并发编程-你真的知道并发问题产生的源头吗?
本文从计算机系统层面来讲述在提升性能的过程中,引发的一系列问题。读完本文你将get到并发编程过程中的原子性,可见性,有序性三大问题的来源。
随着硬件发展速度的放缓,摩尔定律已经不在生效,各个硬件似乎已经到了瓶颈;然而随着互联网的普及,网民数量不断增加,对系统的性能带来了巨大的挑战。因此我们要通过各种方式来压榨硬件的性能,从而提高系统的性能进而提升用户体验,提升企业的竞争力。
由于CPU,内存,IO三者之间速度差异,为了提高系统性能,计算机系统对这三者速度进行平衡。
- CPU 增加了缓存,以均衡与内存的速度差异;
- 操作系统增加了进程、线程,以分时复用 CPU,进而均衡 CPU 与 I/O 设备的速度差异;
- 编译程序优化指令执行次序,使得缓存能够得到更加合理地利用。
缓存导致得可见性的问题
一个线程对共享变量的修改,另外一个线程能够立刻看到,我们称为可见性。

多核时代,每颗 CPU 都有自己的缓存,这时 CPU 缓存与内存的数据一致性就没那么容易解决了,当多个线程在不同的 CPU 上执行时,这些线程操作的是不同的 CPU 缓存。 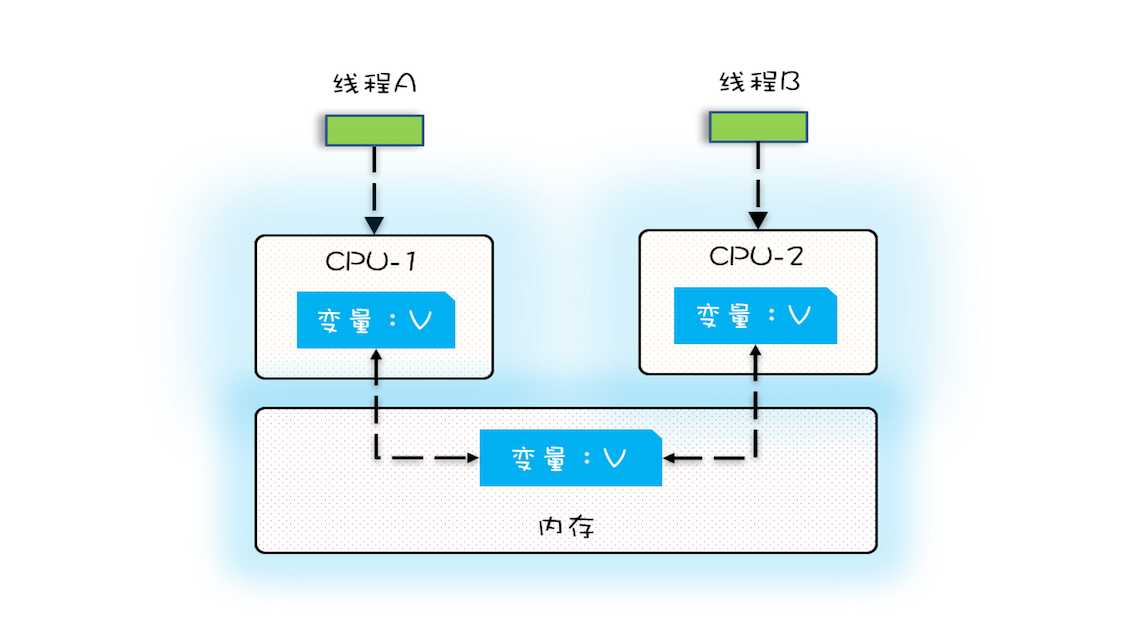
线程切换带来的原子性问题
由于IO和cpu执行速度的差别巨大,所以在早期操作系统中就发明的多线程,即使在单核的cpu上我们也可以一遍听着歌,一边写着bug,这就是多线程。
早期操作系统基于进程来调度cpu, 不同进程间是不共享内存空间的,所以进程要做任务切换要切换内存映射地址,而一个进程创建的所有线程都是共享一个内存空间,所以线程做任务切换成本很低。现代操作系统都基于更轻量级的线程来调度,现在我们提到的“任务切换”都是指“线程切换”。
因为式单核cpu,所以同一时刻只能执行一个任务,所以多线程通常使用抢占的方式来获取操作系统的时间片。
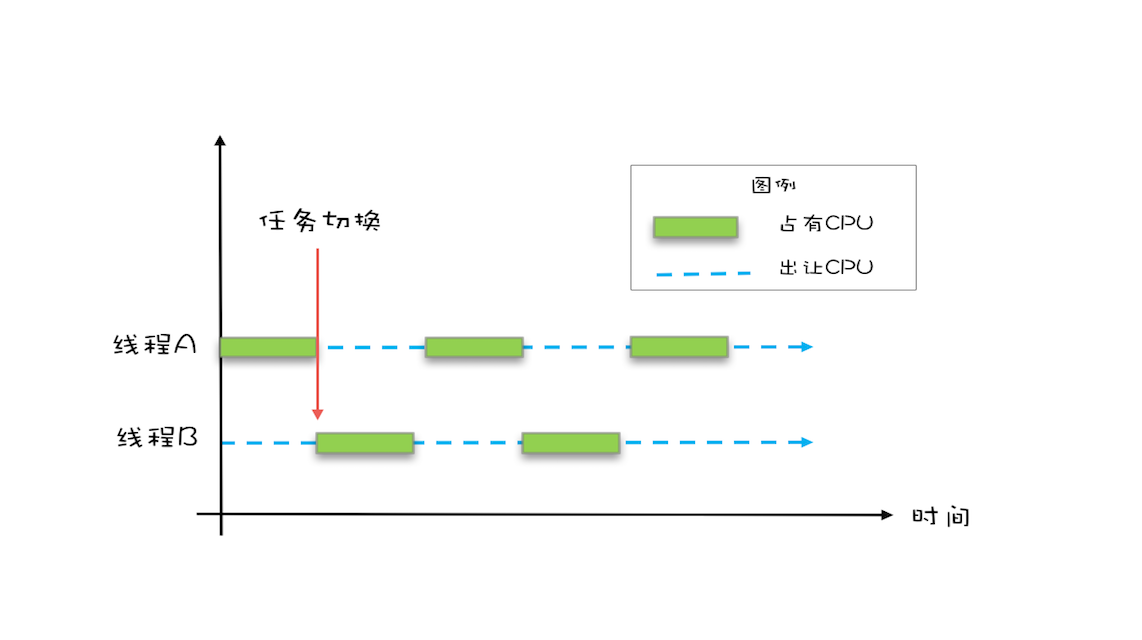
Java的并发编程中都是基于多线程,线程的切换时机通常在一条cpu指令执行完毕之后,而Java作为一门高级编程语言,通常一条语句可能由多个cpu指令来完成。例如:count += 1, 至少需要三条指令。
-
