


python常用模块-1
一、认识模块
1、什么是模块:一个模块就是一个包含了python定义和声明的文件,文件名就是加上.py的后缀,但其实import加载的模块分为四个通用类别 :
1.使用python编写的代码(.py文件) 2.已被编译为共享库二和DLL的C或C++扩展 3.包好一组模块的包 4.使用C编写并连接到python解释器的内置模块
2、为何要使用莫模块?
如果你想退出python解释器然后重新进入,那么你之前定义的函数或变量都将丢失,因此我们通常将程序写到文件中以便永久保存下来,需要时,就通过python test.py 方式去执行,此时test.py被称为脚本script。 随着程序的发展,功能越来越多,为了方便管理,我们通常将文件分成一个个的文件,这样做程序的结构更清晰,方便管理。这时我们不仅仅可以吧这些文件当做脚本去执行,还可以把它们当做模块来导入到其他模块中,实现了功能的重复利用。
二、常见模块分类
常用模块一: collocations 模块 时间模块 random模块 os模块 sys模块 序列化模块 re模块 常用模块二:这些模块和面向对象有关 hashlib模块 configparse模块 logging模块
三、正则表达式
像我们平常见的那些注册页面啥的,都需要我们输入手机号码吧,你想我们的电话号码也是有限定的吧(手机号码一共11位,并且只以13,14,15,17,18开头的数字这些特点)如果你的输入有误就会提示,那么实现这个程序的话你觉得用While循环so easy嘛,那么我们来看看实现的结果。


1 while True: 2 phone_number=input('请输入你的电话号码:') 3 if len(phone_number)==11 and phone_number.isdigit()\ 4 and (phone_number.startswith('13')\ 5 or phone_number.startswith('14') \ 6 or phone_number.startswith('15') \ 7 or phone_number.startswith('17') \ 8 or phone_number.startswith('18')): 9 print('是合法的手机号码') 10 else: 11 print('不是合法的手机号码')
看到这个代码,虽说理解很容易,但是我还有更简单的方法。那我们一起来看看吧。
1 import re 2 phone_number=input('请输入你的电话号码:') 3 if re.match('^(13|14|15|17|18)[0-9]{9}$',phone_number): 4 '''^这个符号表示的是判断是不是以13|14|15|17|18开头的, 5 [0-9]: []表示一个字符组,可以表示0-9的任意字符 6 {9}:表示后面的数字重复九次 7 $:表示结束符 8 ''' 9 print('是合法的手机号码') 10 else: 11 print('不是合法的手机号码')
大家可能都觉的第一种方法更简单吧,但是如果我让你从整个文件中匹配出所有的手机号码,你能用python写出来吗?但是导入re模块和利用正则表达式就可以解决这一个问题了。
那么什么是正则呢?
首先你要知道的是,谈到正则,就只和字符串相关了。在线测试工具 http://tool.chinaz.com/regex/
比如你要用‘1’去匹配‘1’,或者用‘2’去匹配‘2’,直接就可以匹配上。
字符组:[字符组]
在同一位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示
字符分为很多类,比如数字,字母,标点等登。
假如你现在要求一个位置‘只能出现一个数字’,那么这个位置上的字符只能是0、1、2、3.......9这是个数之一。
字符组:

字符:

量词:
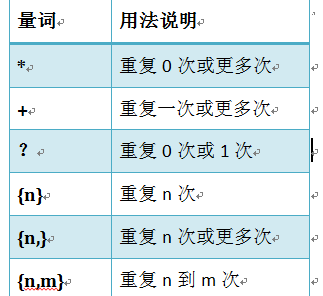
.^$

*+?{}

注意:前面的*,+,?等都是贪婪匹配,也就是尽可能多的匹配,后面加?就变成了非贪婪匹配,也就是惰性匹配。
贪婪匹配:

几个常用的配贪婪匹配
|
1
2
3
4
5
|
*?;重复任意次,但尽可能少重复 +?:重复一次或更多次,但尽可能少重复 ??:重复0次或1次,但尽可能少重复{n,m}:重复n到m次,但尽可能少重复 {n,}: 重复n次以上,但尽可能少重复 |
.*?的用法:
|
1
2
3
4
5
6
|
.是任意字符*是取0到无限长度?是非贪婪模式和在一起就是取尽量少的任意字符,一般不会这么单独写,大多用在:.*?x意思就是取前面任意长度的字符,直到一个x出现 |
字符集:
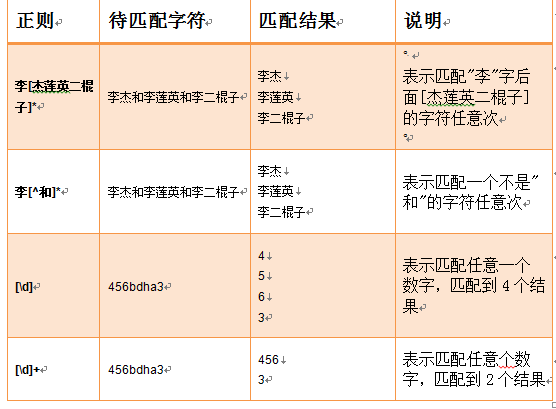
分组()与或|[^]:
|
1
2
3
4
5
6
7
8
9
10
|
(1)^[1-9]\d{13,16}[0-9x]$ #^以数字0-9开始, \d{13,16}重复13次到16次 $结束标志上面的表达式可以匹配一个正确的身份证号码(2)^[1-9]\d{14}(\d{2}[0-9x])?$ #?重复0次或者1次,当是0次的时候是15位,是1的时候是18位(3)^([1-9]\d{16}[0-9x]|[1-9]\d{14})$#表示先匹配[1-9]\d{16}[0-9x]如果没有匹配上就匹配[1-9]\d{14} |
1 举个例子,比如html源码中有<title>xxx</title>标签,用以前的知识,我们只能确定源码中的<title>和</title>是固定不变的。因此,如果想获取页面标题(xxx),充其量只能写一个类似于这样的表达式:<title>.*</title>,而这样写匹配出来的是完整的<title>xxx</title>标签,并不是单纯的页面标题xxx。 2 3 想解决以上问题,就要用到断言知识。 4 5 在讲断言之前,读者应该先了解分组,这有助于理解断言。 6 7 分组在正则中用()表示,根据小菜理解,分组的作用有两个: 8 9 10 11 n 将某些规律看成是一组,然后进行组级别的重复,可以得到意想不到的效果。 12 13 n 分组之后,可以通过后向引用简化表达式。 14 15 16 17 18 19 先来看第一个作用,对于IP地址的匹配,简单的可以写为如下形式: 20 21 \d{1,3}.\d{1,3}.\d{1,3}.\d{1,3} 22 23 但仔细观察,我们可以发现一定的规律,可以把.\d{1,3}看成一个整体,也就是把他们看成一组,再把这个组重复3次即可。表达式如下: 24 25 \d{1,3}(.\d{1,3}){3} 26 27 这样一看,就比较简洁了。 28 29 30 31 再来看第二个作用,就拿匹配<title>xxx</title>标签来说,简单的正则可以这样写: 32 33 <title>.*</title> 34 35 可以看出,上边表达式中有两个title,完全一样,其实可以通过分组简写。表达式如下: 36 37 <(title)>.*</\1> 38 39 这个例子实际上就是反向引用的实际应用。对于分组而言,整个表达式永远算作第0组,在本例中,第0组是<(title)>.*</\1>,然后从左到右,依次为分组编号,因此,(title)是第1组。 40 41 用\1这种语法,可以引用某组的文本内容,\1当然就是引用第1组的文本内容了,这样一来,就可以简化正则表达式,只写一次title,把它放在组里,然后在后边引用即可。 42 43 以此为启发,我们可不可以简化刚刚的IP地址正则表达式呢?原来的表达式为\d{1,3}(.\d{1,3}){3},里边的\d{1,3}重复了两次,如果利用后向引用简化,表达式如下: 44 45 (\d{1,3})(.\1){3} 46 47 简单的解释下,把\d{1,3}放在一组里,表示为(\d{1,3}),它是第1组,(.\1)是第2组,在第2组里通过\1语法,后向引用了第1组的文本内容。 48 49 经过实际测试,会发现这样写是错误的,为什么呢? 50 51 小菜一直在强调,后向引用,引用的仅仅是文本内容,而不是正则表达式! 52 53 也就是说,组中的内容一旦匹配成功,后向引用,引用的就是匹配成功后的内容,引用的是结果,而不是表达式。 54 55 因此,(\d{1,3})(.\1){3}这个表达式实际上匹配的是四个数都相同的IP地址,比如:123.123.123.123。 56 57 58 59 至此,读者已经掌握了传说中的后向引用,就这么简单。
分组命名:语法(?p<name>)注意先命名,后正则
import re import re ret=re.search('<(\w+)>\w+<(/\w+)>','<h1>hello</h1>') print(ret.group()) # 给分组起个名字。就用下面的分组命名,上面的方法和下面的分组命名是一样的,只不过就是给命了个名字 ret=re.search('<(?P<tag_name>\w+)>\w+</(?P=tag_name)>','<h1>hello</h1>')
#(?P=tag_name)就代表的是(\w+)
