《集体智慧编程》学习笔记
连载中~~
目录
第一章,集体智慧导言
第二章,提供推荐
第三章,发现群组
**该书使用python作为示例语言,2.x版本
第一章 集体智慧导言
集体智慧
为了创造新的想法,而将一群人的行为、偏好或思想组合在一起。
机器学习
人工智能的一个与算法相关的子域,允许计算机不断地进行学习。<个人理解>(计算机接收到一定的数据,通过确定的算法推断出数据相关的信息,借此来推断出未来可能会出现的数据****由此可见,需要学好数学 ~~~)。
机器学习的局限
机器学习基于“过去”,受限于大量模式上的归纳能力,如果出现了一个不同与以往任何模式的情况,机器会因无法和人一样做出“理性的判断”而出现“误解”。
总结:本章概述了集体智慧和机器学习
第二章 提供推荐
协作型过滤
根据人们对某些东西的喜好,来对提供给他人的进行过滤。
搜集偏好
同过算法判断人与人的相似程度
---欧几里得距离:通过计算个体在坐标系(共有的数据项作坐标轴)中的距离作为个体的相似程度,距离越近越相似。
---皮尔逊系数:通过计算共有数据项在坐标系(个体作坐标轴)中的一条与所有数据距离之和是最小值的直线,直线的系数作为相似度,系数越接近1,越相似。
---等等。
要根据实际情况选择算法,例如:在面对数据中存在大量偏低喜好和偏高喜好的用户时,欧几里得距离会之间认为两类无关,但实际上他们的喜好曲线可能时相似的,所以适合选用皮尔逊系数。
提供推荐
基于用户的相似程度进行推荐,通过对用户相似程度的加权处理,可以判断物品的推荐度。
仿照用户,可以求出物品的相似程度,加权处理,可以得出用户对该物品可能给予的评价,进而实行推荐。
总结:通过相关的算法,计算用户的或者物品的相似程度,加权处理后即可作为提供推荐的标准。
第三章 发现群组
本章主要学习聚类,聚类是一种无监督学习。有监督学习是指,利用带有正确答案的样本数据进行“训练”。
分级聚类
分级聚类是指不断地将最为相似的群组两两合并,来构造出一个群组的层级结构。其中的每个群组都是从单一元素开始的,在每次迭代的过程中,分级聚类算法会计算每两个群组间的距离,并将距离最近的两个群组合并成一个新的群组,一直重复,直到只剩一个群组为止。结构如下:
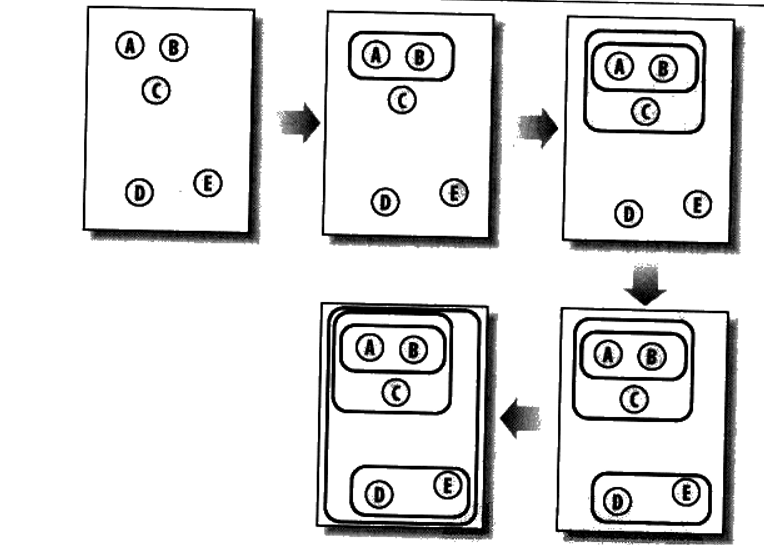
迭代过程中可以保留每一次聚合的状态,进而形成一组树形数据,可以作图来查看。
列聚类
将数据倒置后再进行分级聚类,可以得到另一组数据,两组数据常常是很有必要的。
K-均值聚类
分级聚类虽然可以返回一个形象直观的树,但是该算法计算量大而且没有进行处理的情况下无法得到不同的组。
K-均值聚类可以先接收用户所要求取得组数,然后将数据分布在空间内,随机生成n(用户期望得到的组数)个点,进行迭代。根据每个数据距离最近的点进行分组,分组后的中心位置赋给随机点,一直迭代到分配过程不再产生变化为止。过程如下:
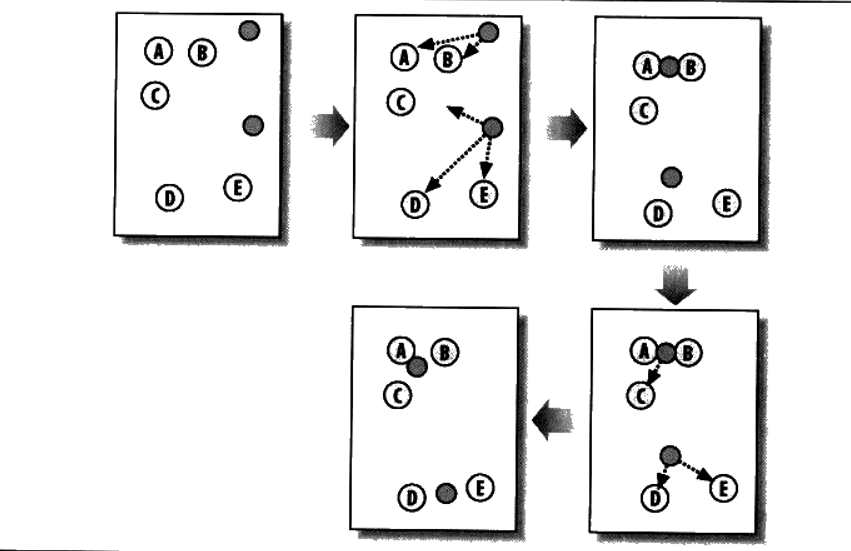
针对偏好分类
将希望拥有的物品列举出来,利用算法将偏好相近者分在一起。由于是对数据集合的计算,并且数据之包含0,1,所以采用Tanimoto系数的度量方法,计算的是集合之间的关系。
以二维形式展现数据
将所有数据绘制在一张纸上(多维缩放),为数据集找到一种二维表达形式,根据彼此之间的差距相互靠近远离,知道无法移动到更好的情况,随后得到所有数据的二维展示图。
待续......

