
RabbitMQ 安装及常用操作命令
一、什么是RabbitMQ
RabbitMQ 即一个消息队列,主要是用来实现应用程序的异步和解耦,同时也能起到消息缓冲,消息分发的作用。
RabbitMQ使用erlang语言开发(由爱立信公司开发 可以做到“热插拔”,如django改了代码后自动重启web服务,而erlang改了代码后局部立刻生效,不需重启服务,可以将改了的模块直接加载到系统里)
与python中进程线程的区别:
1、RabbitMQ允许不同应用、程序间交互数据
2、python中的Threading queue只能允许单进程内多线程交互的
3、python中的MultiProcessing queue只能允许父进程与子进程或同父进程的多个子进程交互
应用场景:
电商秒杀活动
抢购小米手机
堡垒机批量发送文件
谈到队列服务, 会有三个概念: 发消息者、队列、收消息者,RabbitMQ 在这个基本概念之上, 多做了一层抽象, 在发消息者和 队列之间, 加入了交换器 (Exchange). 这样发消息者和队列就没有直接联系, 转而变成发消息者把消息给交换器, 交换器根据调度策略再把消息再给队列。
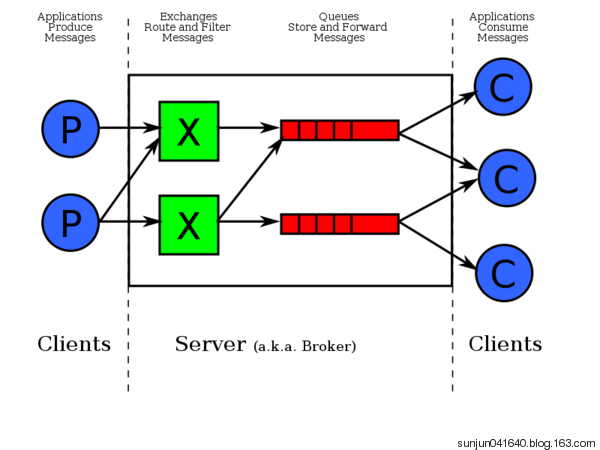
- 左侧 P 代表 生产者,也就是往 RabbitMQ 发消息的程序。
- 中间即是 RabbitMQ,其中包括了 交换机 和 队列。
- 右侧 C 代表 消费者,也就是往 RabbitMQ 拿消息的程序。
那么,其中比较重要的概念有 4 个,分别为:虚拟主机,交换机,队列,和绑定。
- 虚拟主机:一个虚拟主机持有一组交换机、队列和绑定。为什么需要多个虚拟主机呢?很简单,RabbitMQ当中,用户只能在虚拟主机的粒度进行权限控制。 因此,如果需要禁止A组访问B组的交换机/队列/绑定,必须为A和B分别创建一个虚拟主机。每一个RabbitMQ服务器都有一个默认的虚拟主机“/”。
- 交换机:Exchange 用于转发消息,但是它不会做存储 ,如果没有 Queue bind 到 Exchange 的话,它会直接丢弃掉 Producer 发送过来的消息。
这里有一个比较重要的概念:路由键 。消息到交换机的时候,交换机会转发到对应的队列中,那么究竟转发到哪个队列,就要根据该路由键。 - 绑定:也就是交换机需要和队列进行绑定,这其中如上图所示,是多对多的关系。
交换机(Exchange)
交换机的功能主要是接收消息并且转发到绑定的队列,交换机不存储消息,在启用ack模式后,交换机找不到队列会返回错误。交换机有四种类型:Direct, topic, Headers and Fanout
- Direct:direct 类型的行为是"先匹配, 再投送". 即在绑定时设定一个 routing_key, 消息的routing_key 匹配时, 才会被交换器投送到绑定的队列中去. (组播)
- Topic:按规则转发消息(最灵活)
- Headers:设置header attribute参数类型的交换机
- Fanout:转发消息到所有绑定队列 (广播)
Direct Exchange
Direct Exchange是RabbitMQ默认的交换机模式,也是最简单的模式,根据key全文匹配去寻找队列。

第一个 X - Q1 就有一个 binding key,名字为 orange; X - Q2 就有 2 个 binding key,名字为 black 和 green。当消息中的 路由键 和 这个 binding key 对应上的时候,那么就知道了该消息去到哪一个队列中。
