


信息安全系统设计基础第九周学习总结
第十章 系统级I/O
10.1 Unix I/O
-
一个unix文件就是一个m字节的序列(B0B1B2...Bm-1)。所有的IO设备,如网络,磁盘,终端,都被模型化为文件,而所有的输入和输出都被当作对相应文件的读和写来执行。 2、所有的输入和输出都被当作统一的方式来处理:
1)打开文件。一个应用程序通过要求内核打开相应的文件,来宣告它想要访问一个IO设备。内核返回一个小的非负整数,叫做描述符,它在后续对此文件的所有操作中标识这个文件。内核记录这个打开文件的所有信息,而应用程序只需记住这个描述符。
Unix创建的每个进程开始都有三个打开的文件:标准输入(描述符为0),标准输出(描述符1),标准错误(描述符为2)。头文件unistd.h中定义了相关常量。
2)改变当前的位置。内核保持一个文件位置k,对于每个打开文件,初始为0。这个文件位置是从文件开头起始的字节偏移量。
3)读写文件。读操作是从文件拷贝n>0个字节到存储器,从当前文件位置k开始,然后将k增加到k+n。写操作是从存储器拷贝n>0个字节到文件,从当前文件位置k开始,然后更新k。
4)关闭文件。内核释放文件打开时创建的数据结构,并恢复描述符到可获得描述符池中。
10.2 打开和关闭文件
-
进程是通过调用open函数来打开一个已存在的文件或是创建一个新文件
#include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> int open(char *filename, int flags, mode_t mode); 返回:若成功则为新文件描述符,若出错则为-1。 -
Flag参数指明了进程打算如何访问这个文件:
O_RDONLY:只读 O_WRONLY:只写 O_RDWR:可读可写。
-
Mode参数指明了新文件的访问权限位。通过调用umask函数设置。

-
Close函数关闭文件。
#include <unistd.h> int close(int fd); 返回:若成功则0,若出错则为-1。关闭一个已关闭的描述符会出错。
10.3 读和写文件
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t n);
返回:若成功则为读的字节数,若EOF则为0,若出错则为-1。
ssize_t write(int fd, const void *buf, size_t n);
返回:若成功则为写的字节数,若出错则为-1。
某些情况下,原始的read,write传送的字节比应用程序要求的要少,这些不足值(short count)不一定是错误(比如read函数参数要读5个字节,结果只读了3个字节,即小于5),下面的情况下将可能发生不足值:
1)读时遇到EOF。
2)从终端读文本行。
3)读和写网络套接字。
为了避免不足值问题(健壮程序的需求,如Web服务器这样的网络应用),就需要通过反复调用read和write处理不足值。
10.4 用RIO包壮健地读写
RIO包会自动处理不足值。提供了两类不同的函数:
-
无缓冲的输入输出函数
-
带缓冲的输入函数
1.无缓冲的输入输出函数
通过调用rioreadn和riowriten函数,应用程序可以在存储器和文件之间直接传送数据。
#include “csapp.h”
ssize_t rio_readn (int fd, void *usrbuf, size_t n);
ssize_t rio_writen (int fd, void *usrbuf, size_t n);
返回:若成功则为传送的字节数,若EOF则为0(只对rio_readn而言),若出错则为-1。

2.带缓冲的输入函数
1)文本行:一个由换行符结尾的ACSII码字符序列。Unix中换行符(\n)ACSII码换行符(LF)数字值均为0x0a。
2)包装函数(rio_readlineb):
从内部读缓冲区拷贝一个文件行,当缓冲区为空时,自动调用read填满缓冲区。
3)rio_readnb:
从和rio_readlineb一样的读缓冲区中传送原始字节。
#include “csapp.h”
void rio_readinitb(rio_t *rp, int fd)
返回:无
ssize_t rio_readlineb (rio_t *rp,void *usrbuf, size_t n);
ssize_t rio_readn (rio_t *rp, void *usrbuf, size_t n);
返回:若成功则为读的字节数,若EOF则为0,若出错则为-1。

10.5 读取文件元数据
-
元数据:应用程序能够通过调用stat和fstat函数,检索到关于关于文件的信息,如创建时间,修改时间,metadata。
#include <unistd.h> #include <sys/stat.h> int stat(const char *filename, struct stat *buf); int fstat(int fd, struct stat *buf); 返回: 若成功则为0,若出错则为-1.Stat函数以一个文件名作为输入,ftast以文件描述符作为输入。


