rb”、“wb”、“xb”、“ab”方式的话,就是直接是以二进制的形式进行读取和写入,写入的时候也需要是二进制的形式
1、"ab"方式
f = open('test','ab') data = f.write(bytes('hllo',encoding='utf-8')) print(data,type(data)) f.close() #打印结果 ''' 4 <class 'int'> '''
四、“r+”、“w+”、“x+”、“a+”
“r+”:【可读、可写】
“w+”:【可读、可写】
“x+”:【可读、可写】
“a+”:【可读、可写】
1、“r+”
f = open('test','r+',encoding='utf-8') ret = f.read() print(ret) ret2 = f.write('777') #在写入的时候,需要定位下写入的位置 print(ret2) f.close() #打印结果: ''' admin|123 哈哈哈|1234 hellohellohellohellohellohellohellohllo 3(添加的777) '''
f = open('test','r+',encoding='utf-8') #read:如果打开模式无b,则read的时候按照字符读取 data = f.read(1) #tell:当前指针所在的位置永远是字节 print(f.tell()) #打印结果;3(第一个字符:李)
2、“w+”
3、“x+”
4、“a+”
一般都是会用r+进行读写操作,因为其他的方法会有局限性(a+:只能在最后进行追加,w+:先清空原先的内容再写)
5、文件添加的指针位置
5.1、默认情况
默认情况下先读取内容再写的话,默认指针就是从第一个位置遍历一遍内容,最后读完,指针的位置就在最后一位,所以写的时候也是从最后一位进行添加
5.2、修改指针位置
seek():修改的位置写入之后,会将后面的数据覆盖
tell():获取当前指针的位置
f = open('test','r+',encoding='utf-8') ret = f.read() print(ret) #打印结果: ''' admin|123 哈哈哈|1234 hellohellohellohellohellohellohellohllo777777777777 ''' f = open('test','r+',encoding='utf-8') ret = f.read() print(ret) f.seek(1) f.write('222') f.close() #打印结果: ''' a222n|123 哈哈哈|1234 hellohellohellohellohellohellohellohllo777777777777 '''
f = open('test','r+',encoding='utf-8') #read:如果打开模式无b,则read的时候按照字符读取 data = f.read(1) #tell:当前指针所在的位置永远是字节 print(f.tell()) #seek:调整当前指针的位置(字节) f.seek(f.tell()) #write:当前指针位置向后覆盖 f.write('888') f.close()
五、“rb”、“wb”、“xb”、“ab”或“r+b”、“w+b”、“x+b”、“a+b”(以字节的形式进行操作)
六、文件操作功能
1、read()
无参数,读取全部;有参数与打开方式有关(有b ,按字节;无b,按字符)
2、tell()
获取当前指针位置,永远按照字节
3、seek()
跳转到指定位置,永远按照字节
4、write()
写数据,与打开方式有关(有b ,按字节;无b,按字符)
5、close()
关闭文件
6、fileno()
文件描述符
7、flush()
将写入的文件强制从缓冲区刷新存入到硬盘
f = open('test2','a',encoding='utf-8') f.write('缓冲区') input("不输入的时候,写入的一直在缓冲区") f = open('test2','a') print(f.read()) #打印结果为空,因为前面的一直在等待input输入内容才会刷新到硬盘当中 f = open('test2','a',encoding='utf-8') f.write('缓冲区') f.flush() input("不输入的时候,写入的一直在缓冲区") f = open('test2','a') print(f.read()) #打印结果:缓冲区(直接强制刷新到硬盘中)
8、readable()
判断是否可读
f = open('test','w',encoding='utf-8') print(f.readable()) #打印结果:False,w的读取方式是不可读的
9、seekable()
是否可以移动指针
10、readline()
仅读取一行
f = open('test','r',encoding='utf-8') print(f.readline()) print(f.readline()) #打印结果 ''' 张三|123 李四|456 '''
11、truncate()
用来截断数据,指针后面的数据会直接被截断、清空掉
f = open('test','r+',encoding='utf-8') f.seek(3) f .truncate() print(f.read()) f.close() #打印结果 ''' 张(指针以字节的形式定位了3位,并且将指针后面的内容进行清空) '''
12、for循环文件对象
打开文件之后(对象),循环这个文件(对象)
