
Javascript 闭包与高阶函数 ( 一 )
上个月,淡丶无欲 让我写一期关于 闭包 的随笔,其实惭愧,我对闭包也是略知一二 ,不能给出一个很好的解释,担心自己讲不出个所以然来。 所以带着学习的目的来写一写,如有错误,忘不吝赐教 。
为什么要有闭包?
初识闭包时,,我一直在想,为什么只有JS有闭包,c#,c++ 为什么没有 ??
1. 封装局部变量
看下面一个例子,计算 斐波那契 数。
为了能够重用数据,一个通用做法就是将计算过的数据缓存起来,但缓存的数据对外是不可见的 。
看下面的 c# 代码 :
public static class Fibonacci{
public static Fibonacci(){
cache[0] = 1;
cache[1] = 1;
}
private static IList<int> cache = new List<int>(1000,-1);
public static int Calc(n){
if(cache[n] != -1){
return cache[n];
}else{
return cache[n] = Calc(n-1) + Calc(n-2);
}
}
}
快两年没写c#了, 很撇脚,囧 ,但是在这类静态语言,这种方法很合适 。
看JS 怎么写
var cache = [1, 1];
var calc = function(){
return cache[n] != undefined ?
cache[n]:
cache[n] = calc(n-1) + calc (n-2);
}
但是在JS中杜绝使用全局变量,所以下面改写
var calc = function(){
return calc.cache[n] != undefined ?
calc.cache[n]:
calc.cache[n] = calc.cache(n-1) + calc.cache (n-2);
}
calc.cache = [1,1];
这里将全局变量作为 calc 的一个属性存储,但是对外可见,无法隐藏 。
就到了闭包大显身手的时候,由于这里 cache 被外部调用,所以可以不被销毁。
var Fibonacci = (function() {
var cache = [1, 1];
return {
calc: function(n) {
return cache[n] != undefined ?
cache[n] :
cache[n] = this.calc(n - 1) + this.calc(n - 2);
}
}
})();
Fibonacci.calc(5); // 8
总结:
在 c# ,c++ 等高级语言中,存在私有变量,所以无需闭包 。但是在JS中,私有变量是一件很麻烦的事情 。这时候,将局部变量放置在一个函数作用域中,可以在内部使用,而外面无法访问。这就形成了闭包 。
2.延续对象生命周期
对于全局变量来说,全局变量的生存周期当然是永久的,除非我们主动销毁这个全局变量。
而对于在函数内用var关键字声明的局部变量来说,当退出函数时,这些局部变量即失去了它们的价值,它们都会随着函数调用的结束而被销毁:
现在来看看下面这段代码:
var func = function(){
var a = 1;
return function(){
a++;
alert ( a );
}
};
var f = func();
f(); // 输出:2
f(); // 输出:3
f(); // 输出:4
f(); // 输出:5
跟我们之前的推论相反,当退出函数后,局部变量a并没有消失,而是似乎一直在某个地方存活着。这是因为当执行 var f=func();时,f返回了一个匿名函数的引用,它可以访问到 func()被调用时产生的环境,而局部变量 a 一直处在这个环境里。既然局部变量所在的环境还能被外界访问,这个局部变量就有了不被销毁的理由。在这里产生了一个闭包结构,局部变量的生命看起来被延续了。
这个特性有时候会很麻烦,但有时候很有用,用来延续局部变量的寿命 。
img 对象经常用于进行数据上报,如下所示:
var report = function( src ){
var img = new Image();
img.src = src;
};
report( 'http://xxx.com/getUserInfo' );
但是通过查询后台的记录我们得知,因为一些低版本浏览器的实现存在bug,在这些浏览器
下使用report函数进行数据上报会丢失30%左右的数据,也就是说,report函数并不是每一次都成功发起了 HTTP请求。 丢失数据的原因是 img 是 report 函数中的局部变量, 当 report 函数的调用结束后,img 局部变量随即被销毁,而此时或许还没来得及发出 HTTP请求,所以此次请求就会丢失掉。
现在我们把 img 变量用闭包封闭起来,便能解决请求丢失的问题:
var report = (function(){
var imgs = [];
return function( src ){
var img = new Image();
imgs.push( img );
img.src = src;
}
})();
高阶函数
闭包在JS中非常广泛,常常与高阶函数作伴 。
高阶函数是指至少下面条件之一的函数
- 函数作为参数传递
- 函数作为返回值输出
函数作为参数传递作为回调函数,应用场景非常广泛,此处不再举例 。
函数作为返回值,这里给出两个例子 。
判断数据类型
'use strict';
var Type = {};
for (var i = 0, type; type = ['String', 'Number', 'Boolean', 'Object'][i++];) {
(function(type) {
Type["is" + type] = function(o) {
return Object.prototype.toString.call(o) === '[object ' + type + ']';
}
})(type);
}
console.log(Type.isString("hh"));

实现单例模式
