[Python自学] day-2 (模块、byte转换、执行过程、列表、字典、元组、字符串)
一、模块
模块分两种:标准库和第三方库,标准库是不需要安装就可以使用的库。
import [模块名]:导入一个库,优先是在项目路径中寻找。自定义模块名不要和标准库模块名相同。
1.sys模块
import sys print(sys.path)
sys.path保存的是Python内部调用或模块的查找路径。结果如下:
['D:\\pycharm_workspace\\FirstProject\\day2',
'D:\\pycharm_workspace\\FirstProject',
'D:\\Python36\\python36.zip',
'D:\\Python36\\DLLs',
'D:\\Python36\\lib',
'D:\\Python36',
'D:\\Python36\\lib\\site-packages']
sys.argv保存参数,第一个参数为该模块文件的相对路径,后面的参数加在一起形成一个列表。
os.system()执行一条系统命令。直接输出到屏幕,不能存到变量里,该方法返回状态码(0为成功)。
os.mkdir("new_dir"),在当前路径创建一个新目录。当目录已经存在时,会抛出异常。
 第一层的数据完全copy。第二层的数据未copy,copy的是内存地址。共同指向同一块内存区域。
判断是否是阿拉伯数字和字符(isalnum):
判断是否为纯英文字符(isalpha):包含大小写
判断是否为十进制(isdecimal)
判断是否全为小写(islower)
在前面使用字符填充(rjust):
全部转换为小写(lower)
替换(replace):
从右边开始查找返回索引(rfind):
按某个字符分割(split):
转换为Title(title):
用0在前面补位(zfill):主要用于16进制前面使用0补位。
添加一条:id5不存在时,则为添加。
删除:
修改id2中的年龄:
更新(update):若info与info2之间的key有交叉,则使用info2中的内容替代。没交叉的部分,在info里创建。
把字典转换为列表,每一个key-value转换为元组:
在这里,若fromkeys的第二个参数为二层以上结构。则dict1每个key对应的value为一个引用。修改其中一个,全部都会变化。
第一层的数据完全copy。第二层的数据未copy,copy的是内存地址。共同指向同一块内存区域。
判断是否是阿拉伯数字和字符(isalnum):
判断是否为纯英文字符(isalpha):包含大小写
判断是否为十进制(isdecimal)
判断是否全为小写(islower)
在前面使用字符填充(rjust):
全部转换为小写(lower)
替换(replace):
从右边开始查找返回索引(rfind):
按某个字符分割(split):
转换为Title(title):
用0在前面补位(zfill):主要用于16进制前面使用0补位。
添加一条:id5不存在时,则为添加。
删除:
修改id2中的年龄:
更新(update):若info与info2之间的key有交叉,则使用info2中的内容替代。没交叉的部分,在info里创建。
把字典转换为列表,每一个key-value转换为元组:
在这里,若fromkeys的第二个参数为二层以上结构。则dict1每个key对应的value为一个引用。修改其中一个,全部都会变化。
'D:\\Python36\\lib\\site-packages'中主要存放安装的第三方库。'D:\\Python36\\lib'主要放标准库。
import sys print(sys.argv)
2.os模块
import os os.system("dir") #只执行命令,不保存结果
import os cmd_res = os.popen("dir").read() print(cmd_res)
os.popen("dir")执行dir命令,并将结果存放到内存的某个区域,需要使用read()读取结果。
import os os.mkdir("new_dir")
3.第三方模块
即自定义的py文件(test.py)。在另外一个py文件中导入(import)该模块。使用import test。若IDE提示该模块No Module named test。则在项目目录或包含该文件的目录上点击右键,选择Mark Directory As->Source Root。
二、pyc
执行一个模块后,会在代码文件目录中出现一个__pycache__文件夹,该文件夹里存在与模块名对应的pyc文件。例如module1.cpython-36.pyc。
随着JAVA等基于虚拟机的语言兴起,不能把语言纯粹地分成解释性和编译型这两种。
JAVA首先是通过编译器编译成字节码文件,然后在运行时通过解释器给解释成机器码。所以我们说JAVA是一种先编译后解释的语言。
Python到底是什么:
Pyhton和Java/C#一样,也是一门基于虚拟机的语言。也是一门先编译后解释的语言。
三、Python执行过程
PyCodeObject:就是Pyhton编译器编译成的结果。当Python程序运行时,编译结果保存在内存中的PyCodeObject中,运行结束后回写到pyc文件中。当程序第二次执行时,首先会在硬盘中寻找pyc文件,找到就直接载入,否则就重复编译过程。如果pyc更新时间比源代码时间老,则需要重新编译。
四、数据类型初识
int:在C语言中,32位机器只能存-2**31~2**31-1,即-2147483648~2147483647。64位机器存-2**63~2**63-1。在Python中没有限制整型数值的大小,实际上机器内存有限,整型数值也不会是无限的。例如print(type(2**100)),输出是int。
float:小数,例如3.23。科学计数,5.2E-4,相当于5.2*10**-4。
布尔值:真或假(Ture/False),1或0(只有1和0代表真假)。
五、三元运算
result = 值1 if 条件 else 值2。即当if条件成立时,result为值1,否则为值2.
