

18、迭代器和生成器
迭代器和生成器是函数中的一大重点,务必掌握,何为迭代?何为迭代器?
预习:
1、处理文件,用户指定要查找的文件和内容,将文件中包含要查找内容的每一行都输出到屏幕(使用生成器)
2、批量处理文件,用户指定要查找的目录和内容,将本层目录下所有文件中包含要查找内容的每一行都输出到屏幕
本篇导航:
for i in 50: print(i) #运行结果: # Traceback (most recent call last): # File "G:/python/python代码/八月/day2 迭代器生成器/3迭代器.py", line 8, in <module> # for i in 50: # TypeError: 'int' object is not iterable
报错:
TypeError: 'int' object is not iterable
类型报错:'int'对象是不可迭代的 何为迭代?
iterable:可迭代的;迭代的;
可迭代的:从上面代码可以简单分析出能被for循环取值的就是可迭代,那么我们就可以初步总结出可迭代的类型:str、list、tuple、set、dict
可迭代的 ——对应的标志 拥有__iter__方法
print('__iter__' in dir([1,2,3])) #判断一个变量是不是一个可迭代的
可迭代协议
可以被迭代要满足的要求就叫做可迭代协议。可迭代协议的定义非常简单,就是内部实现了__iter__方法。
__iter__方法作用:


l = [1,2,3,4,5] print(l.__iter__()) l_iterator = iter(l) #建议用iter(l) print(set(dir(l_iterator))-set(dir(l))) #结果: #<list_iterator object at 0x000001FDD1B79048> #{'__length_hint__', '__next__', '__setstate__'}
iterator:迭代器;迭代程序
迭代器协议:必须拥有__iter__方法和__next__方法
通过iter(x)得到的结果就是一个迭代器,
x是一个可迭代的对象
在for循环中,就是在内部调用了__next__方法才能取到一个一个的值。
__next__的精髓:
l = [1,2,3,4,5] l_iterator = iter(l) print(l_iterator.__next__()) print(l_iterator.__next__()) print(l_iterator.__next__()) print(l_iterator.__next__()) print(l_iterator.__next__()) next(l_iterator) #==l_iterator.__next__() while True: try: print(next(l_iterator)) except StopIteration: break
如果我们一直取next取到迭代器里已经没有元素了,就会报错(抛出一个异常StopIteration),告诉我们,列表中已经没有有效的元素了。这个时候,我们就要使用异常处理机制来把这个异常处理掉。try_except异常处理机制只做了解,不是本章重点,会面会详细讲解。
判断是否可迭代和迭代器的简洁方法:
from collections import Iterable from collections import Iterator s = 'abc' print(isinstance(s,Iterable)) print(isinstance(s,Iterator)) print(isinstance(iter(s),Iterator))
不管是一个迭代器还是一个可迭代对象,都可以使用for循环遍历
迭代器出现的原因 帮你节省内存
迭代器大部分都是在python的内部去使用的,我们直接拿来用就行了
我们自己写的能实现迭代器功能的东西就叫生成器。
1.生成器函数:常规函数定义,但是,使用yield语句而不是return语句返回结果。yield语句一次返回一个结果,在每个结果中间,挂起函数的状态,以便下次重它离开的地方继续执行
2.生成器表达式:类似于列表推导,但是,生成器返回按需产生结果的一个对象,而不是一次构建一个结果列表
生成器Generator:
本质:迭代器(所以自带了__iter__方法和__next__方法,不需要我们去实现)
特点:惰性运算,开发者自定义
#生成器函数 def func(): print('aaaa') a = 1 yield a #返回第一个值 print('bbbb') yield 12 #返回第二个值 ret = func() #拿到一个生成器 # print(ret) #<generator object func at 0x0000028AE2DA2EB8> print(next(ret)) #取第一个值 print(next(ret)) #取第二个值 print(next(ret)) #取第三个值 会报错 因为没有第三个值 def make_cloth(): for i in range(2000000): yield "第%s件衣服"%i szq = make_cloth() print(next(szq)) print(next(szq)) print(next(szq)) for i in range(50): print(next(szq))
生成器的好处:不会一下子在内存中生成太多数据
其它应用:
import time def tail(filename): f = open(filename) f.seek(0, 2) #从文件末尾算起 while True: line = f.readline() # 读取文件中新的文本行 if not line: time.sleep(0.1) continue yield line tail_g = tail('tmp') for line in tail_g: print(line)
def averager(): total = 0.0 count = 0 average = None while True: term = yield average total += term count += 1 average = total/count g_avg = averager() next(g_avg) print(g_avg.send(10)) print(g_avg.send(30)) print(g_avg.send(5))
def init(func): #在调用被装饰生成器函数的时候首先用next激活生成器 def inner(*args,**kwargs): g = func(*args,**kwargs) next(g) return g return inner @init def averager(): total = 0.0 count = 0 average = None while True: term = yield average total += term count += 1 average = total/count g_avg = averager() # next(g_avg) 在装饰器中执行了next方法 print(g_avg.send(10)) print(g_avg.send(30)) print(g_avg.send(5))
def func(): # for i in 'AB': # yield i yield from 'AB' #等同于上面两行 yield from [1,2,3] g = func() print(next(g)) print(next(g)) print(next(g)) print(next(g))
for i in range(100): print(i*i) l =[i*i for i in range(100)] #列表推导式 print(l) l = [{'name':'v','age':28},{'name':'v'}] name_list = [dic['name'] for dic in l] #列表推导式 print(name_list) l = [{'name':'v1','age':28},{'name':'v2'}] name_list_generator = (dic['name'] for dic in l) #生成器表达式 print(name_list_generator) print(next(name_list_generator)) print(next(name_list_generator)) egg_list=['鸡蛋%s' %i for i in range(10)] #列表推导式 print(egg_list) laomuji = ('鸡蛋%s' %i for i in range(1,11)) #生成器表达式 print(laomuji) print(next(laomuji)) print(next(laomuji))
