Java之集合(八)HashMap
转载请注明源出处:http://www.cnblogs.com/lighten/p/7338372.html
1.前言
本章介绍Java中最常用的一个集合类HashMap,此类在不同的JDK版本有不同的实现,目的就是为了优化其效率。本章依旧是基于JDK8的HashMap进行讲解,其与JDK7有极大的区别,从代码量上来说,JDK8的实现超过2千行,JDK7为1千行。因此,本章只介绍HashMap的实现原理,其它的略讲。
注意:红黑树图画的有点问题,线的颜色不对,之前理解的不到位,如果看晕了可以看TreeMap中的介绍,比这里要清楚一些。左旋右旋操作还是看这篇文章。图不改了。
2.HashMap
HashMap实现了Map接口,其数据结构是Hash表。该类与HashTable十分相似,就两点不一样:1.线程不安全;2.允许键或值为null。HashMap不保证map中的次序,特别是不保证次序永远相同。HashMap提供常量时间性能的基本操作get和put。迭代器遍历的效率与HashMap的容量和Size相关,所以不要设置初始容量过大(或者load factor太小)。
HashMap有两个参数会影响其性能:初始容量大小和载入因子(load factor)。初始容量大小指的是Hash桶的大小。载入因子是来衡量hash表在其容量增加之前允许达到的完整度。当hash表中的实体数量超过了载入因子和当前容量,hash表就会刷新,新的hash表将会是hash桶的2倍数量。通常载入因子设置成0.75,这个会达到一个良好了时间和空间性能。超过这个值会减少空间开销,但是会增加查询开销。设置初始容量的时候需要考虑map中将容纳的数量和map的载入因子,这样可以最小化刷新的次数。如果初始容量大于最大的实体数/载入因子就不会刷新。可以使用Collections.synchronizedMap(new HashMap(...));来进行同步hashMap。
注意:如果在创建迭代器之后,HashMap的结构改变了,任何情况下迭代器的remove方法都会抛出并发异常。因此迭代器是"fail-fast“的。
JDK8在实现上与JDK7最大的不同在于,当hash桶上的数量过大的时候,会将结构改变成Tree,类似于TreeMap。大部分的桶都使用普通的方法,但是合适的时候会使用TreeNode方法。TreeNode桶可以转换并且像其他的使用一样,并且在数量过多的时候查找效率会得到提升。然而,在绝大部分桶并没有数据过多的时候正常使用,在表格方法中判断tree桶存在会有延迟。
2.1数据结构

DEFAULT_INITIAL_CAPACITY:默认初始化容量,必须是2n,
MAXIMUM_CAPACITY:最大的容量230,必须小于或等于这个值
DEFAULT_LOAD_FACTOR:默认的载入因子0.75f
TREEIFY_THRESHOLD:桶的阈值,超过这个数量会转成Tree。默认8
UNTREEIFY_THRESHOLD:桶的阈值,低于这个数量会转成普通的桶。默认6
MIN_TREEIFY_CAPACITY:hash表最小的容量。必须是4*TREEIFY_THRESHOLD,避免刷新和treeification thresholds的冲突。

数据结构如上图,主要就是一个table和size。HashMap的键值对Entry实现如下:

hash值,键,值和下一个节点。
2.2 方法

这段代码的理解可以参考:这里。下面做一个简单的描述。
这段代码就是一个计算hash值的代码,难以理解的地方在于h^h>>>16。这是一个扰动函数,目的是为了减少碰撞或者说是冲突。上面计算出来的hash值是不能直接使用的,因为int的取值范围太大,不可能放在hash表中(初始容量只有16),所以还需要再做一步取余的操作n&(length-1),这样就可以放入其中了。但是这么处理会有一个麻烦的地方,那就是其值关注了低位的情况(初始容量太小)。高位的数据等同于没用,如果hashCode的值直接使用,而其值的分布范围恰好造成低位近似,就会产生严重的冲突。上面的扰动函数就是用来解决这个问题的。h^h>>>16,整形的长度是32个bits,右移16位正好高低位做异或,得到的值的低位保留了高位的相关信息,使得低位更加随机,减少冲突的产生,更加均匀的分布到hash表中。所给链接也有实验证明,这样操作是能减少冲突的。
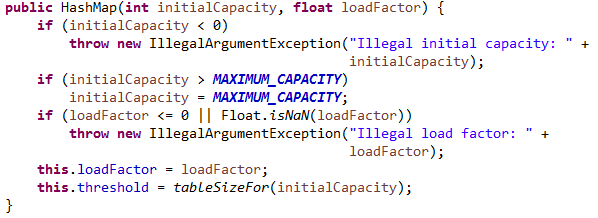
从构造函数可以看出,其并没有初始化hash表,数组table。这个和JDK7所进行的就不一样,其在构造方法中就初始化了hashTable。先看看最常用的两个方法put和get的实现吧。

