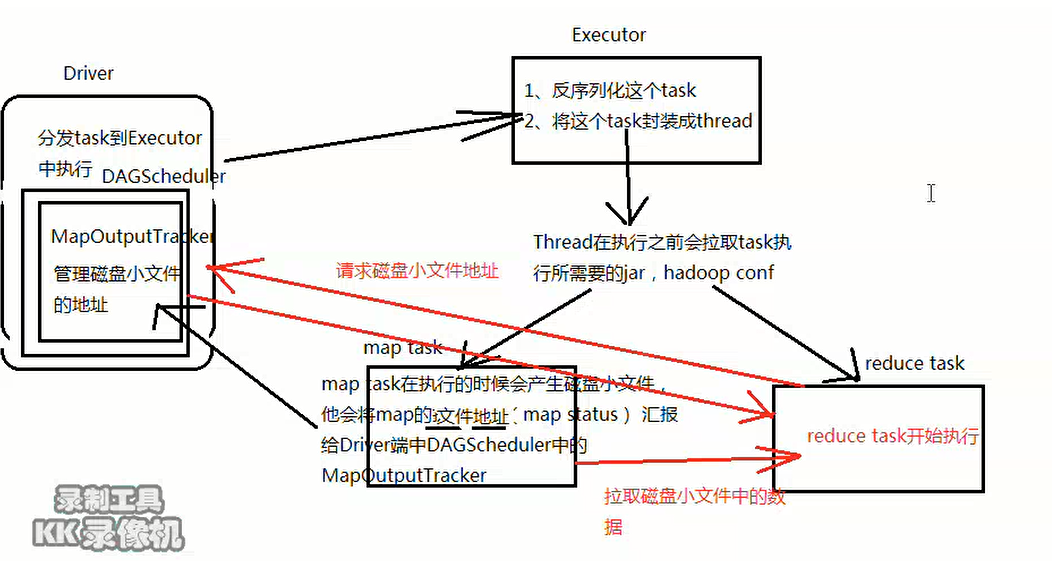
Spark中的Shuffle过程
一、Spark中的Shuffle过程
Shuffle分为两种:Shuffle write、Shuffle read
Spark中Shuffle分为两种:HahShuffle、SortShuffle;
1、HashShuffle
磁盘小文件的个数为:M*R = 4*3 =12个
每一个buffer的大小为32k,由于产生的磁盘小文件过多,会产生一系列的问题
如:因为在写文件的时候会产生大量的写句柄,导致产生大量的临时对象,产生OM问题
在Reduce端读取小文件的时候,又会产生的大量的读句柄,浪费资源
在Reduce端读取小文件时,因为小文件数目过多,产生大量的通信操作,通信操作会根频繁,浪费资源。
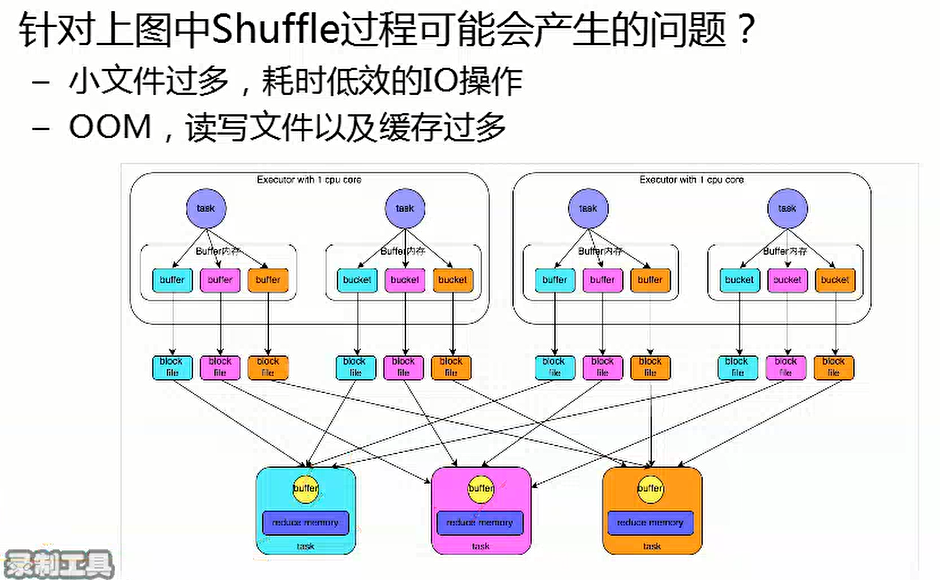
