Python微信机器人
_____egon新书来袭请看:https://egonlin.com/book.html
一 简介
wxpy基于itchat,使用了 Web 微信的通讯协议,,通过大量接口优化提升了模块的易用性,并进行丰富的功能扩展。实现了微信登录、收发消息、搜索好友、数据统计等功能。
总而言之,可用来实现各种微信个人号的自动化操作。
安装:wxpy 支持 Python 3.4-3.6,以及 2.7 版本
pip3 install -U wxpy
二 登录微信
1、扫码登录微信
from wxpy import * bot = Bot()
2、cache_path=True
运行上面的程序,会弹出二维码,用手机微信扫一扫即可实现登录。
但上面的程序有一个缺点,每次运行都要扫二维码。不过wxpy非常贴心地提供了缓存的选项,用于将登录信息保存下来,就不用每次都扫二维码,如下
bot = Bot(cache_path=True) # 必须先登录过一次以后才可以使用缓存
三 微信好友男女比例

from wxpy import * from pyecharts import Pie bot=Bot(cache_path=True) #注意手机确认登录 friends=bot.friends() attr=['男朋友','女朋友'] value=[0,0] for friend in friends: if friend.sex == 1: # 等于1代表男性 value[0]+=1 elif friend.sex == 2: #等于2代表女性 value[1]+=1 pie = Pie("Egon老师的好朋友们") pie.add("", attr, value, is_label_show=True) pie.render('sex.html')

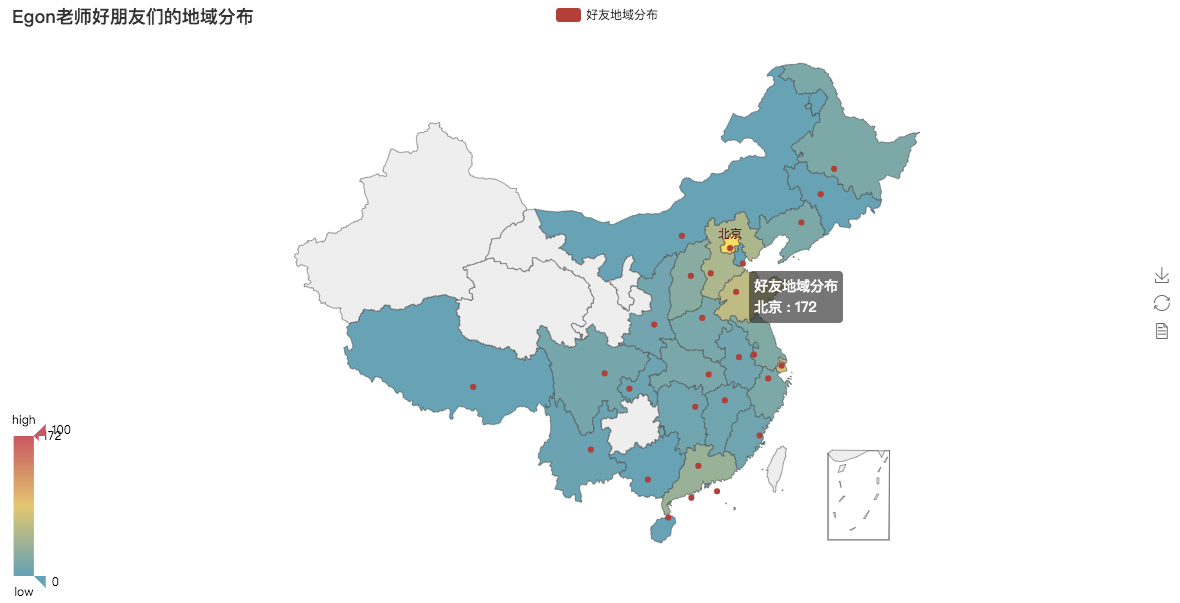
四 微信好友地域分布
from wxpy import * from pyecharts import Map bot=Bot(cache_path=True) friends=bot.friends() area_dic={} for friend in friends: if friend.province not in area_dic: area_dic[friend.province]=1 else: area_dic[friend.province]+=1 attr = area_dic.keys() value = area_dic.values() map = Map("Egon老师好朋友们的地域分布", width=1200, height=600) map.add( "好友地域分布", attr, value, maptype='china', is_visualmap=True, #结合体VisualMap visual_text_color='#000' ) map.render('area.html')
五 微信好友数据分析之词云
bg.jpg

#安装软件 pip3 install jieba pip3 install pandas pip3 install numpy pip3 install scipy pip3 install wordcloud


from wxpy import * import re import jieba import pandas as pd import numpy bot=Bot(cache_path=True) friends=bot.friends() # 统计签名 with open('signatures.txt','w',encoding='utf-8') as f: for friend in friends: # 对数据进行清洗,将标点符号等对词频统计造成影响的因素剔除 pattern=re.compile(r'[一-龥]+') filterdata=re.findall(pattern,friend.signature) f.write(''.join(filterdata)) #过滤停止词 with open('signatures.txt','r',encoding='utf-8') as f: data=f.read() segment=jieba.lcut(data) words_df=pd.DataFrame({'segment':segment}) stopwords = pd.read_csv("stopwords.txt", index_col=False, quoting=3, sep=" ", names=['stopword'], encoding='utf-8') words_df = words_df[~words_df.segment.isin(stopwords.stopword)] #使用numpy进行词频统计 words_stat = words_df.groupby(by=['segment'])['segment'].agg({"计数":numpy.size}) words_stat = words_stat.reset_index().sort_values(by=["计数"],ascending=False) # print(words_stat) #词频可视化:词云,基于wordcloud库,当然pyecharts也可以实现 from scipy.misc import imread from wordcloud import WordCloud, ImageColorGenerator import matplotlib.pyplot as plt # 设置词云属性 # color_mask = imread('background.jfif') # color_mask = imread('bg.jpg') color_mask = imread('bg1.jpeg') wordcloud = WordCloud( # font_path="simhei.ttf", # mac上没有该字体 font_path="/System/Library/Assets/com_apple_MobileAsset_Font3/6d903871680879cf5606a3d2bcbef058e56b20d4.asset/AssetData/华文仿宋.ttf", # 设置字体可以显示中文 