

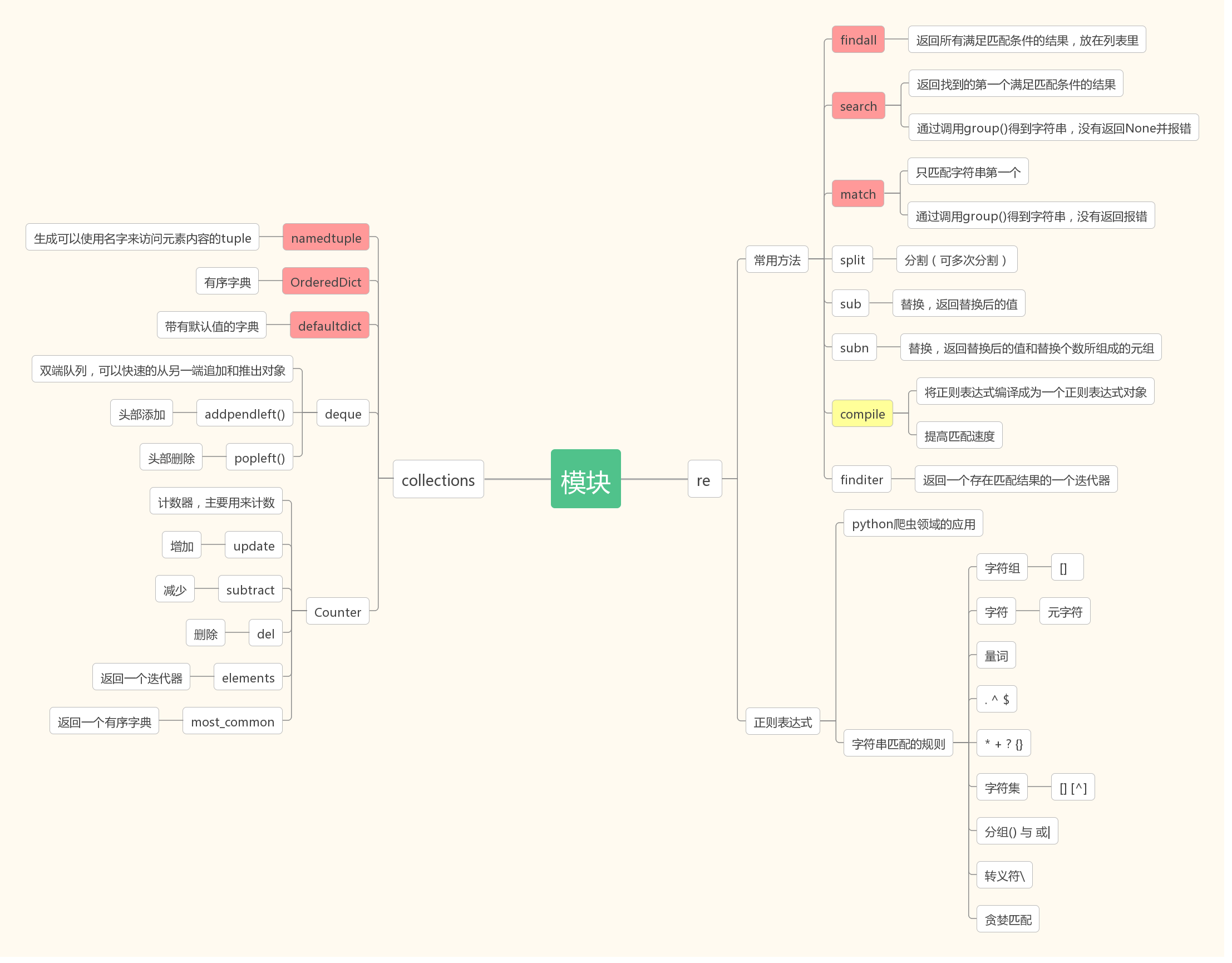
20、collections模块和re模块(正则表达式详解)
从今天开始我们就要开始学习python的模块,今天先介绍两个常用模块collections和re模块。还有非常重要的正则表达式,今天学习的正则表达式需要记忆的东西非常多,希望大家可以认真记忆。按常理来说我们应该先解释模块概念性东西再来学习具体的模块使用。可是直接解释可能反而不好理解,模块的使用非常方便,所以我们采用先介绍使用常用模块过两天再具体进行模块概念的讲解。
预习:
实现能计算类似
1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )等类似公式的计算器程序(使用正则表达式)
本篇导航:
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1、namedtuple: 生成可以使用名字来访问元素内容的tuple
用tuple元组不变特性可以表示坐标:
p = (1, 2, 3)
虽然很简单但是无法给人已直观的坐标感受,所以这个时候我们可以使用namedtuple


from collections import namedtuple #模块的导入,后面的将不再强调 Ponit = namedtuple('Ponit',['x','y','z']) p = Ponit(1,2,5) print(p.x) print(p.y) print(p.z)
2、deque: 双端队列,可以快速的从另外一侧追加和推出对象
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈
# 双向队列 from collections import deque deq = deque() deq.append(12) #从右追加 deq.append(11) deq.append(15) print(deq) deq.appendleft(10) #从左追加 deq.appendleft(16) print(deq) deq.pop() #从右取值 deq.pop() print(deq) deq.popleft() #从左取值 deq.popleft() print(deq) deq.popleft() # deq.popleft() #取完后继续取会报错 print(deq)
deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
3、Counter: 计数器,主要用来计数
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。
from collections import Counter c = Counter('abcdeabcdabcaba') print(c) print(c['a'])
计数器的其他方法
from collections import Counter #计数器的更新增加和减少 c = Counter('which') print(c) c.update('witch') print(c) c.update('watch') print(c) c.subtract('where') print(c) #键的删除 del c["h"] print(c) #返回一个迭代器 print(list(c.elements())) #返回一个有序字典 print(c.most_common()) #浅拷贝 c2 = c.copy() print(c2) #清空 c.clear() print(c)
4、OrderedDict: 有序字典
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。如果要保持Key的顺序,可以用OrderedDict
from collections import OrderedDict d = dict([('a', 1),('b', 2),('c', 3)]) print(d) o_d = OrderedDict([('a', 1), ('b', 2), ('c', 3)]) print(o_d) od = OrderedDict() od['z'] = 10 od['x'] = 10 od['y'] = 30 print(od) print(od.keys())
注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序
5、defaultdict: 带有默认值的字典
有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
即: {'k1': 大于66 , 'k2': 小于66}
x = {"k1":[],"k2":[]}
y = [11,22,33,44,55,66,77,88,99,90]
for i in y :
if i > 66 :
x["k1"].append(i)
if i < 66:
x["k2"].append(i)
print(x)
from collections import defaultdict x = defaultdict(list) y = [11, 22, 33,44,55,66,77,88,99,90] for i in y : if i > 66 : x['k1'].append(i) else : x['k2'].append(i) print(x)