Ps:为什么 X 到 Q2 要有 black,green,2个 binding key呢,一个不就行了吗? - 这个主要是因为可能又有 Q3,而Q3只接受 black 的信息,而Q2不仅接受black 的信息,还接受 green 的信息。
Topic Exchange
Topic Exchange 转发消息主要是根据通配符。 在这种交换机下,队列和交换机的绑定会定义一种路由模式,那么,通配符就要在这种路由模式和路由键之间匹配后交换机才能转发消息。
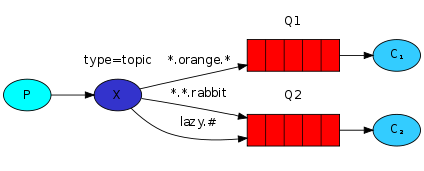
在这种交换机模式下:
- 路由键必须是一串字符,用句号(
.) 隔开,比如说 agreements.us,或者 agreements.eu.stockholm 等。 - 路由模式必须包含一个 星号(
*),主要用于匹配路由键指定位置的一个单词,比如说,一个路由模式是这样子:agreements.b.*,那么就只能匹配路由键是这样子的:第一个单词是 agreements,第二个单词是 b,第三个单词任意一个单词。 井号(#)就表示相当于一个或者多个单词,例如一个匹配模式是agreements.eu.berlin.#,那么,以agreements.eu.berlin开头的路由键都是可以的。
topic 和 direct 类似, 只是匹配上支持了"模式", 在"点分"的 routing_key 形式中, 可以使用两个通配符:
*表示一个词.#表示零个或多个词.
Headers Exchange
headers 也是根据规则匹配, 相较于 direct 和 topic 固定地使用 routing_key , headers 则是一个自定义匹配规则的类型.
在队列与交换器绑定时, 会设定一组键值对规则, 消息中也包括一组键值对( headers 属性), 当这些键值对有一对, 或全部匹配时, 消息被投送到对应队列.
Fanout Exchange
Fanout Exchange 消息广播的模式,不管路由键或者是路由模式,会把消息发给绑定给它的全部队列,如果配置了routing_key会被忽略。
二、windows下安装RabbitMQ
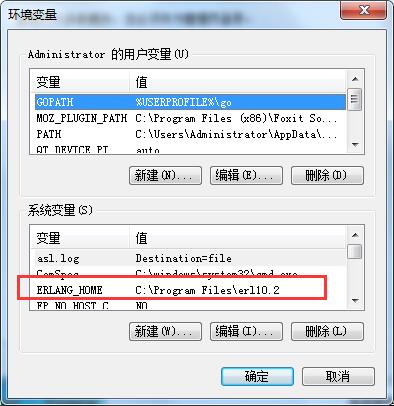
1、安装Erlang
Rabbit MQ 是建立在Erlang OTP平台上,所以在安装rabbitMQ之前,需要先安装Erlang
官网下载安装,全部点“下一步”就行
安装完成之后添加一下系统环境变量
2、安装RabbitMQ
官网下载,默认安装的RabbitMQ监听端口是5672
3、配置RabbitMQ
激活 RabbitMQ's Management Plugin ,使用RabbitMQ 管理插件,可以更好的可视化方式查看Rabbit MQ 服务器实例的状态
打开命令行窗口输入命令:
C:\Users\Administrator>"C:\Program Files\RabbitMQ Server\rabbitmq_server-3.7.11\ sbin\rabbitmq-plugins.bat" enable rabbitmq_management
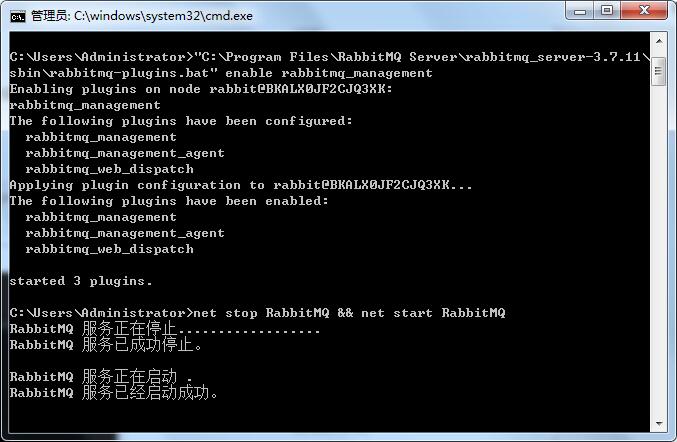
激活插件后需重启服务:
net stop RabbitMQ && net start RabbitMQ
若报错:“发生错误:发生系统错误 5。 拒绝访问。” 则使用管理员权限打开cmd再执行此命令
4、创建用户,密码及绑定角色