background_color="white", # 背景颜色 max_words=100, # 词云显示的最大词数 mask=color_mask, # 设置背景图片 max_font_size=100, # 字体最大值 random_state=42, width=1000, height=860, margin=2,# 设置图片默认的大小,但是如果使用背景图片的话, # 那么保存的图片大小将会按照其大小保存,margin为词语边缘距离 ) # 生成词云, 可以用generate输入全部文本,也可以我们计算好词频后使用generate_from_frequencies函数 word_frequence = {x[0]:x[1]for x in words_stat.head(100).values} print(word_frequence) word_frequence_dict = {} for key in word_frequence: word_frequence_dict[key] = word_frequence[key] print(word_frequence_dict) wordcloud.generate_from_frequencies(word_frequence_dict) # 从背景图片生成颜色值 image_colors = ImageColorGenerator(color_mask) # 重新上色 wordcloud.recolor(color_func=image_colors) # 保存图片 wordcloud.to_file('output.png') plt.imshow(wordcloud) plt.axis("off") plt.show()
from wxpy import * import re import jieba import pandas as pd import numpy bot=Bot(cache_path=True) friends=bot.friends() # 统计签名 with open('signatures.txt','w',encoding='utf-8') as f: for friend in friends: # 对数据进行清洗,将标点符号等对词频统计造成影响的因素剔除 pattern=re.compile(r'[一-龥]+') filterdata=re.findall(pattern,friend.signature) f.write(''.join(filterdata)) #过滤停止词 with open('signatures.txt','r',encoding='utf-8') as f: data=f.read() segment=jieba.lcut(data) words_df=pd.DataFrame({'segment':segment}) stopwords = pd.read_csv("stopwords.txt", index_col=False, quoting=3, sep=" ", names=['stopword'], encoding='utf-8') words_df = words_df[~words_df.segment.isin(stopwords.stopword)] #使用numpy进行词频统计 words_stat = words_df.groupby(by=['segment'])['segment'].agg({"计数":numpy.size}) words_stat = words_stat.reset_index().sort_values(by=["计数"],ascending=False) print(words_stat) #可是化词云 from pyecharts import WordCloud word_frequence = {x[0]:x[1]for x in words_stat.head(100).values} name = word_frequence.keys() value = word_frequence.values() wordcloud = WordCloud(width=1300, height=620) wordcloud.add("", name, value, word_size_range=[20, 100]) wordcloud.render('cy.html')

停止词,是由英文单词:stopword翻译过来的,原来在英语里面会遇到很多a,the,or等使用频率很多的字或词,常为冠词、介词、副词或连词等。如果搜索引擎要将这些词都索引的话,那么几乎每个网站都会被索引,也就是说工作量巨大。可以毫不夸张的说句,只要是个英文网站都会用到a或者是the。那么这些英文的词跟我们中文有什么关系呢? 在中文网站里面其实也存在大量的stopword,我们称它为停止词。比如,我们前面这句话,“在”、“里面”、“也”、“的”、“它”、“为”这些词都是停止词。这些词因为使用频率过高,几乎每个网页上都存在,所以搜索引擎开发人员都将这一类词语全部忽略掉。如果我们的网站上存在大量这样的词语,那么相当于浪费了很多资源。原本可以添加一个关键词,排名就可以上升一名的,为什么不留着添加为关键词呢?停止词对SEO的意义不是越多越好,而是尽量的减少为宜。 中英文停止词表: able about above according accordingly across actually after afterwards again against ain't all allow allows almost alone along already also although always am among amongst an and another any anybody anyhow anyone anything anyway anyways anywhere apart appear appreciate appropriate are aren't around as a's aside ask asking associated at available away awfully be became because become becomes becoming been before beforehand behind being believe below