python用css方法爬取伯乐在线
1.css的用法
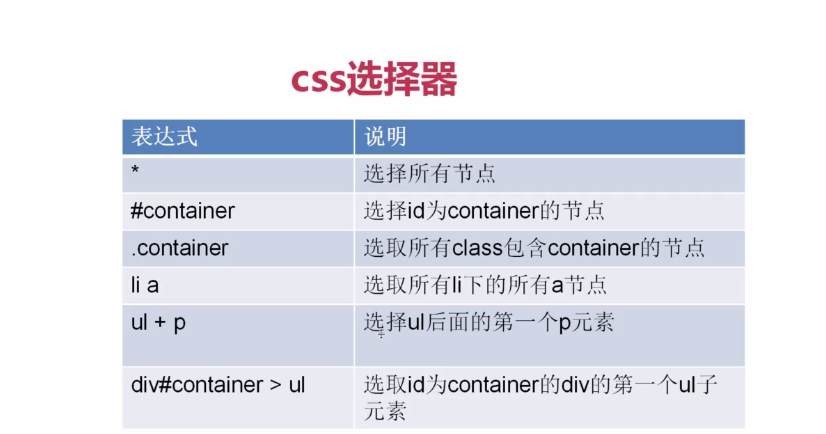
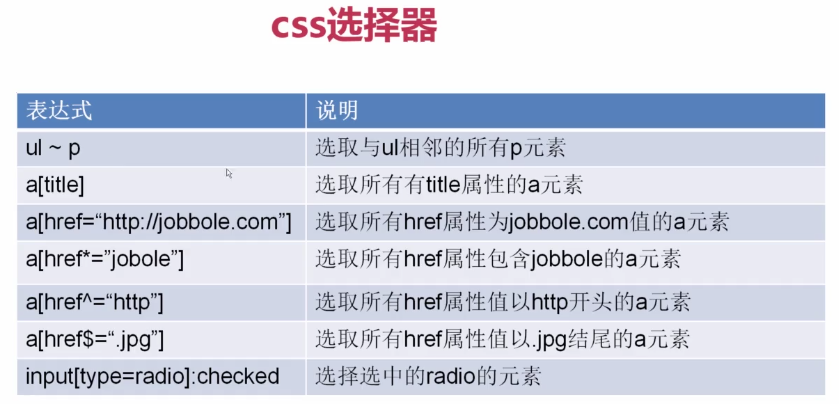

2.css的用法
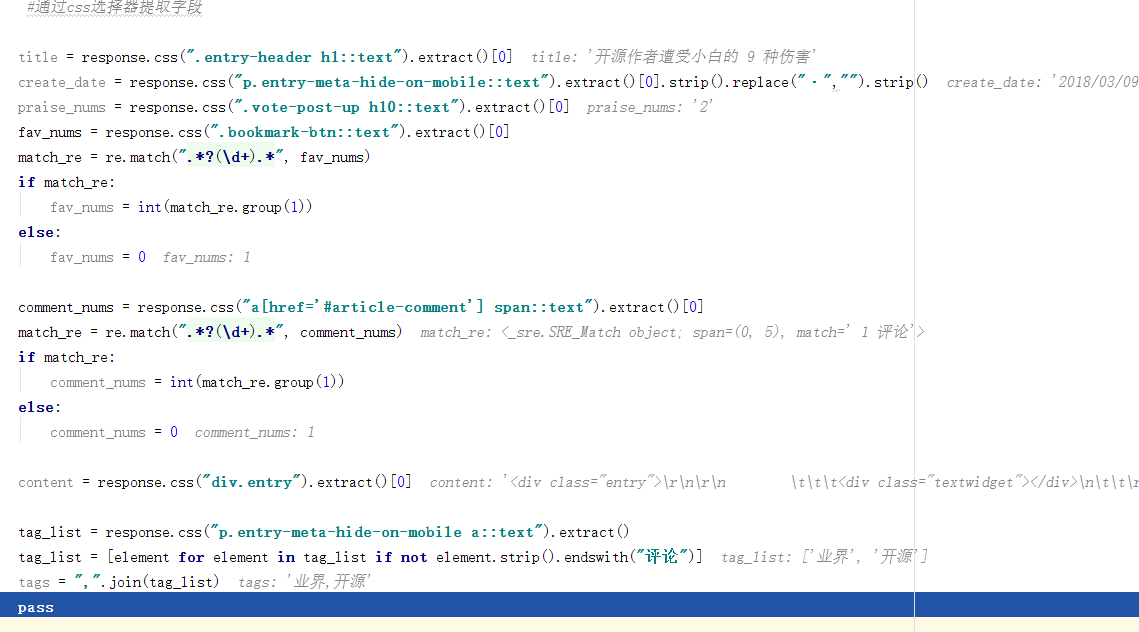
#通过css选择器提取字段 # front_image_url = response.meta.get("front_image_url", "") #文章封面图 # title = response.css(".entry-header h1::text").extract()[0] # create_date = response.css("p.entry-meta-hide-on-mobile::text").extract()[0].strip().replace("·","").strip() # praise_nums = response.css(".vote-post-up h10::text").extract()[0] # fav_nums = response.css(".bookmark-btn::text").extract()[0] # match_re = re.match(".*?(\d+).*", fav_nums) # if match_re: # fav_nums = int(match_re.group(1)) # else: # fav_nums = 0 # # comment_nums = response.css("a[href='#article-comment'] span::text").extract()[0] # match_re = re.match(".*?(\d+).*", comment_nums) # if match_re: # comment_nums = int(match_re.group(1)) # else: # comment_nums = 0 # # content = response.css("div.entry").extract()[0] # # tag_list = response.css("p.entry-meta-hide-on-mobile a::text").extract() # tag_list = [element for element in tag_list if not element.strip().endswith("评论")] # tags = ",".join(tag_list)