指令1:首先,需要把变量count从该内存加载到cpu的寄存器
-
指令2:之后,在寄存器中执行+1操作
-
指令3: 最后,将结果写入内存(忽略缓存机制)
假设count = 0, 有2个线程同时执行count+=1这段代码。线程A执行完指令1将count = 0加载到cpu寄存器,进行了任务切换到了线程B执行,线程B执行完之后将count = 1写入到内存,然后再切换到线程A执行,此时线程A获取寄存器中的count=0进行+1操作得到结果也是1,所以最终内存中的count = 1,而我们所期望的是2.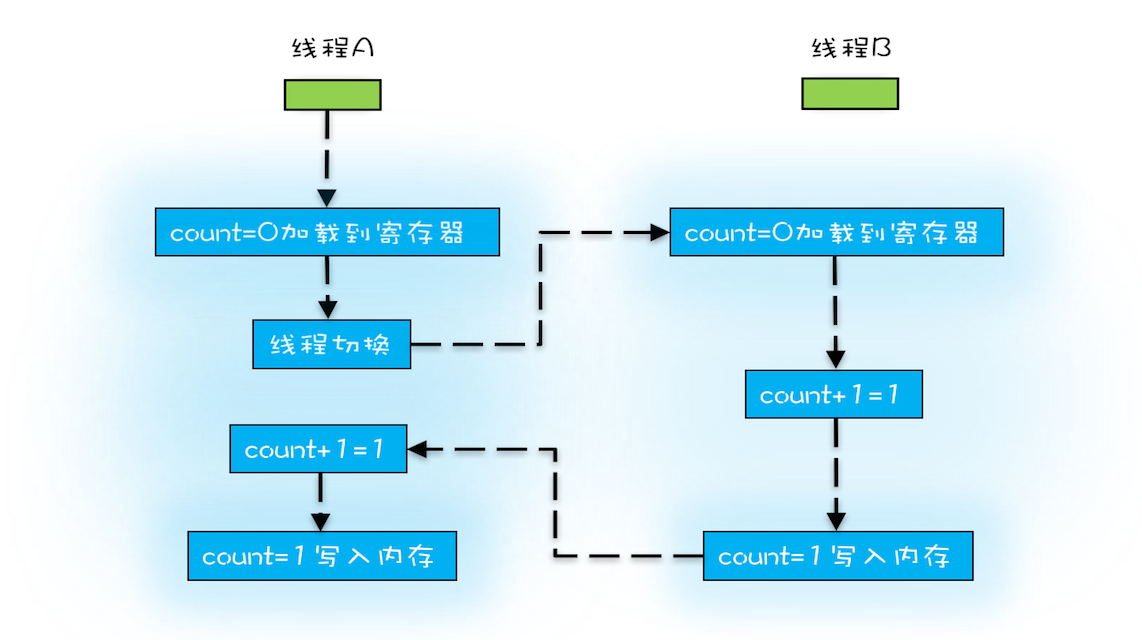
CPU层面的原子操作仅仅是在指令级别的,既一条cpu指令不可中断。在高级语言中,我们为了避免以上情况发生,我们把一个或多个操作在cpu执行过程中不被中断的特性称为原子性。
编译优化带来的有序性问题
为了提高程序的执行效率,编译器有时会在编译过程中对程序的进行优化,从而改变程序的执行顺序。如程序“a = 4; b = 5”,在优化后执行顺序可能变成“b = 5; a = 4”。通常进行一项优化过程中可能会带来另一项问题,改变程序的执行顺序通常也会导致让人意想不到的bug。
Java领域中一个经典的案例就是利用双重检查创建单例对象,代码如下:在获取实例getInstance()方法中,我们首先判断instance是否为空,如果为空则锁住Singleton.class对象并再次检查instance是否为空,如果仍然为空则创建Singleton的一个实例。
public class Singleton {
static Singleton instance;
/**
* 获取Singleton对象
*/
public static Singleton getInstance(){
if (instance == null) {
synchronized(Singleton.class) {
if (instance == null)
instance = new Singleton();
}
}
return instance;
}
}