import re ret = re.findall('a', 'eva egon yuan') # 返回所有满足匹配条件的结果,放在列表里 print(ret) #结果 : ['a', 'a'] ret = re.search('a', 'eva egon yuan').group() print(ret) #结果 : 'a' # 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以 # 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 ret = re.match('a', 'abc').group() # 同search,不过尽在字符串开始处进行匹配 print(ret) #结果 : 'a' ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割 print(ret) # ['', '', 'cd'] ret = re.sub('\d', 'H', 'eva3egon4yuan4', 1)#将数字替换成'H',参数1表示只替换1个 print(ret) #evaHegon4yuan4 ret = re.subn('\d', 'H', 'eva3egon4yuan4')#将数字替换成'H',返回元组(替换的结果,替换了多少次) print(ret) obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字 ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串 print(ret.group()) #结果 : 123 import re ret = re.finditer('\d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器 print(ret) # <callable_iterator object at 0x10195f940> print(next(ret).group()) #查看第一个结果 print(next(ret).group()) #查看第二个结果 print([i.group() for i in ret]) #查看剩余的左右结果
注意:
1、findall的优先级查询:
import re ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com') print(ret) # ['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com') print(ret) # ['www.oldboy.com']
2、split的优先级查询
ret=re.split("\d+","eva3egon4yuan") print(ret) #结果 : ['eva', 'egon', 'yuan'] ret=re.split("(\d+)","eva3egon4yuan") print(ret) #结果 : ['eva', '3', 'egon', '4', 'yuan'] #在匹配部分加上()之后所切出的结果是不同的, #没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项, #这个在某些需要保留匹配部分的使用过程是非常重要的。
在很多地方都需要我们输入电话号码比如说注册,验证等等。
那我们写一个代码
phone_number = input('please input your phone number : ')
假如我们随意的在手机号码这一栏输入一个11111111111,它会提示我们格式有误。这个功能是怎么实现的?根据手机号码一共11位并且是只以13、14、15、17、18开头的数字这些特点,我们用python写了如下代码:
while True: phone_number = input('please input your phone number : ') if len(phone_number) == 11 \ and phone_number.isdigit()\ and (phone_number.startswith('13') \ or phone_number.startswith('14') \ or phone_number.startswith('15') \ or phone_number.startswith('17') \ or phone_number.startswith('18')): print('是合法的手机号码') else: print('不是合法的手机号码')
学了今天的知识我们可以这样写:
import re phone_number = input('please input your phone number : ') if re.match('^(13|14|15|17|18)[0-9]{9}$',phone_number): print('是合法的手机号码') else: print('不是合法的手机号码')
这个做法用到了re模块和正则表达式,正则表达式不仅在python领域,在整个编程届都占有举足轻重的地位。
不管以后你是不是去做python开发,只要你是一个程序员就应该了解正则表达式的基本使用。如果未来你要在爬虫领域发展,你就更应该好好学习这方面的知识。 但是你要知道,re模块本质上和正则表达式没有一毛钱的关系。re模块和正则表达式的关系 类似于 time模块(明天学习但是前面用过多次你应该有所了解)和时间的关系 你没有学习python之前,也不知道有一个time模块,但是你已经认识时间了 12:30就表示中午十二点半。 时间有自己的格式,年月日时分秒,12个月,365天......已经成为了一种规则。你也早就牢记于心了。time模块只不过是python提供给我们的可以方便我们操作时间的一个工具而已
