

福大软工1816 · 第二次作业 - 个人项目
1.GitHub地址
2.PSP表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | 100 | 120 |
| •Estimate | •估计这个任务需要多少时间 | 1200 | 1300 |
| Development | 开发 | 60 | 60 |
| •Analysis | •需求分析 (包括学习新技术) | 120 | 300 |
| •Design Spec | •生成设计文档 | 20 | 30 |
| •Design Review | •设计复审 | 20 | 40 |
| •Coding Standard | •代码规范(为目前的开发制定合适的规范) | 30 | 50 |
| •Design | •具体设计 | 60 | 80 |
| •Coding | •具体编码 | 240 | 400 |
| •Code Review | •代码复审 | 60 | 120 |
| •Test | •测试(自我测试,修改代码,提交修改) | 20 | 30 |
| Reporting | 报告 | 100 | 150 |
| •Test Repor | •测试报告 | 20 | 35 |
| •Size Measurement | •计算工作量 | 20 | 30 |
| •Postmortem & Process Improvement Plan | •事后总结, 并提出过程改进计划 | 60 | 100 |
| 合计 | 2130 | 2730 |
3.解题思路:
1.根据题需求,可以通过readline()接收每行字符串,累加统计出字符数和行数,但使用while(!readline())读入会致使第一个字符读入而产生每行首字符缺失,故我通过设置字符串“str”来专门完整接收.
2.在统计字符数、单词后,有了这些信息,加之在外层设置包含属性{string temp;int flag}的类数组来记录以.split()分隔字符后的各个字符串,再运用.toLowerCase()小写化各数组中的字符串达到统一一小写的目的。.isAlphabetic()辅之长度限制来去除不符合单词标准的字符串,并留下标准单词。
3.根据要求所示,中文不算字符,故而对于中文输入,我用创建类isChinese用以判断及统计中文次数,控制正确的单词、字符数。
4.结构体数组按词频、两两间字符串用.Compare进行对比,字典序排序。(以上所称“结构体”在JAVA中均称为“类”)
5 .输出即可。
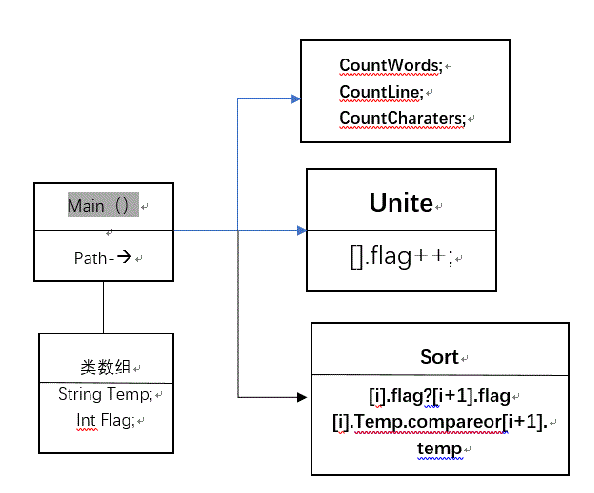
4.设计实现过程:
- 1.存储--Fileread:按行读入并且小写、分割、整合出标准单词,累计字符数、单词数、行数,并且设置hashmap,对每次读入的单词在map中的key值进行对比,若有则对应其value++,以此统计该单词的词频。
- 2.排序--MapUtils:通过之前存储在map的键值对<Key,Value>中的Value进行降序排序,再在输出环节取前10个单词,如果出现value相同情况,则对应其Key值进行对比,最后按照字典序输出
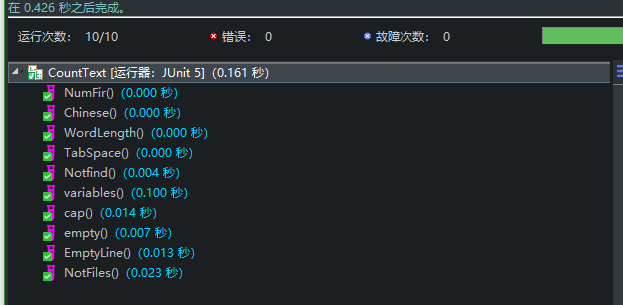
5.单元测试:
- 1.10个测试文本
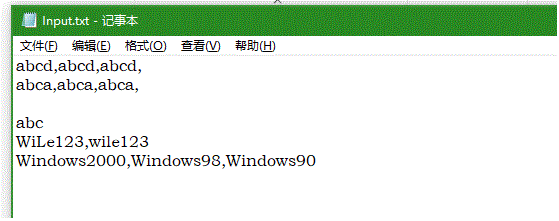
- 1.中文输入;
- 2.数字开头;
- 3.单词长度;
- 4.只包含换行符、空格符、制表符;
- 5.输入参数不匹配文件名;
- 6.无参输入;
- 7.超过10个单词
- 8.大小写分辨;
- 9.空文档;
- 10.文档中存在空行情况;
在此感谢王彬的单元测试实例性质的测试安排,借鉴其设置的顺序,有序的设置了10个文本~并且都通过了。
- 2.特殊例子输入:包含间隔空白行正确输出、同单词不同大小写统一、同频字典序输出,未达标准的字符串舍弃)
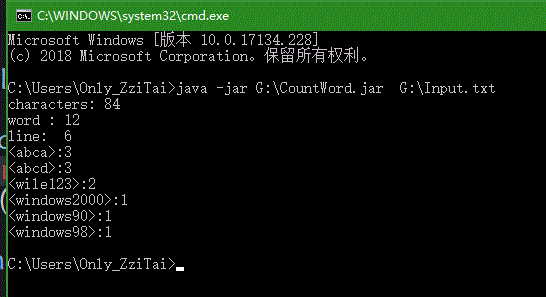
- 3.覆盖图