使用rabbitmqctl控制台命令(位于C:\Program Files\RabbitMQ Server\rabbitmq_server-3.7.11\sbin>)来创建用户,密码,绑定权限等。
rabbitmq的用户管理包括增加用户,删除用户,查看用户列表,修改用户密码。
查看已有用户及用户的角色:
c:\Program Files\RabbitMQ Server\rabbitmq_server-3.7.11\sbin>rabbitmqctl.bat list_users Listing users ... user tags guest [administrator]
新增一个用户:
命令:rabbitmqctl.bat add_user username password
c:\Program Files\RabbitMQ Server\rabbitmq_server-3.7.11\sbin>rabbitmqctl.bat add_user lee 123 Adding user "lee" ... c:\Program Files\RabbitMQ Server\rabbitmq_server-3.7.11\sbin>rabbitmqctl.bat list_users Listing users ... user tags lee [] guest [administrator]
添加角色:
命令:rabbitmqctl.bat set_user_tags username administrator c:\Program Files\RabbitMQ Server\rabbitmq_server-3.7.11\sbin>rabbitmqctl.bat set_user_tags lee administrator Setting tags for user "lee" to [administrator] ... c:\Program Files\RabbitMQ Server\rabbitmq_server-3.7.11\sbin>rabbitmqctl.bat list_users Listing users ... user tags lee [administrator] guest [administrator]
添加多个角色:
命令:rabbitmqctl.bat set_user_tags username tag1 tag2 ...
c:\Program Files\RabbitMQ Server\rabbitmq_server-3.7.11\sbin>rabbitmqctl.bat set_user_tags lee administrator monitoring Setting tags for user "lee" to [administrator, monitoring] ...
更改用户密码:
命令:rabbitmqctl.bat change_password userName newPassword
c:\Program Files\RabbitMQ Server\rabbitmq_server-3.7.11\sbin>rabbitmqctl.bat change_password lee 123456 Changing password for user "lee" ...
删除用户:
命令:rabbitmqctl.bat delete_user username
c:\Program Files\RabbitMQ Server\rabbitmq_server-3.7.11\sbin>rabbitmqctl.bat delete_user lee Deleting user "lee" ...
