
ceph笔记(一)
一、ceph概述
本质上是rados:可靠的、自动的、分布式对象存储
特性:高效性(大型的网络raid,性能无限接近raid)、统一性(支持文件存储、块存储、对象存储)、可扩展性
数据库的一个弱点:查表
ceph中没有数据库,集群状态全靠cluster map展示
三种存储类型与rados的关系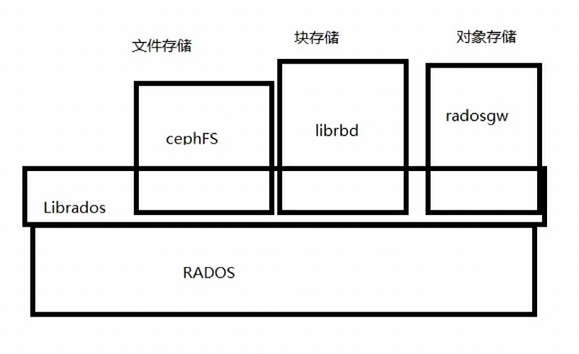
补充
云主机创建:nova-->libvirtd:虚拟机控制程序-->qemu(其他硬件的虚拟化)-kvm(cpu、内存的虚拟化)驱动-->云主机
块存储创建:cinder-->backend驱动--->ceph
挂载:qemu调用librbd(实质是librados库),再访问rados,是通过网络的形式
二、ceph逻辑架构
osd daemon去管理底层的硬盘,主osd负责读写,其余osd负责复制
pg:几个osd daemon的属组,它是一个逻辑概念,并没有size的说法。比如一个班上有虚拟化组、存储组、网络组
# librbd是在虚拟机上的,负责把文件切分成4M一个obj,不足4M也按4M切。每个obj都带有一个id
ceph存储小文件的效率不高,因为存个16M的文件还要切片、哈希就会慢。从理论上来讲,底层磁盘越多,ceph效率越高
ceph中的对应关系
每个obj对应一个PG
一个PG可以对应很多个obj
osd与pg之间是多对多的关系,比如,一个组起码得有两个人,某些人可能也从属于两个组
pg与osd之间的映射是基于crush算法
四、pool存储池提供
1.pg数目
2.对象副本数
3.crush规则(pg--->osd:acting set)
4.用户及权限
功能:为客户端提供块设备
pool相当于lvm里面的vg,osd相当于pv。在lvm里面,vg建好之后,就可以在vg基础上划分一些空间(lv)供使用,而ceph的image就类比这个空间,映射到虚拟机使用的/dev/vd?。所以,image是给虚拟机分配存储空间,但是要注意,这只是一个配额,就是说你最多只能使用这么大的空间,而且你每一次存储的时候,对应的pg都不一定是上一次的pg,因为客户端每次都会从mon那里获取最新的map,librbd会作出最优选择,这样ceph集群的数据才会更均匀。
你可以把pool想象成一个垃圾场,你订购的体积是100立方米。你可以把你每天的生活垃圾倒进去,对于倒垃圾的位置没有限制,(这里就类比了虚拟机每次都不一定使用上一次的pg),每次倒的垃圾大小没有限制,只要你累计的体积不超过100立方(image)即可。但有些人觉得垃圾场里面好脏,不愿意进去,只倒在垃圾场门口,久而久之,门口堆满了垃圾,里面有大把空间,但是又没人想进去,造成空间的浪费和低效。针对这种情况,ceph做了优化,每次都让客户端获取最新的map以选择最适合的pg,使得集群整体的数据更均匀。
虚拟机中obj如何找到自己对应的pg?
客户端输入pool_id和obj_id
crush获得obj_id并对其做哈希,然后计算OSD个数,Hash取模得到一个值,比如0x58;再把pool_id(假设是4)与前者的值,综合一块,得出的值就是pg_id(4.0x58)。
这中间做了很多复杂的运算,目的是为了让数据更平衡些,因为ceph的数据平衡是伪平衡,只能用哈希让它更平衡一些
pg又是怎么样找到osd的?
pg向mon节点取crush map,就知道自己负责哪几个osd了
上面的整个流程是这样的:
第一步,获取pg和osd的对应关系
虚拟机在对数据分块之前,会调用librbd,librbd再调用librados,librados连上ceph的mon集群,获取整个集群的最新状态(包括各种map,主要是想知道pg和osd的对应关系)。
第二步,获取obj与pg的关系
obj-id做哈希,整体的osd数哈希取模,结合pool_id--->pg-id---crush map--->osd--->disk
五、pool的类型
1.复制类型
2.纠错码类型(速度慢、不支持ceph所有的操作(比如垃圾清理时它会禁止写操作,整个集群就不可写了,此时pg的状态为scrubling))
客户端写入数据流程分析
pool类似于vg的概念,不是真实分区,本质就是一堆pg的集合。可以建好几个pool,用做不同的用途:存数据、存镜像
一个pg不能处于多个pool
file-->obj-->某一个pg--crush算法-->osd daemon
mon节点上有个pg_monitor函数,它会监控有没有新的pool创建,如果有的话,检测是否需要创建新的pg,如果需要,ceph就进入creating状态,下一步是通过crush算法找到pg里面包含的osd,发给主osd,然后成员之间peering,最终生成pg
写数据怎么写?
