提取网页网站-lxml结合xpath语法实例二(数据提取)
这一篇文章爬取我博客内容并且按照输入提示保存
有关参考
爬取文章标题:https://www.cnblogs.com/lcyzblog/p/11275188.html
源码分析:文本存放于div的clss属性为postBody的标签下
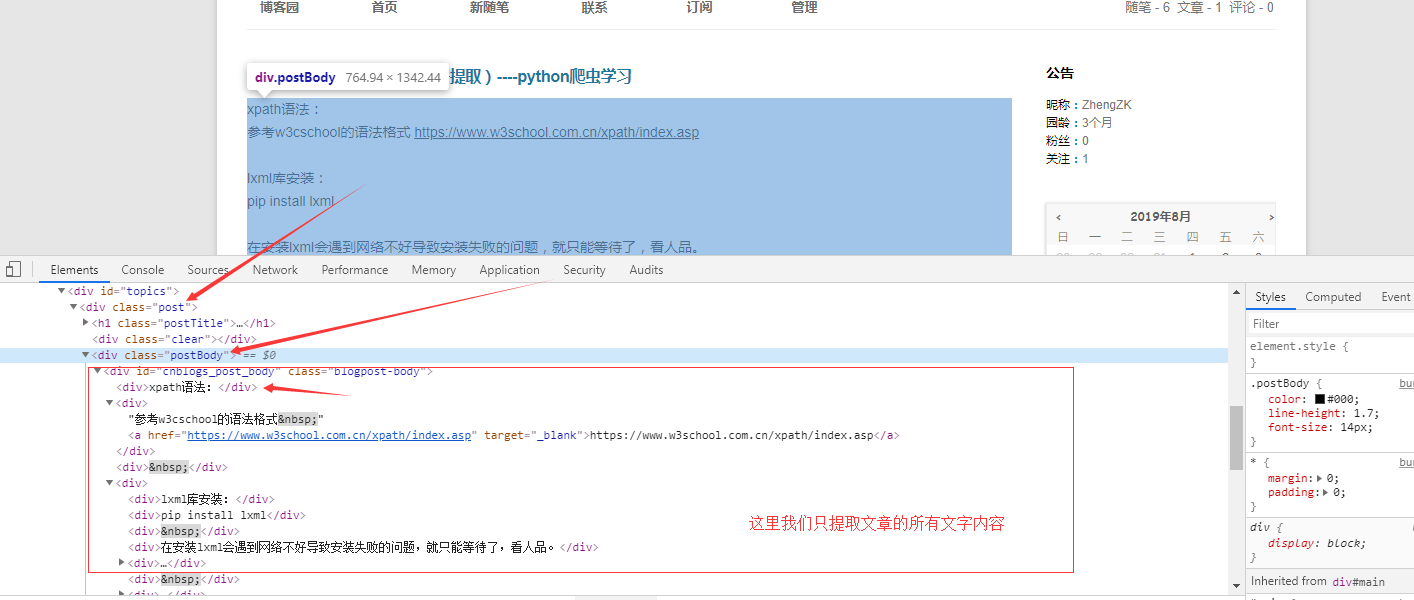
from lxml import etree
import requests
get_cookie = requests.session()
def get_titles_and_blogurl():
global url_blog
global title_blog
url_get_cookies = 'https://www.cnblogs.com/'
blog_url = "https://www.cnblogs.com/lcyzblog/"
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'}
get_cookie.get(url=url_get_cookies, headers=header)
html_blog = get_cookie.get(blog_url)
myblog_html = etree.HTML(html_blog.text)
#get_myblog_title用于获取博客文章标题
#get_myblog_url用于获取博客链接
get_myblog_title = "//div[@class='postTitle']/a/text()"
get_myblog_url="//div[@class='postTitle']/a/@href"
title_blog=myblog_html.xpath(get_myblog_title)
url_blog=myblog_html.xpath(get_myblog_url)
blog_main=dict(zip(title_blog,url_blog))
print(blog_main)
return blog_main
def get_main(text_note):
#利用字典得到文章的标题去得到文章对应的url
main_blog_url=main_is_blog[text_note]
main_blog_html=get_cookie.get(main_blog_url)
blog_main_html=etree.HTML(main_blog_html.text)
main_blog_xpath="//div[@class='postBody']//text()"
main_blog_text = blog_main_html.xpath(main_blog_xpath)
print(main_blog_text)
numbers = input("是否需要保存文章?(yes/no)到本地: ")
if numbers=="yes":
with open("./"+text_note+".txt",'w',encoding='utf-8') as fp:
for str_blog in main_blog_text:
fp.write(str_blog)
else:
return main_blog_text
if __name__ == '__main__':
#得到博客文章的标题和url
main_is_blog=get_titles_and_blogurl()
note = input("请输入查看的文章:")
get_main(text_note=note)