get方法的就是通过调用getNode方法找到该键值对而已。

这段代码就可以看出其都需要判断一下table有没有初始化,没有就直接返回null。否则就返回该键落在的hash表上的hash桶的第一个节点,比对键值。如果不是就根据是TreeNode还是一般的链表结构继续查找,直到找到或者找完该桶所有元素。

put方法也是先判断表存不存在,不存在就创建,再判断hash表中该位置是否有值,没有值就直接存入。存在就判断这第一个键是否相等,最后才根据onlyIfAbsent来决定是否设置值。如果第一个不相同,就判断是否是TreeNode,再根据其相关方法插入,否则就是一般的桶,遍历到最后一个还不存在就创建,再判断当前数量是否达到转换成Tree结构的阈值。找到了就停止,和之前一样根据onlyIfAbsent来决定是否设置值。
现在来看看resize方法和treeifyBin方法。resize方法太长,就不进行截图了,描述一下进行过程:(1)初始化变量,包括原表,原表长度,和原表要变成的长度。如果原表容量大于0,超过最大值就不改变,返回,小于最大值就新表扩容1倍,新表下次扩容大小也加倍。如果原表容量等于0,但是下次扩容大小大于0,下次扩容大小就是新表大小。如果都不满足,就设置新表大小为默认初始化大小,计算下一个扩容大小。如果下一次扩容大小为0,就通过loadFactor和新表容量计算出大小。(2)根据计算出来的新表大小生成新表(3)如果旧表不为null,遍历旧表,一个个桶遍历过去,放在新表指定位置。(4)返回新表。
2.3 桶的转换
从前面也可以看出,当一个hash桶的数值达到了默认值时,就会转换成树结构。下面深入探讨一下这部分的内容:

上图是一个TreeNode的基本结构,这个树结构是一个红黑树,下面详细介绍一下该内的相关方法,了解一下红黑树的实现方法。

树的根节点查找十分简单,不断的查找父节点就可以了,为null的那个节点就是根节点。

上面方法就是hash表的一个结点的链表达到了转换成树结构阈值的时候的转换方法。可以看到在hash表较小的时候,其先采取的方法是扩容来达到减少结点链表长度的作用。如果不进行扩容,就将结点替换成TreeNode,然后遍历设置前后结点了,hd是头结点,tl是前一个结点,p是当前结点。组成了TreeNode的双向链表头,将头结点放入hash当前位置,然后调用头结点的treeify方法。

上面代码就是将双向链表的TreeNode结点改成Tree结构。这个方法是TreeNode类的方法。从双向链表第一个节点就是当前结点开始,设置成树的根节点。每个进来的结点(遍历的结点)都拿出其键和hash值,然后遍历这棵树(这就是上面代码循环root结点的内容),准备加入已经有序的树中。如果进来的结点的hash值比当前树结点要小,dir为-1(放入结点左边),大于dir为1(放入结点右边),如果相等,且不能通过类的compareTo方法进行比较出结果,就通过System.identityHashCode(a)方法比较,只是为了满足能够比较出差异,而不保证顺序。接下来根据dir判断放入当前节点的左边还是右边,前提其为null,不为null就循环。最后找这个位置,进来的结点父节点就是当前循环的树的结点,dir小于0树的结点左孩子就是进来的结点,大于0就是在右边。
上面的操作可能会破坏红黑树的左右平衡,所以还需要进行平稳的插入。TreeNode的balanceInsertion(root, x)方法来完成,其返回值是根节点。此方法太长,不进行截图,这里描述一下维持红黑树平衡的办法。此方法的入参是上面一步得到的二叉树的根节点root和插入树的当前结点x,此时虽然满足了红黑树的一个特性即左节点<父节点<右节点,但是可能破坏了平衡二叉树的要求,左右子树的深度差距不能超过1。要理解这段代码,标记位red十分重要,其表示红黑树是否红链接。红链接的含义是将其和其左节点看做是同一个节点,此为2-3树的原理。这里提供一个具体的参考博客,再来看Java中的平衡插入步骤就会比较容易了。博客:这里。步骤如下:
1.插入节点x先被设置成红链接,其的父节点xp为null,证明插入节点是root节点,返回x根节点。
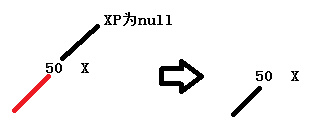
2.xp不是红链接,或者父节点xp的父节点xpp为null,不需要调整,直接返回root节点。
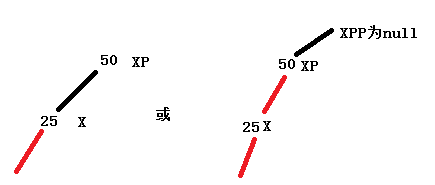
这两种情况都是返回root节点,一个新入的X结点都是先设置成红链接,再不断上移,和2-3树那篇文章的顺序是反的。
3.判断插入的x是在父父节点xpp的左边,到了这一步肯定是因为xp是红链接,且xpp不为null:
①xpp节点右边xppr不为null,且xppr是一个红链接。这种情况xppr分裂,xp也不会是红链接,但是xpp变成了红链接。当前结点变成了xpp节点。
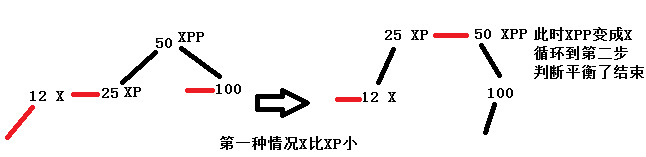
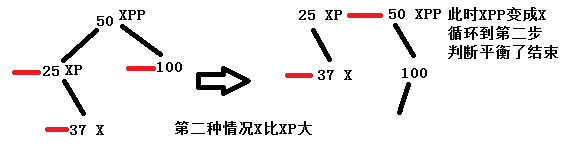
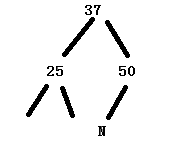
上面两种情况都差不多,最终会变成XPP成为X节点,重新进入循环,然后满足第2部,返回root节点50,从图中也可以看出,此时左右树的深度是达到了平衡。
②x是xp的右节点,x变成xp,进行左旋转。重新赋值xp和xpp。如果xp不为null,xp变成非红链接。此时xpp不为null,xpp是一个红链接,进行左旋转。
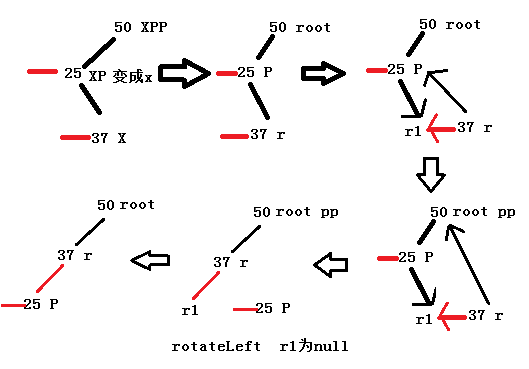
上图是第一次左旋操作,可以看出37和25的位置对调了一下,而此时X是P,XP是不为null,且XPP也是不为null的,此时需要进行右旋转:

这样就可以看出形状从最初的不平衡,变成了最后的平衡状态。
4.x是父父节点xpp的右边,这个步骤的逻辑和3是一样的,只是换了方向而已,不再给出图解:
①如果xppl不为null且是红链接,拆分成不是红链接,xp也不是红链接,xpp变成红链接,当前结点变成xpp。
②x是xp的左节点,x变成xp进行右旋转,重新赋值xp和xpp。再判断xp是否为null,不是null,xp变成非红链接,但是如果xpp不为null,那么xpp是一个红链接,进行左旋转。
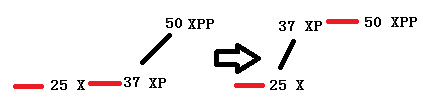
左右旋转是为了插入和删除的时候保持二叉树的平衡。光看代码和图解,还是比较难以理解,只知道按着代码会变成这个平衡的样子,但是不知道为何这样操作会保持平衡(上图解并没有给出全部的可能性)。其实左旋转和右旋转并不是很难理解,听其名字就可见一二。下面以左旋为例进行详细介绍,右旋其实是一样的。
上面这个图形肯定是不平衡的,而简单的平衡方法就是以25为父节点,左旋转一圈变成
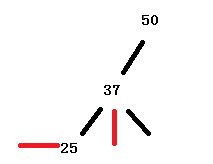
一般想象旋转,肯定就是这样子的了。但是问题就出来了,37的旋转会产生冲突,所以Java的那段难以理清的代码,就是为了解决这个冲突的。

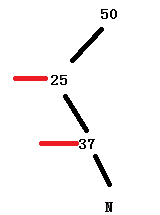
这里的p就是要旋转的顶点了。如果P不存在或者没有右节点,那就旋转不了。第一个if就是解决P的右节点存在左节点,这个左节点就是p的右节点了,从图也可以看出数值的排序是37的左是会大于P 25的左的,所以放在P的右边。第二个if就是用右节点替换掉P节点,作为顶点,此时如果该顶点的父节点为null,意味着一开始这个订单就是root顶点,需要替换root,改变红链接,如果该顶点的父节点不为null,左旋的结点就不是根节点,要重新绑定其子节点:左节点等于P的时候,变成r,否者就是右节点变成r(左旋是发生在父节点的左边还是右边的区别)。然后把p绑定在r上。

最后结果如上,由于XPP还存在,所以需要以XPP右旋,右旋的逻辑不再叙述,和左旋一样,最后的结果(没有再仔细处理红链接):
3. 后记
HashMap本想给出整个流程图的,但是想了想必要性不大。hash表的结构和使用应该都不是什么难点,唯一复杂的就是JDK8的转成红黑树的部分,本文也着重介绍了这部分的内容,也就不再进行画图了。HashMap中其它的内容也不会难以看懂,就不再进行介绍了,有了上面的解析,再看HashMap也不会一脸迷茫。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号