

1、开启map端输出文件的合并机制
1.1 为什么要开启map端输出文件的合并机制
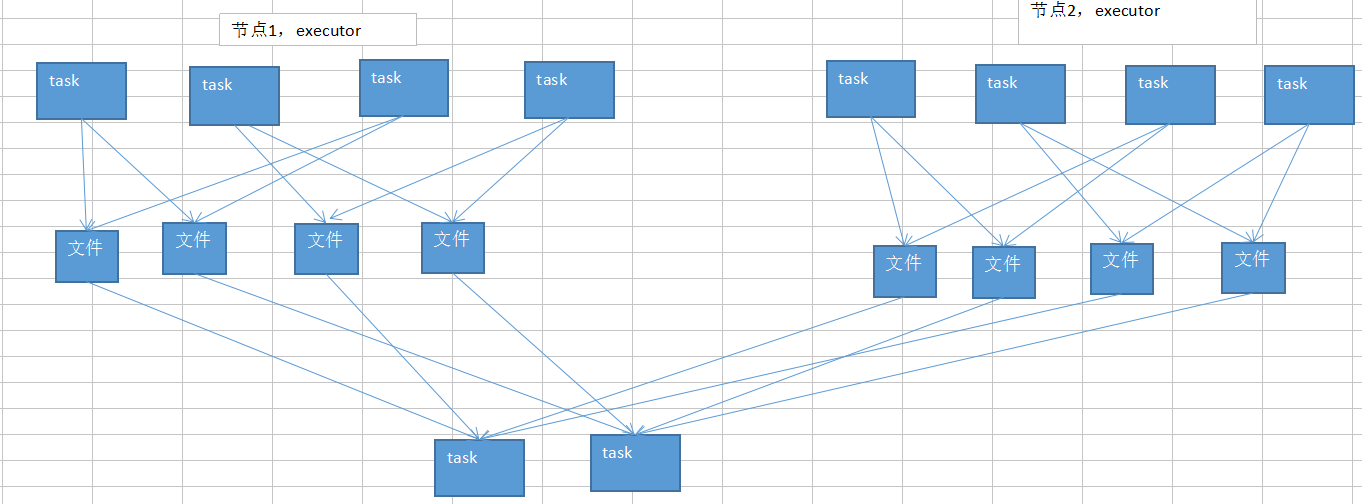
默认情况下,map端的每个task会为reduce端的每个task生成一个输出文件,reduce段的每个task拉取map端每个task生成的相应文件

开启后,map端只会在并行执行的task生成reduce端task数目的文件,下一批map端的task执行时,会复用首次生成的文件
1.2 如何开启
//开启map端输出文件的合并机制 conf.set("spark.shuffle.consolidateFiles", "true");
2、调节map端内存缓冲区
2.1 为什么要调节map端内存缓冲区
默认情况下,shuffle的map task,输出的文件到内存缓冲区,当内存缓冲区满了,才会溢写spill操作到磁盘,如果该缓冲区比较小,而map端输出文件又比较大,会频繁的出现溢写到磁盘,影响性能。
2.2 如何调整
//设置map 端内存缓冲区大小(默认32k) conf.set("spark.shuffle.file.buffer", "64k");
3、调节reduce端内存占比
3.1 为什么要调节reduce端内存占比
reduce task 在进行汇聚,聚合等操作时,实际上使用的是自己对应的executor内存,默认情况下executor分配给reduce进行聚合的内存比例是0.2,如果拉取的文件比较大,会频繁溢写到本地磁盘,影响性能。
3.2 如何调整
//设置reduce端内存占比 conf.set("spark.shuffle.memoryFraction", "0.4");
4、修改shuffle管理器
4.1 有哪些shuffle管理器
HashShuffleManager:1.2.x版本前的默认选择
SortShuffleManager:1.2.x版本之后的默认选择,会对每个task要处理的数据进行排序;同时,可以避免像HashShuffleManager那么默认去创建多份磁盘文件,而是一个task只会写入一个磁盘文件,不同reduce task需要的的数据使用offset来进行划分。
tungsten-sort(钨丝):1.5.x之后的出现,和SortShuffleManager相似,但是它本事实现了一套内存管理机制,性能有了很大的提高,而且避免了shuffle过程中产生大量的OOM、GC等相关问题。
4.2 如何选择
4.2.1 如果不需要排序,建议使用HashShuffleManager以提高性能
4.2.2 如果需要排序,建议使用SortShuffleManager
4.2.3 如果不需要排序,但是希望每个task输出的文件都合并到一个文件中,可以去调节bypassMergeThreshold这个阀值(默认为200),因为在合并文件的时候会进行排序,所以应该让该阀值大于reduce task数量。
4.2.4 如果需要排序,而且版本在1.5.x或者更高,可以尝试使用tungsten-sort
4.3 在项目中如何使用
//设置spark shuffle manager (hash,sort,tungsten-sort) conf.set("spark.shuffle.manager", "tungsten-sort"); //设置文件合并的阀值 conf.set("spark.shuffle.sort.bypassMergeThreshold", "550");