-
函数是线程安全的:它在同一个描述符上可以被交替地调用。
10.6 共享文件
-
对于内核而言,文件文件和二进制文件毫无区别。
-
共享文件
内核用三种相关的数据结构来表示打开的文件。
1)描述符表:它的表项由进程打开的文件描述符来索引的。每个打开的描述符表项指向文件表中的一个选项。
2)文件表:打开文件的集合是一张文件表来表示的,所有的进程共享这张表。包括当前的文件位置、引用计数以及一个指向v-node表中对应表项的指针。
3)v-node表:同文件表一样,所有的进程共享这张v-node表。每个表项包含stat结构中的大部分信息,包括st_mode和st_size成员。
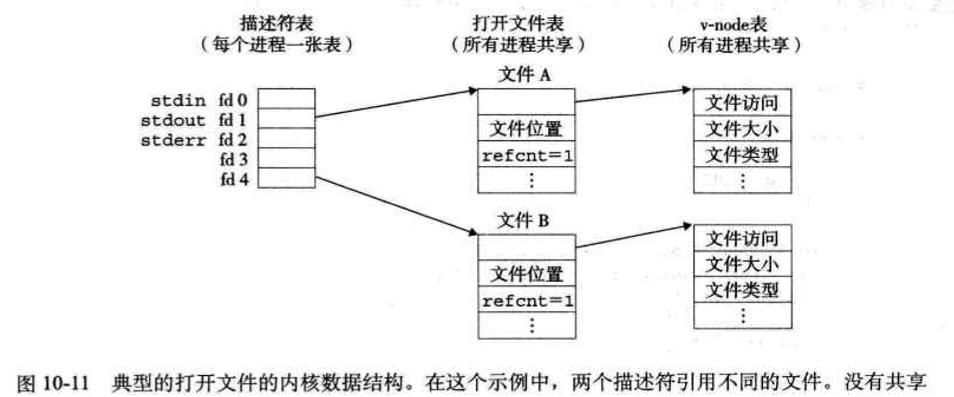
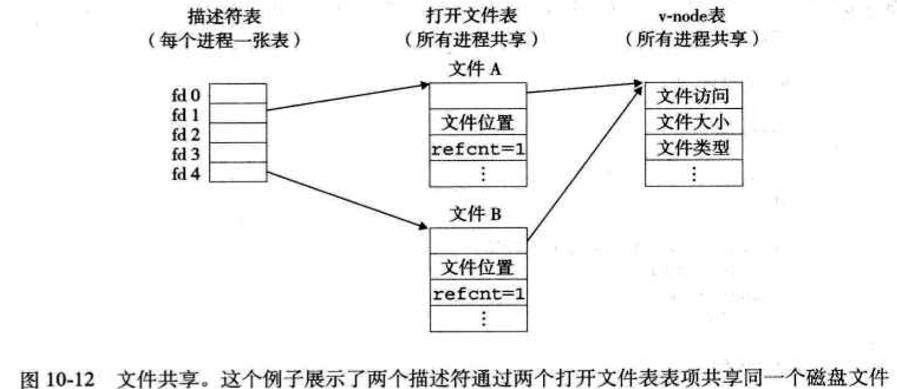

10.7 I/O重定向
-
I/O重定向操作符,允许用户将磁盘文件和标准输入输出联系起来:
unix > ls > foo.txt -
I/O重定向如何工作——使用dup2函数
#include <unistd.h> int dup2(int oldfd, int newfd); 返回:若成功则为非负的描述符,若出错则为-1.
实际是dup2函数(one case)。dup2函数对文件描述符表项进行重定位。

10.8 标准I/O
-
标准I/O :ANSI C定义的一组高级输入输出函数。如fopen,fclose,fread,fwrite,fgets,fputs,scanf,printf。
-
标准IO库将一个打开的文件模型化为一个流,对于程序员来说,一个流就是一个指向类型为FILE结构的一个指针。每个ANSI C程序开始都有三个打开的流stdin,stdout,stderr,分别对应于标准输入、输出、错误:
#include <stdio.h> extern FILE *stdin; extern FILE *stdout; extern FILE *sterr;!类型为FILE的流是对文件描述符和流缓冲区的抽象。
10.9 该使用哪些I/O函数

标准I/O流,从某种意义上而言是全双工的,因为程序能够在同一个流上执行输入和输出。但是有一些限定:
-
限制1: 跟在输出函数之后的输入函数。如果中间没有fflush,fseek,fsetpos或rewind的调用,一个输入函数不能跟随在一个输出函数之后。fflush清空与流相关的缓冲区,后三个函数使用unix I/O lseek函数来重置当前文件的位置。
-
限制2: 跟在输入函数之后的输出函数。情况类同上。 这些限定给网络应用带来一个问题:因为对套接字使用lseek是非法的。用Rio包可以解决这个问题。用sprintf把输出格式化一个字符串,通过riowriten输出,傅rioreadlineb来读一行,用scanf来从文本中提取不同的字段。
遇到的问题及解决办法:
首先学完本章之后总结为Unix系统I/O最基本的函数包括read和write等,所有的外部设备都被建模为文件,使得我们可以像读写文件一下读写外设。然后c语言标准I/O拥有应用级缓冲,而流的概念是对文件描述符和流缓冲区的抽象,流缓冲区的目的是为了减少Unix I/O系统调用,减少内核开销。但对最后的两个限制不太理解。后来经过查阅资料,看了网上一篇知乎上的一些回答,有了一定的理解。 但还有一点疑问就是执行定位后,一定会刷新缓冲区吗?写入后如果不fflush,那么其实可能还没有写入,可能写入了一部分,这时候读,是不是从哪里开始读是不可知的?
参考资料:
《深入理解计算机系统》
博客http://blog.csdn.net/jewes/article/details/8629004帮助理解了I/O