beside besides best better between beyond both brief but by came can cannot cant can't cause causes certain certainly changes clearly c'mon co com come comes concerning consequently consider considering contain containing contains corresponding could couldn't course c's currently definitely described despite did didn't different do does doesn't doing done don't down downwards during each edu eg eight either else elsewhere enough entirely especially et etc even ever every everybody everyone everything everywhere ex exactly example except far few fifth first five followed following follows for former formerly forth four from further furthermore get gets getting given gives go goes going gone got gotten greetings had hadn't happens hardly has hasn't have haven't having he hello help hence her here hereafter hereby herein here's hereupon hers herself he's hi him himself his hither hopefully how howbeit however i'd ie if ignored i'll i'm immediate in inasmuch inc indeed indicate indicated indicates inner insofar instead into inward is isn't it it'd it'll its it's itself i've just keep keeps kept know known knows last lately later latter latterly least less lest let let's like liked likely little look looking looks ltd mainly many may maybe me mean meanwhile merely might more moreover most mostly much must my myself name namely nd near nearly necessary need needs neither never nevertheless new next nine no nobody non none noone nor normally not nothing novel now nowhere obviously of off often oh ok okay old on once one ones only onto or other others otherwise ought our ours ourselves out outside over overall own particular particularly per perhaps placed please plus possible presumably probably provides que quite qv rather rd re really reasonably regarding regardless regards relatively respectively right said same saw say saying says second secondly see seeing seem seemed seeming seems seen self selves sensible sent serious seriously seven several shall she should shouldn't since six so some somebody somehow someone something sometime sometimes somewhat somewhere soon sorry specified specify specifying still sub such sup sure take taken tell tends th than thank thanks thanx that thats that's the their theirs them themselves then thence there thereafter thereby therefore therein theres there's thereupon these they they'd they'll they're they've think third this thorough thoroughly those though three through throughout thru thus to together too took toward towards tried tries truly try trying t's twice two un under unfortunately unless unlikely until unto up upon us use used useful uses using usually value various very via viz vs want wants was wasn't way we we'd welcome well we'll went were we're weren't we've what whatever