大规模数据爬取 -- Python
Python书写爬虫,目的是爬取所有的个人商家商品信息及详情,并进行数据归类分析
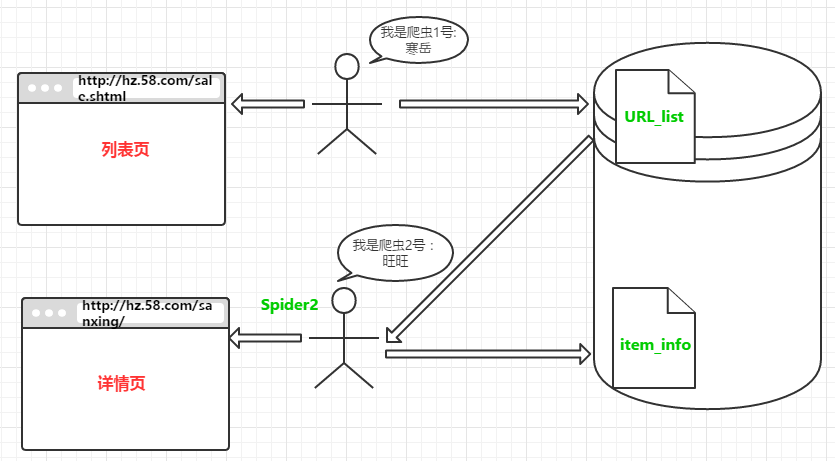
整个工作流程图:
第一步:采用自动化的方式从前台页面获取所有的频道
from bs4 import BeautifulSoup import requests #1、找到左侧边栏所有频道的链接 start_url = 'http://hz.58.com/sale.shtml' url_host = 'http://hz.58.com' def get_channel_urls(url): wb_data = requests.get(start_url) soup = BeautifulSoup(wb_data.text,'lxml') links = soup.select('ul.ym-mainmnu > li > span > a["href"]') for link in links: page_url = url_host + link.get('href') print(page_url) #print(links) get_channel_urls(start_url) channel_list = ''' http://hz.58.com/shouji/ http://hz.58.com/tongxunyw/ http://hz.58.com/danche/ http://hz.58.com/diandongche/ http://hz.58.com/diannao/ http://hz.58.com/shuma/ http://hz.58.com/jiadian/ http://hz.58.com/ershoujiaju/ http://hz.58.com/yingyou/ http://hz.58.com/fushi/ http://hz.58.com/meirong/ http://hz.58.com/yishu/ http://hz.58.com/tushu/ http://hz.58.com/wenti/ http://hz.58.com/bangong/ http://hz.58.com/shebei.shtml http://hz.58.com/chengren/ '''
第二步:通过第一步获取的所有频道去获取所有的列表详情,并存入URL_list表中,同时获取商品详情信息
from bs4 import BeautifulSoup import requests import time import pymongo client = pymongo.MongoClient('localhost',27017) ceshi = client['ceshi'] url_list = ceshi['url_list'] item_info = ceshi['item_info'] def get_links_from(channel,pages,who_sells=0): #http://hz.58.com/shouji/0/pn7/ list_view = '{}{}/pn{}/'.format(channel,str(who_sells),str(pages)) wb_data = requests.get(list_view) time.sleep(1) soup = BeautifulSoup(wb_data.text,'lxml') links = soup.select('td.t > a[onclick]') if soup.find('td','t'): for link in links: item_link = link.get('href').split('?')[0] url_list.insert_one({'url':item_link}) print(item_link) else: pass # Nothing def get_item_info(url): wb_data = requests.get(url) soup = BeautifulSoup(wb_data.text,'lxml') no_longer_exist = '商品已下架' in soup if no_longer_exist: pass else: title = soup.title.text price = soup.select('span.price_now > i')[0].text area = soup.select('div.palce_li > span > i')[0].text #url_list.insert_one({'title':title,'price':price,'area':area}) print({'title':title,'price':price,'area':area}) #get_links_from('http://hz.58.com/pbdn/',7) #get_item_info('http://zhuanzhuan.58.com/detail/840577950118920199z.shtml')
第三步:采用多进程的方式的main主函数入口
from multiprocessing import Pool from channel_extract import channel_list from page_parsing import get_links_from def get_all_links_from(channel): for num in range(1,31): get_links_from(channel,num) if __name__ == '__main__': pool = Pool() pool.map(get_all_links_from,channel_list.split())
第四步:实时对获取到的数据进行监控
from time import sleep from page_parsing import url_list while True: print(url_list.find().count()) sleep(5)
具体运行效果: