

文件操作_new
文件处理流程
- 打开文件,得到文件句柄并赋值给一个变量
- 通过句柄对文件进行操作
- 关闭文件
文件编码
一句话 :打开文件的时候,养成良好的习惯 指定编码 f=open('aa.txt','r',encoding='utf-8') ,存的时候和打开的时候,编码一致。
以下是为了证明上边这一句真理
文件保存编码如下
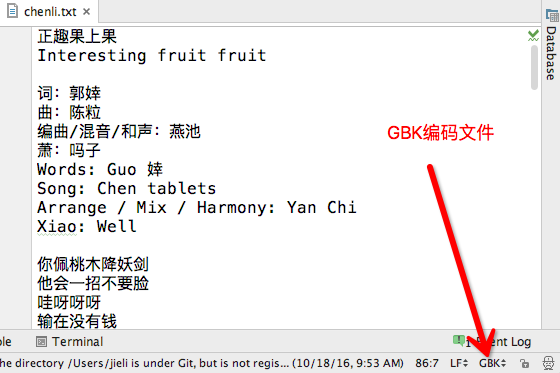 ··········
··········
此刻错误的打开方式
f=open('chenli.txt',encoding='utf-8')
f.read()
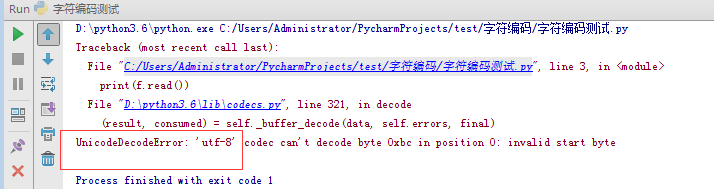
正确的打开方式
#不指定打开编码,默认使用操作系统的编码,windows为gbk,linux为utf-8,与解释器编码无关
f=open('chenli.txt',encoding='gbk') #在windows中默认使用的也是gbk编码,此时不指定编码也行
f.read()
文件基本操作
文件的基本操作无非就是两种: 打开文件(读)和写入文件(写)
打开文件


# 打开文件(打开就记得关闭) # open 文件路径 打开方式默认为’r‘ 指定字符编码 记住这三要素 # * 三要素 赋值后才能操作 # 打开文件的方法就是这个 先理解 后边有更简单的方法 f=open('aa.txt','r',encoding='utf-8') res=f.read() #赋值后才能操作 print(res)
打开文件的方式
打开文件的模式有:
- r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】
- w,只写模式【不可读;不存在则创建;存在则清空内容】
- x, 只写模式【不可读;不存在则创建,存在则报错】
- a, 追加模式【可读; 不存在则创建;存在则只追加内容】
"+" 表示可以同时读写某个文件
- r+, 读写【可读,可写】
- w+,写读【可读,可写】
- x+ ,写读【可读,可写】
- a+, 写读【可读,可写】
"b"表示以字节的方式操作
- rb 或 r+b
- wb 或 w+b
- xb 或 w+b
- ab 或 a+b
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
r或rt 默认模式,文本模式读 rb 二进制文件 w或wt 文本模式写,打开前文件存储被清空 wb 二进制写,文件存储同样被清空 a 追加模式,只能写在文件末尾 a+ 可读写模式,写只能写在文件末尾 w+ 可读写,与a+的区别是要清空文件内容 r+ 可读写,与a+的区别是可以写到文件任何位置
读出文件的方式
f=open('aa.txt','r',encoding='utf-8') res=f.read() print(res)
f=open('aa.txt','r',encoding='utf-8') print(f.readline(),end='') #读取第一行 print(f.readline(),end='') #读取第二行 # 每行中间有个换行符,要想去掉加end 这里去掉的是print自带的换行 print自带的 # 如果只写print(f.readline(),end='') 每次读取都是第一行,不会每次执行就往下走的,貌似每次 # 执行,都是重新打开文件 # 或者 print(f.readline().strip()) #一次读出第一行 print(f.readline().strip()) #读出第二行 print(f.readline().strip()) #读出第三行
f=open('aa.txt','r',encoding='utf-8') res=f.readlines() print(res) ''' ['11111\n', '2222\n', '3333\n', '33333\n'] '''
修改和追加文件
f.write()
''' 原来aa.txt文件内容 aaaaaa bbbbb 你好 cccc ddddd eeeeeee 修改完毕后的内容 aaaaaa bbbbb 修改了 cccc ddddd eeeeeee ''' import os #以只读的方式打开源文件 以写的方式创建新的文件 with open('aa.txt','r',encoding='utf-8') as r_f,open('bb.txt','w',encoding='utf-8') as w_f: r_data=r_f.readlines() #print(r_data) for line in r_data: #将源文件内容写入新文件 并且修改 if line.startswith('你好'): line='修改了\n' w_f.write(line) #目前就有了两个文件,但是只需要一个修改后的文件,原理就是删除源文件,将新文件重命名 ##删除和重命名文件 os.remove('aa.txt') os.rename('bb.txt','aa.txt')
#文件的写入 以写w的方式打开文件:有则清空,没有则创建 f = open('bb.txt',encoding='utf-8',mode='w') f.write('aaaaaa\nnbnfbnfb\n') #可以按照元组和列表的方式写入文件 f.writelines('111111\neeeeeee\n') f.writelines(['yanqi\n','limin\n','gege\n']) f.writelines(('sisisii\n','limin\n','gege\n'))
