
ng-深度学习-课程笔记-13: 目标检测(Week3)
1 目标定位( object localization )
目标定位既要识别,又要定位,它要做的事就是用一个框框把物体目标的位置标出来。
怎么做这个问题呢,我们考虑三目标的定位问题,假定图中最多只出现一个目标,假定图片的左上角为(0,0),右下角为(1,1)。
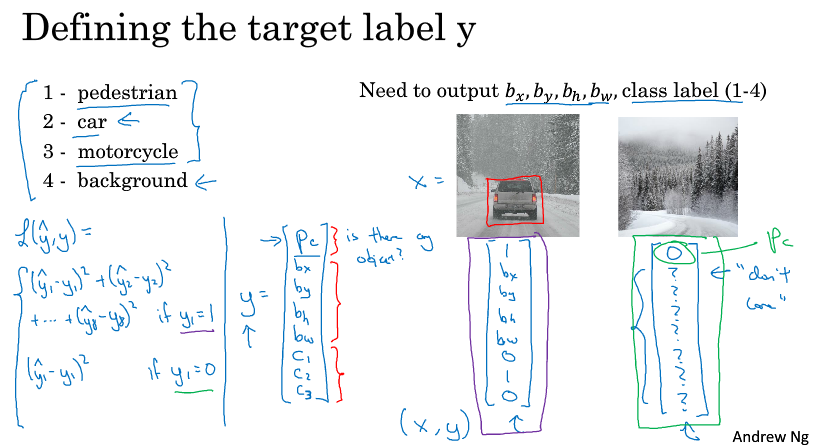
我们输出层的标签有这么几个,pc, bx, by, bh, bw, c1, c2, c3,其中pc表示是否存在目标,c1,c2,c3分别代表三个类别的目标是否存在,(bx, by)表示框框中心点的坐标,bh表示框框高度,bw表示框框宽度。
考虑损失函数,y = 0 时,只考虑pc之间的逻辑回归损失或平方损失都行,因为此时没有目标;
y = 1时,一般对pc采用平方损失或者逻辑回归的损失,对c1, c2, c3采用softmax的损失,对bx, by, bh, bw采用平方损失。
2 特征点检测( landmark detection )
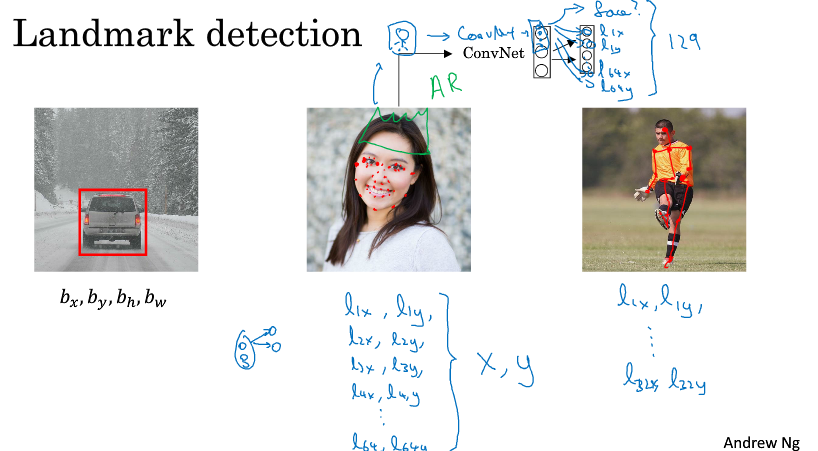
假如你想标记出人脸中的特征位置(比如眼睛),对于神经网络的输出单元,首先有个face表示是否有人脸,然后是一系列的特征点的坐标,比如l1x, l1y, l2x, l2y, l3x, l3y, l4x, l4y表示四个特征点,表示左眼的外眼角和内眼角,右眼的外眼角和内眼角。
当然要训练这个网络,必须有标签好的数据,一般都是人为辛苦标注的。
这个检测脸部特征模块,是一个识别脸部表情的基本模块,也是计算机图形效果(比如实现头戴皇冠,脸部扭曲)的一个关键模块。
如果你对人体姿态检测感兴趣的话,也是使用类似上述的方法,先检测出人体姿态的关键特征点。
3 目标检测( object detection )
比如我们想做一个汽车的目标检测,首先先构建一个数据集,输入图像,输出图像是否为汽车,注意有汽车的图像中汽车要尽量占满整个画布且在正中央。
用这个数据集训练一个卷积神经网络,能够预测图像中是否为汽车。
然后可以利用滑动窗口的技术,先用小窗口,对新来的图像用窗口截取一段用网络判断是否为汽车,依次滑动窗口进行判断,对每个位置用0和1标记,直到滑过图像的每一个角落。然后增大窗口,重复操作,再增大一点窗口,重复操作。
滑动窗口的缺点就是计算成本太高,每次滑动都要用卷积来计算一次,这样滑动太慢了。
如果滑动stride小,则计算量大;如果stride大,可能无法准确定位到目标。
4 滑动窗口的卷积实现( Convolutional implementation of sliding windows )
事实上,我们不用像上一节中那样,自己去滑动窗口截取图片的一小部分然后检测,卷积这个操作就可以实现滑动窗口。
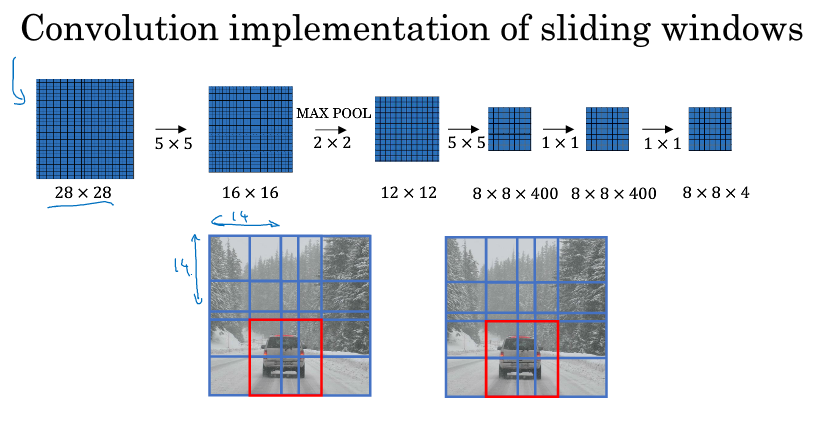
如下图中间一行卷积的初始图,我们假设输入的图像是16*16的,而窗口大小是14*14,我们要做的是把蓝色区域输入卷积网络,生成0或1分类,接着向右滑动2个元素,形成的区域输入卷积网络,生成0或1分类,然后接着滑动,重复操作。我们在16*16的图像上卷积了4次,输出了4个标签,我们会发现这4次卷积里很多计算是重复的。
