20172306 2018-2019-2 《Java程序设计》第五周学习总结
20172306 2018-2019-2 《Java程序设计》第五周学习总结
教材学习内容总结
-
查找
- 查找中,我们对这些算法的实现就是对某个Comparable对象的数组进行查找
- 泛型声明必须位于返回类型之前,这样泛型才可作为返回类型的一部分。
-
linearSearch (T[] data,int min,int max,T target) ```
Searching.linearSearch (targetarray,min,max,target)
这个例子可以表现出泛型方法的应用。(编译器将用targetarray的数据类型和target的数据类型来替代泛型T)- 查找的两种方法:线性查找和二分查找。
- 线性查找就是从最开始一直遍历到最后一个来找,因此找到的时间是不固定的,而且效率是很低的。好处是不需要对数组进行排序
![]()
- 二分查找,是在数组排序之后进行查找,要从中间开始找,之后不断地取中值进行查找,它的效率比较高,但是要是排好序的数组。在去中间的时候,有可能会遇到/2之后是分数的情况,那么根据算法,它选择的是两个中间值中的第一个。
- 线性查找算法具有的线性时间复杂度为O(n),二分查找具有一个对数算法且具有时间复杂度O(log2 n);因此,在n较大时,二分查找要快的多。
-
排序
- 排序分为顺序排序和对数排序。顺序排序通常使用一对嵌套循环对n个元素排序,需要大约n2次比较,对数排序对n个元素进行排序通常需要大约nlog2 n次比较
-
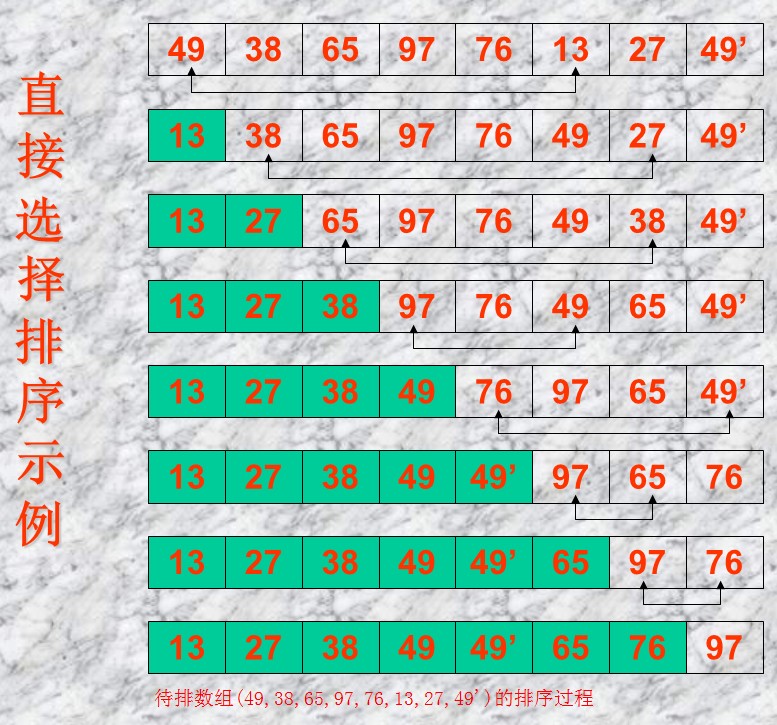
选择排序
- 通俗来说就是,在列表中选出最小值,和第一个值进行交换,然后在除了第一个之后的数字中找到最小值,和第二个进行交换以此类推。其概念为通过反复地将某一特定值放到它在列表中的最终已排序位置从而完成对某一列表值的排序。
![]()
- 通俗来说就是,在列表中选出最小值,和第一个值进行交换,然后在除了第一个之后的数字中找到最小值,和第二个进行交换以此类推。其概念为通过反复地将某一特定值放到它在列表中的最终已排序位置从而完成对某一列表值的排序。
-
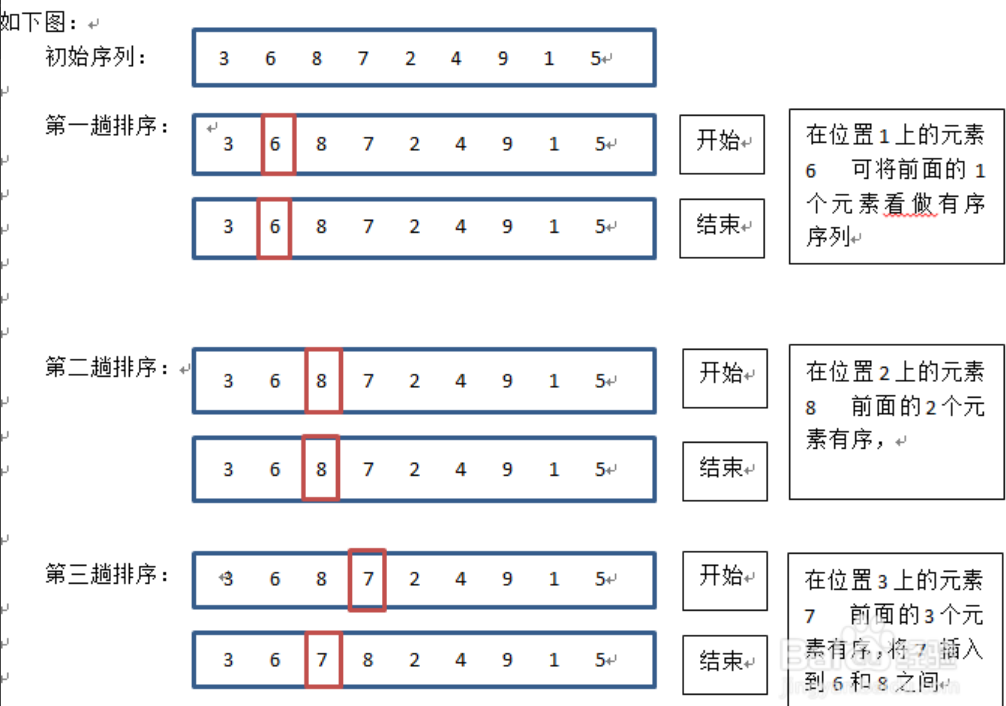
插入排序
- 通俗的说就是,假定数字已经是排好序的了,然后将第一个和第二个比较,看排没排错,如果错了就调换位置,这样第一个和第二个就排好了,再将第三个排进前两个中,以此类推。其概念就是通过反复的将某一特定值插入到该列表某个已排序的子集中来完成对列表值的排序
![]()
