[Python自学] day-3 (集合、文件、编码、函数)
一、集合
集合元素不会重复,而且是无序的。
定义集合:
set_1 = {1,2,3,4,5}
set求交集(intersection):
set1 = set([1,2,3,4,5,6]) set2 = set([4,5,6,7,8]) print(set1.intersection(set2))
set1 = set([1,2,3,4,5,6]) set2 = set([4,5,6,7,8]) print(set1.union(set2))
print(set1.difference(set2)) #set1里有,set2里没有的 print(set2.difference(set1)) #set2里有,set1里没有的
print(set2.issubset(set1)) #判断set2是否为set1的子集
print(set1.issuperset(set2)) #判断set1是否为set2的超集
list_1 = set([1,2,3,4,5,6]) list_2 = set([4,5,6,7,8,9]) print(list_1.symmetric_difference(list_2)) #输出{1,2,3,7,8,9}
判断两个集合是否不相交:
list_1 = set([1,2,3,4,5,6]) list_2 = set([7,8,9]) list_3 = set([6,7,8]) print(list_1.isdisjoint(list_2)) #输出True print(list_1.isdisjoint(list_3)) #输出False
集合运算符:
交集:set1 & set2
并集:set1 | set2
差集:set1 - set2
对称差集:set1 ^ set2
添加元素(add):
set_1.add(99)
set_1.remove(99) #删除一个不存在的元素会报错。 print(set_1.discard(100)) #删除一个不存在的元素返回None。
99 in set_1 #不存在:99 not in set_1
print(set_1.pop())
二、文件操作
对文件操作流程:
- 打开文件,得到文件操作句柄,并赋值给一个变量。
- 通过句柄对文件进行操作。
- 关闭文件。
打开文件:
data = open("ratherbe").read() print(data)
UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 41: illegal multibyte sequence
因为Windows默认gbk编码,必须制定使用utf-8编码打开。
data = open("ratherbe",encoding = "utf-8").read() print(data)
f = open("ratherbe",encoding = "utf-8",mode = "r") data = f.read() print(data)
打开模式,默认是"r",即读模式。
文件读取的时候,维护了一个光标指针,从第一行开始读,如果read()两次,第二次是读不到内容的。
写文件:需要打开写权限,w权限时,open时创建一个文件,若存在同名文件,会被空文件覆盖,切记!!!
f = open("ratherbe2","w",encoding = "utf-8") f.write("hello")
追加文件:使用mode = "a"参数。该模式下 不能读。
f = open("ratherbe2","a",encoding = "utf-8") f.write("World")
for i in range(5): #读取5行 line = f.readline().strip() print(line)
按行读取全部(readlines):注意文件大小,例如2G,20G的文件,不要全部读到内存中。
f.readlines() #返回一个列表,每一行是一个元素。
for line in f: print(line.strip())
获取读取光标位置(tell):
print(f.tell()) #返回当前读取光标的位置,初次打开文件,返回0
设置光标位置(seek):
f.seek(0) #将光标重置到文件开头,然后再次读取文件内容是否可移动光标(seekable):例如tty或其他设备是不能移动光标的。 print(f.seekable())
读取指定数量的字符(read(num)):
print(f.read(11))
print(f.fileno())
print(f.name) print(f.closed) print(f.encoding)
由于磁盘速度远利于内存,如果每次write都直接写硬盘,会造成IO瓶颈。所以文件写数据的机制是有一个不大的缓存区,当缓存满了后才会一次性触发写入操作。Flush是手工触发写入操作。
f = open("ratherbe1","a+",encoding="utf-8") f.write("Hello\n") f.flush()
import sys import time for i in range(100): sys.stdout.write("#") sys.stdout.flush() time.sleep(0.2)
f = open("ratherbe","a+",encoding="utf-8") print(f.truncate(10))
读写模式(r+):可读可写,但是写始终从第一行添加。
f = open("ratherbe","r+",encoding="utf-8")
追加读写模式(a+): 推荐使用。追加到最后。
在使用a+模式读时,默认的光标在最后,所以需要使用seek(0)将光标移动到最前面,再使用f.read()读。否则读不到内容。
但使用a+模式写的时候,都是从最后开始添加,无需指定seek。
Linux读取Windows文本文件(rU或r+U):该模式下,会自动将\r\n、\r \n转换为\n。即将windows下的换行符转换为linux下的换行符。
二进制读(rb):按二进制读文件,不能指定encoding="utf-8".