rabbitmq用户角色可分为五类:超级管理员, 监控者, 策略制定者, 普通管理者以及其他。
(1) 超级管理员(administrator)
可登陆管理控制台(启用management plugin的情况下),可查看所有的信息,并且可以对用户,策略(policy)进行操作。
(2) 监控者(monitoring)
可登陆管理控制台(启用management plugin的情况下),同时可以查看rabbitmq节点的相关信息(进程数,内存使用情况,磁盘使用情况等)
(3) 策略制定者(policymaker)
可登陆管理控制台(启用management plugin的情况下), 同时可以对policy进行管理。
(4) 普通管理者(management)
仅可登陆管理控制台(启用management plugin的情况下),无法看到节点信息,也无法对策略进行管理。
(5) 其他的
无法登陆管理控制台,通常就是普通的生产者和消费者。
使用浏览器打开 http://localhost:15672 访问Rabbit Mq的管理控制台,使用刚才创建的账号登陆系统:
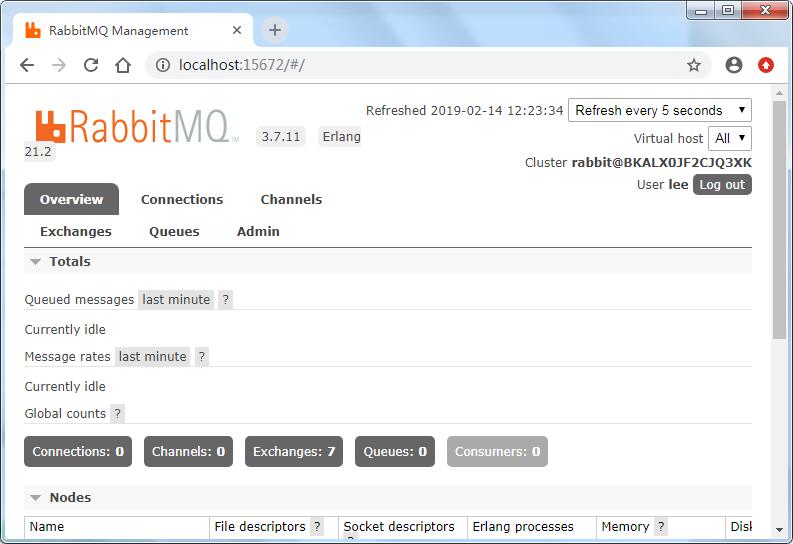
除了可查看所有的信息 ,上面的命令 增删改查、权限设置,都可以在这个页面完成,还可以依据业务需求设置策略(policy)
权限设置
用户权限指的是用户对exchange,queue的操作权限,包括配置权限,读写权限。
读写权限影响到从queue里取消息、向exchange发送消息以及queue和exchange的绑定(binding)操作。
例如: 将queue绑定到某exchange上,需要具有queue的可写权限,以及exchange的可读权限;向exchange发送消息需要具有exchange的可写权限;从queue里取数据需要具有queue的可读权限
权限相关命令为:
(1) 设置用户权限
rabbitmqctl set_permissions -p VHostPath User ConfP WriteP ReadP
sudo rabbitmqctl set_permissions -p / lee ".*" ".*" ".*"
sudo rabbitmqctl set_permissions -p / lee1 ".*" ".*" ""
(2) 查看(指定hostpath)所有用户的权限信息
rabbitmqctl list_permissions [-p VHostPath]
C:\Program Files\RabbitMQ Server\rabbitmq_server-3.7.11\sbin>rabbitmqctl.bat list_permissions Listing permissions for vhost "/" ... user configure write read guest .* .* .*
(3) 查看指定用户的权限信息
rabbitmqctl list_user_permissions User
C:\Program Files\RabbitMQ Server\rabbitmq_server-3.7.11\sbin>rabbitmqctl.bat list_user_permissions lee Listing permissions for user "lee" ... vhost configure write read / .* .*
(4) 清除用户的权限信息
rabbitmqctl clear_permissions [-p VHostPath] User
C:\Program Files\RabbitMQ Server\rabbitmq_server-3.7.11\sbin>rabbitmqctl.bat clear_permissions lee Clearing permissions for user "lee" in vhost "/" ... C:\Program Files\RabbitMQ Server\rabbitmq_server-3.7.11\sbin>rabbitmqctl.bat list_user_permissions lee Listing permissions for user "lee" ...