what's when whence whenever where whereafter whereas whereby wherein where's whereupon wherever whether which while whither who whoever whole whom who's whose why will willing wish with within without wonder won't would wouldn't yes yet you you'd you'll your you're yours yourself yourselves you've zero zt ZT zz ZZ 一 一下 一些 一切 一则 一天 一定 一方面 一旦 一时 一来 一样 一次 一片 一直 一致 一般 一起 一边 一面 万一 上下 上升 上去 上来 上述 上面 下列 下去 下来 下面 不一 不久 不仅 不会 不但 不光 不单 不变 不只 不可 不同 不够 不如 不得 不怕 不惟 不成 不拘 不敢 不断 不是 不比 不然 不特 不独 不管 不能 不要 不论 不足 不过 不问 与 与其 与否 与此同时 专门 且 两者 严格 严重 个 个人 个别 中小 中间 丰富 临 为 为主 为了 为什么 为什麽 为何 为着 主张 主要 举行 乃 乃至 么 之 之一 之前 之后 之後 之所以 之类 乌乎 乎 乘 也 也好 也是 也罢 了 了解 争取 于 于是 于是乎 云云 互相 产生 人们 人家 什么 什么样 什麽 今后 今天 今年 今後 仍然 从 从事 从而 他 他人 他们 他的 代替 以 以上 以下 以为 以便 以免 以前 以及 以后 以外 以後 以来 以至 以至于 以致 们 任 任何 任凭 任务 企图 伟大 似乎 似的 但 但是 何 何况 何处 何时 作为 你 你们 你的 使得 使用 例如 依 依照 依靠 促进 保持 俺 俺们 倘 倘使 倘或 倘然 倘若 假使 假如 假若 做到 像 允许 充分 先后 先後 先生 全部 全面 兮 共同 关于 其 其一 其中 其二 其他 其余 其它 其实 其次 具体 具体地说 具体说来 具有 再者 再说 冒 冲 决定 况且 准备 几 几乎 几时 凭 凭借 出去 出来 出现 分别 则 别 别的 别说 到 前后 前者 前进 前面 加之 加以 加入 加强 十分 即 即令 即使 即便 即或 即若 却不 原来 又 及 及其 及时 及至 双方 反之 反应 反映 反过来 反过来说 取得 受到 变成 另 另一方面 另外 只是 只有 只要 只限 叫 叫做 召开 叮咚 可 可以 可是 可能 可见 各 各个 各人 各位 各地 各种 各级 各自 合理 同 同一 同时 同样 后来 后面 向 向着 吓 吗 否则 吧 吧哒 吱 呀 呃 呕 呗 呜 呜呼 呢 周围 呵 呸 呼哧 咋 和 咚 咦 咱 咱们 咳 哇 哈 哈哈 哉 哎 哎呀 哎哟 哗 哟 哦 哩 哪 哪个 哪些 哪儿 哪天 哪年 哪怕 哪样 哪边 哪里 哼 哼唷 唉 啊 啐 啥 啦 啪达 喂 喏 喔唷 嗡嗡 嗬 嗯 嗳 嘎 嘎登 嘘 嘛 嘻 嘿 因 因为 因此 因而 固然 在 在下 地 坚决 坚持 基本 处理 复杂 多 多少 多数 多次 大力 大多数 大大 大家 大批 大约 大量 失去 她 她们 她的 好的 好象 如 如上所述 如下 如何 如其 如果 如此 如若 存在 宁 宁可 宁愿 宁肯 它 它们 它们的 它的 安全 完全 完成 实现 实际 宣布 容易 密切 对 对于 对应 将 少数 尔后 尚且 尤其 就 就是 就是说 尽 尽管 属于 岂但 左右 巨大 巩固 己 已经 帮助 常常 并 并不 并不是 并且 并没有 广大 广泛 应当 应用 应该 开外 开始 开展 引起 强烈 强调 归 当 当前 当时 当然 当着 形成 彻底 彼 彼此 往 往往 待 後来 後面 得 得出 得到 心里 必然 必要 必须 怎 怎么 怎么办 怎么样 怎样 怎麽 总之 总是 总的来看 总的来说 总的说来 总结 总而言之 恰恰相反 您 意思 愿意 慢说 成为 我 我们 我的 或 或是 或者 战斗 所 所以 所有 所谓 打 扩大 把 抑或 拿 按 按照 换句话说 换言之 据 掌握 接着 接著 故 故此 整个 方便 方面 旁人 无宁 无法 无论 既 既是 既然 时候 明显 明确 是 是否 是的 显然 显著 普通 普遍 更加 曾经 替 最后 最大 最好 最後 最近 最高 有 有些 有关 有利 有力 有所 有效 有时 有点 有的 有着 有著 望 朝 朝着 本 本着 来 来着 极了 构成 果然 果真 某 某个 某些 根据 根本 欢迎 正在 正如 正常 此 此外 此时 此间 毋宁 每 每个 每天 每年 每当 比 比如 比方 比较 毫不 没有 沿 沿着 注意 深入 清楚 满足 漫说 焉 然则 然后 然後 然而 照 照着 特别是 特殊 特点 现代 现在 甚么 甚而 甚至 用 由 由于 由此可见 的 的话 目前 直到 直接 相似 相信 相反 相同 相对 相对而言 相应 相当 相等 省得 看出 看到 看来 看看 看见 真是 真正 着 着呢 矣 知道 确定 离 积极 移动 突出 突然 立即 第 等 等等 管 紧接着 纵 纵令 纵使 纵然 练习 组成 经 经常 经过 结合 结果 给 绝对 继续 继而 维持 综上所述 罢了 考虑 者 而 而且 而况 而外 而已 而是 而言 联系 能 能否 能够 腾 自 自个儿 自从 自各儿 自家 自己 自身 至 至于 良好 若 若是 若非 范围 莫若 获得 虽 虽则 虽然 虽说 行为 行动 表明 表示 被 要 要不 要不是 要不然 要么 要是 要求 规定 觉得 认为 认真 认识 让 许多 论 设使 设若 该 说明 诸位 谁 谁知 赶 起 起来 起见 趁 趁着 越是 跟 转动 转变 转贴 较 较之 边 达到 迅速 过 过去 过来 运用 还是 还有 这 这个 这么 这么些 这么样 这么点儿 这些 这会儿 这儿 这就是说 这时 这样 这点 这种 这边 这里 这麽 进入 进步 进而 进行 连 连同 适应 适当 适用 逐步 逐渐 通常 通过 造成 遇到 遭到 避免 那 那个 那么 那么些 那么样 那些 那会儿 那儿 那时 那样 那边 那里 那麽 部分 鄙人 采取 里面 重大 重新 重要 鉴于 问题 防止 阿 附近 限制 除 除了 除此之外 除非 随 随着 随著 集中 需要 非但 非常 非徒 靠 顺 顺着 首先 高兴 是不是 说说
六 聊天机器人
1、为微信传输助手传送消息