这是上面单元测试的覆盖图,在测试内跳过调用main直接调用其他类,在上文有说到...我把大部分功能全堆在了一个类里面...即"lib",故而覆盖率较高。Partion和isChinese均是用来配合考量中文字符的类,写完感觉有点多余...覆盖率仍说明一点问题,内容不够精简,有待优化提高!
下面是部分测试代码:
@Test
void EmptyLine() throws Exception {
Lib.yourMethodName("EmptyLine.txt");
}
@Test
void TabSpace() throws Exception {
Lib.yourMethodName("TabSpace.txt");
}
@Test
void variables() throws Exception {
Lib.yourMethodName("variables.txt");
}
6.代码说明:
- 1.记录读入的文件信息、统计字符、单词、行数(部分代码展示);
while ((str = br.readLine()) != null)
{
int wordsCount = 0;
countChar += str.length();
String[] words = str.split("[ ,.:|;+?!<>\\-#$%&]");//
if (str.isEmpty())
{
countline++;
continue;
}
wordLength += words.length
- 2.对比排序(使用hashmap提高排序速度)
public class MapUtils {
public static Map<String, Integer> sortByValue(Map<String, Integer> map) {
List<Entry<String, Integer>> list = new ArrayList<>(map.entrySet());
list.sort(Entry.comparingByValue());//
Collections.reverse(list);
Map<String, Integer> result = new LinkedHashMap<>();
for (Entry<String, Integer> entry : list) {
result.put(entry.getKey(), entry.getValue());
}
List<Map.Entry<String,Integer>> list =new ArrayList<Map.Entry<String,Integer>>(wList.entrySet());
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
if( o1.getValue()==o2.getValue())
{ return o1.getKey().compareTo(o2.getKey());}
return o2.getValue().compareTo(o1.getValue());
}
});
return result;
}
7.性能分析:运行5000次的结果
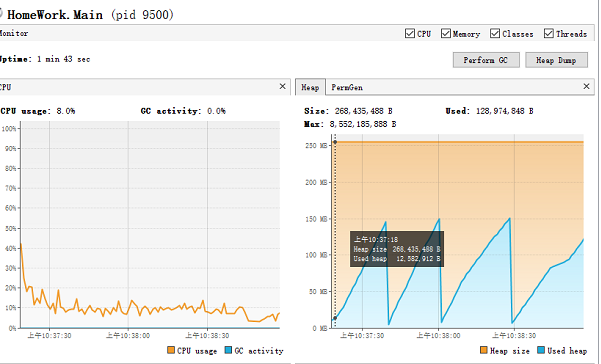

- 主要问题还是在开辟有效的记录信息的数组上。
8.异常处理:
对于与文本匹配的情况分析;
1.输入文件名未正确,则提示:Not Find"
2.未输入文本名,则提示:""Please Enter Right Filename!!"
for(int i=0;i<args.length;i++)
{
name+=args[i];
}
File file =new File(name);
if(!file.exists())
{
System.err.println("The file was not found!");
}
if(name=="")
{
System.err.println("Please enter a filename!!");
}
9.总结与感想
- 1.可以说是刚开始接触java,在使用上对许多函数十分生疏,其实在第二项任务布置下来的这几天每天都有投入许多时间在学习研究,频频碰壁,并且一直努力解决问题,时间上更多的是去寻找如何使用包,或者函数、或者eclipse的使用、解决问题方法。
- 2.自审:发现对算法的关注还是很少的, 都是用现有的弱成渣的知识来完成这次任务.....接下来也得接触更多更优良的算法来解决我接下来作业的问题!
- 3.作业评价:对于这次作业,作业质量个人并不满意,有许多可以优化的地方来不及学习新技术并优化处理,花了许多时间的结果到最后却变成单纯的解决任务而已。
- 4 VISUAL VM:看了半天Visual VM的使用方法,才找到使用VM出现问题的地方,这些都是第一次涉猎!感觉性能分析确实是个很神奇的工具,能一眼看到自己代码的不足!期待以后也会越用越好,代码也写得越简越精!
- 5 单元测试和覆盖图: 又是新事务,探索的过程总是令人窒息...疯狂搜索使用方法、下插件等等,出现了好多乱七八糟的东西,可以和探索VM过程一样揪心...好在慢慢懂得了怎么用、更轻松的用,最后还是很开心的结束了作业!受益匪浅!
- 6.Github与博客: 这些都是这学期接触的东西,之前从未涉及,翻天也就是看看别人博客解决一些自己的代码问题,但到自己去编辑博客时才发现博主都是不辞辛苦地、事无巨细地完成他们自己的每一篇文章来造福他人;Github的使用仍然还是处于皮毛阶段,自己仍在去看入门教程和一些博客来弥补知识漏洞!在不断的修改、上传中看到自己龟速的进步还是很快乐的!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号