

SQL语句之表操作
SQL语句系列
写在前面
在上一篇博文里面我整理了“行”级别的操作,分别是“增(insert)、删(delete)、改(update)、查(select)”,这篇文章继续整理“表”级别的操作,同样分为“增(create table)、删(drop table与truncate table)、改(alter table)、查(show tables)”,有心的朋友可能已经发现,表级别的操作都包含"table"这个单词,为了方便记忆我也有意识的将操作分级别整理,制成下面表,往后再不断完善该表:
|
增 |
删 |
改 |
查 |
|
|
行级别 |
insert |
delete |
update |
select |
|
表级别 |
create table |
drop table truncate table |
alter table |
show tables |
表操作——增(新建表)
1、基本语法
基本语法:
create table 表名(
字段名1 类型 是否为空,
字段名2 类型 是否为空,
……
)engine=innodb default charset=utf8
创建一个新的表,就是要告诉数据库你这张表叫什么,里面有多少字段(列),每一字段(列)叫什么名字。这就好比excel里面的表格一样,需要给表格命名,给每一列命名;但是与excel表格不同的是,数据库为了提高存储和读取的效率,需要在建表的时候告诉它每列(每个字段)的数据类型是什么,需要占几个字节(列如int、char、text、datetime等);除此之外,我们还可以要求每一个字段具有一些其他属性,比如不可为空、唯一、自增、默认值等。
接下来还可以设置引擎(engine)和存储时的默认编码(default charset)。
1.1 表名和字段名的命名规则
建议在SQL中使用驼峰式命名,比如用户信息表命名为UserInfo,每个单词的首字母大写;名字简洁,做到让人一目了然,非特殊情况不建议使用特殊字符,不过在某些情况下有例外,比如对外键命名时,习惯使用“fk_T1_T2_id”这样的命名风格。
1.2 字段的类型


1 bit(长度) 2 --二进制位,长度(1-64),默认长度=1 3 4 tinyint(长度) unsigned zerofill 5 -- 短整数 6 -- 有符号(默认,后面不跟unsigned):-128 ~ 127. 7 -- 无符号(unsigned):0 ~ 255 8 -- zerofill:若不够位数在高位补0,例如tinyint(4),存储1是为0001 9 10 int(长度) unsigned zerofill 11 -- 整数 12 -- 有符号:-2147483648 ~ 2147483647 13 -- 无符号(unsigned):0 ~ 4294967295 14 -- zerofill同上 15 16 bigint(长度) unsigned zerofill 17 -- 长整数 18 -- 有符号:-9223372036854775808 ~ 9223372036854775807 19 -- 无符号:0 ~ 18446744073709551615 20 -- zerofill同上 21 22 decimal(总长度,小数位数) unsigned zerofill 23 -- 精确的小数(高精度的数据推荐使用) 24 -- 总长度最大值为65,小数位数最大值为30 25 26 float(总长度,小数位数) unsigned zerofill 27 -- 单精度浮点数(非精确小数) 28 -- 有符号:-3.402823466E+38 ~ -1.175494351E-38,0 29 1.175494351E-38 ~ 3.402823466E+38 30 -- 无符号:0,1.175494351E-38 ~ 3.402823466E+38 31 32 double(总长度,小数位数) unsigned zerofill 33 -- 双精度浮点数(非精确小数值) 34 -- 有符号: 35 -1.7976931348623157E+308 ~ -2.2250738585072014E-308 36 0 37 2.2250738585072014E-308 ~ 1.7976931348623157E+308 38 -- 无符号: 39 0,2.2250738585072014E-308 ~ 1.7976931348623157E+308
1 char (长度) 2 -- 表示固定长度的字符串,最多达255个字符 3 -- 该类型储存时占用固定位数,查找速度较快 4 5 varchar(长度) 6 -- 可变字符串,最多达255个字符 7 -- 括号内的“长度”参数表示最多占用的字符 8 -- 查找速度慢于char,但是相对来说较节省空间 9 10 text 11 -- 可变的长字符串,最多65535 (2**16 − 1)个字符。 12 13 mediumtext 14 -- 可变的中长字符串,最多16777215 (2**24 − 1) 个字符 15 16 longtext 17 -- 可变长的特长字符串,最多4294967295 (2**32 − 1) 个字符(4GB) 18 19 enum(元素1,元素2,元素3……) 20 -- 枚举类型 21 -- 一个枚举里面最多 65,535个不重复的元素,实际应用中一般少于3000个 22 -- 枚举类型表示该字段只能插入在枚举里的一个元素 23 24 set(元素1,元素2,元素3……) 25 -- 集合类型 26 -- 一个集合最多包含64个不重复的元素 27 -- 集合类型表示该字段只能插入在集合中的一个或多个元素 28
1 DATE 2 -- 日期 3 -- 格式: YYYY-MM-DD,如 2018-01-01 4 5 TIME 6 -- 时间 7 -- 格式:HH:MM:SS,如 12:01:59 8 9 YEAR 10 -- 年份 11 -- 格式:YYYY,如 2018 12 13 DATETIME 14 -- 日期+时间 15 -- 格式:YYYY-MM-DD HH:MM:SS,如 2018-01-01 12:01:59 16 17 TIMESTAMP 18 -- 时间戳 19 -- 格式:YYYYMMDD HHMMSS 20 -- 默认长度14位,也可以设置成其他位数,例如设置成8位,则显示年月日
1 --二进制数据可以存储图片、视频等格式内容,但将其存入数据库属非主流做法 2 TinyBlob 3 Blob 4 MediumBlob 5 LongBlob
1.3 是否为空
-- 数据库中,如果插入一行数据时,不给某字段插入内容,即插入空(SQL用null表示)
-- 例如,在test中分别插入“空字符串”和“空”,对比如下两步操作:
insert into test(name) values(""); -- 此时name不为空
insert into test() values (); -- name为空

2、自增 & 主键
-- 在建表时的字段名后跟 auto_increment
-- 一般情况下,我们建表时,会给每张表设置一个id字段,这个字段既自增,且为主键(primary key)
-- 主键:不为null,且唯一的字段
-- 故,id字段自增(唯一),且不为null,所以可为主键。PS:mysql规定,自增列必须设为主键
create table t1(
id int auto_increment primary key
);

-- 一般将自增列设置为主键,除此之外也可将多列设置为主键
create table t3(
num int(4) zerofill not null,
name char(10) not null,
gender char(2) default "男",
tstamp timestamp default CURRENT_TIMESTAMP,
primary key(num, name) -- 将 num、name两字段共同设为主键
);
-- 插入几条数据试试
insert t3(num,name) values(1,"小明");
insert t3(num,name) values(1,"小李"); -- 虽然num也是1,但是name不同
insert t3(num,name) values(2,"小李"); -- name也是“小李”,但num不同
insert t3(num,name) values(1,"小李"); -- 报错,已经存在(1,"小李")
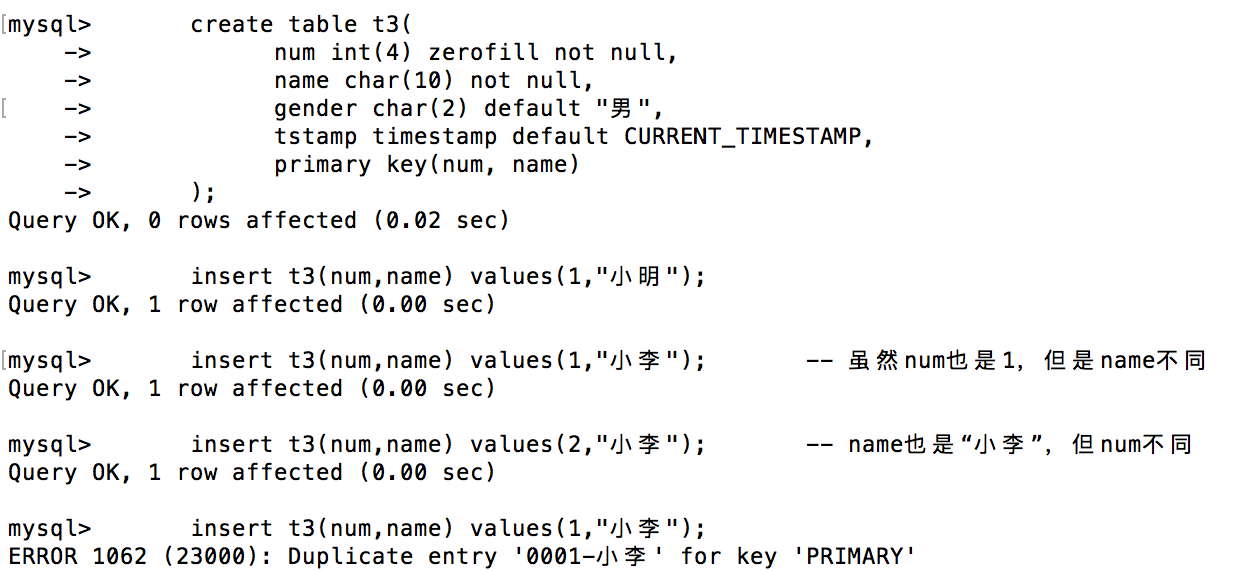
此时t3表中数据如下:

3、默认值
-- 在插入数据时,如果不插入任何值时,想自动插入默认值,可以使用语句“default 值”
create table t2(
id int(4) zerofill auto_increment primary key, -- zerofill上文已述
gender char(2) not null default "男",
ttamp timestamp default CURRENT_TIMESTAMP -- 默认插入当前时间戳
);
-- 插入两条数据试试
insert into t2(gender) values("女");
insert into t2() values();
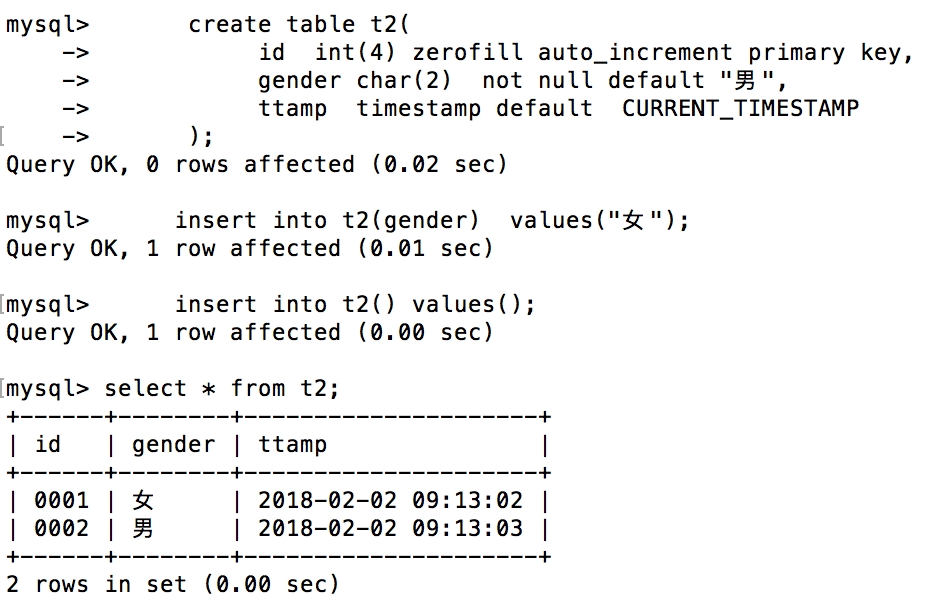
4、外键
表操作——删(删除表)
表操作——改(更改表的结构)
表操作——查(联表查询)