f = open("ratherbe","rb") print(f.readline()) #输出 b"We're a thousand miles from comfort,\r\n",b代表二进制
f = open("ratherbe","wb") f.write("hello world".encode())
f = open("ratherbe","ab") f.write("hello world".encode())
修改文件内容:有两种方式。
- 类似Linux中的vim。是将文件全部读到内存中,再在内存中修改。最后再全部写回文件。
- 一行一行读,然后匹配到要修改的部分,修改完毕后写到另外一个文件中,无需修改的部分直接写入新文件。例如:
f = open("ratherbe","r+",encoding="utf-8") f_new = open("ratherbe.bk","w",encoding="utf-8") for line in f: if "继续前行" in line: line = line.replace("继续前行","赶紧后退") f_new.write(line) f.close() f_new.close()
使用管理上下文来关闭文件:
1 with open("ratherbe","r+",encoding="utf-8") as f,open("ratherbe.bk","w",encoding="utf-8") as f_new: 2 for line in f: 3 if "继续前行" in line: 4 line = line.replace("继续前行","赶紧后退") 5 f_new.write(line)
Python官方约定:每一行代码不要超过80个字符。使用反斜杠(\)来换行。
with open("ratherbe","r+",encoding="utf-8") as f, \ open("ratherbe.bk","w",encoding="utf-8") as f_new:
三、字符编码与转码
参考博客:https://blog.csdn.net/qq_38412868/article/details/83278723
ASCII:英文占一个字节,不能存放中文。
Unicode(万国码):不管中文还是英文,都占两个字节。
UTF-8(可变长万国码):存放英文占一个字节,存放中文占三个字节。
Unicode兼容GBK、GB2312等各国编码。
UTF-8是Unicode的一个扩展集。Python3默认是Unicode编码集。
不同编码之间的转化,中间都通过Unicode。
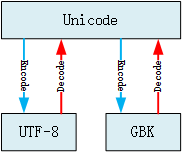
GBK需要转换为UTF-8格式流程:
- 首先通过解码(decode)转换为Unicode编码
- 然后通过编码(encode)转换为UTF-8编码
- 反之亦然
eg.在Python3中把中文转换成GBK:
在Python3.x中。默认字符集为Unicode,所以如以下:
s = "你好" s_to_gbk = s.decode() #s的编码集默认是Unicode。所以没有decode方法。运行报错。
s = "你好" s_to_gbk = s.encode("gbk")
s = "你好" s_to_gbk = s.encode("gbk") s_to_gbk.decode("gbk").encode("utf-8") #先使用decode把gbk转换为Unicode,再使用encode转换为utf-8。
编码(encode):将Unicode编码成其他编码,例如utf-8(Unicode的扩展编码集),GBK(中文),韩文、日文编码等。
encode("gbk") #参数为目标编码集
注意:该方法的参数为待转换字符串的当前编码集,例如python文件前面使用#-*- coding:utf-8 -*-后。定义的字符串应该为utf-8编码集,但是使用sys.getdefaultencoding()获取的系统默认编码集为ascii(python2.x为ascii,python3.x默认为Unicode,字符当前所处编码集若为Unicode,则不存在decode方法)。则decode的参数会默认为ascii,在这种情况下会出错,提示ascii码不能转换为Unicode。所以在这种情况下需要指定decode的参数为utf-8。
decode("gbk") #参数为待转换字符串的当前编码集(若不填写,则使用默认系统编码集)
查看系统默认编码集:例如Python2.x在Windows下编码默认是GBK。在Linux编码默认是ASCii。Python3.x默认都是Unicode。
import sys print(sys.getdefaultencoding()) #python2.x默认是ascii。python3.x默认Unicode,所以默认支持中文,并且变量名也支持中文。
注意:在py文件开头使用#-*- coding:utf-8 -*-指定该文件编码为utf-8。但是文件中定义的字符串变量例如s = "你好",的Unicode。
四、函数
三种编程模式和方法:
- 面向对象:类,class
- 面向过程:过程,def
- 函数式编程:函数,def
函数构造:
def function_name( x ): "Testing Function" print("This is the first Function.") y = x**2 return y
def:定义函数的关键字
funciton_name:函数名
():内可定义形参
"":函数描述,强烈建议为函数添加描述信息
return:函数返回值
函数与过程的区别:过程即没有返回值的函数。
def function_1(): #这是一个函数(有返回值) print("This is a Function") return 0 def function_2(): #这是一个过程(没有返回值) print("This is a Procedule") x = function_1() y = function_2() print(x) #输出0 print(y) #输出None(Python默认返回一个None)