正则表达式本身也和python没有什么关系,就是匹配字符串内容的一种规则。
官方定义:正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
在线测试工具:http://tool.chinaz.com/regex/
首先你要知道的是,谈到正则,就只和字符串相关了。在我给你提供的工具中,你输入的每一个字都是一个字符串。其次,如果在一个位置的一个值,不会出现什么变化,那么是不需要规则的。比如你要用"1"去匹配"1",或者用"2"去匹配"2",直接就可以匹配上。这连python的字符串操作都可以轻松做到。那么在之后我们更多要考虑的是在同一个位置上可以出现的字符的范围。
字符组 : [字符组]
在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示
正则
|
待匹配字符
|
匹配 |
说明
|
[0123456789] |
8 |
True |
在一个字符组里枚举合法的所有字符,字符组里的任意一个字符 |
[0123456789] |
a |
False |
由于字符组中没有"a"字符,所以不能匹配 |
[0-9] |
7 |
True |
也可以用-表示范围,[0-9]就和[0123456789]是一个意思 |
[a-z] |
s |
True |
同样的如果要匹配所有的小写字母,直接用[a-z]就可以表示 |
[A-Z] |
B |
True |
[A-Z]就表示所有的大写字母 |
[0-9][a-f][A-F] |
e
|
True
|
可以匹配数字,大小写形式的a~f,用来验证十六进制字符 |
字符:
元字符
|
匹配内容
|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线或汉字 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| \b | 匹配一个单词的结尾 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结 |
| \W |
匹配非字母或数字或下划线或汉字
|
| \D |
匹配非空白符
|
| \S |
匹配非数字
|
| a|b |
匹配字符a或字符b
|
| () |
匹配括号内的表达式,也表示一个组
|
| [...] |
匹配字符组中的字符
|
| [^...] |
匹配除了字符组中字符的所有字符
|
量词:
量词
|
用法说明
|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
. ^ $
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| 海. | 海燕海娇海东 | 海燕海娇海东 | 匹配所有"海."的字符 |
| ^海. | 海燕海娇海东 | 海燕 | 只从开头匹配"海." |
| 海.$ | 海燕海娇海东 | 海东 | 只匹配结尾的"海.$" |
* + ? { }
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| 李.? | 李杰和李莲英和李二棍子 |
李杰 |
?表示重复零次或一次,即只匹配"李"后面一个任意字符
|
| 李.* | 李杰和李莲英和李二棍子 | 李杰和李莲英和李二棍子 |
*表示重复零次或多次,即匹配"李"后面0或多个任意字符
|
| 李.+ | 李杰和李莲英和李二棍子 | 李杰和李莲英和李二棍子 |
+表示重复一次或多次,即只匹配"李"后面1个或多个任意字符
|
| 李.{1,2} | 李杰和李莲英和李二棍子 |
李杰和 |
{1,2}匹配1到2次任意字符
|
注意:前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| 李.*? | 李杰和李莲英和李二棍子 | 李杰 李莲 李二 |
惰性匹配 |
字符集[][^]
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| 李[杰莲英二棍子]* | 李杰和李莲英和李二棍子 |
李杰 |
表示匹配"李"字后面[杰莲英二棍子]的字符任意次
|
| 李[^和]* | 李杰和李莲英和李二棍子 |
李杰 |
表示匹配一个不是"和"的字符任意次
|
| [\d] | 456bdha3 |
4 |
表示匹配任意一个数字,匹配到4个结果
|
| [\d]+ | 456bdha3 |
456 |
表示匹配任意个数字,匹配到2个结果
|
分组 ()与 或 |[^]
身份证号码是一个长度为15或18个字符的字符串,如果是15位则全部由数字组成,首位不能为0;如果是18位,则前17位全部是数字,末位可能是数字或x,下面我们尝试用正则来表示:
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| ^[1-9]\d{13,16}[0-9x]$ | 110101198001017032 |
110101198001017032 |
表示可以匹配一个正确的身份证号 |
| ^[1-9]\d{13,16}[0-9x]$ | 1101011980010170 |
1101011980010170 |
