Select Sort
The algorithm works as follows:
1. Find the minimum value in the list
2. Swap it with the value in the first position
3. Repeat the steps above for the remainder of the list
(starting at the second position and advancing each time)
Effectively, the list is divided into two parts: the sublist of items already sorted, which is built up from left to right and is found at the beginning, and the sublist of items remaining to be sorted, occupying the remainder of the array.
Here is an example of this sort algorithm sorting five elements:
--------------------------------------------------------------------------------------------
64 25 12 22 11
11 25 12 22 64
11 12 25 22 64
11 12 22 25 64
11 12 22 25 64
------------------------------------------------------------------
(nothing appears changed on this last line because the last 2 numbers were already in order)
Selection sort can also be used on list structures that make add and remove efficient, such as a linked list. In this case it's more common to remove the minimum element from the remainder of the list, and then insert it at the end of the values sorted so far.
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
/* a[0] to a[n-1] is the array to sort */
int iPos;
int iMin;
/* advance the position through the entire array */
/* (could do iPos < n-1 because single element is also min element) */
for (iPos = 0; iPos < n; iPos++)
{
/* find the min element in the unsorted a[iPos .. n-1] */
/* assume the min is the first element */
iMin = iPos;
/* test against all other elements */
for (i = iPos+1; i < n; i++)
{
/* if this element is less, then it is the new minimum */
if (a[i] < a[iMin])
{
/* found new minimum; remember its index */
iMin = i;
}
}
/* iMin is the index of the minimum element. Swap it with the current position */
if ( iMin != iPos )
{
swap(a, iPos, iMin);
}
}
---------------------------------------------------------------------------------------------------------------------------------
Mathematical definition
Let L be a non-empty set and  such that f(L) = L' where:
such that f(L) = L' where:
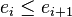 for all
for all  and
and  ,
,  ,
, --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Analysis
Selection sort is not difficult to analyze compared to other sorting algorithms since none of the loops depend on the data in the array. Selecting the lowest element requires scanning all n elements (this takes n − 1 comparisons) and then swapping it into the first position. Finding the next lowest element requires scanning the remaining n − 1 elements and so on, for (n − 1) + (n − 2) + ... + 2 + 1 = n(n − 1) / 2 ∈ Θ(n2) comparisons (seearithmetic progression). Each of these scans requires one swap for n − 1 elements (the final element is already in place).
Data structure Array
Worst case performance О(n2)
Best case performance О(n2)
Average case performance О(n2)
Worst case space complexity О(n) total, O(1) auxiliary
Comparison to other sorting algorithms
Among simple average-case Θ(n2) algorithms, selection sort almost always outperforms bubble sort and gnome sort, but is generally outperformed byinsertion sort. Insertion sort is very similar in that after the kth iteration, the first k elements in the array are in sorted order. Insertion sort's advantage is that it only scans as many elements as it needs in order to place the k + 1st element, while selection sort must scan all remaining elements to find the k + 1st element.
Simple calculation shows that insertion sort will therefore usually perform about half as many comparisons as selection sort, although it can perform just as many or far fewer depending on the order the array was in prior to sorting. It can be seen as an advantage for some real-time applications that selection sort will perform identically regardless of the order of the array, while insertion sort's running time can vary considerably. However, this is more often an advantage for insertion sort in that it runs much more efficiently if the array is already sorted or "close to sorted."
While selection sort is preferable to insertion sort in terms of number of writes (Θ(n) swaps versus Ο(n2) swaps), it almost always far exceeds (and never beats) the number of writes that cycle sort makes, as cycle sort is theoretically optimal in the number of writes. This can be important if writes are significantly more expensive than reads, such as with EEPROM or Flash memory, where every write lessens the lifespan of the memory.
Finally, selection sort is greatly outperformed on larger arrays by Θ(n log n) divide-and-conquer algorithms such as mergesort. However, insertion sort or selection sort are both typically faster for small arrays (i.e. fewer than 10-20 elements). A useful optimization in practice for the recursive algorithms is to switch to insertion sort or selection sort for "small enough" sublists.
Variants
Heapsort greatly improves the basic algorithm by using an implicit heap data structure to speed up finding and removing the lowest datum. If implemented correctly, the heap will allow finding the next lowest element in Θ(log n) time instead of Θ(n) for the inner loop in normal selection sort, reducing the total running time to Θ(n log n).
A bidirectional variant of selection sort, called cocktail sort, is an algorithm which finds both the minimum and maximum values in the list in every pass. This reduces the number of scans of the list by a factor of 2, eliminating some loop overhead but not actually decreasing the number of comparisons or swaps. Note, however, that cocktail sort more often refers to a bidirectional variant of bubble sort.
Selection sort can be implemented as a stable sort. If, rather than swapping in step 2, the minimum value is inserted into the first position (that is, all intervening items moved down), the algorithm is stable. However, this modification either requires a data structure that supports efficient insertions or deletions, such as a linked list, or it leads to performing Θ(n2) writes.
In the bingo sort variant, items are ordered by repeatedly looking through the remaining items to find the greatest value and moving all items with that value to their final location. Like counting sort, this is an efficient variant if there are many duplicate values. Indeed, selection sort does one pass through the remaining items for each item moved. Bingo sort does two passes for each value (not item): one pass to find the next biggest value, and one pass to move every item with that value to its final location. Thus if on average there are more than two items with each value, bingo sort may be faster.
Reference:Wikipedia