librdb的作用:帮客户端拿到最新的map并做分析;把对象进行切片
刚建好的ceph集群时,没有pool和pg,只有mon和一堆osd,主osd负责读写,从的负责复制
osd节点对于cpu和内存的要求也非常高,因为它要维持PG的这个逻辑单位,1G内存对应1T磁盘
六、PG
epoach:单调递增的版本号
acting set:列表,第一个为primary osd,其余为replicated osd
up set:acting set过去的版本
pg tmp:临时pg组,这种会在主osd成员坏掉、新osd加入的时候出现。比如一个部门,项目经理离职了,新找来了一个项目经理,这个新来的项目经理要向其他的成员学习业务,在这个过程,部门中肯定要暂时选个领头人,直到新来的项目经理学习完毕。
pg的状态
ceph -s(在某个mon上执行)
状态的变迁:creating--->peering(组员互相认识的过程)--->active(能干活,但是数据还没同步完)--->clean(已复制完数据,可以写入新的数据)
stable:你这个组里有人没在2秒内给mon汇报状态。如果300秒之内没回应,mon就会把osd从pg提出
backfilling:有新的OSD进来了(全量)
recovery:原来的成员在300秒内活了,要求更新数据(增量)
如果一个集群中你设置了一个osd对应多个pg,那么当一个osd坏掉之后,有些数据的副本数就少了一份,由于pg是逻辑单位,所以,在这种情况下要恢复数据,压力是很大的。如果再有一个osd坏掉,有些数据的副本可能就剩下一份了,pg的压力就更大了,很容易造成连锁反映
在pool里面设置的副本数为3,意味着你一个pg对应3个osd
osd daemon的状态,默认每2秒汇报自己的状态给mon,同时监控组内成员的状态
up:可以提供IO
down:不能提供IO
in:osd有数据
out:osd没数据
osd的功能:存储以及后端数据复制,监控自己以及组内成员的状态
七、ceph网络架构
三类集群:disk集群、osd daemon集群(几十个到几万个)、monitor daemon集群
最好的方案:一块osd daemon对应一块硬盘是最好的方案
monitor:一台服务器安装一个monitor软件,数量无上限、最好为奇数
monitor集群负责维护cluster map
cluster map包含:mon map、osd map、pg map、crush map
monitor集群使用的算法是paxos(功能之一就是选举),统治者是leader,其余为provider,版本落后的叫rqueester。rqueester向leader发起获取集群最新信息的请求,leader不会给,它会让rqueester找provider要。
集群网络也叫北向网络:用于与客户端通信,必须万兆网络,因为对集群健康状态的要求非常高
功能:mon集群通信;osd汇报状态给mon,客户端访问osd存储,更新维护cluster map
存储网络也就东西网络:PG组里面的某个OSD坏掉了(300秒还没恢复过来就会被踢出集群),数据在平衡的过程中,流量是非常巨大的,所以也必须万兆网络。
八、缓存机制
一台mon节点只能起一个monitor daemon
一台osd节点可以有多个osd daemon
缓存分两种:
首先大概了解一下
libvirt ---> qemu(vm) --->librbd --->rados(服务端缓存--->机械硬盘)
|
客户端缓存
1.客户端rbd缓存
write back:异步写,客户端先存到rbd缓存,然后再由rbd缓存发送到rados
优点:速度快
缺点:数据不安全,数据不一致
适用场景:对数据安全性要求不高,读写混合型的系统
write through:同步写,一边往rbd缓存写,同时也往rados写
优点:读快、安全
缺点:写慢
适用场景:读多写少
ceph支持在线修改配置文件
2.ceph服务端缓存
cache tiering,专门找一堆固态硬盘做一存储池,与你的机械硬盘做一个映射关系
客户端来数据先写ssd,就返回写成功了,然后再写到机械硬盘
优点:可以提升ceph的存储性能
缺点:成本高,性能提升并不明显
服务端缓存与客户端缓存对比
1.一个是内存级别的,另外一个是基于ssd
2.服务端缓存不存在数据不一致问题
##################部署#####################
如果文件系统是日志文件系统的话,写数据是有两次返回的
第一次客户端数据来了,记录在主osd的日志上,从osd从主osd的日志读取,也写入自己的日子中,然后返回结果给主osd,主osd再返回给客户端。等到所有主从osd的数据都写到硬盘后,又返回一个信息给客户端,数据已经真实的存在我的磁盘上了,你可以把缓存清理掉了。如果这一步没有完成,那ceph会支持你再发送一次请求。
有没有优化可言?固态盘作为日志盘,最好一块机械盘对应一块osd,实在没钱把固态就分区吧
固态盘的空间越小,越慢,一般至少要保留30%的空间,固态盘不推荐分区
如何计算日志盘大小=(网络带宽和硬盘带宽大小其中一个*脏数据最大同步时间(5-15s))*2
如何把ceph crush视图导出来