var getSingle = function(func){
var ret = null;
return function(){
return ret || ret = func.apply(this, Array.prototype.slice.call(arguments));
}
}
var getScript = getSingle(function(){
return document.createElement( 'script' );
});
var script1 = getScript();
var script2 = getScript();
alert ( script1 === script2 ); // 输出:true
高阶函数实现 AOP
AOP(面向切面编程)的主要作用是把一些跟核心业务逻辑模块无关的功能抽离出来,这些
跟业务逻辑无关的功能通常包括日志统计、安全控制、异常处理等。把这些功能抽离出来之后 。再通过“动态织入”的方式掺入业务逻辑模块中。这样做的好处首先是可以保持业务逻辑模块的纯净和高内聚性,其次是可以很方便地复用日志统计等功能模块。
在传统通过on = 为事件注册处理程序中,赋值一个新的处理程序会覆盖掉原来的处理程序,我们可以这么做
var addEvent = function(target,event ,func){
var old;
target[event] = functoin(e){
if(old = target[event]){
old();
}
func();
}
}
通常,在 JavaScript中实现 AOP,都是指把一个函数“动态植入”到另外一个函数之中,具
体的实现技术有很多,本节我们通过扩展 Function.prototype 来做到这一点
Function.prototype.before = function(beforeFn) {
var self = this;
return function() {
beforeFn.apply(this, Array.prototype.slice.call(arguments));
return self.apply(this, Array.prototype.slice.call(arguments));
}
};
Function.prototype.after = function(afterFn) {
var self = this;
return function() {
var ret;
ret = self.apply(this, Array.prototype.slice.call(arguments));
afterFn.apply(this, Array.prototype.slice.call(arguments));
return ret;
}
}
var func = function() {
console.log(2);
}
func = func.before(function() {
console.log(1);
}).after(function() {
console.log(3);
})
func();
输出 1 2 3 。
return 后的函数中的this 取决于真实环境的this ,因为返回的是一个独立的函数 。
高阶函数的其他应用
函数柯里化
currying又称部分求值。一个currying的函数首先会接受一些参数,接受了这些参数之后,该函数并不会立即求值,而是继续返回另外一个函数,刚才传入的参数在函数形成的闭包中被保存起来。待到函数被真正需要求值的时候,之前传入的所有参数都会被一次性用于求值。
看下面一个例子
func(1); 1
func(1)(2); 2
func(1)(2)(3); 6
...
这个例子就是函数柯里化的典型应用,重点考察闭包和高阶函数,也是一道比较常见的面试题
看下面的解法 。
'use strict';
var curry = (function() {
var data = [1];
var func = function(n) {
data.push(n);
return func;
}
func.valueOf = function() {
var ret = data.reduce(function(a, b) {
return a * b;
})
data = [1];
return ret;
}
return func;
})();
console.log(curry(1));
console.log(curry(1)(2));
console.log(curry(1)(2)(3));
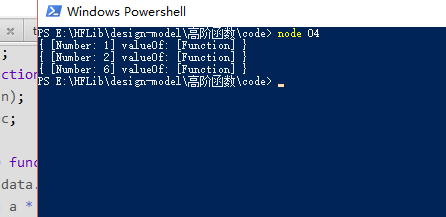
在上面的解法中,我们将函数柯里化和数据计算放在一起,违背了单一职责原则 。现在,我们可以专门定义一个函数,用于对参数进行柯里化。
'use strict';
var curry = function(fn) {
var args = [];
var ret = function(n) {
args.push(n);
return ret;
}
ret.valueOf = function() {
var ret = args.reduce(fn);
args = [];
return ret;
}
return ret;
}
var func = curry(function(a, b) {
return a * b;
})
console.log(func(1));
console.log(func(1)(2));
console.log(func(1)(2)(3));
如果有错误,希望不吝赐教 ~
注: 这篇随笔的一些例子代码来自于 《JavaScript 设计模式与实践 》 ,书中非常详细并深入讲解了JavaScript 高级和 17 种设计模式,对于JavaScript提高非常有帮助 。安利 ~ 。 想要电子版可以给我发邮件: mymeat@126.com
转载请说明原文出处:http://www.cnblogs.com/likeFlyingFish/p/6421615.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号