而实际上,直接对这个16*16的图像进行卷积,如下图中间一行的卷积的整个过程,这个卷积就是在计算我们刚刚提到的很多重复的计算,过程中蓝色的区域就是我们初始的时候用来卷积的第一块区域,到最后它变成了2*2的块的左上角那一块,我们可以看到最后输出的2*2块,刚好就是4个输出,对应我们上面说的输出4个标签。
这两个过程刚好可以对应的上。所以我们不需要把原图分成四个部分,分为用卷积去检测,而是把它们作为一张图片输入给卷积网络进行计算,其中的公有区域可以共享很多计算。

我们不用依靠连续的卷积操作来识别图片中的汽车,我们可以对整张图片进行卷积,一次得到所有的预测值,如果足够幸运,神经网络便可以识别出汽车的位置。
5 边界框预测( Bounding box prediction )
上一节的算法有一个缺点,就是边界框(bounding box)的位置可能不够准确,例如,可能你的框没有完美地框中汽车,而是框中了四分之三的样子。
其中一个能得到更精准的边界框的算法就是YOLO算法,YOLO的意思是you only look once。
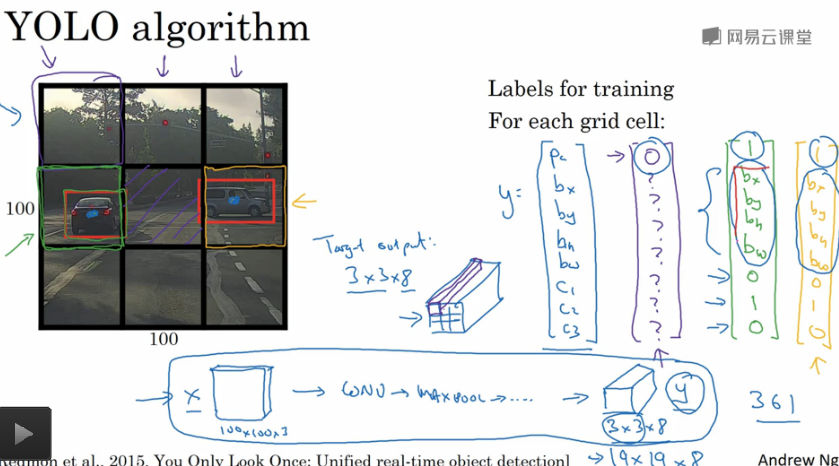
怎么做的呢?假设我们的图像是100*100,我们在图像上放上3*3=9的网格(用3*3是为了介绍简单,实际实现会更精细,比如19*19)。
基本思路就是逐一在9个格子里使用目标定位。对于没有目标的格子,它的标签y就是pc为0,没啥好说的;
对于某个有目标的格子,按目标定位的方法贴上标签。需要注意的是,yolo会把目标分配到包含对象中点的那个格子里,所以如果车子的边缘跑到别的格子去了,我们会忽视那些边缘。
因为我们的标签有8个分量(参见前面说过的目标定位),所以最终的标签的shape是3*3*8。
我们要训练的卷积神经网络就是输入100*100*3的图像,输出3*3*8的标签。这样我们就可以得到精准的边界框了。
这个算法能够得到更准确的边界框而不用受限于滑动窗口的步长;其次这是一个卷积实现,我们并没有在9块区域跑9次算法,而是直接对整张图进行卷积的训练,因为在各个格子里的很多计算步骤是可以共享的。所以这个算法效率很高。
另外有个细节,关于bx, by, bh, bw,我们说格子左上角是(0, 0),右下角是(1, 1),那么这四个参数可以认为是在格子中占的比例大小,bx, by是(0,1)的,而bh, bw可能大于1,因为可能目标太大占了几个格子,指定边界框的方式有很多,这种约定是比较合理的。
6 交并比( Intersection over union)
交并比函数IoU是用来评判目标检测是否准确的,它做的就是计算预测边框和实际边框的交集和并集的比。
一般IoU大于等于0.5就说明检测正确,如果你希望严格点,可以定为0.6或0.7。
7 非极大值限制( Non-max suppression)
之前讲的yolo算法中,有个问题就是当一辆汽车占了很多个格子的时候,很多格子都会觉得它里面有辆车,所以算法可能会对同一对象做多次检测。