print(ret.group()) # 了解(和上面的是一样的,是上面方式的那种简写)
ret=re.search(r'<(\w+)>\w+</\1>','<h1>hello</h1>')
print(ret.group(1))
转义符:
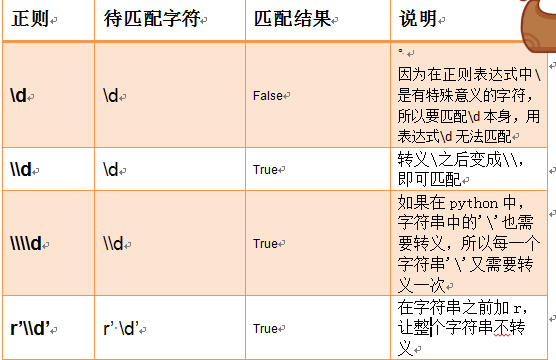
四、re模块
1 # 1.re模块下的常用方法 2 # 1.findall方法 3 import re 4 ret = re.findall('a','eva ang egons') 5 # #返回所有满足匹配条件的结果,放在列表里 6 print(ret) 7 8 # 2.search方法 9 # 函数会在字符串中查找模式匹配,只会找到第一个匹配然后返回 10 # 一个包含匹配信息的对象,该对象通过调用group()方法得到匹配的 11 # 字符串,如果字符串没有匹配,则报错 12 ret = re.search('s','eva ang egons')#找第一个 13 print(ret.group()) 14 15 16 # 3.match方法 17 print(re.match('a','abc').group()) 18 #同search,只从字符串开始匹配,并且guoup才能找到 19 20 21 # 4.split方法 22 print(re.split('[ab]','abcd')) 23 #先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割 24 25 26 # 5.sub方法 27 print(re.sub('\d','H','eva3sdf4ahi4asd45',1)) 28 # 将数字替换成'H',参数1表示只替换一个 29 30 31 # 6.subn方法 32 print(re.subn('\d','H','eva3sdf4ahi4asd45')) 33 #将数字替换成’H‘,返回元组(替换的结果,替换了多少次) 34 35 36 # 7.compile方法 37 obj = re.compile('\d{3}')#将正则表达式编译成一个正则表达式对象,规则要匹配的是三个数字 38 print(obj) 39 ret = obj.search('abc12345eeeee')#正则表达式对象调用search,参数为待匹配的字符串 40 print(ret.group()) #.group一下就显示出结果了 41 42 # 8.finditer方法 43 ret = re.finditer('\d','dsf546sfsc')#finditer返回的是一个存放匹配结果的迭代器 44 # print(ret)#<callable_iterator object at 0x00000000021E9E80> 45 print(next(ret).group())#查看第一个结果 46 print(next(ret).group())#查看第二个结果 47 print([i.group() for i in ret] )#查看剩余的左右结果
1 import re 2 ret = re.findall('www.(baidu|oldboy).com','www.oldboy.com') 3 print(ret) #结果是['oldboy']这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 4 5 ret = re.findall('www.(?:baidu|oldboy).com','www.oldboy.com') 6 print(ret) #['www.oldboy.com']
1 ret = re.split('\d+','eva123dasda9dg')#按数字分割开了 2 print(ret) #输出结果:['eva', 'dasda', 'dg'] 3 4 ret = re.split('(\d+)','eva123dasda9dg') 5 print(ret) #输出结果:['eva', '123', 'dasda', '9', 'dg'] 6 # 7 # 在匹配部分加上()之后和不加括号切出的结果是不同的, 8 # 没有括号的没有保留所匹配的项,但是有括号的却能够保留了 9 # 匹配的项,这个在某些需要保留匹配部分的使用过程是非常重要的
re模块和正则表达式的关系:
re模块和正则表达式没有一点毛线关系。re模块和正则表达式的关系类似于time模块和时间的关系,你没有学习python之前,也不知道有一个time模块,但是你已经认识时间了呀,12:30就表示中午十二点半。时间有自己的格式,年月日时分秒,已成为一种规则。你早就牢记于心了,time模块只不过是python提供给我们的可以方便我们操作时间的一个工具而已。
五、collections模块
在内置数据类型(dict,list,set,tuple)的基础上,collections 模块还提供了几个额外的数据类型:
1.namedtuple:生成可以使用名字来访问元素内容的tuple
2.deque:双向队列(两头都可进可出,但是不能取中间的值),可以快速的从另外一侧追加和推出对象
3.Counter:计数器,主要用来计数
4.OrderedDict:有序字典
5.defaultdict:带有默认值的字典
namedtuple:
我们知道tuple可以表示不变集合,例如,一个点的二维坐标就可以表示成:p=(1,2)
但是,看到(1,2),很难看出这个tuple是用来表示坐标的。
那么,我们的namedtuple就能用上了。
namedtuple('名称',‘属性list’)
|
1
2
3
4
|
from collections import namedtuplepoint = namedtuple('point',['x','y'])p = point(1,2)print(p.x,p.y)、<br><br><br> |
Circle = namedtuple('Circle', ['x', 'y', 'r'])#用坐标和半径表示一个圆
deque:
|
1
2
3
4
5
6
7
8
9
10
|
单向队列<br># import queue #队列模块# q = queue.Queue()# q.put(10)# q.put(20)# q.put(30)# # 10 20 30# print(q.get())# print(q.get())# print(q.get())# print(q.get()) |
deque是为了高效实现插入和删除操作的双向队列,适用于队列和栈
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
from collections import dequeq = deque(['a','b','c'])q.append('ee')#添加元素q.append('ff')q.append('qq')print(q)q.appendleft('www')#从左边添加print(q)q.pop() #删除元素q.popleft() #从左边删除元素print(q) |
OrderedDict:
使用字典时,key是无序的。在对字典做迭代时,我们无法确定key的顺序。如果要保持key的顺序,可以用OrderedDict
|
1
|
from collections import OrderedDict |
d = {'z':'qww','x':'asd','y':'asd','name':'alex'}
print(d.keys()) #key是无序的
|
1
|
od = OrderedDict([('a', 1), ('b', 2), ('c', 3)]) print(od)# OrderedDict的Key是有序的 <br>OrderedDict([('a', 1), ('b', 2), ('c', 3)])<br><br><br> |
OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:od = OderedDict ()
od['z']=1
od['y']=2
od['x']=3
print(od.keys()) #按照插入额key的顺序返回
defaultdict:
1 d = {'z':'qww','x':'asd','y':'asd','name':'alex'} 2 print(d.keys()) 3 from collections import defaultdict 4 values = [11,22,33,44,55,66,77,88,99] 5 my_dict = defaultdict(list) 6 for v in values: 7 if v>66: 8 my_dict['k1'].append(v) 9 else: 10 my_dict['k2'].append(v) 11 print(my_dict)
1 from collections import defaultdict 2 dd = defaultdict(lambda: 'N/A') 3 dd['key1'] = 'abc' 4 print(dd['key1']) # key1存在 5 6 print(dd['key2']) # key2不存在,返回默认值
Counter:
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。Counter类和其他语言的bags或multisets很相似。
from collections import Counter c = Counter('abcdeabcdabcaba') print(c) # 输出:Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
其他详细内容 http://www.cnblogs.com/Eva-J/articles/7291842.html