日志打印时间:%y是年、%m是月、%d是日、%X是小时分钟秒
import time time_format="%y.%m.%d %X" current_time = time.strftime(time_format)
返回多个值:
def test1(): print("Return multi value") return 1,"hello",{"name":"leo"},["leo",32,"huadumeilinwan"] #返回值是一个元组
def test2(): return test1 #test1是一个函数名,返回<function test1 at 0x00AD55D0>,函数在内存中的地址
def test3(x,y): print(x,y) test3(y=5,x="hello") #指定参数名,可以调换参数的位置 def test3(x,y): print(x,y) test3(5,y="hello") #正确,先按位置参数,再按关键字。 def test3(x,y): print(x,y) test3(x=5,"hello") #报错
def test4(name = "Leo"): #默认参数name="Leo" print(name) test4("Kale") #若不传参,则打印"Leo"。
def test5(x,y=2): print(x) print(y) test5(1) #在有默认参数的时候,可以少传,系统会默认传递y test5(1,2,3) #不能有多余参数,报错 def test6(*args): #传递多个参数(位置参数) print(args) print(type(args)) #argv为参数组成的元组 test6(1,2,3,4,5)
字典参数:以关键字参数传入,并将关键字参数组织成一个字典。
def test7(**kwargs): #传递多个关键字参数,并组织成字典 print(kwargs) print(kwargs["name"]) test7(name="Leo",age=22,sex="male") #{'name': 'Leo', 'age': 22, 'sex': 'Male'} test7(**{"name":"Leo","age":22,"sex":"Male"}) #与上面一样
def test8(name,*args,**kwargs): print(name) print(args) #打印一个空的元组,() print(kwargs) #打印字典,{'sex': 'Male', 'age': 32} test8("Leo",sex = "Male",age=32) #由于后面都是关键字参数,所以都又kwargs接收。
函数调用:函数的定义必须在被调用之前,否则报错函数未定义。
def test10(): logger() test10() #报错,name 'logger' is not defined def logger(): print("logger")
局部变量和全局变量:
在顶层定义的变量为全局变量。函数内部定义的为局部变量。
name = "Leo" #全局变量name def show_name(): name = "Kale" #局部变量name print(name) #默认打印局部变量,输出Kale show_name() print(name) #默认打印全局变量,输出Leo
name = "Leo" def show_name(): global name #在函数内部把name声明为全局变量 name = "Kale" print(name) #输出Kale show_name() print(name) #输出Kale
注意:在函数中无法修改全局变量,仅限于整数、字符串等数据类型。列表、字典、集合、对象等可以在函数内部直接修改。例如:
names = ["zhengzhu","lei","li"] def test11(): names[1] = "Leo" print(names) test11() print(names)
五、递归函数
- 递归必须有一个明确的结束条件。
- 每次进入更深一层的递归时,问题规模相比上次都应该有所减少。
- 递归效率不高,递归层次过多会导致栈溢出。
eg.
def digui(x): y = x/2 y = int(y) if y > 0: #结束条件y=0 print(y) return digui(y) digui(99)
六、函数式编程
函数式编程是抽象度很高的编程范式。即输入一个值,对应输出也是一个确定的值,类似数学函数y=2x,x输入对应y的输出。
def functional(x): #函数式编程,x与y的值一一对应 y = 2x return y def function(x): #我们写的函数,可以根据x导致不同的返回值 if x > 0: y = 100/x else: y = 100*x return y
Python不是一个纯函数式编程语言。纯函数式编程语言有lisp、hashshell、erlang等。
函数式编程 eg.
def add(x,y): return x+y def multi(x,y): return x*y def sub(x,y): return x-y res = sub(multi(add(1,2),3),4) print(res)
七、高阶函数
一个函数接受另一个函数作为其参数,则该函数称为高阶函数。
def func(x,y): return x*y def function(a,b,func_name): #将一个函数名作为变量 return func(a+b,a-b) print(function(3,5,func)) #将func函数传入function函数
保持学习,否则迟早要被淘汰*(^ 。 ^ )***
