

simhash算法原理
谷歌通过simhash算法来对重复的网页进行去重,因此产生了simhash算法
simhash算法主要是针对长文本的相似度,节省时间而创立的
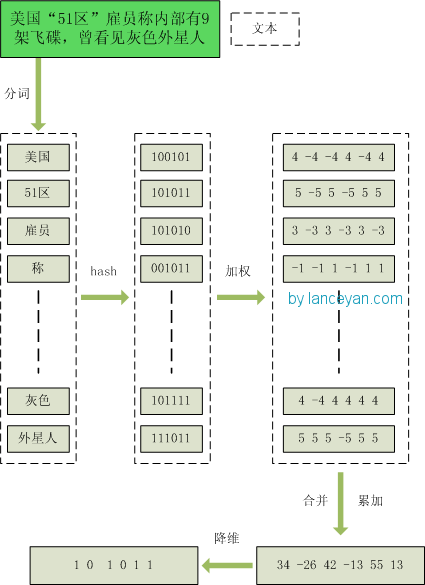
算法主要分为五步:
1.分词 对文本分词,提取特征词并计算tfidf值;
2.哈希 对特征词进行哈希编码,比如把一个词“X”变为100001的方式,
3.加权 乘以它的权重,假如X的权重为5,则X的编码为5 -5 -5 -5 -5 5;
4.合并 把同一个文本的所有的特征词的向量进行相加最终形成一个的向量,比如(5 -5 -5 -5 -5 5) 加上 (-4 4 4 -4 -4 4)等于(1 -1 -1 -9 -9 9)
5.降纬 把合并之后的向量转化为01向量,每一个大于0的记为1,小于0的记为0,则上述向量变为1 0 0 0 0 1
为每一个文本生成一个哈希编码后,对后来的文章进行比较,通过比较两个哈希编码中按位取异或(也叫海明距离),如果结果小于3(这个数值是大家试验出来的),则认为两篇文本相似。

