
ElasticStack系列之三 & 索引前半段过程
- 索引分片
- 数据路由
- mapping解析
- 倒排索引
- 写入存储
1. 索引分片
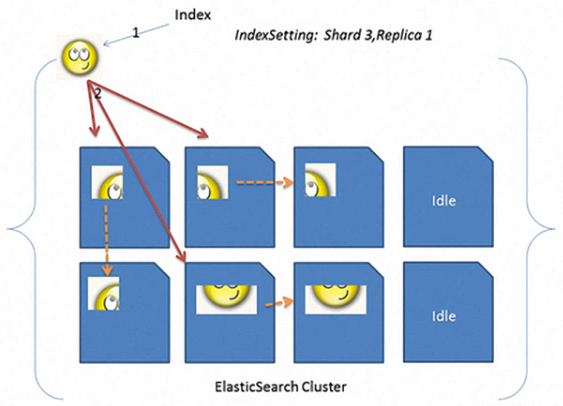
上图所示,一共有3个分片(shard),每个shard上有一个副本(replica),看到的蓝色图片为一个一个不同的datanode,目的是为了高可用。其中3个shard将所有的数据进行分割到不同的片上。如果使用es默认配置,你用一个节点进行启动,发现服务器状态总是yellow的,那是因为默认配置每个分片上都有一个副本,且es规定分片和副本不能放到一个节点上,那么一个节点启动es是找不到地方存放副本的地方,故集群服务状态始终为yellow,除非将副本数设置为0,那么机器就会变为green。
2. 路由策略

es底层查询方式是:search and get , 即先通过查询条件获得一大堆id,之后再通过这些id直接get到所需要的数据再返回。
3. mapping解析
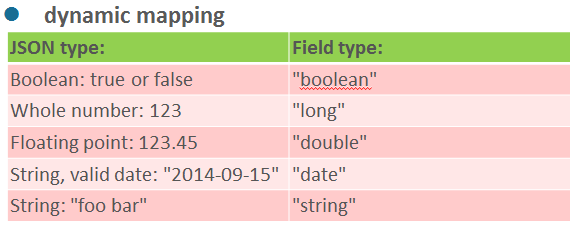
es默认使用的是动态解析,即在建立索引的时候不需要你提前创建对应的schema或者表结构,其实内部es也是对你提交的数据进行推测mapping后才索引,这个时候es可能会出现一些问题,(当然,大部分的时候还是可以正常使用的。建议能不用动态解析还是不要用,因为会发生一些意向不到的问题,如果遇到一些奇葩的需求,例如真的不知道对应的schema对应的是什么,只能选用es动态解析)
如上图所示,各个类型的匹配规则就是如此。但是有时候业务方为了图省事或者写入有误,将所有的内容都加上了双引号,除了日期无影响为,其他的所有非string类型字段都会被解析为string类型,那么测试你的数据类型可能就都会有问题了。
例如:
1. 一个属性字段应该都是long类型,将所有数字都导进来了,但是无法进行sum计算,那么问题就来了,人家找过来问你为什么呢?所以这是有问题的。
2. 还有一个很严重的实例,你不是说es可以不用设计表结构,那好,那我就拿到数据直接往你es里灌,后续人家说了,我给你导入无重复的2亿数据,怎么导完之后查了很多条数据都没有查到呢。那这个问题你想破了头皮也查不出来。最后通过对方导出日志发现是因为查询的这些条数据其中有一个字段value写成了valeu,导致你查询的时候怎么查都查不到。
提前申明:
如果有人非得用这个动态功能,那么我必须先要告诉你们用这个的风险,有什么问题自己负责。你不要说es有问题什么的,这个我提前都已经告诉你了,需要你心里有数。
4. 倒排索引
正排索引:通过id可以找到这个文章中包含哪些词

倒排索引:通过关键词可以找到包含有哪些文章

5. 写入存储
数据进入ES且如何才能让数据更快的被检索使用,用Lucene的设计思路就是“开新文件”
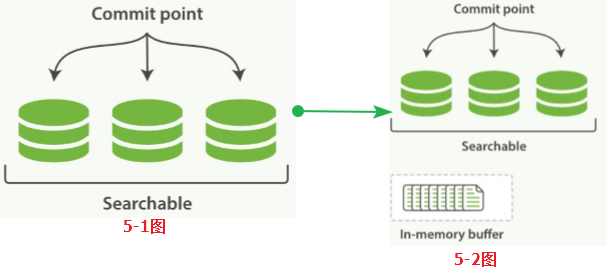
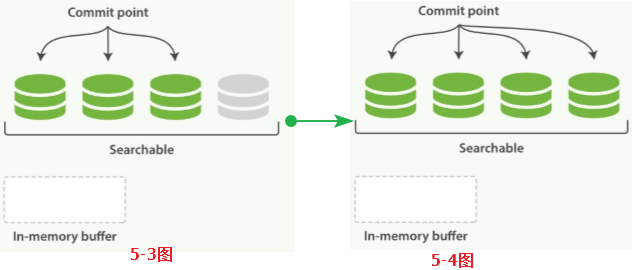
Lucene把每次生成的倒排索引叫做一个段(segment)。然后另外使用一个commit文件,记录索引内所有的segment。而生成segment的数据来源选择是内存中的buffer,即动态更新如下:
1. 当前索引有3个segment可用,状态图 --> 5-1图
2. 新接收的数据进入内存buffer,状态图 --> 5-2图
3. 内存buffer刷到磁盘,生成一个新的segment,commit文件同步更新。既然涉及到磁盘,那么一个不可避免的问题来了:磁盘太慢了!所以需要在刷新到磁盘中间加一个缓存用于提升速度。
4. 内存buffer生成一个新的segment,刷到文件系统缓存中,lucene可以检索这个新的segment,状态图 --> 5-3图
5. 文件系统缓存真正同步到磁盘上,commit文件更新,达到状态图 --> 5-4图
对于第5步刷到文件系统缓存的步骤,在ES中默认设置为5s(ES2.x之前的flush时间间隔为:1s)间隔,对于大多数应用来说几乎相当于实时可搜索了。ES也提供了单独的 /_refresh 接口,用户可以手动设置:
curl -xpost http://ip:9200/logstash/_settings -d
'
{
"refresh_interval" : "10s" //-1代表完全关闭刷新
}
'

既然refresh只是写到文件系统缓存,那么最后一步写到实际磁盘又是由什么来控制?如果这期间发生主机错误、硬件故障等异常情况,数据会不会丢失?
其实ES在把数据写入到内存buffer的同时还会另外记录一个translog日志(记录的是commit的原始内容,即当前文档的原样json串)。在5-3图和5-4图refresh发生的时候,translog日志文件依然保持原样如图5-5图所示。也就是说,如果在这期间发生异常,ES会从commit位置开始,恢复整个translog文件中的记录,保证数据的一致性。
等到真正把segment刷到磁盘且commit文件进行更新的时候,translog文件才清空,这一步叫flush,ES默认30分钟(或translog大小达到512MB)主动进行一次flush。
5-1. translog的一致性
索引数据的一致性通过translog保证,那么translog文件自己呢?
默认清空,ES每5s 强制刷新translog日志到磁盘上。所以,如果数据没有副本然后又发生故障,ES确实可能会丢失5s 的数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号