三、python中操作RbbitMQ
RabbitMQ支持不同的语言,对于不同语言有相应的模块,这些模式支持使用开发语言连接RabbitMQ
Python连接RabbitMQ模块有:
1.pika主流模块
2.Celery分布式消息队列
3.Haigha提供了一个简单的使用客户端库来与AMQP代理进行交互的方法
使用RabbitMQ前,首先阅读开始文档: http://www.rabbitmq.com/getstarted.html
简单的发送接收实例
默认情况下,使用同一队列的进程,接收消息方使用轮询的方式,依次获取消息
对于一条消息的接收来说,只有当接收方收到消息,并处理完消息,给RabbitMQ发送ack,队列中的消息才会删除
如果在处理的过程中socket断开,那么消息自动转接到下一个接收方
安装python rabbitMQ module
pip install pika
发送端即生产者:
1 import pika 2 #credentials = pika.PlainCredentials('用户名','密码') 3 #connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.14.52', credentials=credentials)) #远程访问 4 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) #相当于链创建了一个socket 5 channel = connection.channel() #建立了rabbit协议的通道 6 7 #声明queue 8 channel.queue_declare(queue='hello') 9 channel.basic_publish(exchange='',routing_key='hello',body='Hello World!') #发送到队列中去了 不接收就一直存在 10 print(" [x] Sent 'Hello World!'") 11 connection.close()
接收端即消费者:
1 import pika 2 3 conn = pika.BlockingConnection(pika.ConnectionParameters("localhost")) 4 channel = conn.channel() 5 6 #再次声明一个queue的原因是我们不知道是生产者还是消费者谁先启动,假如消费者先启动了而此时还没有queue就报错了,生产者声明了queue,消费者会先检查一遍 有queue就不再自己生成了 7 channel.queue_declare(queue='h1') 8 9 def callback(ch, method, properties, body): #拿到消息后调用此方法 10 #ch为channel通道的实例 11 #<BlockingChannel impl=<Channel number=1 OPEN conn=<SelectConnection OPEN socket=('::1', 58747, 0, 0)->('::1', 5672, 0, 0) params=<ConnectionParameters host=localhost port=5672 virtual_host=/ ssl=False>>>> 12 #method为<Basic.Deliver(['consumer_tag=ctag1.73eb90c0953f466db93f173e2750407d', 'delivery_tag=1', 'exchange=', 'redelivered=False', 'routing_key=h1'])> 13 #properties是空的 <BasicProperties> 14 #body为发送端发送的字节数据 b'asdfasdfasdf!' 15 print('received %r' % body) 16
17 channel.basic_consume(callback, queue='h1', no_ack=True) #从h1队列中取数据
18 #注:no_ack=true(此时为自动应答)的情况下,consumer会在接收到数据之后,立即回复Ack。而这个Ack是TCP协议中的Ack。此Ack的回复不关心consumer是否对接收到的数据进行了处理,当然也不关心处理数据所需要的耗时.服务端收到ack会立即将缓存中的message删除,而no_ack=False则数据一直存在 直到重启rabbitmq服务
19 print("waiting for messages") 20 channel.start_consuming() #死循环 一直等待
注:连接远程rabbitmq server的话,需要配置权限
首先在rabbitmq server上创建一个用户
sudo rabbitmqctl add_user name password #rabbitmqctl为rabbitmq的管理工具
rabbitmqctl set_user_tags name administrator #设置角色
同时还要配置权限
sudo rabbitmqctl set_permissions -p / lee ".*" ".*" ".*"
可通过命令行去查看队列
rabbitmqctl list_queues
也可通过打开浏览器http://localhost:15672/ 去查看
运行上述代码,先启动消息生产者,然后再分别启动3个消费者,通过生产者多发送几条消息,你会发现,这几条消息会被依次分配到各个消费者身上
在这种模式下,RabbitMQ会默认把p发的消息依次分发给各个消费者(这次发给了C1,下次就发给C2),跟负载均衡差不多
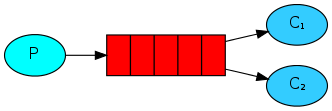
消息确认
完成一项任务可能需要几秒钟。你可能想知道,如果一个消费者开始了一项长任务,但只完成了一部分就死了,会发生什么。一旦rabbitmq将消息传递给客户,它就会立即将其从内存中删除。在这种情况下,如果您杀死一个工人,我们将丢失它正在处理的消息。我们还将丢失发送给这个特定工作人员但尚未处理的所有消息。
但我们不想失去任何任务。如果一个工人死了,我们希望把任务交给另一个工人。
为了确保消息不会丢失,rabbitmq支持消息确认。确认(nowledgement)从使用者发送回来,告诉rabbitmq特定消息已被接收、处理,rabbitmq可以自由删除它。
如果使用者在没有发送ACK的情况下死亡(其通道关闭、连接关闭或TCP连接丢失),rabbitmq将理解消息没有完全处理,并将重新对其进行排队。如果有其他消费者同时在线,它会很快将其重新发送给其他消费者。这样,即使工人偶尔死亡,你也可以确保没有信息丢失。
没有任何消息超时;当使用者死亡时,rabbitmq将重新传递消息。即使处理消息需要很长的时间,也可以。
