
android学习笔记----xml语法、约束、解析
目录
xml作用:
一:可以在客户端/服务器之间传递数据
二:用来保存有关系的数据
三:用来做配置文件
在android中的界面的布局文件、清单文件都是用xml文件来描述的。
所有的浏览器都可以解析xml
xml语法:

xml文件的encoding默认是:"utf-8",但是如果用记事本编辑xml,保存的时候默认ANSI,代表使用平台的编码表gbk保存,不指定编码的话,在解析的时候可能会出现问题。在保存的时候选择UTF-8保存就可以不指定编码,最好还是要指定编码。
保存的时候,编码方式要和声明的encoding一致,如果不一致,则按照保存的为准,忽视了声明encoding。比如保存的时候选择ANSI,但是encoding=“utf-8”,则还是按照平台编码标准gbk,解析的时候,中文会乱码。除非保存选择ANSI,encoding=“gbk”
用集成开发环境就不会出现上述问题,会自动处理成一致的。
元素:

比如:
<?xml version = "1.0" encoding = "utf-8"?>
<中国>
<北京>
</北京>
</中国>
<中国>
<武汉>
</武汉>
</中国>
这就是错误的,要么认为没有根标签,要么认为有2个根标签<中国>,语法不对。

如果标签中没有其他内容,那么可以自闭合,如<tag />
第一种写法:(可读性好,浪费流量)
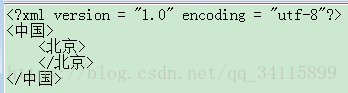
空格对用户来说也是需要流量的
第二种写法:(可读性差,节省流量)
元素--命名规范:

属性:

注释:

切记,第一行一定是xml声明,不能是注释
CDATA区:

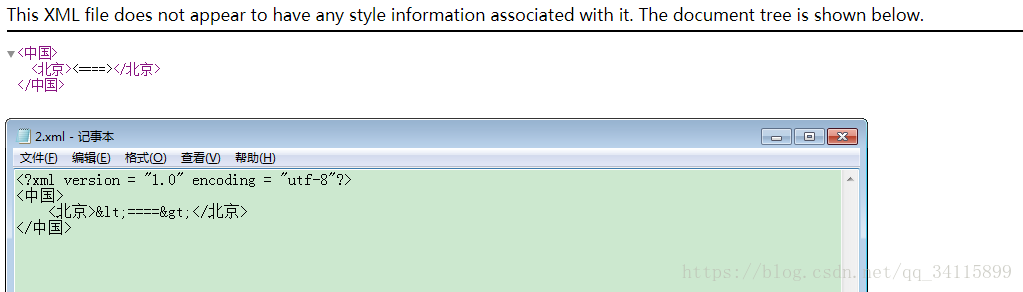
比如:想显示尖括号<>这个直接打上去不允许,会被认为是标签的尖括号。那么操作如下:
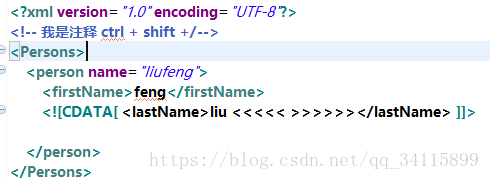
浏览器打开效果:

特殊字符:
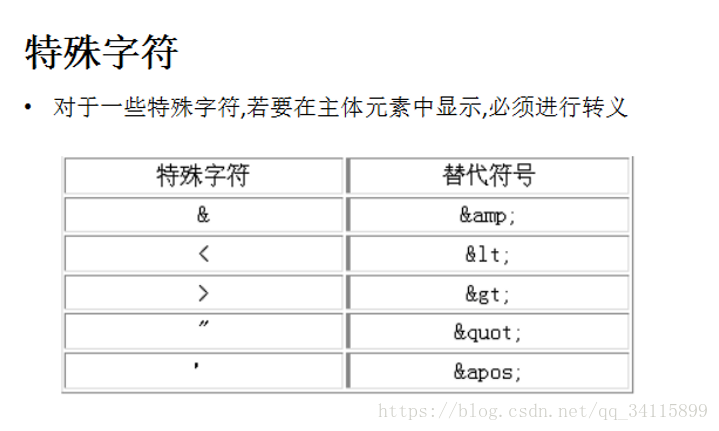
要想直接显示大于号小于号,则需要转义字符
XML约束:

有效的xml一定是格式良好的xml,而格式良好的xml不一定是有效的xml

DTD约束:

book.dtd中
“(书+)”代表可以有多个<书>这种结点

引入DTD文档URL会自动下载DTD文档





#PCDATA说明标签内只能是普通文本,不能含有其他标签,比如<书名><a>java就业培训教程</a></书名>就出错,因为不能含有<a>标签,只能是普通文本。
EMPTY说明标签内不能有任何内容,只能是空标签
()括号里面表示该标签包含哪些子标签,比如<!ELEMENT 书 (书名,作者,售价)>,因为是用逗号分隔,所以子标签的顺序一定是<书名><作者><售价>

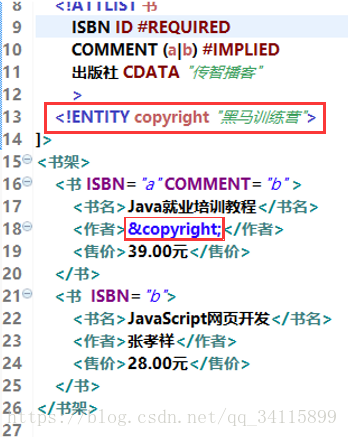
<!ATTLIST>约束属性列表
比如

上图说明,ISBN属性ID表示取值不能重复,如果另一个<书>标签的ISBN属性与这个标签的ISBN值重复就会报错,#REQUIRED说明这个ISBN属性是必须有的。
COMMENT的属性CDATA表示这个属性只能是普通文本字符串,#IMPLIED表示这个属性可有可无,假如属性加上(a|b)就表示只能从“a”或“b”任选其一,上面的<书 ISBN="a" COMMENT="ddd">就会报错,不能取值“ddd”。

比如:
网页效果:


通过DTD可以约束元素的名称,元素出现的顺序、次数,属性的名称、类型、是否必须出现、值是否可以重复。
如果是声明在xml文档中的DTD,那么编码没有要求,如果是独立的DTD文档,扩展名是dtd,则编码必须是utf-8
Schema约束:



xmlns表示命名空间
targetNamespace表示目标空间,通常是指公司的域名,都是不同的。
在xml文档中,需要符合schema约束,比如在xml中的xmlns:android就是schema约束中的目标空间android,比如为xmlns:android="http://schemas.android.com/apk/res/android",这是作为一个文档的标识,并不是说文档就在这个网址中,比如另外一个xml文件中也有<书>标签,就用名称空间来区分,比如android:layout_height="wrap_content"就用到了schema技术,表示这个layout_height属性的名称空间是android。
xmlns:xsi就是需要符合的标准比如xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http//www.itheima.com bookschema.xsd"表示对应的文档在http//www.itheima.com, 文档名字是bookschema.xsd。
Schema:
一:Schema扩展名.xsd,本身也是一份xml文档
二:对名称空间(namespace)支持的很好
三:支持的类型比dtd更丰富,约束的更细致,可以支持自定义的类型
四:schema正在逐步替换dtd,在android中清单文件和布局文件就用到了schema约束
xml约束技术的作用:规范xml文件的书写(标签 属性 文本)
xml约束常用技术:dtd schema
android中用到的约束schema
名称空间:起到了类似包名的作用
如果xml没有约束,那么只需要遵循xml基本语法即可,比如服务端和客户端传输数据,只要事先协商好每个标签是什么意思就行,就不必用约束。
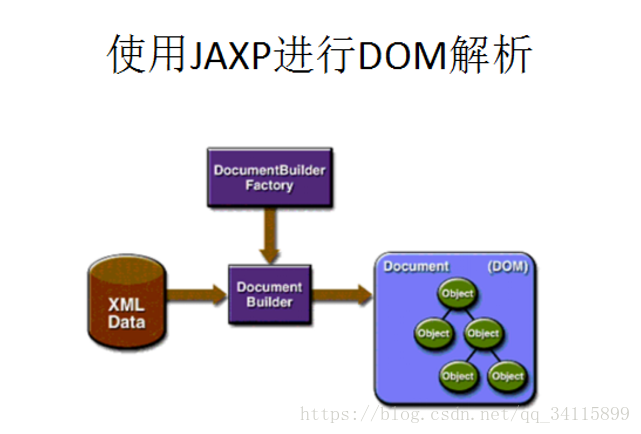
XML解析:

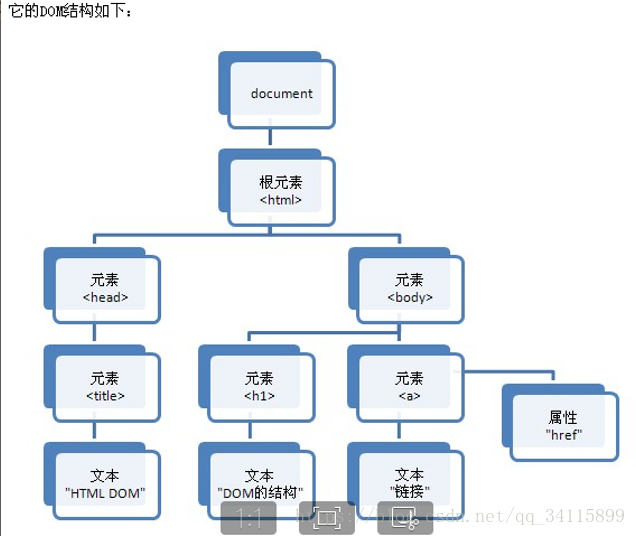
DOM解析:
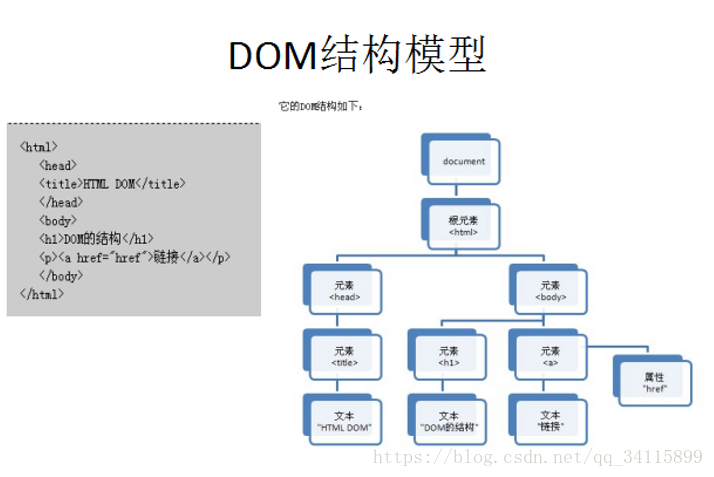
DOM文档都加载到内存中



book.xml如下:

在eclipse中显示:
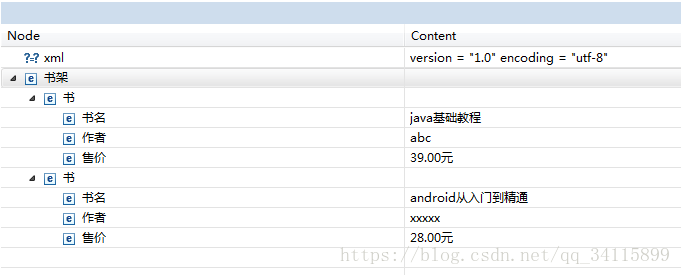
先把book.xml复制粘贴到项目中
package xml解析;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class DomParseTest {
public static void main(String[] args) throws Exception {
// 获取DocumentBuilderFactory
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
// 获取DocumentBuilder
DocumentBuilder documentBuilder = builderFactory.newDocumentBuilder();
// 通过ducumentBuilder解析xml文档获得Document对象
Document document = documentBuilder.parse("book.xml");
// 通过元素的名字可以找到元素的集合
NodeList nodeList = document.getElementsByTagName("书");
// 找到第几个元素
Node node = nodeList.item(0);
Node node1 = nodeList.item(1);
// 读出对应的节点文本内容
String content = node.getTextContent();
String content1 = node1.getTextContent();
System.out.println("书:");
System.out.println(content);
System.out.println(content1);
System.out.println("============================");
// 通过元素的名字可以找到元素的集合
NodeList nodeList1 = document.getElementsByTagName("书名");
// 找到第几个元素
Node node2 = nodeList1.item(0);
Node node3 = nodeList1.item(1);
// DOM把xml读取到了内存中,这只是在内存中的修改,源文件并没有变
node2.setTextContent("被修改了");
// 读出对应的节点文本内容
String content2 = node2.getTextContent();
String content3 = node3.getTextContent();
System.out.println("书名:");
System.out.println(content2);
System.out.println(content3);
}
}运行结果如图:

package xml解析;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.Result;
import javax.xml.transform.Source;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class DomParseTest {
public static void main(String[] args) throws Exception {
// 获取DocumentBuilderFactory
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
// 获取DocumentBuilder
DocumentBuilder documentBuilder = builderFactory.newDocumentBuilder();
// 通过ducumentBuilder解析xml文档获得Document对象
Document document = documentBuilder.parse("book.xml");
// 通过元素的名字可以找到元素的集合
NodeList nodeList = document.getElementsByTagName("书");
// 找到第几个元素
Node node = nodeList.item(0);
Node node1 = nodeList.item(1);
// 读出对应的节点文本内容
String content = node.getTextContent();
String content1 = node1.getTextContent();
System.out.println("书:");
System.out.println(content);
System.out.println(content1);
System.out.println("============================");
// 通过元素的名字可以找到元素的集合
NodeList nodeList1 = document.getElementsByTagName("书名");
// 找到第几个元素
Node node2 = nodeList1.item(0);
Node node3 = nodeList1.item(1);
// DOM把xml读取到了内存中,这只是在内存中的修改,源文件并没有变
node2.setTextContent("被修改了");
// 读出对应的节点文本内容
String content2 = node2.getTextContent();
String content3 = node3.getTextContent();
System.out.println("书名:");
System.out.println(content2);
System.out.println(content3);
TransformerFactory transformerFactory = TransformerFactory.newInstance();
Transformer transformer = transformerFactory.newTransformer();
// 数据源
Source xmlSource = new DOMSource(document); // 获取内存中的document对象
// 要输出到的目的地
Result outputTarget = new StreamResult("book.xml");
transformer.transform(xmlSource, outputTarget);
System.out.println("=========================");
System.out.println("现在查看xml发现真正被修改了");
}
}运行结果:



DOM解析要点:

SAX解析:

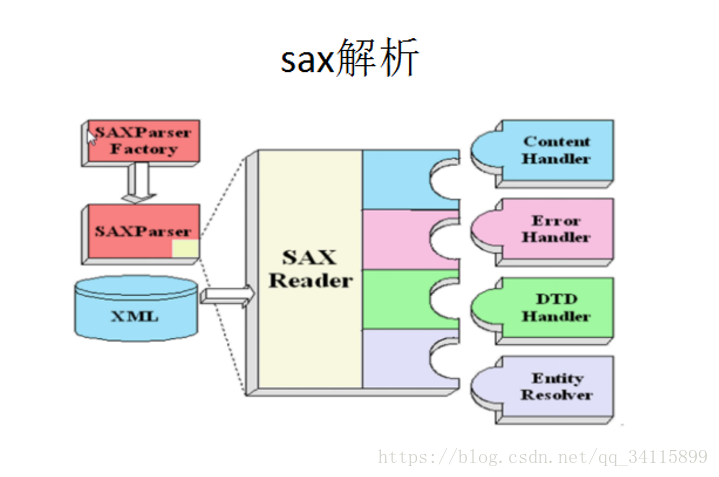
用代码解决SAX解析的过程:
package xml解析;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.DefaultHandler;
public class SaxParserTest {
public static void main(String[] args) throws Exception {
// 获取工厂
SAXParserFactory parserFactory = SAXParserFactory.newInstance();
SAXParser saxParser = parserFactory.newSAXParser();
// 获取xmlReader通过这个reader可以试着ContentHandler
XMLReader xmlReader = saxParser.getXMLReader();
// 给xmlReader设置contentHandler
// contentHandler是一个接口,里面太多的方法没实现
// 所以不去直接实现contentHandler,而是继承它默认的实现DefaultHandler
xmlReader.setContentHandler(new MyHandler());
// 解析xml文档
xmlReader.parse("book.xml");
}
private static class MyHandler extends DefaultHandler {
@Override
public void startDocument() throws SAXException {
System.out.println("文档开始");
}
@Override
public void endDocument() throws SAXException {
System.out.println("文档结束");
}
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes)
throws SAXException {
System.out.println("开始标签<" + qName + ">");
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
System.out.println("结束标签</" + qName + ">");
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
String text = new String(ch, start, length);
System.out.println("文本内容" + text);
}
}
}运行结果:

从结果可以看出,不管开始标签结束标签,之后就会尝试获取内容,如果内容为空,那么就不会获取结束标签。
也就是调用了startElement方法或者endElement方法后,一定会调用characters方法,如果调用characters方法获取的文本为空串,那么就会跳到下一行进行解析。
sax解析一次性解析完毕,中途不会停止,除非抛异常,而pull解析需要自己去next()进行下一次解析。
PULL解析:

pull解析在java里面需要导包,但是在android里面不需要解析,默认就是pull解析
关于pull解析可以看我的另一篇文章:android学习笔记----pull解析与xml生成和应用申请权限模版
================================Talk is cheap, show me the code================================