表示也可以匹配这串数字,但这并不是一个正确的身份证号码,它是一个16位的数字
|
| ^[1-9]\d{14}(\d{2}[0-9x])?$ | 1101011980010170 |
False |
现在不会匹配错误的身份证号了 |
| ^([1-9]\d{16}[0-9x]|[1-9]\d{14})$ | 110105199812067023 |
110105199812067023 |
表示先匹配[1-9]\d{16}[0-9x]如果没有匹配上就匹配[1-9]\d{14}
|
转义符 \
在正则表达式中,有很多有特殊意义的是元字符,比如\d和\s等,如果要在正则中匹配正常的"\d"而不是"数字"就需要对"\"进行转义,变成'\\'。
在python中,无论是正则表达式,还是待匹配的内容,都是以字符串的形式出现的,在字符串中\也有特殊的含义,本身还需要转义。所以如果匹配一次"\d",字符串中要写成'\\d',那么正则里就要写成"\\\\d",这样就太麻烦了。这个时候我们就用到了r'\d'这个概念,此时的正则是r'\\d'就可以了。
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| \d | \d | False |
因为在正则表达式中\是有特殊意义的字符,所以要匹配\d本身,用表达式\d无法匹配
|
| \\d | \d | True |
转义\之后变成\\,即可匹配
|
| "\\\\d" | '\\d' | True |
如果在python中,字符串中的'\'也需要转义,所以每一个字符串'\'又需要转义一次
|
| r'\\d' | r'\d' | True |
在字符串之前加r,让整个字符串不转义
|
贪婪匹配
贪婪匹配:在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| <.*> |
<script>...<script> |
<script>...<script> |
默认为贪婪匹配模式,会匹配尽量长的字符串
|
| <.*?> | r'\d' |
<script> |
加上?为将贪婪匹配模式转为非贪婪匹配模式,会匹配尽量短的字符串
|
.*?的用法
. 是任意字符 * 是取 0 至 无限长度 ? 是非贪婪模式。 何在一起就是 取尽量少的任意字符,一般不会这么单独写,他大多用在: .*?x 就是取前面任意长度的字符,直到一个x出现
练习:
import re ret = re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>") #还可以在分组中利用?<name>的形式给分组起名字 #获取的匹配结果可以直接用group('名字')拿到对应的值 print(ret.group('tag_name')) #结果 :h1 print(ret.group()) #结果 :<h1>hello</h1> ret = re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>") #如果不给组起名字,也可以用\序号来找到对应的组,表示要找的内容和前面的组内容一致 #获取的匹配结果可以直接用group(序号)拿到对应的值 print(ret.group(1)) print(ret.group()) #结果 :<h1>hello</h1>
import re ret=re.findall(r"\d+","1-2*(60+(-40.35/5)-(-4*3))") print(ret) #['1', '2', '60', '40', '35', '5', '4', '3'] ret=re.findall(r"-?\d+\.\d*|(-?\d+)","1-2*(60+(-40.35/5)-(-4*3))") print(ret) #['1', '-2', '60', '', '5', '-4', '3'] ret.remove("") print(ret) #['1', '-2', '60', '5', '-4', '3']
import requests import re import json def getPage(url): response=requests.get(url) return response.text def parsePage(s): com=re.compile('<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>' '.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>',re.S) ret=com.finditer(s) for i in ret: yield { "id":i.group("id"), "title":i.group("title"), "rating_num":i.group("rating_num"), "comment_num":i.group("comment_num"), } def main(num): url='https://movie.douban.com/top250?start=%s&filter='%num response_html=getPage(url) ret=parsePage(response_html) print(ret) f=open("move_info7","a",encoding="utf8") for obj in ret: print(obj) data=json.dumps(obj,ensure_ascii=False) f.write(data+"\n") if __name__ == '__main__': count=0 for i in range(10): main(count) count+=25