这里的file_helper就是微信的文件传输助手,我们给文件传输助手发送一条消息,可以在手机端的文件传输助手中收到括号内的消息
bot.file_helper.send('egon say hello')
2、收发消息@bot.register()
from wxpy import * bot=Bot(cache_path=True) @bot.register() def recv_send_msg(recv_msg): print('收到的消息:',recv_msg.text) # recv_msg.text取得文本 return 'EGON自动回复:%s' %recv_msg.text # 进入Python命令行,让程序保持运行 embed()
3、自动给老婆回复信息
当你在网吧吃着鸡,操作骚出天际时,你老婆打电话让你回家吃饭,此时你怎么办。。。
from wxpy import * bot=Bot(cache_path=True) girl_friend=bot.search('Quincy.Coder')[0] print(girl_friend) @bot.register(chats=girl_friend) # 接收从指定好友发来的消息,发送者即recv_msg.sender为指定好友girl_friend def recv_send_msg(recv_msg): print('收到的消息:',recv_msg.text) # recv_msg.text取得文本 if recv_msg.sender == girl_friend: recv_msg.forward(bot.file_helper,prefix='老婆留言: ') #在文件传输助手里留一份,方便自己忙完了回头查看 return '老婆最美丽,我对老婆的爱如滔滔江水,连绵不绝' #给老婆回一份 embed()
4、从微信群中定位好友
老板的信息一定要及时回复
bot=Bot(cache_path=True) company_group=bot.groups().search('群名称')[0] boss=company_group.search('老板的微信名称')[0] @bot.register(chats=company_group) #接收从指定群发来的消息,发送者即recv_msg.sender为组 def recv_send_msg(recv_msg): print('收到的消息:',recv_msg.text) if recv_msg.member == boss: recv_msg.forward(bot.file_helper,prefix='老板发言: ') return '老板说的好有道理,深受启发' embed()
5、聊天机器人
给所有人自动回复
import json import requests from wxpy import * bot = Bot(console_qr=True, cache_path=True) # 调用图灵机器人API,发送消息并获得机器人的回复 def auto_reply(text): url = "http://www.tuling123.com/openapi/api" api_key = "申请图灵机器人获取key值放到这里" payload = { "key": api_key, "info": text, } r = requests.post(url, data=json.dumps(payload)) result = json.loads(r.content) return "[EGON微信测试,请忽略] " + result["text"] @bot.register() def forward_message(msg): return auto_reply(msg.text) embed()
给指定的群回复
import json import requests from wxpy import * bot = Bot(console_qr=True, cache_path=True) group=bot.groups().search('教学部三人组')[0] print(group) # 调用图灵机器人API,发送消息并获得机器人的回复 def auto_reply(text): url = "http://www.tuling123.com/openapi/api" api_key = "申请图灵机器人获取key值放到这里" payload = { "key": api_key, "info": text, } r = requests.post(url, data=json.dumps(payload)) result = json.loads(r.content) return "[EGON微信测试,请忽略] " + result["text"] @bot.register(group) def forward_message(msg): return auto_reply(msg.text) embed()
给指定的人回复
import json import requests from wxpy import * bot = Bot(console_qr=True, cache_path=True) girl_friend=bot.search('Quincy.Coder')[0] # 调用图灵机器人API,发送消息并获得机器人的回复 def auto_reply(text): url = "http://www.tuling123.com/openapi/api" api_key = "申请图灵机器人获取key值放到这里" payload = { "key": api_key, "info": text, } r = requests.post(url, data=json.dumps(payload)) result = json.loads(r.content) return "[EGON微信测试,请忽略] " + result["text"] @bot.register() def forward_message(msg): if msg.sender == girl_friend: return auto_reply(msg.text) embed()

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步