非最大值限制做的就是清理这些检测结果,使每个对象只被检测一次。具体怎么做,我们先假设目标只有一个,汽车,那么标签变成5个( pc, bx, by, bh, bw )
把图片分成19*19格子,对每一格子如果pc<=0.6,则丢弃,认为它不包含汽车。
对于剩下的格子,选择概率pc最高的框框,然后把跟这个框框的IoU很高(比如说>=0.5)的框框抑制;
然后再找概率最高的框框,接着把IoU(重叠)很高的框框抑制;
以此类推,最后把抑制的框框都去掉,这就是非最大值抑制。如果尝试同时检测三个目标的话,就对三个类独立地进行非最大值抑制。
8 Anchor Boxes
Anchor Boxes是处理一个格子出现多个目标的手段。
如下图所示,人和车重叠在了一起,这个时候可以预先定义不同形状的anchor box,这个例子中我们定义两个anchor box。
然后标签也变成原来的2倍,分别表示2个box:[ pc, bx, by, bh, bw, c1, c2, c3, pc, bx, by, bh, bw, c1, c2, c3 ]
对于第一个box,行人的形状,用标签的前8个表示,这里所有的参数都和检测行人有关。
对于第二个box,汽车的形状,用标签的后8个表示,这里所有的参数都和检测汽车有关。
之前,训练的每一个目标,都分配到包含中点的格子里。
现在,训练的每一个目标,都分配到(包含中点的格子,和目标IoU最高的anchor box)里。
如果你有2个anchor但是格子出现了3个目标,这种情况算法并没有很好的处理办法,但执行了默认的手段就是把两个对象放在一个格子里且它们的anchor是一样的,希望你的数据集不会出现这种情况。
如何选择anchor呢,人们一般手工指定anchor的形状,你可以选择5-10个anchor box覆盖多种不同的形状,涵盖你想要检测的对象的各种形状。
后期YOLO论文有更好的做法,用k-menas将两类对象的形状进行聚类,用它来选择一组anchor box。

9 yolo算法( yolo algorithm )
先根据上面讲述的内容,给训练样本贴好相应的标签,然后训练,预测。
最后要做非最大值抑制,步骤如下。
(1) 如果anchor box有两个,那么对于每个格子都会得到有两个边界框;
(2) 抛弃概率低的框框;
(3) 假设我们要预测三个目标,那么对每一个类,单独用非最大值抑制去得到最后的预测框框。
10 候选区域( Region proposals )
候选区域用的比较少,但是这个概念在计算机视觉领域的影响力很大,是个很有趣的想法。
我们之前讲的滑动窗口,它可能会在显然没有任何对象的区域上运算,这很没意义。
针对这个,有人提出了R-CNN,带区域的卷积网络,这个算法尝试选出一些区域,在这些区域上运行卷积网络分类器是有意义的。
选出候选区域的方法是运行图像分割算法,找一些色块,在这些色块上做卷积得到特征,然后(SVM)分类。
R-CNN运行还是挺慢的,所以有一系列的研究工作去改进这个算法。
比如Fast R-CNN,用了卷积(实现的滑动窗口)来进行分类,提高了速度,但是它得到候选区的速度还是挺慢的。
所以又提出了Faster R-CNN,用卷积去来获得候选区域色块,结果比Fast快很多。