思维导图:
预习答案:
import re def func() : """简单输入判断""" while True : msg = input("请输入需要计算的表达式(q:退出):").strip() if msg == "q" : # 退出程序 print("bye-bye") exit() elif len(msg) == 0 : #输入空 continue return msg.replace(" ","") #去空格 def multiply_divide(msg): """ 乘除运算 :param msg: 表达式 :return: 返回计算结果 """ l = '\d+\.*\d*[\*\/]+[\+\-]?\d+\.*\d*' ret = re.search(l, msg) # 匹配乘除号 if not ret : # 乘除号不存在,返回输入的表达式 return msg calculate = re.search(l, msg).group() # 匹配乘除号 if '*' in calculate : # 当可以用乘号分割,证明有乘法运算 a,b = calculate.split('*') # 以乘号作为分割符 value = float(a) * float(b) # 计算乘法 else : a,b = calculate.split('/') # 用除号分割 if float(b) == 0 : # 如果分母为0,则退出计算 print("被除数为0!") exit() value = float(a) / float(b) # 计算除法 # 获取第一个匹配到的乘除计算结果value,将value放回原表达式 a,b = re.split(l, msg, 1) # 分割表达式 msg = "{}{}{}".format(a,value,b) # 将计算结果替换会表达式 return multiply_divide(msg) # 递归表达式 def add_subtract(msg): """ 加减运算 :param msg: 表达式 :return: 返回计算结果 """ l = '\d+\.*\d*[\+\-]{1}\d+\.*\d*' msg = msg.replace('+-', '-') # 替换表达式里的所有'+-' msg = msg.replace('--', '+') msg = msg.replace('-+', '-') msg = msg.replace('++', '+') ret = re.search(l, msg) # 匹配加减号 if not ret : # 如果不存在加减号,则证明表达式已计算完成,返回最终结果 return msg ret = re.search(l, msg).group() if len(ret.split('+')) > 1 : # 以加号分割成功,有加法计算 a,b = ret.split('+') value = float(a) + float(b) # 计算加法 elif ret.startswith('-') : # 如果是已'-'开头则需要单独计算 a,b, part3 = ret.split('-') value = -float(b) - float(part3) # 计算以负数开头的减法 else: a,b = ret.split('-') value = float(a) - float(b) # 计算减法 a,b = re.split(l, msg, 1) # 分割表达式 msg = "{}{}{}".format(a,value,b) # 将计算后的结果替换回表达式,生成下一个表达式 return add_subtract(msg) # 递归运算表达式 def del_bracket(msg): """ 小括号去除运算 :param msg: 表达式 :return: 返回计算结果 """ l = r'\([^()]+\)' if not re.search(l, msg) : # 判断小括号,如果不存在小括号,直接调用乘除,加减计算 ret1 = multiply_divide(msg) ret2 = add_subtract(ret1) return ret2 # 返回最终计算结果 calculate = re.search(l, msg).group() # 如果有小括号,匹配出优先级最高的小括号 calculate = calculate.strip('[\(\)]') # 剔除小括号 ret1 = multiply_divide(calculate) # 计算乘除 ret2 = add_subtract(ret1) # 计算加减 a,b = re.split(l,msg,1) # 将小括号计算结果替换回表达式 msg = "{}{}{}".format(a,ret2,b) # 生成新的表达式 return del_bracket(msg) # 递归去小括号 def get() : while True : msg = func() # 获取到的表达式 ret = del_bracket(msg) # 用函数计算后得出的结果 ret = float(ret) print("表达式计算结果:%s" % ret) get() #1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) ) #此题有多种写法按个人理解