使用生成器的优点:
1、延迟计算,一次返回一个结果。也就是说,它不会一次生成所有的结果,这对于大数据量处理,将会非常有用。
2、提高代码可读性
#列表解析 sum([i for i in range(100000000)])#内存占用大,机器容易卡死 #生成器表达式 sum(i for i in range(100000000))#几乎不占内存
总结:
1、把列表解析的[]换成()得到的就是生成器表达式
2、列表解析与生成器表达式都是一种便利的编程方式,只不过生成器表达式更节省内存
3、Python不但使用迭代器协议,让for循环变得更加通用。大部分内置函数,也是使用迭代器协议访问对象的。例如, sum函数是Python的内置函数,该函数使用迭代器协议访问对象,而生成器实现了迭代器协议,所以,我们可以直接这样计算一系列值的和
print(sum([1,2,3])) print(sum(range(1,4))) print(sum(x ** 2 for x in range(4))) print(sum([x ** 2 for x in range(4)]))
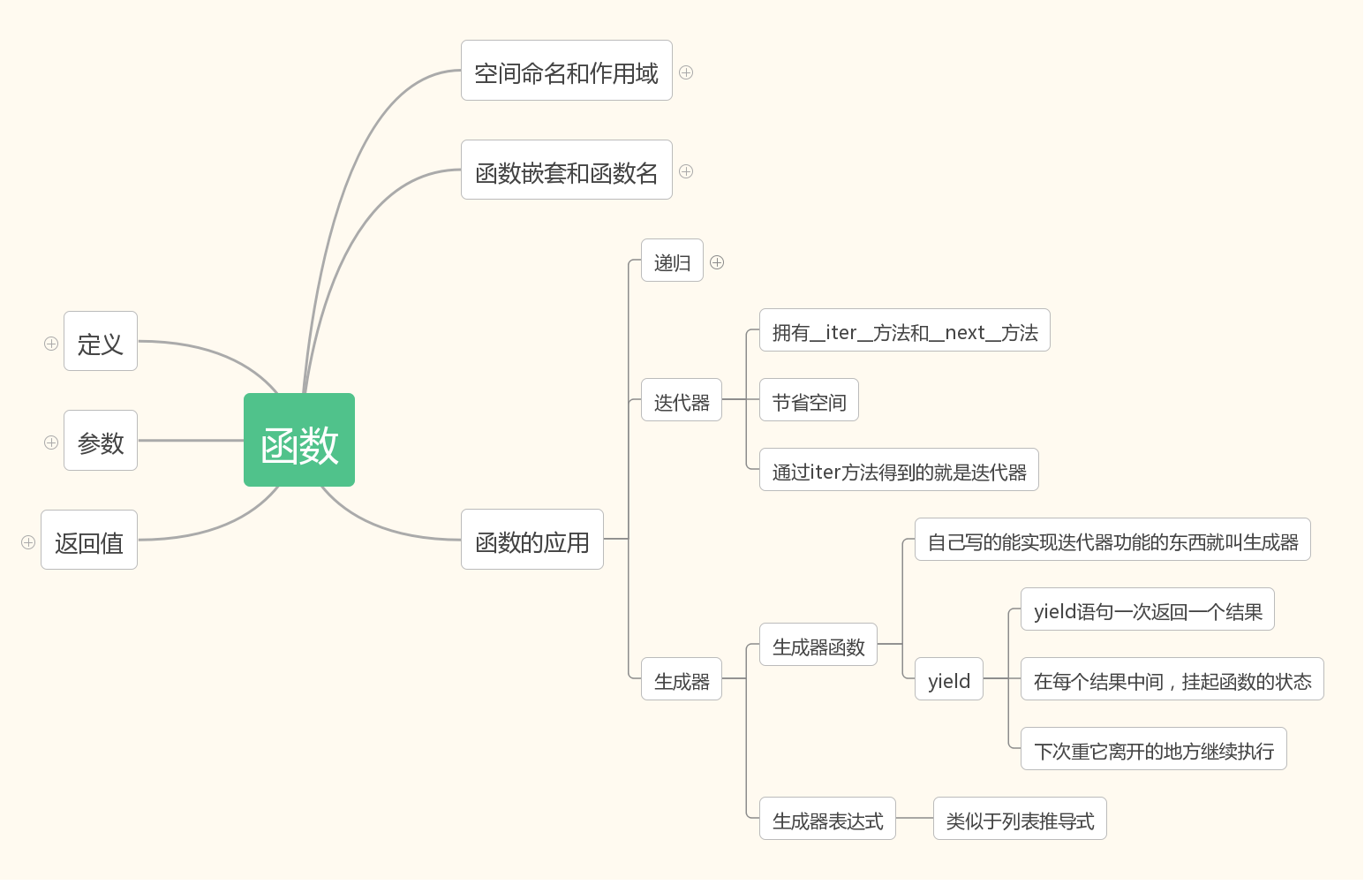
思维导图:
预习答案:
def grep_file(filename,grep_content): f = open(filename) for line in f: if grep_content in line: yield line g = grep_file('tmp_file','python') for line in g: print(line,end='')
def init(func): def inner(*args,**kwargs): g = func(*args,**kwargs) next(g) return g return inner @init #grep_file = init(grep_file) def grep_file(grep_content,printer_g): while True: filename = yield f = open(filename) for line in f: if grep_content in line: printer_g.send(line) @init ##printer = init(printer) 激活print_g def printer(): while True: line = yield if line:print(line,end='') grep_g = grep_file('python', printer()) grep_g.send('tmp_file')
import os def getpath(filepath): g = os.walk(filepath) for par_dir, _, files in g: for file in files: yield par_dir + "\\" + file # 2打开文件对象发给3 def getfile(filepaths): for filepath in filepaths: with open(filepath, encoding="utf-8") as file: yield file # 3读取每一行发给4 def getline(files): for file in files: for line in file: yield line # 4判断pattern发给5 def grep(lines, pattern): for line in lines: if pattern in line: yield line # 5打印文件名 def printname(strings): for string in strings: print(string) filepath = r"F:\Code\Python\LearnPython\Day14 generator" pattern = "jean" printname(grep(getline(getfile(getpath(filepath))), pattern))