f = open('test','r',encoding='utf-8') for line in f: print(line) #打印结果 ''' 张 李 钱 '''
13、close()
关闭文件
14、with 操作
14.1、集合了open与close操作文件的功能,打开文件,操作完之后将文件进行关闭
14.2、格式
with open('xb') as f: pass
14.3、python2.7及以上,支持同时打开两个文件
with open('test') as f1,open('test1') as f2: pass
将一个文件里面的前十行,写到另一个文件里面
with open('test','r',encoding='utf-8') as f1,open('test2','w',encoding='utf-8') as f2: times = 0 for line in f1: times +=1 if times<=10: f2.write(line) else: break #运行结果 ''' test文件 张 李 钱 1 2 3 4 5 6 7 8 9 test2文件 张 李 钱 1 2 3 4 5 6 7 '''
15、replace()
将test文件里面的test字符串替换成st并且写在test1文件中
with open('test','r',encoding='utf-8') as f1,open('test2','w',encoding='utf-8') as f2: for line in f1: new_str = line.replace('test','st') f2.write(new_str) #运行结果 ''' 张 李 钱 1 2 3 4 5 6 7 8 9 test test2文件 张 李 钱 1 2 3 4 5 6 7 8 9 st '''
内置函数补充
一、随机验证码
random模块
1、随机产生字母
ascii里面的A-Z字母的十进制范围为:65-90;小写字母(a-z)十进制范围为:97-122
import random #ascii里面的A-Z字母的十进制范围为:65-90 i = random.randrange(65,91) c = chr(i) print(c) #运行结果:J
2、随机产生数字
import random
#1< = i<5 i = random.randrange(1,5) print(i) #运行结果:5
3、生成多位随机验证码
import random li = [] for i in range(6): temp = random.randrange(65, 91) c = chr(temp) li.append(c) result = ''.join(li) #拼接列表的验证码 print(result) #运行结果:XXVXOU
4、任意位置生成多个数字、字母混合的随机验证码
import random li = [] for i in range(6): r = random.randrange(0,5) if r == 2 or r ==4: #随机生成的第三位永远都是数字 num = random.randrange(0, 10) li.append(str(num)) #下面的join方法的时候要求需要全部是字符串,不支持数字,所以需要将数字转换成字符串 else: temp = random.randrange(65,91) c = chr(temp) li.append(c) result = ''.join(li) #拼接列表的验证码 print(result) #运行结果:HM6I93
5、固定位置生成多个数字、字母混合的随机验证码
注意点⚠️
使用join拼接功能的时候,需要全部是字符串,不可以是数字,需要将数字强制转换成字符串
import random li = [] for i in range(6): if i == 2: #随机生成的第三位永远都是数字 num = random.randrange(0, 10) li.append(str(num)) #下面的join方法的时候要求需要全部是字符串,不支持数字,所以需要将数字转换成字符串 else: temp = random.randrange(65,91) c = chr(temp) li.append(c) result = ''.join(li) #拼接列表的验证码 print(result) #运行结果:HU2MUS
二、map函数
1、map()函数
需求:对列表的每一个元素都加100
2、格式
map(函数,可迭代的对象(可以for循环的东西)),内部帮忙进行循环,具体的执行就是自己写的函数即可
#通过for循环来解决 li = [11,22,33,44,55] def f1(args): result = [] for i in args: result.append(100+i) return result r = f1(li) print(list(r)) #打印结果:[111, 122, 133, 144, 155]
#通过map函数实现 li = [11,22,33,44,55] def f2(a): return a+100 result = map(f2,li) print(list(result)) #打印结果:[111, 122, 133, 144, 155]
#lambda+map li = [11,22,33,44,55] result = map(lambda a:a + 100,li) print(list(result)) #打印结果:[111, 122, 133, 144, 155]