eg.
a,b,c = 1,3,5 result = a if a>b else c print(result)
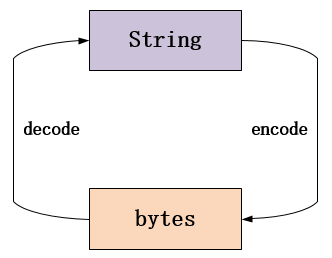
六、bytes和str
在Python3中,对文本和二进制数据做了更为清晰的区分。文本总是Unicode,由str表示,二进制数据则由Bytes类型表示。
str和bytes之间可以互相转换。如下图所示:
eg.
msg = "我爱北京天安门".encode("utf-8") print(msg) msg = msg.decode("utf-8") print(msg)
将"我爱北京天安门"使用encode()编码成二进制,参数指定待转换的文本编码为utf-8,默认为utf-8。然后decode()解码成文本。
七、列表
定义一个列表:
names = []
names = ["Leo","Alex","Jack","Leno"]
取一个值:
index=1
names[index] #取出Alex。
切片:
取一个范围的值:names[1:3],取出["Alex","Jack"],左边的1包含,右边的3不包含。names[0:3]和names[:3]是一样的。
取最后的值:names[-1],取出Leno。
取最后一段的值:names[-2:],取出["Jack","Leno"]。
跳着切片:names[0:-1:2],从第一个取到倒数第二个,没取一个跳过一个。
追加(append):names.append("成龙")。
插入(insert):names.insert(1,"成龙"),把成龙放到了index为1的位置,后面的名字依次后移。
替换:names[1] = "杨幂",直接写入某个位置,把成龙替换为杨幂。
删除(remove):三种方法:names.remove("杨幂")。del names[1]。names.pop(1)。pop()若不填写下标,则默认删除最后一个。
查找下标(index):names.index("杨幂"),返回第一个杨幂的下标。
清除(clear):names.clear()
翻转(reverse):names.reverse()
排序(sort):names.sort()。默认是特殊字符>数字>大写>小写,按ASCII码来排序的。
合并(extend):names.extend(names2)。将names2列表加到names后面。合并后name2仍然存在。
复制(copy):names2 = names.copy()。只拷贝第一层数据,为浅COPY。第二层是存的引用,所以拷贝的是指针。注意注意!!!
eg.
names = [1,2,3,['a','b'],4,5] names2 = names.copy() names2[2] = 10 names2[3][1] = 'c' print(names) print(names2)
若要使用真正的copy则需要导入copy模块:
import copy names = [1,2,3,['a','b'],4,5] names2 = copy.copy(names) #和list中的copy是一摸一样的 names3 = copy.deepcopy(names) #深度copy,真正意义上的copy。但用得少,占两份完整的内存空间。
列表循环:
num = [0,1,2,3,4,5,6,7,8,9,10] for i in num[0:-1:2]: print(i)
八、元组
即不可变的列表,可称为只读列表。使用( )表示。
names = ("192.168.1.100","admin","passwd")
例如,使用元组来保存不可变数据,例如数据库连接信息。
九、判断值是否为数值
例如输入8,实际上input接受到的是字符串,需要使用int(num)来强制转换为int类型。
num = input("please input a num") if num.isdigit(): num = int(num)
十、字符串操作
字符串的值是不能更改的,所有在字符串上做的改变操作,内部都是重新产生了一个字符串来覆盖原本的字符串。
name = "leo zheng leokale"
首字母大写(capitalize):name = name.capitalize(),输出"Leo zheng leokale"
统计字母或字符串出现次数(count):name.count('e'),输出2。name.count('leo'),输出2。
填充并居中(center):name.center(50,"*"),若name中的字符串不够50个字符,则使用'*'填充够50个。并且将name的字符串居中。
****************leo zheng leokale*****************
判断是否已指定字符结尾(endswith):name.endswith('le'),输出True。
将tab转换为指定个数的空格(expandtabs):name = "leo \tzheng" name.expandtabs(tabsize = 30),将\t转换为30个空格。
查找指定字符或字符串的索引(find):name.find('o'),输出2。默认只找出第一个。或者name.find('ka'),返回13。
格式化(format)(常用):name = "my name is {myname}" print(name.format(myname = "Leokale")),输出"my name is Leokale"。
name = "my name is {name},I am {year} years old." print(name.format(name = "Leokale",year = 32))
格式化(format_map):
name = "my name is {name},I am {year} years old." print(name.format_map({"name":"leokale","year":32}))
print("123".isalnum()) #输出True print("123abc".isalnum()) #输出True print("123abc*".isalnum()) #输出False