假设有两个线程 A、B 同时调用 getInstance() 方法,他们会同时发现 instance == null,于是同时对 Singleton.class 加锁,此时 JVM 保证只有一个线程能够加锁成功(假设是线程 A),另外一个线程则会处于等待状态(假设是线程 B);线程 A 会创建一个 Singleton 实例,之后释放锁,锁释放后,线程 B 被唤醒,线程 B 再次尝试加锁,此时是可以加锁成功的,加锁成功后,线程 B 检查 instance == null 时会发现,已经创建过 Singleton 实例了,所以线程 B 不会再创建一个 Singleton 实例。
以上过程仅仅是我们的理想情况下,但是实际过程中往往会创建多次Singleton实例。原因是创建一个对象需要多条cpu指令,且编译器可能对这几条指令进行了排序。在执行new语句创建一个对象时,通常会包含一下三个步骤(此处进行了简化,实际实现过程会比此过程复杂):
- 在堆内存为对象分配一块内存M
- 在内存M区域进行Singleton对象的初始化
- 将内存M地址赋值给instance变量。
但是实际优化后的执行顺序可能时以下这种情况: - 在堆内存为对象分配一块内存M
- 将内存M地址赋值给instance变量。
- 在内存M区域进行Singleton对象的初始化
假设A,B线程同时执行到了getInstance()方法,线程A执行完instance = $M(将内存M地址赋值给instance变量,但是未将对象进行初始化)后切换到B线程,当B线程执行到instance == null时,由于instance已经指向了内存M的地址,所以会返回false,直接返回instance,如果我们这是访问instance中的成员变量或者方法时就可能会出现NullPointException。

总结
在操作系统平衡CPU,内存,IO三者速度差异过程中进行了一系列的优化。
- CPU 增加了缓存,以均衡与内存的速度差异;
- 操作系统增加了进程、线程,以分时复用 CPU,进而均衡 CPU 与 I/O 设备的速度差异;
- 编译程序优化指令执行次序,使得缓存能够得到更加合理地利用。
这三个不同方面的优化也带来了可见性,原子性,有序性等问题,他们通常是并发程序的bug的源头。
笔者的个人博客网站