三、globals()、locals()
1、globals():所有的全局变量
2、locals():所有的局部变量
NAME = '张三' def show(): a = 123 c = 123 print(locals()) print(globals()) show() #打印结果 ''' {'c': 123, 'a': 123} {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x1006d8550>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': '/Users/monkey/eleme/code/515151/test.py', '__cached__': None, 'NAME': '张三', 'show': <function show at 0x100662e18>} '''
四、 hash()
1、定义
将我们传的对象转换成哈希值,并且保存在硬盘里面
无论我们输入的值是多少,生成的哈希值都是固定的(19位)
s = 'hhh' print(hash(s)) #打印结果:8993219217206648805
2、应用
在字典里面,有的key是比较长的,所以一般在存储的过程中,程序会自动将key转换成哈希值来存储到硬盘当中1、存储空间变小
2、内部可以通过哈希值做一个索引来查找
dic = {'42adasdksabsafbjsvfaskfaskfskfvsfskf':1}
print(hash('42adasdksabsafbjsvfaskfaskfskfvsfskf')) #实际程序中存储的内容为哈希值
五、id()、len()
1、id()
查看内存地址
2、len()
查看长度
python3可以通过字节(转换成字节)、字符的方式查看
python2里面智能通过字节的方式查看
s = '李四' print(len(s)) #打印结果:2 python3里面默认的是字符找的,如果想要计算字节的话,转换成字节即可 s = '李四' b = bytes(s,encoding='utf-8') print(len(b)) #打印结果:6
六、 max() 、min() 、sum()
1、max()
取最大值
2、min()
取最小值
3、sum()
求和
s = [11,22,33,44,55] print(sum(s)) print(max(s)) print(min(s)) #打印结果: # 165 # 55 # 11
七、memoryview()
1、定义
python里面新加的一种函数,查看内存地址相关的类
十、next()、iter():迭代器相关
十一、object()
所有类的父类
十二、pow()
求次方
2**20 #2的20次方 pow(2,20) #2的20次方
十三、property()、repr():面向对象里面的知识点
repr()
repr('zhangsan') #自动执行str类里面的__repr__方法
十四、range()
取范围
十五、reversed()
反转
li = [11,22,33,44] print(li.reverse()) #打印结果:None
十六、round()
定义
四舍五入
r = round(1.8) print(r) #打印结果:2
十七、slice()
1、定义
python3里面新加的函数
2、用途
类似于列表里面的切片的功能
li = [11222,33,22,44,23,4344] s = li[0::2] print(s) #打印结果:[11222, 22, 23]
十八、sort()
1、定义
排序
li = [11,33,22,44] li.sort() print(sorted(li)) #等同于上句代码,排序作用 #打印结果:[11, 22, 33, 44]
十九、vars()、zip()
1、vars()
当前模块可使用的变量
2、zip()
利用内置函数zip(),实现功能
l1 =['zhangsan',22,33,44,55]
l2 = ['is',22,33,44,55]
l3 = ['good',22,33,44,55]
l4 = ['boy',22,33,44,55]
请获取字符串s = 'zhangsan_is_good_boy'
l1 = ['zhangsan',22,33,44,55] l2 = ['is',22,33,44,55] l3 = ['good',22,33,44,55] l4 = ['boy',22,33,44,55] r = zip(l1,l2,l3,l4) temp = list(r)[0] ret = '_'.join(temp) print(ret) #打印结果:zhangsan_is_good_boy
l1 = ['zhangsan',22,33,44] l2 = ['is',22,33,44] l3 = ['good',22,33,44,55] l4 = ['boy',22,33,44,55] r = zip(l1,l2,l3,l4) print(list(r)) #打印结果:[('zhangsan', 'is', 'good', 'boy'), (22, 22, 22, 22), (33, 33, 33, 33), (44, 44, 44, 44)] #如果部分没有55的话就直接一一对应到44而已
二十、所有内置函数汇总
1、汇总图片

2、相关官方文档链接
https://docs.python.org/3/library/functions.html#next
3、划重点