针对上述问题,对HashShuffle进行了优化操作
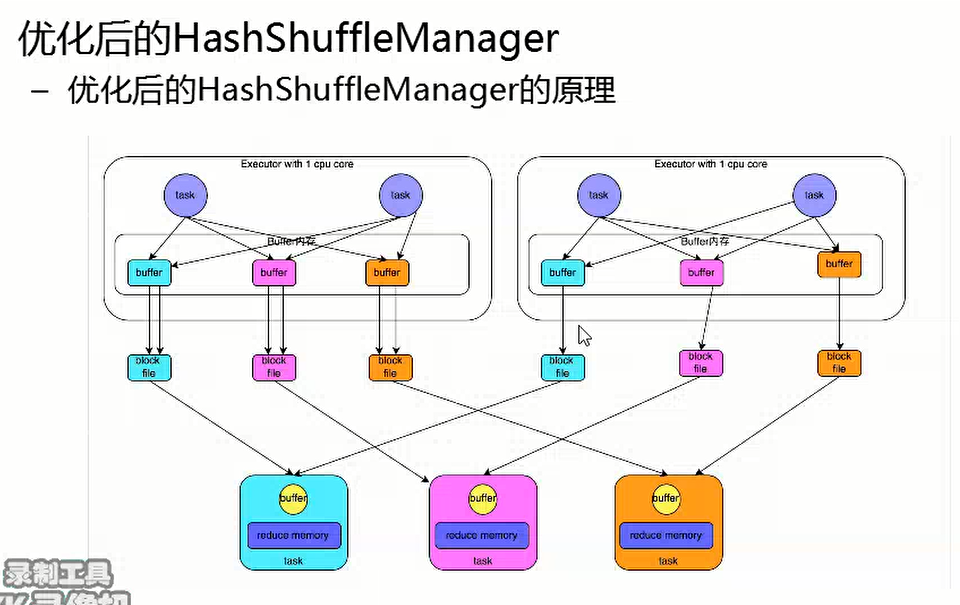
此时一个task group共同使用一组block file,这样可以减少大量的磁盘小文件
优化方式中产生磁盘小文件的个数与Executor中Core的个数有关 文件个数 = core*Reduce个数 = 2*3;
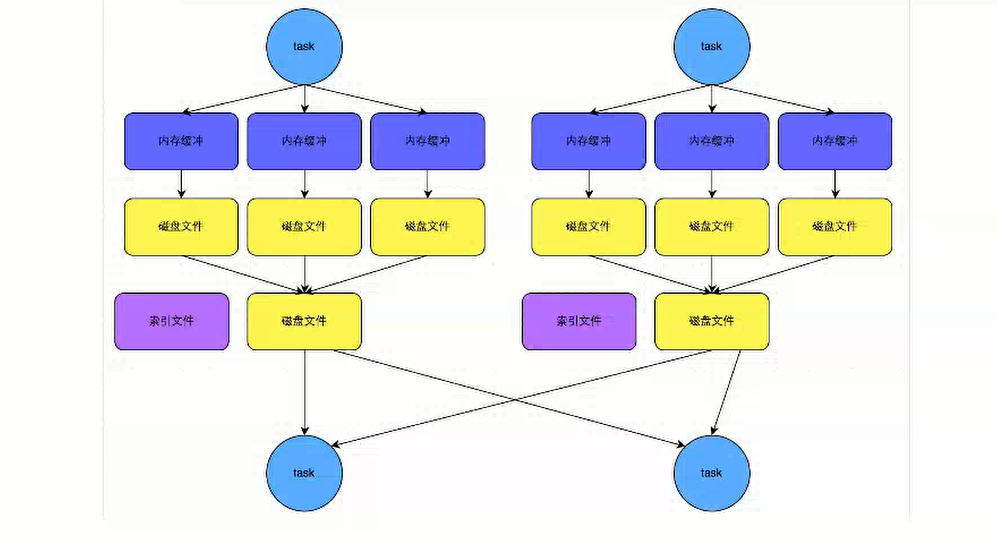
2、SortShuffle
SortShuffle分为两种:普通运行机制、ByPass运行机制
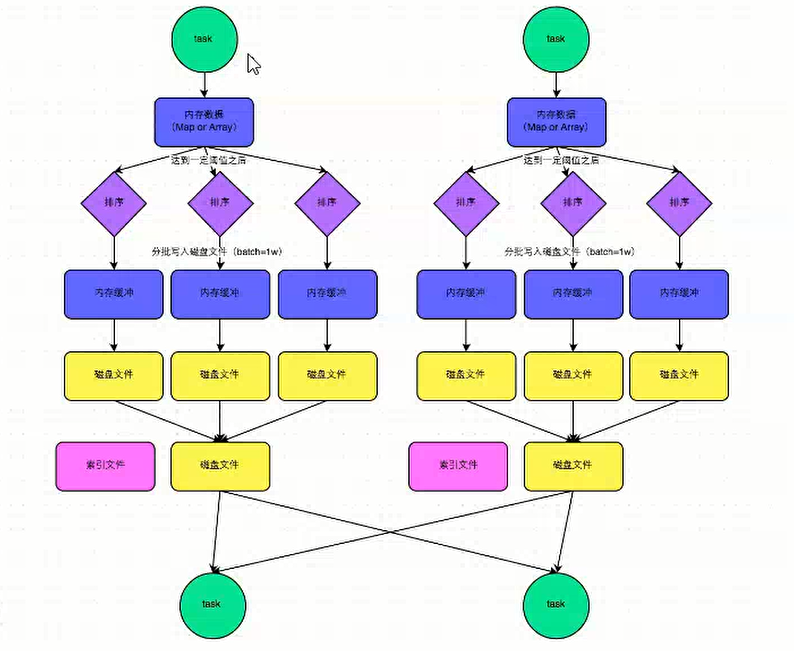
(1)普通运行机制
简单说明:
1、一个task产生的数据存储到Map或者Array中(根据使用的算子进行区分),其中内存数据的溢写机制如下:
默认为5M,当数据为5.1m时,此时内存数据会再次申请内存,大小为5.1*2-5 = 5.2m,如果还可以给其分配5.2m的内存,就不溢写,直到最后不能再给其分配资源时,进行溢写。
2、溢写的时会进行排序操作,然后分批写入磁盘文件(默认是batch=1w)
3、在写完成后,会进行文件的合并,并产生一个索引文件,利用快速查找
产生磁盘小文件的个数为:2*m;与Reduce个数无关。
(2)ByPass运行机制
减少了排序的环节
产生磁盘小文件的个数为:2*m;与Reduce个数无关。
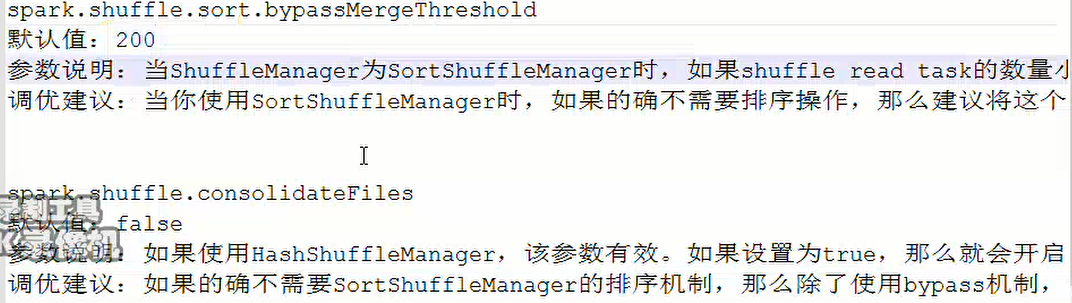
bypass运行机制的触发:shuffle.reduce.task数量小于spark.shuffle.sort.bypassMergeThreshold参数的值。
二、Spark 调优



三、Reduce端拉取数据