
Hadoop序列化与Writable接口(一)
Hadoop序列化与Writable接口(一)
序列化
序列化(serialization)是指将结构化的对象转化为字节流,以便在网络上传输或者写入到硬盘进行永久存储;相对的反序列化(deserialization)是指将字节流转回到结构化对象的过程。
在分布式系统中进程将对象序列化为字节流,通过网络传输到另一进程,另一进程接收到字节流,通过反序列化转回到结构化对象,以达到进程间通信。在Hadoop中,Mapper,Combiner,Reducer等阶段之间的通信都需要使用序列化与反序列化技术。举例来说,Mapper产生的中间结果(<key: value1, value2...>)需要写入到本地硬盘,这是序列化过程(将结构化对象转化为字节流,并写入硬盘),而Reducer阶段读取Mapper的中间结果的过程则是一个反序列化过程(读取硬盘上存储的字节流文件,并转回为结构化对象),需要注意的是,能够在网络上传输的只能是字节流,Mapper的中间结果在不同主机间洗牌时,对象将经历序列化和反序列化两个过程。
序列化是Hadoop核心的一部分,在Hadoop中,位于org.apache.hadoop.io包中的Writable接口是Hadoop序列化格式的实现。
Writable接口
Hadoop Writable接口是基于DataInput和DataOutput实现的序列化协议,紧凑(高效使用存储空间),快速(读写数据、序列化与反序列化的开销小)。Hadoop中的键(key)和值(value)必须是实现了Writable接口的对象(键还必须实现WritableComparable,以便进行排序)。
以下是Hadoop(使用的是Hadoop 1.1.2)中Writable接口的声明:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
|
Writable类
Hadoop自身提供了多种具体的Writable类,包含了常见的Java基本类型(boolean、byte、short、int、float、long和double等)和集合类型(BytesWritable、ArrayWritable和MapWritable等)。这些类型都位于org.apache.hadoop.io包中。
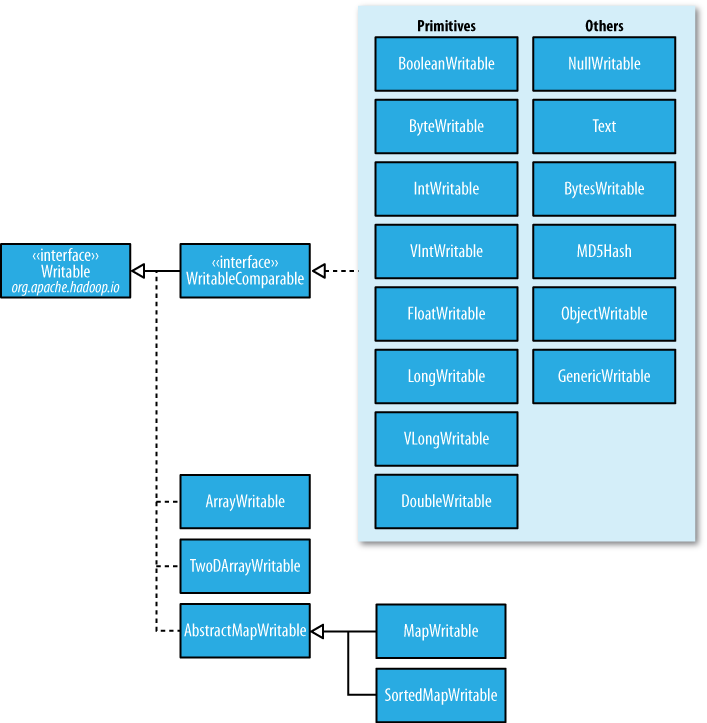
(图片来源:safaribooksonline.com)
定制Writable类
虽然Hadoop内建了多种Writable类提供用户选择,Hadoop对Java基本类型的包装Writable类实现的RawComparable接口,使得这些对象不需要反序列化过程,便可以在字节流层面进行排序,从而大大缩短了比较的时间开销,但是当我们需要更加复杂的对象时,Hadoop的内建Writable类就不能满足我们的需求了(需要注意的是Hadoop提供的Writable集合类型并没有实现RawComparable接口,因此也不满足我们的需要),这时我们就需要定制自己的Writable类,特别将其作为键(key)的时候更应该如此,以求达到更高效的存储和快速的比较。
下面的实例展示了如何定制一个Writable类,一个定制的Writable类首先必须实现Writable或者WritableComparable接口,然后为定制的Writable类编写write(DataOutput out)和readFields(DataInput in)方法,来控制定制的Writable类如何转化为字节流(write方法)和如何从字节流转回为Writable对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
|
|
未完待续,下一篇中将介绍Writable对象序列化为字节流时占用的字节长度以及其字节序列的构成。
参考资料
Tom White, Hadoop: The Definitive Guide, 3rd Edition
---To Be Continued---

【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步