- 通俗的说就是,假定数字已经是排好序的了,然后将第一个和第二个比较,看排没排错,如果错了就调换位置,这样第一个和第二个就排好了,再将第三个排进前两个中,以此类推。其概念就是通过反复的将某一特定值插入到该列表某个已排序的子集中来完成对列表值的排序
-
冒泡排序
- 就是两个两个比较,然后在第一次就可以将最大的值放在最后,完成最大值的位置,之后又进行下一次,每次都会有一个到达正确的位置。其概念为通过重复地比较相邻元素且必要时将他们互换,从而完成对某个列表的排序。
![]()
- 就是两个两个比较,然后在第一次就可以将最大的值放在最后,完成最大值的位置,之后又进行下一次,每次都会有一个到达正确的位置。其概念为通过重复地比较相邻元素且必要时将他们互换,从而完成对某个列表的排序。
-
快速排序法
- 效率比较高,而且适合元素更多一点的,其概念就是通过将列表分区,然后对这两个分区进行递归式排序,从而完成对整个列表的排序。主要是利用了递归的方法,对列表不断的进行分区。
![]()
- 效率比较高,而且适合元素更多一点的,其概念就是通过将列表分区,然后对这两个分区进行递归式排序,从而完成对整个列表的排序。主要是利用了递归的方法,对列表不断的进行分区。
-
归并排序法
- 一种递归算法,同样是分为两半形成长度为1的列表再进行合并。其概念是通过将列表递归式分成两半直至每一子列表都含有一个元素,然后将这些子列表归并到一个排序顺序中,从而完成排序。
![]()
- 一种递归算法,同样是分为两半形成长度为1的列表再进行合并。其概念是通过将列表递归式分成两半直至每一子列表都含有一个元素,然后将这些子列表归并到一个排序顺序中,从而完成排序。
-
基数排序
- 基于队列处理的,基数排序并不是基于排序关键字来比较排序项,而是基于排序关键字的结构。对于排序关键字中每个数字/字符的每种可能取值,都会创建一个单独的队列,队列的数目就称为基数。基数排序的概念适用于任何类型的数据,只要它们的排序关键字可以被切分成一些固定位置。
基数排序
- 基于队列处理的,基数排序并不是基于排序关键字来比较排序项,而是基于排序关键字的结构。对于排序关键字中每个数字/字符的每种可能取值,都会创建一个单独的队列,队列的数目就称为基数。基数排序的概念适用于任何类型的数据,只要它们的排序关键字可以被切分成一些固定位置。




教材学习中的问题和解决过程
- 问题1:
while (left < right) {
while (left < right && data[left].compareTo(partitionelement) <= 0)
left++;