1 import pika 2 import time 3 conn = pika.BlockingConnection(pika.ConnectionParameters("localhost")) 4 channel = conn.channel() 5 6 channel.queue_declare(queue='h1') 7 8 def callback(ch, method, properties, body): 9 print('received %r' % body) 10 time.sleep(20) 11 print("done") 12 13 #手动返回确认标识 14 ch.basic_ack(delivery_tag=method.delivery_tag) #delivery_tag为RabbitMQ生成的随机的一个值 消息处理完后要给服务端一个确认 标记处理的任务是哪一个 15 16 channel.basic_consume(callback, queue='h1') #no_ack=false (此时为手动应答)要求consumer在处理完接收到的数据之后才回复Ack,而这个Ack是AMQP协议中的Basic.Ack。此Ack的回复是和业务处理相关的,所以具体的回复时间应该要取决于业务处理的耗时 17 print("waiting for messages") 18 channel.start_consuming()
使用这段代码,我们可以确保即使您在处理消息时使用ctrl+c杀死了一个工人,也不会丢失任何东西。工人死后不久,所有未确认的信息将被重新传送。
持久化
我们已经学习了如何确保即使消费者死亡,任务也不会丢失(默认情况下,如果要禁用,请使用no-ack=true)。但如果rabbitmq服务器停止,我们的任务仍然会丢失。
当rabbitmq退出或崩溃时,它将忘记队列和消息,除非您告诉它不要这样做。要确保消息不会丢失,需要做两件事:我们需要将队列和消息标记为持久的。
队列持久化:
我们需要确保rabbitmq不会丢失队列。要做到这一点,我们需要声明它是持久的:
channel.queue_declare(queue='hello', durable=True)
#注:如果 delivery_mode没有设置等于2 重启服务之后 队列还在 但里面的数据没了
注:如果我们已经定义了一个名为hello的队列,它是不持久的。rabbitmq不允许您用不同的参数重新定义现有队列,并将向任何试图这样做的程序返回错误。但是有一个快速的解决方法-让我们声明一个具有不同名称的队列,例如任务队列:
channel.queue_declare(queue='task_queue', durable=True)
此队列声明更改需要同时应用于生产者和消费者代码。
消息持久化:
channel.basic_publish(exchange='', routing_key="task_queue", body=message, properties=pika.BasicProperties( delivery_mode = 2, # make message persistent ))
消息公平分发
如果Rabbit只管按顺序把消息发到各个消费者身上,不考虑消费者负载的话,很可能出现,一个机器配置不高的消费者那里堆积了很多消息处理不完,同时配置高的消费者却一直很轻松。为解决此问题,可以在各个消费者端,配置perfetch=1,意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了。

消费者端:
1 import pika 2 import time 3 4 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) 5 channel = connection.channel() 6 7 channel.queue_declare(queue='task_queue', durable=True) 8 print(' [*] Waiting for messages. To exit press CTRL+C') 9 10 def callback(ch, method, properties, body): 11 print(" [x] Received %r" % body) 12 time.sleep(body.count(b'.')) 13 print(" [x] Done") 14 ch.basic_ack(delivery_tag = method.delivery_tag) 15 16 channel.basic_qos(prefetch_count=1) #basic_qos流量控制 一次只拿一个任务 处理不完就不要发给我了 17 channel.basic_consume(callback,queue='task_queue')
18 channel.start_consuming()
Publish\Subscribe(消息发布\订阅)
之前的例子都基本都是1对1的消息发送和接收,即消息只能发送到指定的queue里,但有些时候你想让你的消息被所有的Queue收到,类似广播的效果,这时候就要用到exchange了
交换机的功能主要是接收消息并且转发到绑定的队列,交换机不存储消息,在启用ack模式后,交换机找不到队列会返回错误。
注:使用RoutingKey为#,Exchange Type为topic的时候相当于使用fanout
发送端:
1 import pika 2 import sys 3 4 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) 5 channel = connection.channel() 6 7 #声明一个交换机 8 channel.exchange_declare(exchange='logs', 9 exchange_type='fanout') #广播出去了 没人接收就没有了 是实时的不会保留 10 11 message = ' '.join(sys.argv[1:]) or "info: Hello World!" 12 channel.basic_publish(exchange='logs', 13 routing_key='', #用于设置转发到哪个queue 这里就不用写了 因为是广播模式 14 body=message) 15 print(" [x] Sent %r" % message) 16 connection.close()
接收端:
1 import pika 2 3 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) 4 channel = connection.channel() 5 6 channel.exchange_declare(exchange='logs', 7 exchange_type='fanout') 8 9 result = channel.queue_declare(exclusive=True) # 不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除,程序运行的时候可通过 rabbitmqctl list_queues查看 10 queue_name = result.method.queue 11 12 channel.queue_bind(exchange='logs', 13 queue=queue_name) 14 15 print(' [*] Waiting for logs. To exit press CTRL+C') 16 17 18 def callback(ch, method, properties, body): 19 print(" [x] %r" % body) 20 21 22 channel.basic_consume(callback, 23 queue=queue_name, 24 no_ack=True) 25 26 channel.start_consuming()
有选择的接收消息(exchange type=direct)
RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。

生产者:
1 import pika 2 import sys 3 4 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) 5 channel = connection.channel() 6 7 channel.exchange_declare(exchange='direct_logs', exchange_type='direct') 8 9 severity = sys.argv[1] if len(sys.argv) > 1 else 'info' 10 message = ' '.join(sys.argv[2:]) or 'Hello World!' 11 channel.basic_publish(exchange='direct_logs', 12 routing_key=severity, 13 body=message) 14 print(" [x] Sent %r:%r" % (severity, message)) 15 connection.close()
消费者:
1 import pika 2 import sys 3 4 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) 5 channel = connection.channel() 6 7 channel.exchange_declare(exchange='direct_logs',exchange_type='direct') 8 9 result = channel.queue_declare(exclusive=True) 10 queue_name = result.method.queue 11 12 severities = sys.argv[1:] #python getmsg.py info error -->severities=["info", "error"] 13 14 if not severities: 15 sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0]) 16 sys.exit(1) 17 18 for severity in severities: 19 channel.queue_bind(exchange='direct_logs', 20 queue=queue_name, 21 routing_key=severity) 22 23 print(' [*] Waiting for logs. To exit press CTRL+C') 24 25 def callback(ch, method, properties, body): 26 print(" [x] %r:%r" % (method.routing_key, body)) 27 28 channel.basic_consume(callback, 29 queue=queue_name, 30 no_ack=True) 31 32 channel.start_consuming()
更细致的消息过滤(topic)
在我们的日志系统中,我们可以根据事件级别进行订阅,如上。但我们可能还需要更细致的过滤,如我想知道某个应用程序的日志,这时就可以通过topic来进行过滤

生产者:
1 import pika 2 import sys 3 4 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) 5 channel = connection.channel() 6 7 channel.exchange_declare(exchange='topic_logs',exchange_type='topic') 8 9 routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info' 10 message = ' '.join(sys.argv[2:]) or 'Hello World!' 11 channel.basic_publish(exchange='topic_logs', 12 routing_key=routing_key, 13 body=message) 14 print(" [x] Sent %r:%r" % (routing_key, message)) 15 connection.close()
消费者:
1 import pika 2 import sys 3 4 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) 5 channel = connection.channel() 6 7 channel.exchange_declare(exchange='topic_logs',exchange_type='topic') 8 9 result = channel.queue_declare(exclusive=True) 10 queue_name = result.method.queue 11 12 binding_keys = sys.argv[1:] 13 if not binding_keys: 14 sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0]) 15 sys.exit(1) 16 17 for binding_key in binding_keys: 18 channel.queue_bind(exchange='topic_logs', 19 queue=queue_name, 20 routing_key=binding_key) 21 22 print(' [*] Waiting for logs. To exit press CTRL+C') 23 24 def callback(ch, method, properties, body): 25 print(" [x] %r:%r" % (method.routing_key, body)) 26 27 channel.basic_consume(callback, 28 queue=queue_name, 29 no_ack=True) 30 channel.start_consuming()