文件的光标问题 f.seek(0)
f = open('aa.txt',encoding='utf-8',mode='r') print(f) data = f.read() print(data) #f.close() print('=====================') #f.seek(0) #控制光标 ,seek0就是将光标移动到0的位置 这样再次打印就可以重新读到内容了 data2 = f.read() print(data2) ##发现data2并没内容 这里涉及到光标的问题 ##当read的时候,光标从0的位置开始,往下走,当读完后,光标到了文件的末尾 #所以当第一次read的时候 光标已经到了文件的末尾,所以第二次read就读不到内容了
import time with open('test.txt','rb') as f: f.seek(0,2) while True: line=f.readline() if line: print(line.decode('utf-8')) else: time.sleep(0.2)
read(3):
1. 文件打开方式为文本模式时,代表读取3个字符
2. 文件打开方式为b模式时,代表读取3个字节
其余的文件内光标移动都是以字节为单位如seek,tell,truncate
注意:
1. seek有三种移动方式0,1,2,其中1和2必须在b模式下进行,但无论哪种模式,都是以bytes为单位移动的
file.seek()方法标准格式是:seek(offset,whence=0)offset:开始的偏移量,也就是代表需要移动偏移的字节数whence:给offset参数一个定义,表示要从哪个位置开始偏移;
0代表从文件开头开始算起,
1代表从当前位置开始算起,
2代表从文件末尾算起。
默认为0
f.seek(0,2) 从文件末尾开始
python3里面,seek(3,2) 3表示偏移3个字节,2表示从结尾开始,但是只能以rb格式打开文件,否则会报错
seek(a,b) b可以是0,1,2, 0表示开头,1表示当前位置,2表示结尾,a表示偏移的字节数,
2. truncate是截断文件,所以文件的打开方式必须可写,但是不能用w或w+等方式打开,因为那样直接清空文件了,所以truncate要在r+或a或a+等模式下测试效果
关闭文件
#关闭文件 f.close() #为了防止忘记关闭文件 使用with open 用完后会自动关闭 with open('aa.txt','r',encoding='utf-8') as f: res=f.read() print(res) with open('aa.txt','r',encoding='utf-8') as f,open('db.txt') as f1: res=f.read() res1=f1.read() print(res) print(res1)
上下文管理文件
#上下文管理 自动关闭文件 #针对文件打开,忘记关闭的问题,有了自动关闭功能 #打开文件bb.txt,并赋值给f with open('bb.txt','r',encoding='utf-8') as f: print(f.read()) #可以同时的打开多个文件 with open('bb.txt','r',encoding='utf-8') as read_f,open('aa.txt','w') as write_f:
以二进制方式打开文件
''' b 表示以字节的方式操作 什么最终都是二进制,二进制识别一切 以b方式打开时,读取到的内容是字节的形式,写入的时候,也只能以字节的方式,不能指定编码 ####### rb 文件内容: 还有诗和远方 ''' with open('bb.txt','rb') as f: print(f.read()) ''' 打印结果: b'\xe8\xbf\x98\xe6\x9c\x89\xe8\xaf\x97\xe5\x92\x8c\xe8\xbf\x9c\xe6\x96\xb9' with open('bb.txt','rb') as f: print(f.read().decode('utf-8')) #打印结果: #还有诗和远方 ''' ####### wb 写入 with open('c.txt','wb') as f: f.write('啊hi有诗和远方'.encode('utf-8')) #无所不能的二进制,打开图片 with open('wuwu.jpg','rb') as read_f,\ open('wuwu_new.jpg','wb') as write_f: write_f.write(read_f.read())
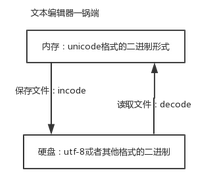
文件内置函数flush
flush原理:
- 文件操作是通过软件将文件从硬盘读到内存
- 写入文件的操作也都是存入内存缓冲区buffer(内存速度快于硬盘,如果写入文件的数据都从内存刷到硬盘,内存与硬盘的速度延迟会被无限放大,效率变低,所以要刷到硬盘的数据我们统一往内存的一小块空间即buffer中放,一段时间后操作系统会将buffer中数据一次性刷到硬盘)
- flush即,强制将写入的数据刷到硬盘