while (data[right].compareTo(partitionelement) > 0)
right--;
if (left < right)
swap(data, left, right);
}
swap(data, min, right);
return right;
这个是快速排序方法中很依赖的partition方法的一部分,在看书时,对于if语句这两个部分不懂,不知道用来干什么的。
- 问题1解决方案:我问了谭鑫,让他给我讲了一下,因为我知道快速排序的主要是怎么排的,只是不懂代码的意思,所以他就主要就代码给我讲了一下,后来明白了
while (left < right) {//进行遍历
while (left < right && data[left].compareTo(partitionelement) <= 0)//这个是从左边扫描到右边,找到大于分区元素的元素
left++;//再比较左面的下一个
while (data[right].compareTo(partitionelement) > 0)//这个是从右边扫描到左边,找到小于分区元素的元素
right--;//再比较右面之前的那一个
//直到两者扫描到中间的值
if (left < right)//如果左面的小于右面的,那么就需要进行交换,
swap(data, left, right);
}
swap(data, min, right);//如果左面大于或者等于右面时,就直接进行交换就可以了
return right;
-
问题2:书中写了快速排序法和归并排序法是更加具有效率的排序方法,那么我很好奇,那么它们的时间复杂度究竟是多少呢?
-
问题2解决方案:我在网上找了这个问题,然后了解到了他们的平均时间复杂度均为O(nlogn)。注意这里是平均,所以存在最优和最糟糕的情况。
- 对于归并排序:总时间=分解时间+解决问题时间+合并时间。分解时间就是把一个待排序序列分解成两序列,时间为一常数,时间复杂度o(1).解决问题时间是两个递归式,把一个规模为n的问题分成两个规模分别为n/2的子问题,时间为2T(n/2).合并时间复杂度为O(n)。总时间T(n)=2T(n/2)+O(n).这个递归式可以用递归树来解,其解是O(nlogn).此外在最坏、最佳、平均情况下归并排序时间复杂度均为O(nlogn).从合并过程中可以看出合并排序稳定。那什么是递归树?
![]() 这个就是递归树的样子,从这个递归树可以看出,第一层时间代价为cn,第二层时间代价为cn/2+cn/2=cn.....每一层代价都是cn,总共有logn+1层。所以总的时间代价为cn*(logn+1).时间复杂度是o(nlogn).