python receive_logs_topic.py "#" 接收所有日志
python receive_logs_topic.py "kern.*" #接收kern.a、kern.b等等的日志
python receive_logs_topic.py "*.critical"
python receive_logs_topic.py "kern.*" "*.critical" #接收多个
python emit_log_topic.py "kern.critical" "A critical kernel error" #客户端发送
以上都是单向通信
RPC(Remote Procedure Call)远程过程调用 (它是一个短链接)
RPC采用客户机/服务器模式。请求程序就是一个客户机,而服务提供程序就是一个服务器。首先,客户机调用进程发送一个有进程参数的调用信息到服务进程,然后等待应答信息。在服务器端,进程保持睡眠状态直到调用信息到达为止。当一个调用信息到达,服务器获得进程参数,计算结果,发送答复信息,然后等待下一个调用信息,最后,客户端调用进程接收答复信息,获得进程结果,然后调用执行继续进行
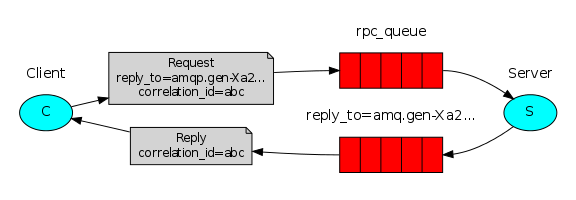
生产者: 服务端必须先启动了 因为服务端声明了rpc_queue
1 import pika 2 import time 3 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) 4 5 channel = connection.channel() 6 7 channel.queue_declare(queue='rpc_queue') 8 9 def fib(n): 10 if n == 0: 11 return 0 12 elif n == 1: 13 return 1 14 else: 15 return fib(n-1) + fib(n-2) 16 17 def on_request(ch, method, props, body): 18 n = int(body) 19 print(" [.] fib(%s)" % n) 20 response = fib(n) 21 22 ch.basic_publish(exchange='', 23 routing_key=props.reply_to, 24 properties=pika.BasicProperties(correlation_id = props.correlation_id), 25 body=str(response)) 26 ch.basic_ack(delivery_tag = method.delivery_tag) 27 28 channel.basic_qos(prefetch_count=1) #basic_qos流量控制 一次只拿一个任务 处理不完就不要发给我了 29 channel.basic_consume(on_request, queue='rpc_queue') #准备接收 30 31 print(" [x] Awaiting RPC requests") 32 channel.start_consuming()
消费者:
1 import pika 2 import uuid 3 4 class FibonacciRpcClient(object): 5 def __init__(self): 6 ''' 7 做了链接,连接rabbit并声明了一个callback_queue,然后准备收结果 8 ''' 9 self.connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) 10 11 self.channel = self.connection.channel() 12 result = self.channel.queue_declare(exclusive=True) 13 self.callback_queue = result.method.queue 14 self.channel.basic_consume(self.on_response, no_ack=True, #准备接收命令结果 15 queue=self.callback_queue) #从自己生成的callback_queue中接 16 17 def on_response(self, ch, method, props, body): 18 '''回调函数''' 19 if self.corr_id == props.correlation_id: #props为服务器端返回的 20 self.response = body 21 22 def call(self, n): 23 self.response = None 24 self.corr_id = str(uuid.uuid4()) #创建唯一标识符 25 self.channel.basic_publish(exchange='', 26 routing_key='rpc_queue', 27 properties=pika.BasicProperties( 28 reply_to = self.callback_queue, #告诉服务器把结果放callback_queue中 29 correlation_id = self.corr_id, #发送该队列的唯一标识符 30 ), 31 body=str(n)) 32 while self.response is None: #channel.start_consuming() 这样写会阻塞 33 self.connection.process_data_events() #检查队列里有没有新消息 不会阻塞 异步 34 return int(self.response) 35 36 fibonacci_rpc = FibonacciRpcClient() 37 38 print(" [x] Requesting fib(30)") 39 response = fibonacci_rpc.call(30) 40 print(" [.] Got %r" % response)
posted on 2019-02-20 15:09 liyancheng 阅读(659) 评论(0) 编辑 收藏 举报

