Java之IO(九)其它字节流
转载请注明源出处:http://www.cnblogs.com/lighten/p/7063161.html
1.前言
之前的章节已经介绍了java的io包中所有成对(输入、输出对应)的字节流,本章介绍剩余的一些字节流,包括:LineNumberInputStream、SequenceInputStream、StringBufferInputStream。在JDK8的版本中,只有中间的SequenceInputStream没有被废弃,其它两个都被指出已废弃了。
2.LineNumberInputStream
这个输入流通过添加函数功能,能保持对输入流的行数的追踪。行号从0开始,每次增加1。顺便说一下,这个类是在JDK1.0就存在了。被废弃的原因在类的注释中也给出了:这个类错误地假设bytes能够足够表示characters。在JDK1.1中,也就是此类后面的版本,更好的方式来操作字符流就是创建一个新的字符流,这个流中包含了一个用于计算行号的类。这也就是在JDK1.1中出现的LineNumberReader,此节不讲,是字符流的内容。
LineNumberInputStream继承于FilterInputStream,类结构如下:
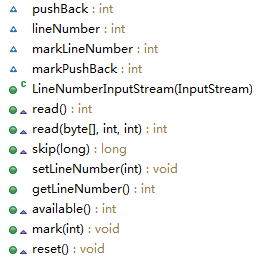
可以看出,对于抽象父类InputStream,其多了set和get行号的两个方法。下面先看基本的数据流的方法实现。

之前看的结构图有四个变量,两个一组应该很好理解,mark开头的主要是让Inputstream的mark()方法使用,记录一下。lineNumber就是记录的行号了,pushBack有什么作用呢?看上图的read逻辑。pushBack默认情况下为-1,-1的时候就读取一个,不是-1的时候就返回这个暂存的值。读取一个字节会判断其是否是\n,是行号就直接加1了,如果是\r,就让pushBack再读一个,如果是\n就重置为-1。这段写的很绕,通俗的说就是:read()方法是读取一个字节,我们都知道流读取了就不能再读取,但是判断换行符的时候就麻烦了,\r的时候需要判断一下下一个是否是\n,所以需要再读取一个字节,这个时候就要保存一下这个字节了,就存在pushback中,pushback一般都是-1,意味着直接读一个就可以了,不是-1的时候就是说之前判断的是\r,但下一个不是\n,所以保存了一下这个非\n的字符,本次就直接返回了。上面有一个坑的地方,其判断了\r之后就还会执行\n,因为没有break。这会造成下例效果:
@Test
public void test() throws IOException {
ByteArrayInputStream bais = new ByteArrayInputStream("123\r\t\n456\r\n789\r\n".getBytes());
LineNumberInputStream lnis = new LineNumberInputStream(bais);
byte[] buffer = new byte[1024];
ByteArrayOutputStream baos = new ByteArrayOutputStream();
int length;
while((length = lnis.read(buffer)) != -1) {
baos.write(buffer, 0, length);
}
System.out.println(new String(baos.toByteArray()));
System.out.println(lnis.getLineNumber());
}

多出现了一个空行。实际上面确实\r\t\n,这个产生了两个回车,实际上直接输出也是两个回车。(-。-)!!!可能废弃的真正原因就如上所说的byte不能表示所有的字符吧。
3.SequenceInputStream
一个SequenceInputStream表示其他输入流的逻辑连接。它从一个有序的输入流开始,从第一个开始直到到达文件的末尾,然后从第二个文件中读取,以此类推,直到最后一个包含的输入流到达文件的末尾。
这个流很简单,结构如下:

就是接受了一组有序的输入流,读取的时候,一个个读到为罢了。

像接力棒一样,读完一个又接一个,知道全部读取完毕。
@Test
public void test2() throws IOException {
ByteArrayInputStream bais = new ByteArrayInputStream("你好".getBytes());
ByteArrayInputStream bais2 = new ByteArrayInputStream(",张三".getBytes());
SequenceInputStream sis = new SequenceInputStream(bais, bais2);
byte[] buffer = new byte[1024];
ByteArrayOutputStream baos = new ByteArrayOutputStream();
int length;
while((length = sis.read(buffer)) != -1) {
baos.write(buffer, 0, length);
}
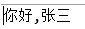
System.out.println(new String(baos.toByteArray()));
}
4.StringBufferInputStream
这个流也是一个废弃的方法,其理由是:这个类不能正确地将字符转换成字节。在JDK 1.1中,从字符串创建流的首选方法是通过StringReader类。
这个类允许应用程序创建一个输入流,其中读取的字节是由字符串的内容提供的。应用程序还可以使用ByteArrayInputStream从字节数组中读取字节。这个类只使用字符串中每个字符的低8位。结构也很简单:

buffer就是缓存的字符串,count就是这个字符串的长度了。read()方法就是将字符串按字节读取:

官方虽然给出了这两个流被废弃的原因,就是字符和字节之间的转换问题,但是个人还是不明白哪里会出问题,对编码还是所知甚少,目前最大的困惑就是所有的流都是以-1为结束标志符,C语言的文件流EOF也是-1,为什么不怕中间有个字节正好是-1呢?这里有篇文章说了一下这个问题:http://blog.csdn.net/jkler_doyourself/article/details/5645925。没有完全理解,但是-1是0xFFFFFFFF,而很多流读取的时候都&0xFF,测试如下:
@Test
public void test3() {
byte[] a = new byte[]{-1};
ByteArrayInputStream bis = new ByteArrayInputStream(a);
System.out.println(bis.read());
}
-1读出来是255。问题的根本在于并不是说读取到-1,主要的判断还是是否结束了,即再取值是否能取到,或者是已知其是否结束。这个方法才是判断流是否结束了,返回-1。而其它情况&0xFF之后就不会表现成-1了,-1是0xFFFFFFFF。这也是一个比较重要的手段。当然实际上值并没有改变,因为你再强转成byte又回到了-1,这里返回int也就规避了这个问题,取了int的0~255范围,所以你能够通过使用read()!=-1来判断结尾,再通过强转回byte变成原有的值。我个人是这么理解的。如有错误,请指教一下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号