滚动条:
import sys,time
for i in range(10):
sys.stdout.write('#')
sys.stdout.flush()
time.sleep(0.2)
或者
import time
for i in range(10):
print('#',end='',flush=True)
time.sleep(0.2)
else:
print()
open函数讲解
1. open()语法
open(file[, mode[, buffering[, encoding[, errors[, newline[, closefd=True]]]]]])
open函数有很多的参数,常用的是file,mode和encoding
file文件位置,需要加引号
mode文件打开模式,见下面3
buffering的可取值有0,1,>1三个,0代表buffer关闭(只适用于二进制模式),1代表line buffer(只适用于文本模式),>1表示初始化的buffer大小;
encoding表示的是返回的数据采用何种编码,一般采用utf8或者gbk;
errors的取值一般有strict,ignore,当取strict的时候,字符编码出现问题的时候,会报错,当取ignore的时候,编码出现问题,程序会忽略而过,继续执行下面的程序。
newline可以取的值有None, \n, \r, ”, ‘\r\n',用于区分换行符,但是这个参数只对文本模式有效;
closefd的取值,是与传入的文件参数有关,默认情况下为True,传入的file参数为文件的文件名,取值为False的时候,file只能是文件描述符,什么是文件描述符,就是一个非负整数,在Unix内核的系统中,打开一个文件,便会返回一个文件描述符。
2. Python中file()与open()区别
两者都能够打开文件,对文件进行操作,也具有相似的用法和参数,但是,这两种文件打开方式有本质的区别,file为文件类,用file()来打开文件,相当于这是在构造文件类,而用open()打开文件,是用python的内建函数来操作,建议使用open
3. 参数mode的基本取值
| Character | Meaning |
| ‘r' | open for reading (default) |
| ‘w' | open for writing, truncating the file first |
| ‘a' | open for writing, appending to the end of the file if it exists |
| ‘b' | binary mode |
| ‘t' | text mode (default) |
| ‘+' | open a disk file for updating (reading and writing) |
| ‘U' | universal newline mode (for backwards compatibility; should not be used in new code) |
r、w、a为打开文件的基本模式,对应着只读、只写、追加模式;
b、t、+、U这四个字符,与以上的文件打开模式组合使用,二进制模式,文本模式,读写模式、通用换行符,根据实际情况组合使用、
不常用了解的知识点
一些查看的命令 f = open('aa.txt',encoding='utf-8',mode='r') print(f.readable()) 判断文件打开的mode是否是'r' print(f.closed) 判断文件是否是关闭状态 print(f.encoding) 查看文件编码 print(f.name) 查看文件名字 print(f.writable()) 判断是否以可写的方式的打开文件 #不常用,了解的知识点 read 可以加数字 截取文件 针对的是字符 读出几个字符 以下是以文本的方式打开,读的是文本的前两个字符 with open('bb.txt','r',encoding='utf-8') as f: print(f.read(2)) 以下是以rb的方式打开,读到的是前两个bytes字符 bytes也是一种字符 with open('bb.txt','rb') as f: print(f.read(2)) seek 加数字 针对的是字节 比如汉字一个是三个字节,seek(2)的话,截半截 肯定报错 with open('bb.txt','r',encoding='utf-8') as f: f.seek(3) print(f.tell())# 当前光标在哪个位置 print(f.read()) truncate 截断文件,保留从开头到指定位置的内容 针对的是字节 是一种写操作, w就直接清空了 with open('bb.txt','r+',encoding='utf-8') as f: f.truncate(3) seek 默认起始位置是文件的开始位置 就是0 但是也可以指定相对位置 在python3中,要用相对位置,必须以b的方式打开 with open('bb.txt','rb') as f: f.read(2) print(f.tell()) f.seek(2,1) #1 表示以当前位置为起始点,往后移动两个 print(f.tell()) f.seek(-1,2) #以文件的末尾位置为开始点,往后移动-2 print(f.tell())