这个就是递归树的样子,从这个递归树可以看出,第一层时间代价为cn,第二层时间代价为cn/2+cn/2=cn.....每一层代价都是cn,总共有logn+1层。所以总的时间代价为cn*(logn+1).时间复杂度是o(nlogn). - 对于快速排序:有最优情况和最糟糕情况。在最优情况下,Partition每次都划分得很均匀,如果排序n个关键字,其递归树的深度就为 [log2n]+1( [x] 表示不大于 x 的最大整数),即仅需递归 log2n 次,需要时间为T(n)的话,第一次Partiation应该是需要对整个数组扫描一遍,做n次比较。然后,获得的枢轴将数组一分为二,那么各自还需要T(n/2)的时间(注意是最好情况,所以平分两半)。于是不断地划分下去,在最优的情况下,快速排序算法的时间复杂度为O(nlogn)。最糟糕情况,当待排序的序列为正序或逆序排列时,且每次划分只得到一个比上一次划分少一个记录的子序列,注意另一个为空。如果递归树画出来,它就是一棵斜树。此时需要执行n‐1次递归调用,且第i次划分需要经过n‐i次关键字的比较才能找到第i个记录,也就是枢轴的位置,因此比较次数为 ,最终其时间复杂度为O(n^2)。
- 对于归并排序:总时间=分解时间+解决问题时间+合并时间。分解时间就是把一个待排序序列分解成两序列,时间为一常数,时间复杂度o(1).解决问题时间是两个递归式,把一个规模为n的问题分成两个规模分别为n/2的子问题,时间为2T(n/2).合并时间复杂度为O(n)。总时间T(n)=2T(n/2)+O(n).这个递归式可以用递归树来解,其解是O(nlogn).此外在最坏、最佳、平均情况下归并排序时间复杂度均为O(nlogn).从合并过程中可以看出合并排序稳定。那什么是递归树?
-
问题3:在问题2中都提到了递归树这个字眼,那么究竟什么是递归树呢?
-
问题3解决方案:看了一些解释,我觉得递归树就是用来计算递归的一个工具,因为形成递归,画出来像树一样,所以叫做递归树。具体参照例子利用递归树进行递归算法
 这个就是递归树的样子,从这个递归树可以看出,第一层时间代价为cn,第二层时间代价为cn/2+cn/2=cn.....每一层代价都是cn,总共有logn+1层。所以总的时间代价为cn*(logn+1).时间复杂度是o(nlogn).
这个就是递归树的样子,从这个递归树可以看出,第一层时间代价为cn,第二层时间代价为cn/2+cn/2=cn.....每一层代价都是cn,总共有logn+1层。所以总的时间代价为cn*(logn+1).时间复杂度是o(nlogn).代码调试中的问题和解决过程
-
问题1:在编辑PP9.2时,书中用了swap的方法,我觉得这里依旧可以用,所以就用了,但是就出现了这样的错误
![]()
-
问题1解决方案:之后不小心对
<? super T>这个部分进行了修改,奇迹般的就不标红了。![]()
-
追加第一问:为什么动那个位置就不标红了呢?
-
回答:我在网上查找了
<? super T>的含义,是说,<T extends Compatable<? super T>>表示了上界为实现了Comparable接口的类,<? super T>则表示实现Comparable接口的类的子类也可以,从而确定下界,而这里的data是不在这个范围内,因此会标红,而当把? super去掉的时候,它的意思就是调用Comparable中的compareTo的方法。


代码托管

上周考试错题总结
![]()
- 题目的意思是:将数组视为循环不需要在数组队列实现中转换元素。数组变为循环数组的话,头的下一个就是尾,所以不需要进行转换元素。

结对及互评
点评模板:
- 博客中值得学习的或问题:
- 他教材的内容总结的比较详细,而且排版看着比我好
- 他的问题有些很有用,有些是马虎的问题
- 这次的博客写的很认真
点评过的同学博客和代码
- 本周结对学习情况
- 20172325
- 结对学习内容
- 学习了第九章的内容
- 共同写了第九章作业
其他(感悟、思考等,可选)
这一章主要是查找和排序,查找以前学过,觉得还不是很难,但是排序后面的快速排序、归并排序、基数排序第一次接触,还是有点蒙,尽管了解它的流程,但是还是对于代码有点糊涂,而且在循环时,对于重复循环还是有点不够熟悉。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 0/0 | 1/1 | 6/6 | |
| 第二周 | 985/985 | 1/1 | 18/24 | |
| 第三周 | 663/1648 | 1/1 | 16/40 | |
| 第四周 | 1742 /3390 | 2/2 | 44/84 | |
| 第五周 | 933/4323 | 1/1 | 23/107 |


 浙公网安备 33010602011771号
浙公网安备 33010602011771号