print("abcABC".isalpha()) #返回True print("abcABC123".isalpha()) #返回False
判断是否为整数(isdigit)
判断是否为一个合法的标识符(isidentifier):即是否是一个合法的变量名。
print("my_name".isidentifier()) #输出True print("--my_name".isidentifier()) #输出false
判断是否全为大写(isupper)
判断是否是纯数字(isnumeric):几乎同isdigit。即判断是否为整数。
判断是否为Title(istitle):即每个单词首字母大写,其他都小写。
判断是否可打印(isprintable):tty file,drive file无法打印。
将一个队列变成字符串(join):
print("+".join(["my","name",'is','leokale'])) #输出my+name+is+leokale
在后面使用字符填充(ljust):
print("name".ljust(20,'*')) #输出name****************
print("name".rjust(20,'*'))
全部转换为大写(upper)
去掉前后的空格和换行符(strip):
name = " name \n" print(name.strip())
去掉左边的空格和换行符(lstrip)
去掉右边的空格和换行符(rstrip)
密码翻译(maketrans):
name = "leokale good day is today" ppp = str.maketrans("leokalgdys","123456789*") #数量要对应 print(name.translate(ppp))
print("namea".replace("a","*",2)) #输出 n*me*
print("leokale".rfind('l')) #输出5
print("my name is leo".split()) #输出['my', 'name', 'is', 'leo'] print("my+name+is+leo".split('+'))
按换行分割(splitlines):在不同系统中按换行符分割(windows和linux不同)。
互换大小写(swapcase):
print("Name".swapcase()) #输出 nAME
print("good thing".title()) #输出 Good Thing
十一、字典
字典是一种key-value数据类型。语法:
info = { 'id1':'Leo', 'id2':'Jack', 'id3':'Alex', 'id4':'Song' }
- dict是无序的,没有下标索引。打印出来,顺序是乱的。
- key必须是唯一的,天生去重。
打印结果:
print(info)
{'id1': 'Leo', 'id2': 'Jack', 'id3': 'Alex', 'id4': 'Song'}
取值:
print(info['id1']) #输出 leo
修改:
info['id1'] = 'Kale' print(info['id1']) #输出 Kale
info['id5'] = 'Lily'
del info['id2'] print(info) info.pop('id2') print(info) info.popitem() #随机删除一个 print(info)
查找:
if 'id1' in info: #'id1' in info,若存在返回True,不存在返回False。列表和元组也可以这样判断。 print("id1存在")
字典嵌套:
1 info = { 2 'id1':{ 3 'name':'Leo', 4 'age':32 5 }, 6 'id2':{ 7 'name':'Boob', 8 'age':12 9 }, 10 'id3':{ 11 'name':'Alex', 12 'age':22 13 }, 14 'id4':{ 15 'name':'Jack', 16 'age':56 17 } 18 }
info['id2']['age'] = 44 print(info)
取值,若不存在则创建该值,若存在则取出该值(setdefault):
info.setdefault('id5',{'name':"武藤兰"}) print(info) #添加了id5,name为武藤兰 info.setdefault('id5',{'name':"藤原爱"}) print(info) #已经存在id5,则返回{'name':'武藤兰'}
info2 = { 'id1':{ 1:2, 2:3 } } info.update(info2)
print(info.items()) #输出dict_items([('id1', {1: 2, 2: 3}), ('id2', {'name': 'Boob', 'age': 12}), ('id3', {'name': 'Alex', 'age': 22}), ('id4', {'name': 'Jack', 'age': 56})]) info_list = list(info.items())
初始化一个字典(fromkeys):
dict1 = dict.fromkeys([1,2,3,4],"test") print(dict1)
dict1 = dict.fromkeys([1,2,3,4],{'name':'leo'})
dict1[1]['name'] = "Jack"
print(dict1) #输出 {1: {'name': 'Jack'}, 2: {'name': 'Jack'}, 3: {'name': 'Jack'}, 4: {'name': 'Jack'}}
循环读取:
for key in info: #建议使用这种,高效。 print(key,info[key]) for k,v in info.items(): #有一个把字典转换为列表的过程,效率比较低,数据量大的时候体现明显。 print(k,v)
保持学习,否则迟早要被淘汰*(^ 。 ^ )***
